DBMS
1.[ PostgreSQL ] Vacuum 최적화
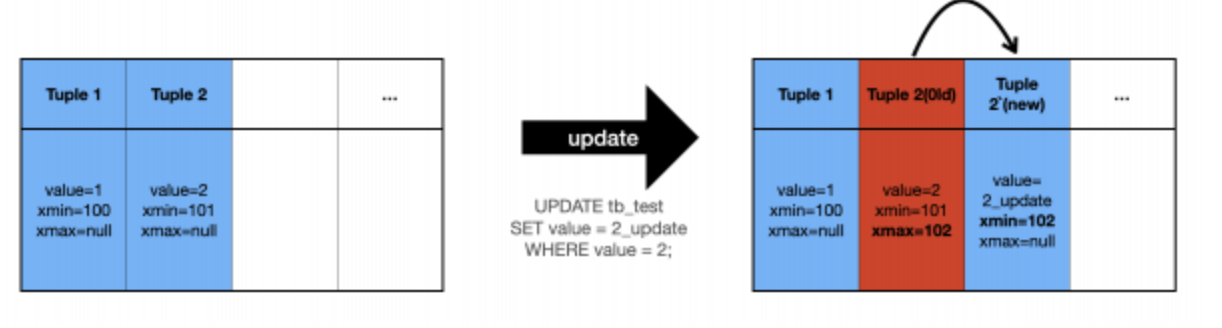
PostgreSQL은 다른 RDBMS와는 다르게 Vacuum이라는 개념이 존재한다.간단히 말하자면 더 이상 사용되지 않는 데이터들을 정리하는 명령이다.DB에 데이터는 물리적으로 디스크에 저장되게 된다. 그러나, 이 데이터를 UPDATE or DELETE 시에 디스크에
2.[DB] 트랜잭션 관리 전략

DBMS는 데이터를 고정 길이의 페이지로 저장하며, 디스크에서 읽거나 쓸 때에 페이지 단위로 입출력이 이루어진다.페이지들을 관리하는 모듈을 페이지 버퍼 관리자 or 버퍼 관리자 라고 한다.질의 처리기 ( Query Processor ) 와 저장 시스템 ( Storage
3.[DB] Replication & Clustering
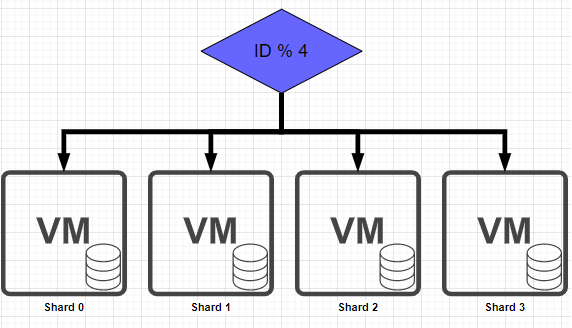
여러 개의 DB를 수평적인 구조로 확장 ( Active - StandBy )노드들 간의 데이터를 동기화하여 일관성 있는 데이터를 유지할 수 있다1개의 노드가 죽어도 다른 노드로 운영 가능장애가 전파된 경우 처리가 까다로움여러 개의 DB를 수직적인 구조로 확장 ( Mas
4.[ MySQL ] Thread
MySQL에서는 각 요청을 어떻게 처리하는지 정리해 보고자 한다. Real MySQL 8.0 책을 읽고 정리한 내용이다. MySQL 스레딩 구조 프로세스 기반이 아닌 스레드 기반으로 작동 Foreground / Background Thread로 구분 >전통적인 스
5.[ MySQL ] InnoDB
