"가장 일반적이면서 중요한 인덱스 방법은 B-Tree다. 모든 애플리케이션을 만족시킬 수 있는 최적의 메모리 구조란 존재하지 않지만, 그래도 하나를 선택해야 한다면 B-Tree를 선택할 것이라는 뜻이다." -Christopher J. Date [데이터베이스 시스템 6판]
인덱스와 B-tree
인덱스의 구조에 따른 분류
- B-Tree
- 비트맵
- 해시
B-Tree ( 만능형 )
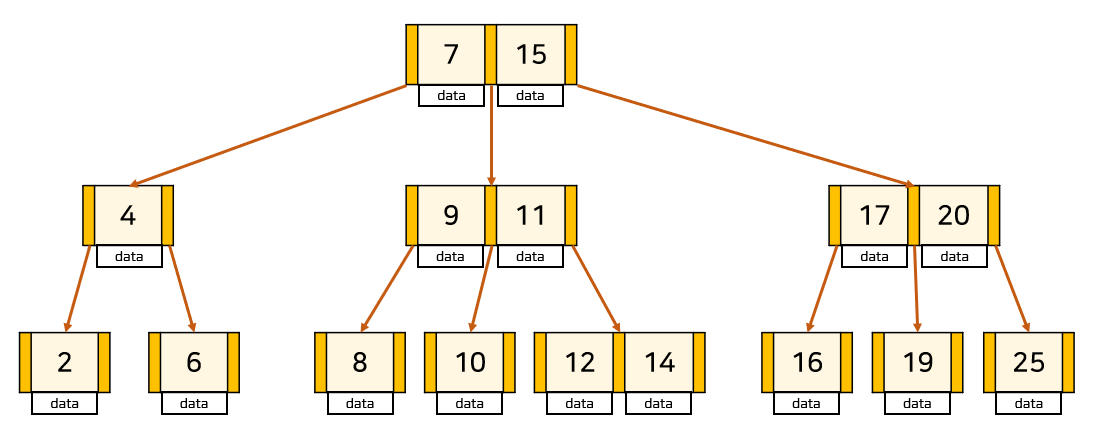
- 데이터를 트리 구조로 저장하는 형태의 인덱스이다.
- 균형잡힌 뛰어난 범용성을 인정받아 가장 많이 사용된다.
- [CREATE INDEX] 구문을 실행하면 모든 DBMS에서 B-Tree 인덱스가 만들어진다.
B-Tree가 검색 알고리즘으로서는 뛰어나게 성능이 좋은 편이 아니지만, 군형이 잘 잡혀있기 때문에 RDB에서 많이 사용된다.
대부분의 데이터베이스에서는 트리의 리프 노드에만 키값을 저장하는 B+Tree라는
B-Tree의 수정 버전을 채택한다.
B+Tree의 검색 성능이 뛰어난 이유
- 루트와 리프의 거리를 가능한 일정하게 유지하려 한다.
-> 균형이 잘 잡혀 검색 성능이 안정적이다. - 트리의 깊이도 대게 3~4 정도의 수준으로 일정하다.
- 데이터가 정렬 상태를 유지하므로 이분 탐색을 통해 검색 비용을 크게 줄일 수 있다.
- 집약하는 함수 등에서 요구되는 정렬을 하지 않은 채 넘어갈 수 있다.
기타 인덱스
비트맵 인덱스
- 데이터를 비트 플래그로 변환해서 저장하는 형태
- 카디널리티가 낮은 필드에 대해 효과를 발휘한다.
- 갱신 시 오버헤드가 너무 크기 때문에 빈번한 갱신이 일어나지 않을 때 사용
해시 인덱스
- 키를 해시 분산해 등가 검색을 고속으로 실행하고자 만들어진 인덱스
- 등가 검색 외에는 효과가 거의 없고 범위 검색을 할 수 없다.
-> 거의 사용되지 않고, 지원하는 구현도 일부에 불과하다.
인덱스를 활용하는 방법
1. 카디널리티와 선택률
- 어떤 필드에 대해 인덱스를 작성할 것인지 기준이 되는 요소
- 카디널리티가 가장 높은 필드는 모든 레코드에 다른 값이 들어가있는 유일키 필드이다. ( 참고 -> 카디널리티가 높다 : 중복도가 낮다 )
- 선택률 : 특정 필드값을 지정했을 때 테이블 전체에서 몇 개의 레코드가 선택되는지
클러스터링 팩터 ( clustering factor )
인덱스의 성능을 결정하는 요인
- 저장소에 같은 값이 어느 정도 물리적으로 뭉쳐 존재하는지를 나타내는 지표
- 높을수족 분산되어 있고, 낮을수록 뭉쳐있다.
-> 인덱스로 접근할 때 특정 값에만 접근하는 경우가 많아 클러스터링 팩터가 낮을수록 접근할 데이터양이 적어 좋다.
인덱스 사용 여부 판단
- 카디널리티가 높을 것
- 선택률이 낮을 것 ( 대체로 5 ~ 10 % ) -> 5% 미만이면 인덱스를 작성할 가치가 있다.
선택률이 10%보다 높으면 테이블 풀 스캔을 하는 편이 더 빠를 가능성이 크다.
인덱스로 성능 향상이 어려운 경우
인덱스 설계란, 테이블 정의와 SQL만 봐서 할 수 있는 작업이 아니다.
