
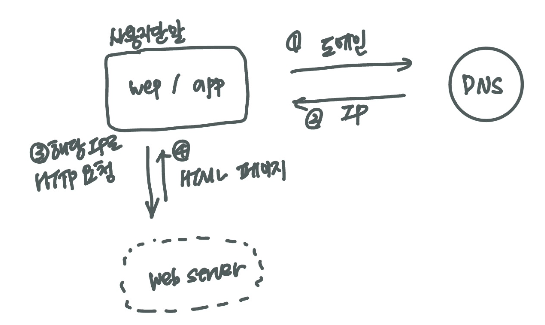
단일서버
복잡한 시스템을 구상하기 전, 기본적으로 다음과 같은 시스템 구조로 시작할 수 있다.
데이터 베이스
데이터베이스 종류
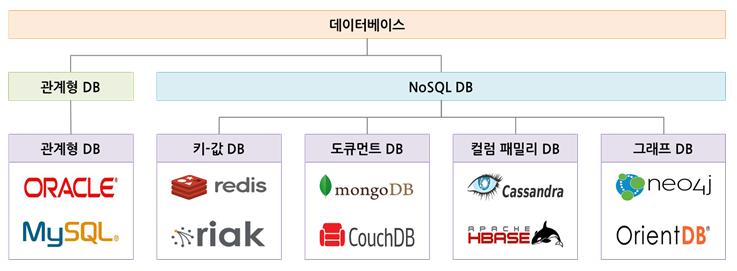
관계형 DB
- 자료를 테이블과 열, 칼럼으로 표현
- SQL을 사용해 데이터를 INSERT, DELETE, UPDATE, JOIN 등을 할 수 있다.
NoSQL DB
- 키-값 저장소, 그래프 저장소, 칼럼 저장소, 문서 저장소가 대표적으로 있다.
언제 NoSQL DB를 사용할까?
- 아주 낮은 응답 지연시간이 요구될때 (RDB에서 Join을 통해 시간이 오래걸릴 수 있음)
- 다루는 데이터가 비정형(unstructured) 이라 관계형 데이터가 아님 (이미지, 비디오, 웹페이지와 같은 경우)
- 데이터(JSON, YAML, XML 등)를 직렬화하거나 역직렬화 할 수 있기만 하면됨
-> 데이터 직렬화 : 데이터를 JSON, YAML, XML과 같은 형식으로 변환
