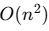Array
가장 기본적인 데이터 구조, 배열은 인덱스와 인덱스에 해당하는 데이터들로 이루어져 있으며, 생성 시 설정된 셀의 수가 고정된다.
- 구조 : 고정 크기의 연속된 메모리 공간
- 접근 : 인덱스를 통해 직접 접근 가능(시간 복잡도 O(1))
- 삽입/삭제 : 요소를 이동해야 하므로 비용이 큼(시간 복잡도 O(n))
- 메모리 : 크기가 고정되어, 공간 낭비 가능성 있음
- ex) 점수 [90, 85, 78] 이 저장된 배열에서 두 번째 점수는 scores[1]로 접근 가능
Linked List
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료구조, 인덱스나 위치와 같은 데이터의 물리적 배치를 사용하지 않고, 다음 노드 연결에 대한 포인터 또는 주소를 사용하는 것이 특징이다.
- 구조 : 동적 크기로, 각 노드가 포인터를 통해 연결됨
- 접근 : 순차적으로 탐색해야 함(시간 복잡도 O(n))
- 삽입/ 삭제 : 포인터만 변경하면 되므로 효율적(시간 복잡도 O(1), 포인터를 알고 있는 경우)
- 메모리 : 필요한 만큼만 할당, 하지만 포인터를 위한 추가 메모리 필요
- ex) 노드 [90] -> [85] -> [76] 로 연결, 처음에 새로운 값을 삽입할 때는 헤드 포인터만 업데이트 하면 됨.
Stack
순서가 보존되는 선형 자료구조의 일종으로, LIFO(Last In First Out) 메커니즘을 갖고 있다.
- 구조 : LIFO(Last In, First Out) 구조, 마지막에 삽입된 데이터가 가장 먼저 삭제됨.
- 연산
∘Push: 데이터를 스택에 삽입
∘Pop: 스택에서 데이터를 제거
∘Peek: 가장 위에 있는 데이터를 확인- ex) 뒤로 가기 기능 : 브라우저에서 사용자가 방문한 페이지 기록을 스택으로 저장
Queue
순서가 보존되는 선형 자료구조의 일종으로, FIFO(First In First Out) 메커니즘을 갖고 있다.
- 구조 : FIFO(First In, First Out) 구조, 먼저 삽입된 데이터가 가장 먼저 삭제됨
- 연산
∘Enqueue: 데이터를 큐에 삽입
∘Dequeue: 큐에서 데이터를 제거
∘Front: 큐의 가장 앞에 있는 데이터를 확인- ex) 은행 대기열 : 먼저 온 사람이 먼저 처리됨.
Tree
비선형 자료구조로, 노드로 구성된 계층적 자료구조, 최상위 노드(Root)를 만들고, 부모(Parent) 노드에 자식(Child) 노드를 추가하고 그리고 그 자식 노드가 부모 노드로써 또 다른 자식 노드를 추가하는 구조를 가지고 있다.
- 구조 : 계층적(hierarchical) 데이터 구조로, 노드(Node)와 간선(Edge)으로 구성
∘ 루트 노드(Root Node) : 트리의 시작점, 단 하나만 존재
∘ 자식 노드(Child Node) : 다른 노드에 연결된 노드
∘ 부모 노드(Parent Node) : 자식 노드를 가지는 노드
∘ 리프 노드(Leaf Node) : 자식 노드가 없는 노드
∘ 레벨(Level) : 루트에서부터 특정 노드까지의 깊이- 특징
- 계층적 구조 : 노드 간에 위계 관계가 있음
- 연결성 : 노드들은 간선을 통해 연결됨
- 사이클 없음 : 트리는 사이클이 없는 비순환 연결 그래프
- 노드 수와 간선 수 관계:
- 노드 수가 N일 때, 간선 수는 N-1
- 종류
- 이진 트리(Binary Tree)
- 각 노드가 최대 두 개의 자식 노드를 가짐
∘ 완전 이진 트리 : 마지막 레벨을 제외하고 모든 레벨이 채워져 있음
∘ 포화 이진 트리 : 모든 레벨이 꽉 채워져 있음
- 이진 탐색 트리(Binary Search Tree)
∘ 왼쪽 서브트리 : 루트보다 작은 값
∘ 오른쪽 서브트리 : 루트보다 큰 값
∘ 효율적 데이터 검색, 삽입, 삭제 지원- 균형 트리(Balanced Tree)
∘ ex) AVL 트리, 레드-블랙 트리
∘ 서브트리 간 높이 차이가 제한되어 있음- 힙(Heap)
∘ 최대 힙(Max Heap) : 부모 노드 ≥ 자식 노드
∘ 최소 합(Min Heap) : 부모 노드 ≤ 자식 노드- 트라이(Trie)
∘ 문자열 탐색 및 저장에 특화된 트리 구조
- 용도
∘ 데이터 계층 표현 : 파일 시스템, 조직도
∘ 탐색 및 정렬 : 이진 탐색 트리
∘ 우선순위 처리 : 힙
∘ 문자열 검색 : 트라이
Red Black Tree
삽입 및 삭제 연산 시 트리의 균형을 유지하도록 설계된 자기 균형 이진 탐색 트리 입니다.
