
데이터베이스란
- 데이터를 저장하는 공간
- 엑셀의 표처럼 각 데이터의 종류와 속성에 따라 분류된 표 형태를 의미
각 용어정리
-
테이블 = 어떤 주제에 관련된 데이터들의 집합(ex. 유저 테이블, 게시글 테이블)
-
열 = 필드, 속성 등으로도 불리며 데이터의 속성의 단위를 의미
-
스키마 = 데이터베이스의 설계도 느낌. 각각 어떤 테이블들이 존재하고, 각 테이블마다 어떤 필드들이 있으며 해당 필드에서 어떤 값을 받는지 등을 간략하게 설명한 것
-
PK(Primary Key) = 주키 라고도 불리며 각 데이터가 가지는 고유한 id 값을 의미
-
외래 키 (Foreign key) = 테이블 간의 관계를 맺어주는 키로 다른 테이블의 정보를 가져올 때 그 테이블의 PK를 가져와서 현재 내 테이블의 Foreign key로 저장 (이후에 참조용으로 사용)
데이터베이스 예시
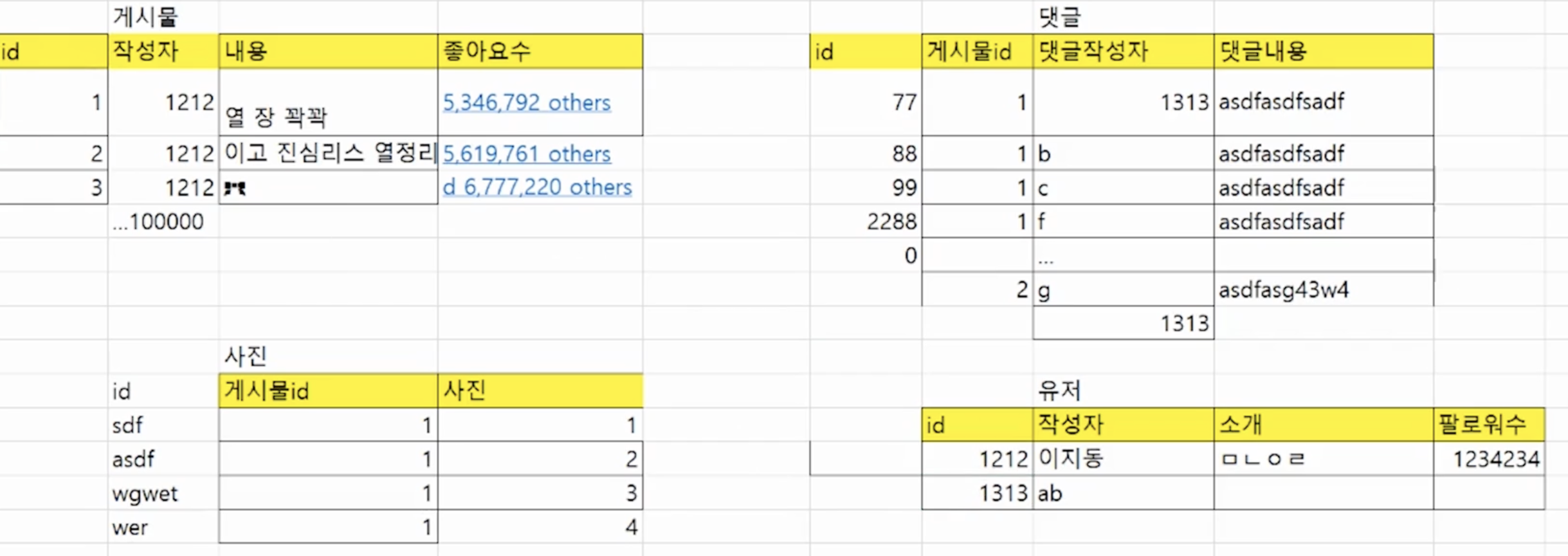
-
관계형 데이터베이스의 예시자료로 각 테이블들은 서로 관계성이 있음
-
각 테이블의 데이터들은 모두 고유한 id값(Primary key)를 가짐
-
테이블을 따로 분리해둠으로써 방대한 데이터를 효율적으로 분산하고, 각 id값을 이용해 다른 테이블의 데이터들을 불러오기 때문에 데이터의 변동이 생기더라도 한 번의 변경으로 모두 일괄적용되는 등의 효율적 관리가 가능
*ex. 데이터를 가져올 때 작성자 이름으로 가져오는 것이 아닌 해당 작성자에 부여된 고유 id값으로 가져오기에, 이후 이름을 변경하더라도 그냥 id값만 가져오면 자연스럽게 변경 적용된 작성자 이름 데이터를 그대로 불러올 수 있음 -
Foreign key를 이용해서 해당 id값으로 추가 데이터를 불러오는 식으로 활용 가능
ex. 게시물 테이블에서 각 게시물에 대한 Foreign key에 작성자 id값을 주어 해당 글의 작성자에 대한 다른 데이터를 가져오기 위한 참조가 가능
+a) 데이터베이스 정규화
정규화
- 정규화(Normalization)의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는 것. 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있음
- 테이블의 분해 방식에 따라 정규화 단계가 정의되어 있으며, 테이블을 어떤 식으로 분해하는지에 따라 정규화 단계가 달라짐
정규화 관련 예시자료
데이터베이스 종류 SQL vs NOSQL
SQL
-
sql 방식은 데이터를 쉽게 읽고 쓰는 것 보다는 무결성(Intergrity)을 중시함
*무결성 = 데이터가 중복없이 정확하며 일관성있고 누락이 없는 것
-
장점
-
데이터 중복 없이 저장하기에 수정이 필요할 경우 한번에 수정이 가능
-
외래 키를 사용하여 테이블 간 Join이 가능
-
데이터 처리 완결성 보장
- 단점
-
컬럼의 추가가 어려움 (기존에 없던 컬럼을 추가할 경우 이전의 데이터들에 임의로 직접적으로 값을 넣어줘야 하는 번거로움 존재)
-
관계가 복잡할수록 필요한 데이터를 읽고 불러오는 과정이 번거로움 (여러 테이블을 다 둘러봐야 함)
-
join을 많이 하게 될 경우, 매우 복잡한 쿼리문을 작성해야 할 수도 있음
NOSQL

-
데이터를 표 형식이 아닌 객체형식으로 저장
-
장점
-
스키마가 없기에 유연함. 데이터 추가의 유연성 (필드 추가)
-
어떠한 형식으로도 데이터를 저장할 수 있기에, 필요한 대로 저장해 읽어오는 속도가 빨라짐
- 단점
-
데이터를 중복되게 필요한 컬렉션 마다 저장할 수 있어 무결성이 깨질 수 있음
-
SQL 방식과 달리 수정 시, 모든 컬렉션에서 다 수정해줘야 한다.