-> 데이터 역직렬화 : 직렬화된 데이터를 원래의 데이터 형태로 복원하는 과정
수직적 규모 확장 vs 수평적 규모 확장
수직적 규모 확장
- 서버의 성능 향상 (더 좋은 CPU, 더 좋은 RAM)
- 한계가 있음. 무한대로 CPU, RAM을 추가할 수 없다.
- 하나의 서버로 운영되어서 자동복구(failover)/다중화(redundancy) 방안이 없다. -> 서버에 장애가 발생하면 웹사이트/앱은 완전히 중단됨
수평적 규모 확장
- 서버의 대수를 증가
-> 로드밸런서 도입
-> 데이터베이스 다중화
로드밸런서
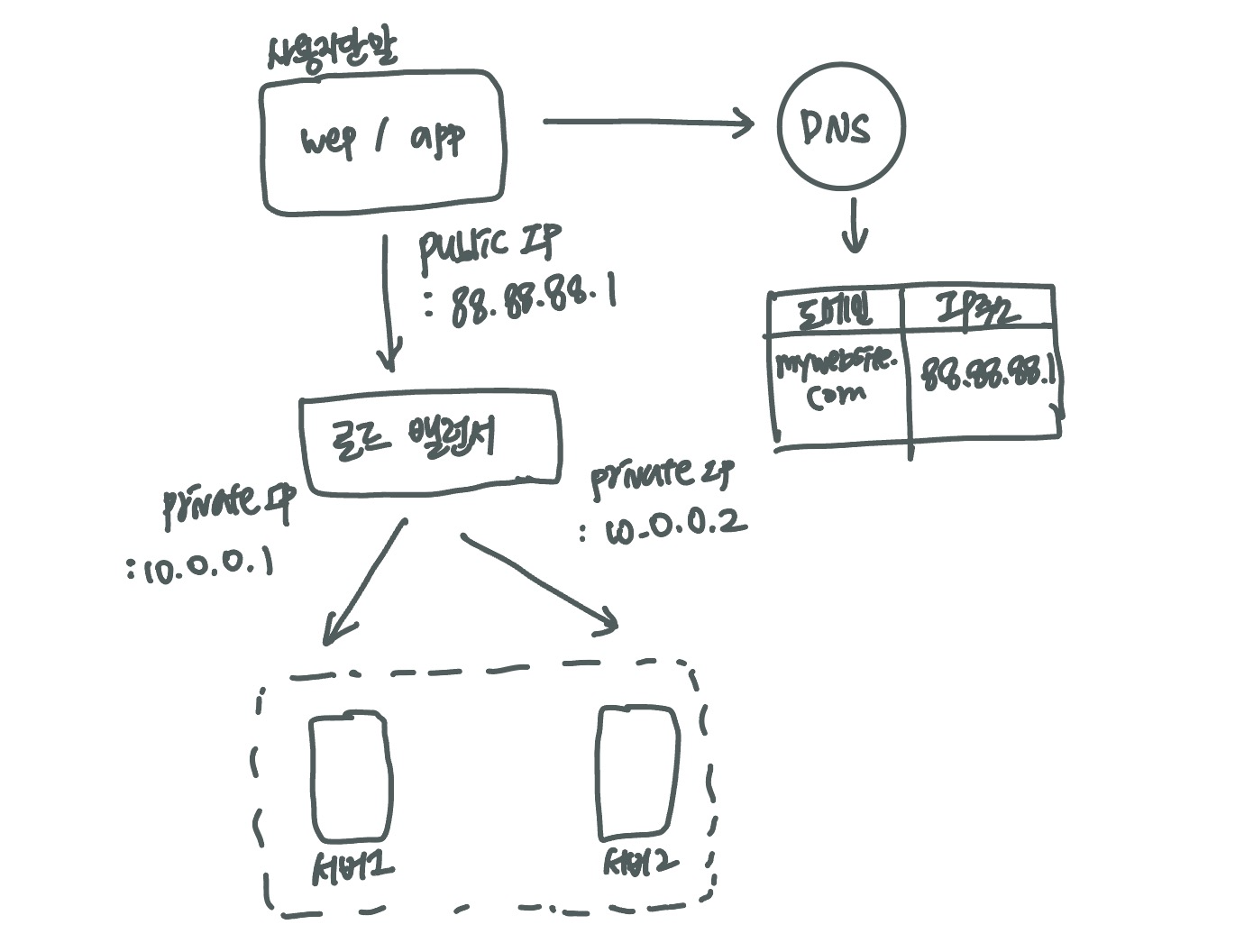
- 로드밸런서의 public IP 주소로 접속
-> 클라이언트는 직접 웹 서버로 접근하지 않는다.
-> 서버간 통신에는 private IP 주소 이용
(private IP : 같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있음) - 이점
-> 서버 1이 다운되어도 서버2를 사용하면 됨. 웹 사이트 전체가 다운되는 일이 방지된다.