InnoDB MySQL 스토리지 엔진 중 하나. 스토리지 엔진 중 거의 유일하게 레코드 기반의 잠금 제공한다. 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어나다. PK에 의한 클러스터링 PK를 기준으로 클러스터링되어 저장 PK 값의 순서대로 디스크에 저장
6.[ MySQL ] Phantom READ
Transaction 격리 수준들을 살펴 보면, Repeatable Read 격리 수준에서 Phantom Read 문제가 발생한다. 그러나, MySQL에서 InnoDB 엔진을 사용할 경우, Repeatable Read 격리 수준에서 Phantom Read가 발생하지
7.Index (기본 / 인덱스 스캔 방향)
책의 목차가 인덱스에 많이 비유된다.목차를 통해 알아낼 수 있는 페이지 번호는 데이터 파일에 저장된 레코드의 주소에 비유된다.DBMS도 데이터베이스 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸린다.컬럼의 값과 해당 레코드가 저장된 주소를 K
8.[ MySQL ] Clustering Index
클러스터링이란 여러 개를 하나로 묶는다는 의미로 주로 사용된다.MySQL의 클러스터링은 테이블의 레코드를 비슷한 것(프라이머리 키를 기준으로)들끼리 묶어서 저장하는 형태로 구현→ 주로 비슷한 값들을 동시에 조회하는 경우가 많다는 점에 착안한 것이다.MySQL의 클러스터
9.[ MySQL ] 쿼리 실행 계획 관련
풀 테이블 스캔 : 인덱스를 사용하지 않고 테이블의 데이터를 처음부터 끝까지 읽어서 작업을 처리풀 테이블 스캔을 선택하는 조건레코드 건수가 너무 작아, 인덱스를 읽는 것 보다 풀 테이블 스캔이 빠른 경우일반적으로 페이지 1개로 구성인덱스 레인지 스캔을 사용할 수 있는