- 특징
- 노드는 빨간색 또는 검은색 입니다.
- 루프 노드는 항상 검은색입니다.
- 모든 리프노드는(NIL 노드)는 검은색 입니다.
- 리프 노드란, 자식 노드가 없는 NULL 노드를 의미
- 빨간색 노드의 자식은 항상 검은색 입니다.
- 빨간색 노드는 연속해서 나타날 수 없습니다.
- 어떤 노드에서 리프 노드까지의 경로에는 동일한 수의 검은색 노드가 존재해야 합니다.
- 이를 흑-높이(Black-Height)라고 한다
- 구조
∘ Red-Black Tree는 일반적인 이진 탐색 트리(BST) 와 비슷하지만, 노드에 색깔 정보를 추가해 균형 유지를 돕습니다.
∘ 트리의 높이를 O(log n)으로 유지하여 최악의 경우에도 효율적은 탐색이 가능
Hash Table
키-값(Key-Value) 쌍을 효율적으로 저장하고 검색하는 데이터 구조, 주어진 키(Key)를 해서 함수(Hash Function)를 통해 인덱스(Index)로 변환하여 데이터를 저장하거나 검색합니다.
- 구조
- 해시 함수
∘ 입력받은 키를 고정된 크기의 인덱스로 매핑
∘ 좋은 해시 함수는 빠르고 균등하게 분산되며, 충돌을 최소화- 버킷
∘ 데이터를 저장하는 배열의 각 슬롯
∘ 키의 해시 값에 따라 데이터가 저장됨- 충돌 처리
∘ 서로 다른 키가 같은 해시 값을 가질 때 발생
∘ 충돌을 해결하기 위한 방법
- 체이닝 : 각 버킷이 연결 리스트를 포함
- 오픈 어드레싱 : 충돌 시 빈 슬롯을 찾음
Graph
정점(Vertex, Node)과 간선(Edge)의 집합으로 구성된 데이터 구조로, 정점 간의 관계를 표현, 그래프는 현실 세계의 다양한 관계를 모델링하기에 적합하며, 네트워크, 경로 탐색, 데이터 연결 등에 활용
- 구성요소
- 정점
∘ 그래프의 구성 요소로, 데이터를 나타냄
∘ ex) 도시, 사람, 컴퓨터 등- 간선
∘ 정점 간의 연결을 나타냄
∘ 간선은 방향성이 있을 수도 없을 수도 있음
- 분류
- 방향 그래프
∘ 간선에 방향성이 있음
∘ ex) A -> B(A에서 B로의 단방향 연결)- 무방향 그래프
∘ 간선에 방향성이 없음
∘ ex) A <-> B(A와 B가 서로 연결)- 가중 그래프
∘ 간선에 가중치가 있음
∘ ex) 도로 거리, 네트워크 대역폭 등- 비가중 그래프
∘ 간선에 가중치가 없음- 순환 그래프
∘ 경로를 따라 시작점으로 다시 돌아올 수 있는 그래프- 비순환 그래프
∘ 순환이 없는 그래프
- 표현 방법
- 인접 행렬
- n X n 행렬로, 정점 간 간선을 나타냄
- 특징:
- 간선 존재 : 1, 없으면 0
- 공간 복잡도 :
- 인접 리스트
- 각 정점에 연결된 정점들의 리스트를 저장
- 특징
- 공간 복잡도 : O(V + E)(정점 : V, 간선 : E)
- 희소 그래프에 적합
- 탐색
- DFS(깊이 우선 탐색)
- 정점의 한 경로를 따라 가능한 멀리 탐색한 후, 다시 돌아와 다른 경로 탐색
- 구현 방법:
- 재귀
- 스택
- BFS(너비 우선 탐색)
- 시작 정점에서 가까운 정점부터 탐색
- 구현 방법:
- 큐
- 알고리즘
- 최단 경로 알고리즘
- 다익스트라 알고리즘 : 가중치가 양수인 그래프에서 최단 경로 찾기
- 밸만-포드 알고리즘 : 음수 가중치를 포함한 그래프에서 최단 경로 찾기
- 폴로이드-워셜 알고리즘 : 모든 정점 간 최단 경로 찾기
- 최소 신장 트리
- 크루스칼 알고리즘 : 간선을 정렬하여 최소 신장 트리 생성
- 프림 알고리즘 : 특정 정점에서 시작해 점진적으로 트리를 확장