-> 부하를 나누기 위해 새로운 서버 추가 가능
데이터베이스 다중화
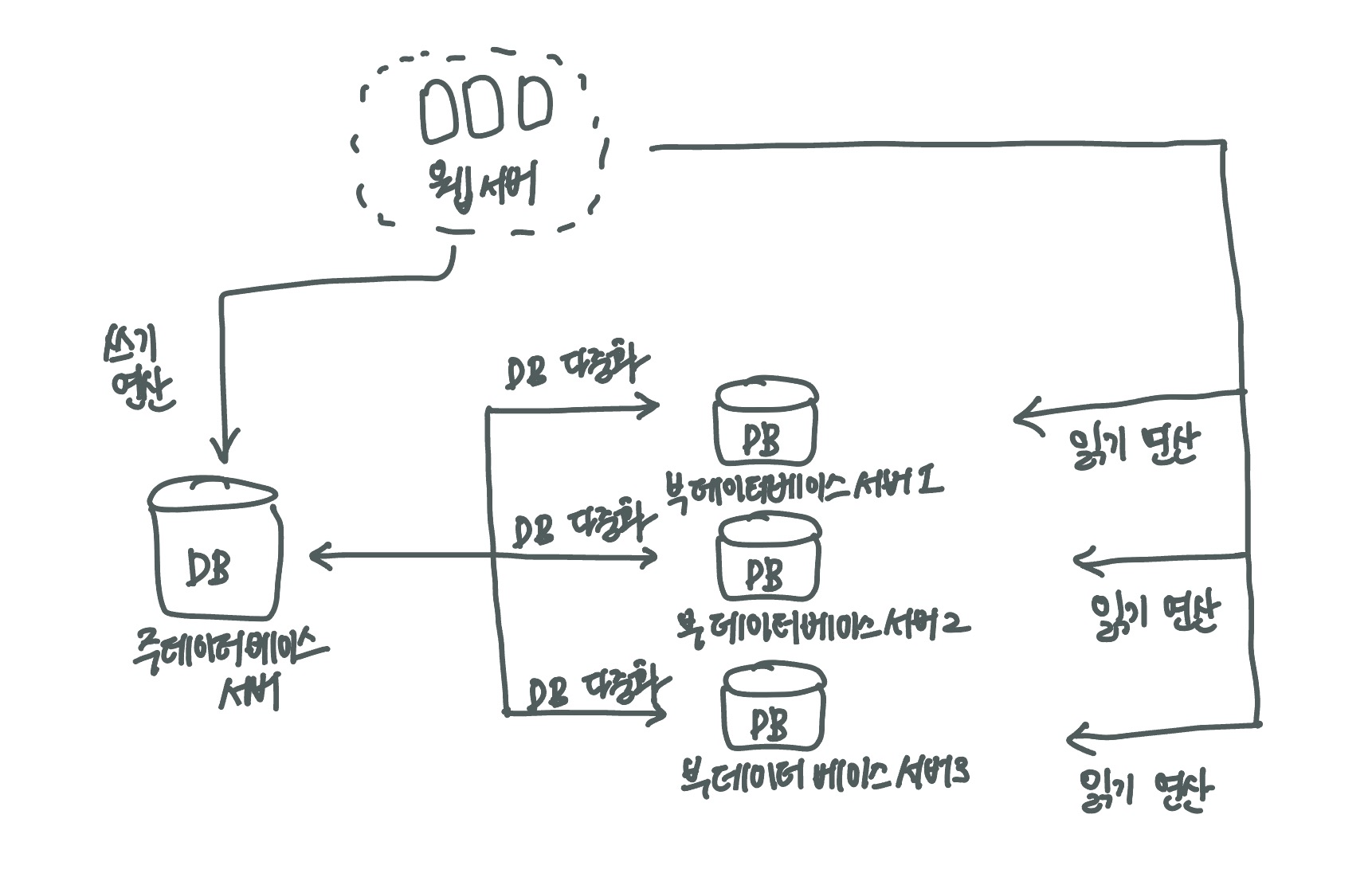
-
주(master)-부(slave) 관계 설정
-> 주데이터 서버 : 쓰기 연산 (write operation)
-> 부데이터 서버 : 읽기 연산 (read operation) -
이점
-> 더 나은 성능 : 쓰기,읽기 연산을 분산시켜 처리할 수 있는 쿼리가 늘어나므로 성능이 좋아진다.
-> 안전성(reliability) : 데이터를 지역적으로 떨어진 여러 장소에 다중화를 시켜서 자연재해 등으로 데이터 베이스 서버 일부가 다운되어도 데이터는 보존된다.