10.[SQL 레벨업] Ch.10 인덱스 사용
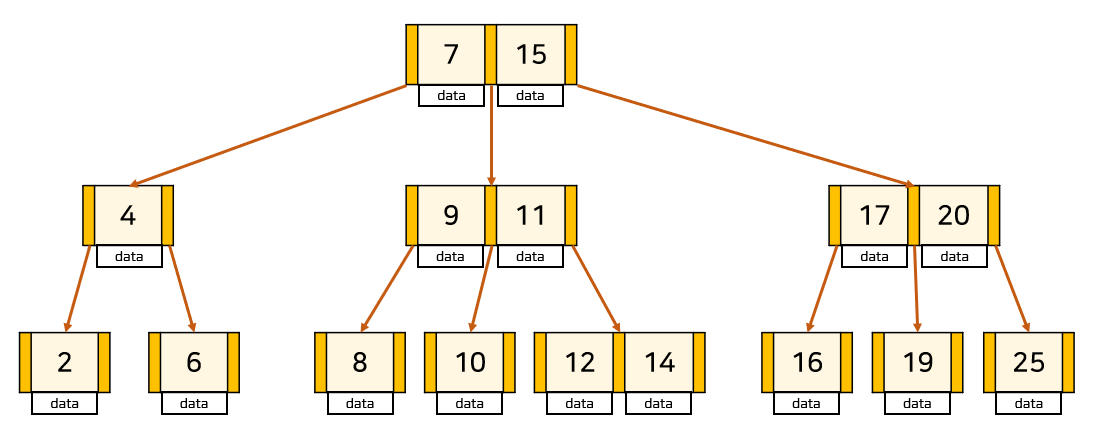
"가장 일반적이면서 중요한 인덱스 방법은 B-Tree다. 모든 애플리케이션을 만족시킬 수 있는 최적의 메모리 구조란 존재하지 않지만, 그래도 하나를 선택해야 한다면 B-Tree를 선택할 것이라는 뜻이다." -Christopher J. Date 데이터베이스 시스템 6판인
11.[SQL 레벨업] Ch.1 DBMS 아키텍처
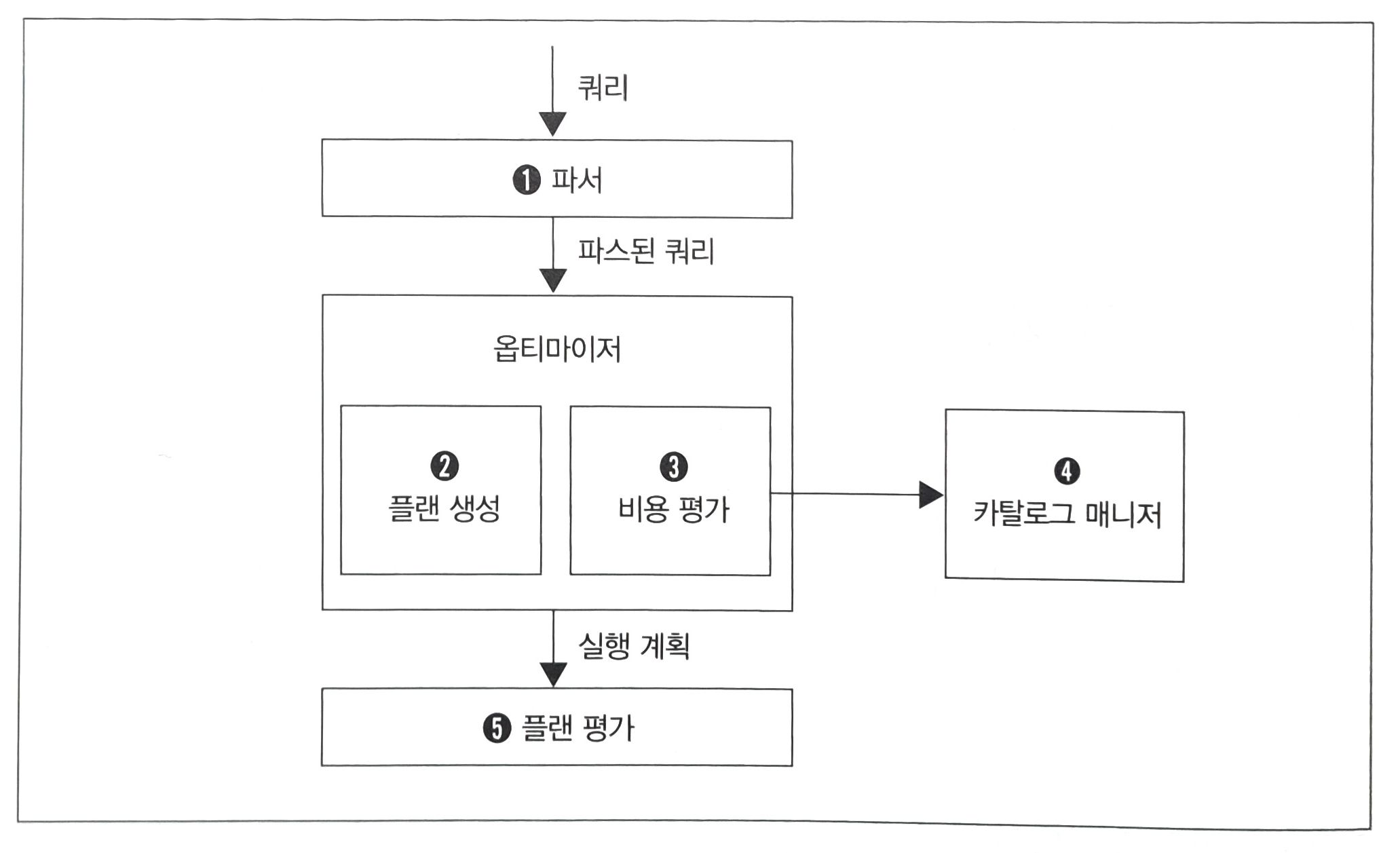
입력받은 SQL을 분석하고, 어떤 순서로 기억장치의 데이터에 접근할지 결정한다.이때 결정되는 계획을 '실행 계획'이라고 부른다.실행 계획에 기반을 둬서 데이터에 접근하는 방법을 '접근 메서드(access method)'라고 부른다.쿼리 평가 엔진 = 계획을 세우고 실행
12.[SQL 레벨업] Ch.3 SQL의 조건 분기
Ch.2의 경우 기본적인 SQL을 설명하는 단원이라 스킵하였다.UNION은 외부적으로 하나의 SQL 구문을 실행하는 것처럼 보이지만, 내부적으로는 여러 개의 SELECT 구문을 실행하는 실행 계획으로 해석된다. 따라서 I/O 비용이 크게 증가한다.UNION을 사용해도
13.[DB] 트랜잭션의 ACID 속성
트랜잭션(Transaction)이란, 데이터베이스의 상태를 변화시키기 위해서 수행하는 작업의 단위를 뜻함데이터베이스의 상태를 변경시킨다는 것은 SELECT, UPDATE, INSERT, DELETE와 같은 질의어(SQL)을 통해 데이터베이스에 접근하는 것을 의미한다.