SQL의 검색 조건과 결합 조건을 바탕으로 데이터를 효율적으로 압축할 수 있는 조건을 찾아야한다. -> 구문과 검색 키 필드의 카디널리티를 알아야 한다.
1. 압축 조건이 존재하지 않을 경우
SELECT order_id, receive_date
FROM Orders;실행 계획을 보지 않아도 테이블 풀 스캔이다.
레코드를 압축하는 WHERE 구가 없으므로 인덱스로 작성할만한 필드도 존재하지 않는다.
2. 레코드를 제대로 압축하지 못하는 경우
SELECT order_id, receive_date
FROM Orders
WHERE process_flg = '5';process_flg의 분포
- 1 : 200만 건
- 2 : 500만 건
- 3 : 500만 건
- 4 : 500만 건
- 5 : 8,300만 건
선택률이 83%로 굉장히 높은 수치이다.
인덱스가 제대로 작동하려면 '레코드를 크게 압축할 수 있는 검색 조건'이 있어야 한다.
3. 입력 매개변수에 따라 선택률이 변동하는 경우
입력 매개변수에 따라 0.01% ~ 10%의 선택률 차이가 난다고 가정했을 경우
성능 향상을 기대하기 어렵다.
10%일 경우 테이블 풀 스캔을 하고, 0.01%일 경우에는 인덱스 스캔을 하면 좋겠지만, 옵티마이저는 그러지 못한다.
3. 인덱스를 사용하지 않는 검색 조건
압축할 검색 조건이 있지만, 인덱스를 사용할 수 없는 타입일 경우
중간 일치, 후방 일치의 LIKE 연산자
SELECT order_id
FROM Orders
WHERE shop_name LIKE '%대공원%';선택률은 0.005%로 가정한다.
이 경우에 shop_name 필드에 인덱스를 작성하면 효율적인 검색이 가능할까?
LIKE 연산자를 사용하는 경우 인덱스는 전방 일치('대공원%')에만 적용할 수 있다.
색인 필드
색인 필드로 연산하는 경우 인덱스를 사용할 수 없다.
SELECT *
FROM SomeTable
WHERE col_1 * 1.1 > 100;그렇지만, 검색 조건의 우변에 식을 사용할 때는 인덱스가 사용된다.
이렇게 쓰면 됨
WHERE col_1 > 100/1.1그 외
- IS NULL을 사용하는 경우
- 색인 필드에 함수를 사용하는 경우
- 부정형을 사용하는 경우
인덱스를 사용할 수 없을 경우 대처법
UI 설계로 처리
- 점포 ID로 검색하면 반드시 주문일도 함께 입력해야하는 등의 입력제한을 둔다.
데이터 마트
간단하게 마트 또는 개요 테이블(Summary Table)이라고 한다.
- 특정한 쿼리에서 필요한 데이터만을 저장하는, 작은 크기의 테이블이다.
- 원래 테이블의 부분 집합(또는 서브셋)
- 접근 대상 테이블의 크기를 작게 해서 I/O 양을 줄이는 것이 데이터 마트의 목적이다.
데이터 마트 선택 시 주의점
데이터 신선도
- 동기 시점의 문제
- 원본 테이블의 복사본 이므로 원본 테이블에서 데이터를 동기화해야 한다.
동기사이클이 짧다 : 신선도 ↑, 성능 ↓
-> 데이터 신선도가 중요한 경우라면 데이터 마트를 채택할 수 없다.
데이터 마트 크기
테이블의 크기를 작게 해 I/O 양을 줄이는 것이 목적이므로 원래의 테이블에서 크기를 딱히 줄일 수 없다면, 소용없다.
데이터 마트 수
데이터 마트 수가 100개를 넘는 경우도 있다.
-> 어떤 처리에 사용되는지가 혼동되면서 더 이상 사용하지 않는데도 쓸데없는 동기화가 일어나는 '좀비 마트'가 생기거나, 관리가 불가능해 질 수 있다.
인덱스 온리 스캔으로 대처
접근하려는 대상의 I/O 감소를 목적으로 한다는 점에서는 데이터 마트와 같다.
인덱스를 사용한 고속화 방법이지만, 기존 인덱스와는 사용 방법이 많이 다르다.
SELECT order_id, receive_date
FROM Orders;풀 스캔을 할 때 검색 대상을 테이블이 아닌 인덱스로 바꿀 수 있다.
CREATE INDEX CoveringIndex ON Orders (order_id, receive_date);order_id, receive_date는 SELECT 구문에 포함되어 있으므로, 일반적으로 인덱스의 필드 후보로 되지 않는다.
그러나, 2개의 필드를 커버하는 인덱스가 존재하면, 테이블이 아닌 인덱스만을 스캔 대상으로 하는 검색을 사용할 수 있다. -> INDEX ONLY SCAN
-> 이러한 인덱스를 커버링 인덱스(Covering Index) 라 한다.
장점
- 인덱스는 테이블 필드의 부분 집합만 저장하므로 원래 테이블에 비해 굉장히 작다.
- 데이터 마트를 만들 시 애플리케이션도 수정해야 하지만, 인덱스를 사용할 경우 그럴 필요가 없다.
로우(레코드) 지향 저장소의 DBMS에 유사적으로 컬러 기반 저장소를 실현하는 것