-> 가용성(availability) : 하나의 데이터베이스 서버에 장애가 발생해도 다른 서버에 있는 데이터를 가져와 계속 서비스 가능 -
대응방법
-> 부서버가 한대인데 다운 : 주서버가 임시적으로 읽기연산 받음. 이후 새로운 부서버가 장애 서버를 대체
-> 부서버 여러대인 경우 다운 : 다른 부서버가 읽기연산 처리. 이후 새로운 부서버가 장애 서버를 대체
-> 주서버 다운 : 만약 하나의 부서버만 있다면 이게 주서버가 되면서 모든 연산 처리. 이후 새로운 부서버 추가. 부서버 데이터가 최신 상태가 아니면 복구 스크립트 추가
(다중마스터, 원형다중화를 도입하면 이런 상황 대처할 수 있음)
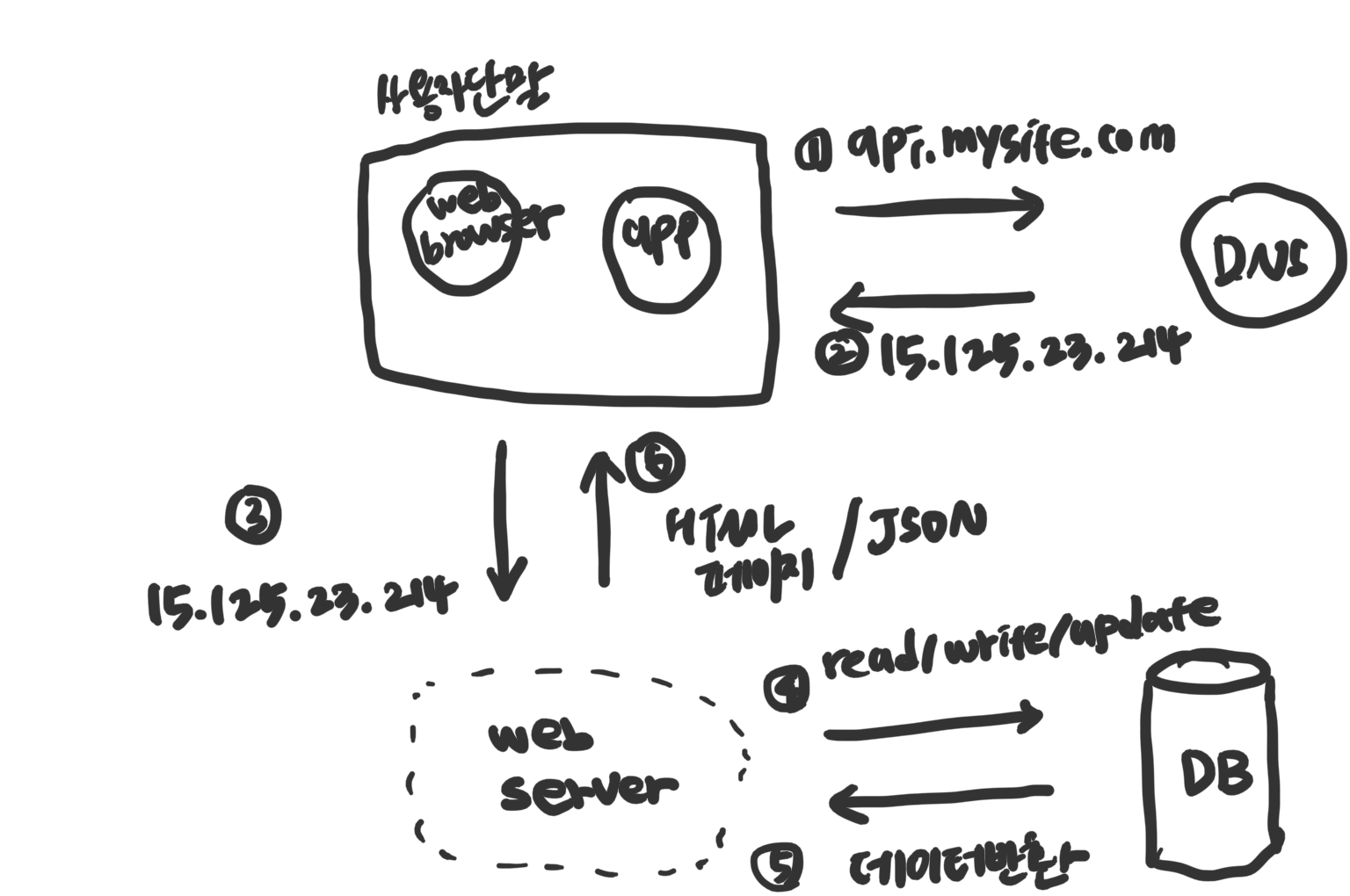