14.[DB] Design Principles
좋은 설계를 위해서 지켜야 하는 것이 무엇이 있을까?FaithfulnessAvoiding redundancySimplicity countsChoosing the right relationshipsPicking the right kind of element디자인은 구체화
15.[SQL 레벨업] Ch.4 집약과 자르기
집약 함수의 종류에는 다음 5가지 종류가 있다.5가지에 대한 설명은 다들 알 것이라고 생각하고 생략하겠다.COUNTSUMAVGMAXMINGROUP BY를 사용해 집약을 수행할 경우에 정렬보다 해시 알고리즘을 많이 사용한다.경우에 따라서 정렬을 사용하기도 하지만, 보다
16.[SQL 레벨업] Ch.5 반복문
SQL은 일부러 반복문을 언어 설계에서 제외했다.일반적으로 SQL에서 반복문이 지원되지 않아, 다음과 같은 방식으로 프로그래밍을 하는 경우가 많다.레코드에 하나씩 접근하는 SELECT 구문을 반복해서 사용한다.호스트 언어에서 반복문을 처리한 뒤 테이블에 갱신한다.그렇지
17.[SQL 레벨업] Ch.6 결합
CROSS Join, INNER JOIN, OUTER JOIN에 대한 내용은 생략하겠다.옵티마이저가 선택 가능한 결합 알고리즘의 종류Nested LoopsHashSort Merge알고리즘을 선택하는 기준은 데이터의 크기, 결합 키의 분산이다.가장 기본적으로 사용하는 것
18.[SQL 레벨업] Ch.7 서브쿼리
서브쿼리란 SQL 내부에서 작성되는 일시적인 테이블이다. 테이블과 서브쿼리는 기능적인 관점에서 차이가 없기 때문에 SQL은 두 가지를 모두 같은 것으로 취급한다. 테이블 : 영속적인 데이터를 저장 뷰 : 영속적이지만 데이터는 저장하지 않음. (접근할 때마다 SELECT
19.[SQL 레벨업] Ch.8 SQL의 순서 (깨어나는 절차 지향)
레크드에 순번을 붙이는 방법은 앞에서 많이 정리해서 생략하고 응용부터 가도록 하겠다.양쪽 끝에서 숫자 세기오름차순, 내림차순한 뒤 같은 속도로 움직인다.그때 lo와 hi가 똑같은 시점이 중앙값이다.그런데 왜 lo+1, lo-1 도 있을까? -> 짝수일 경우 2개의 평균
20.[SQL 레벨업] Ch.9 갱신과 데이터 모델 - (1)
SQL의 대부분은 SELECT 구문이라고 할 수 있다. 반면 UPDATE, DELETE라는 갱신을 위한 기능은 상세하게 다뤄볼 기회가 거의 없다. 그 결과 갱신과 관련된 SQL 구문은 검색 SQL 구문 이상으로 비효율적으로 성능이 좋지 않은 방향으로 작성된다. 이번 장