캐시
값비싼 연산결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소
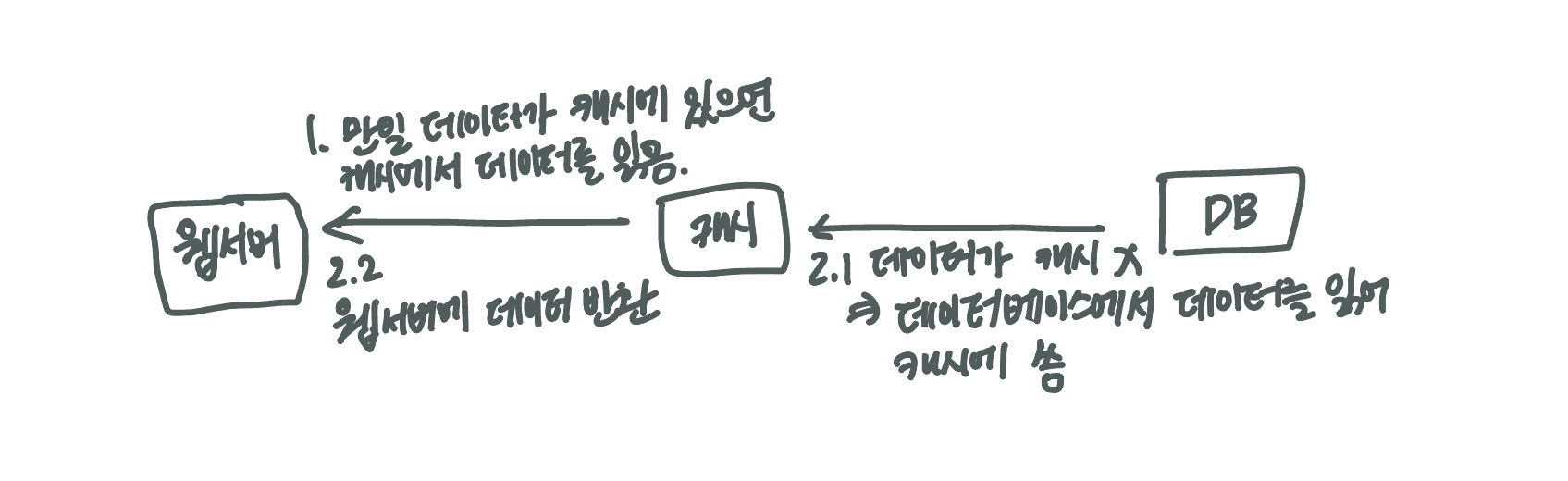
- 이를 읽기 주도형 캐시 전략 이라고 한다.
- 캐시할 데이터 종류, 크기, 액세스 패턴에 맞는 캐시 전략을 선택하면 된다.
- 캐시 서버는 주로 API를 이용해 사용한다.
주의할점
- 데이터 종류 : 캐시는 휘발성 메모리에 두어서 영속적으로 보관할 데이터는 저장하지 않는다.
- 만료 (expire) 정책 : 만료된 데이터는 캐시에서 삭제된다. 따라서 캐시 데이터 관리를 위해 만료 정책이 필요하다.
-> 만료기한 짧음 : 데이터베이스를 너무 자주 읽는다.
-> 만료기한 너무 김 : 원본 데이터와 차이가 날 수 있다. - 일관성 : 저장소의 원본은 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않을때 일관성 깨질 수 있음
- 장애대응 : 캐시 서버 한대만 두면 단일 장애 지점 (Single Poing Of Failure, SPOF)가 되어버릴 수 있다. -> 캐시 서버 분산
- 캐시 메모리
-> 너무 작음 : 데이터가 너무 자주 캐시에서 밀려난다. 성능 떨어짐
-> 따라서 캐시 메모리를 과할당(overprovision)하는게 좋다. - 데이터 방출(eviction)정책 : 캐시가 꽉차면 데이터 방풀을 해야한다.
-> LRU(Least Recently Used) : 마지막으로 사용된 시점이 가장 오래된 데이터를 내보내는 정책
-> LFU(Least Frequently Used) : 사용 빈도가 가장 낮은 데이터를 내보내는 정책
-> FIFO(First In First Out) : 가장 먼저 들어온 데이터를 가장 먼저 내보내는 정책
콘텐츠 전송 네트워크 (CDN)
- 정적 콘텐츠 전송 시 사용하며, 지리적으로 분산 된 서버의 네트워크
- 이미지, 비디오, CSS, JavaScript 파일 등 캐시
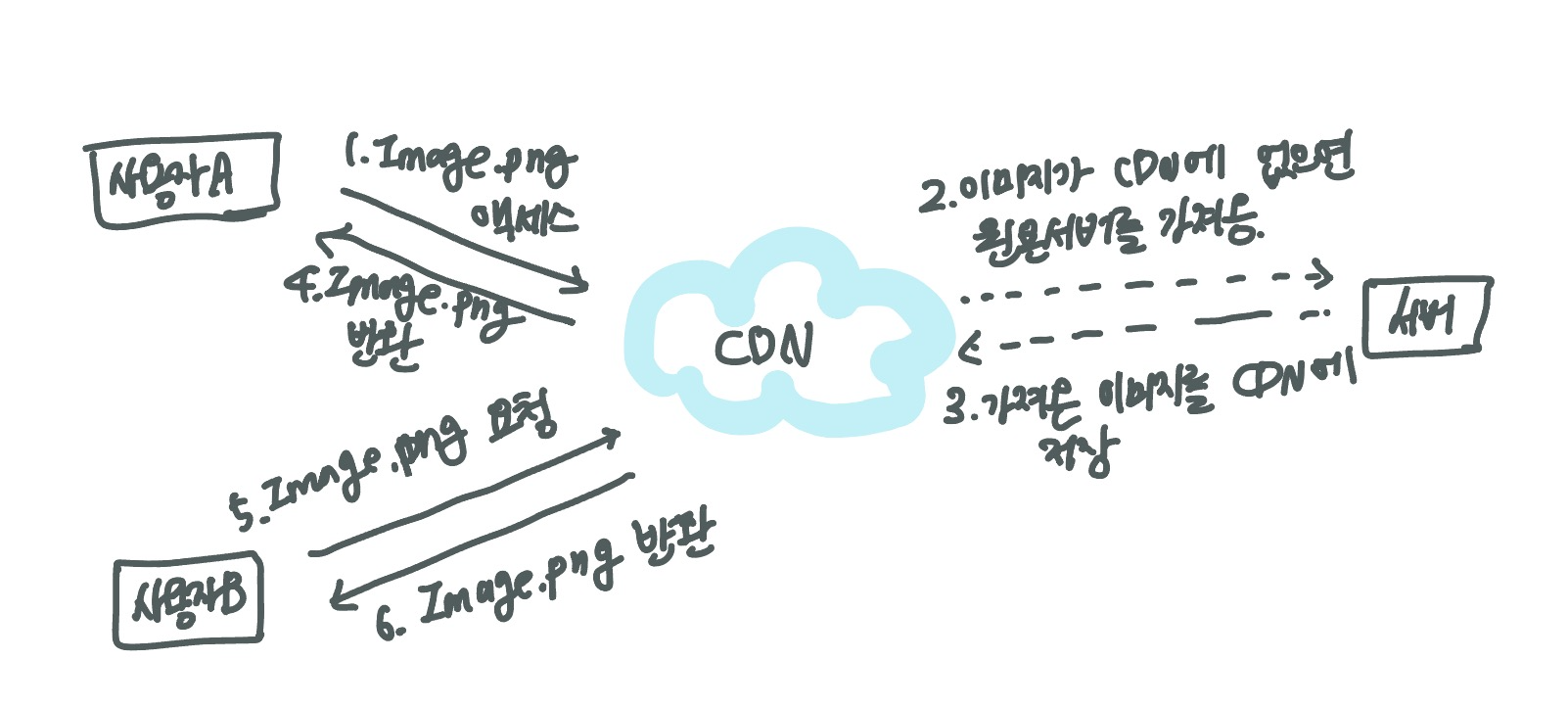
고려사항
- 비용 : 보통 third-party providers에 의해 운영. 따라서 자주 사용되지 않는 콘텐츠는 CDN에서 제외
- 적절한 만료 시한 설정 : time-sensitive 콘텐츠는 만료 시점을 잘 정해야한다. 너무 길면 콘텐츠의 신선도가 떨어지고, 너무 짧으면 원본 서버에 빈번히 접속함
- CDN 장애 대처 : 클라인트 측에서 CDN이 장애나면 원본 서버로부터 데이터를 가져오도록 구성할 수 있다.
- 콘텐츠 무효화
-> CDN 서비스 사업자가 제공하는 API를 이용해 콘텐츠 무효화
-> 콘텐츠의 다른 버전을 서비스하도록 object-versioning 이용. URL 마지막에 버전 번호를 인자로 주면됨. (ex : image.png?v=2)
무상태(stateless) 웹 계층
웹 계층을 수평적으로 확장하는 방법
-> 상태 정보(사용자 세션 데이터와 같은)를 웹 계층에서 제거
-> 상태정보를 관계형 데이터베이스나 NoSQL, Memcached/Redis 같은 캐시 시스템에 보관하고 필요할때 갖고옴
데이터 센터
- 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내된다. 이것을 지리적 라우팅이라고 함.
(geoDNS : 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정할 수 있도록 하는 DNS 서비스) - 데이터 센터를 이용하면 하나에 시미각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
고려사항
- 트래픽 우회 : 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야함. 지리적으로 고려하는 건 GeoDNS 이용
- 데이터 동기화(synchronization) : 한곳에 장애가 났을때 다른곳에서 동일한 데이터를 사용하기 위해서는 데이터를 여러 데이터센터에 다중화를 한다.
- 테스트와 배포 : 자동화된 배포 도구는 모든 데이터 센터에 동일한 서비스가 설치되도록 하는데 중요한 역할
메세지 큐
- 메세지의 무손실을 보장하는 비동기 통신(asynchronous communication)을 지원하는 컴포넌트이다.
- 서비스 또는 서버 간 결합이 느슨해져서 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구상하기 좋다.
- 사용예
-> 사진 보정 애플리케이션 : 보정은 시간이 오래 걸리니깐 비동기적으로 처리하면 편하다.
로그, 메트릭 그리고 자동화
- 로그 : 에러 로그를 모니터링 하면 시스템의 오류와 문제들을 보다 쉽게 찾아낼 수 있다. 로그를 단일 서비스로 모아주는 도구를 사용하면 더 편리하게 검색 해볼 수 있다. (ex : Avo)
- 메트릭 : 사업현황에 관한 유용한 정보 + 시스템의 현재 상태 파악
-> 호스트 단위 메트릭 : CPU, 메모리, 디스크 I/O에 관한 메트릭
-> 종합 메트릭 : 데이터베이스 계층의 성능, 캐시 계층의 성능
-> 핵심 비지니스 메트릭 : 일별 능동 사용자, 수익, 재방문 - 자동화
-> 지속적 통합 (Continuous Integration)을 도와주는 도구를 활용하면 개발자가 만드는 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어 문제를 쉽게 감지
-> 빌드, 테스트, 배포 등의 절차를 자동화할 수 있어서 개발 생산성 향상
데이터베이스의 규모확장
수직적 확장
- 기존 서버에 고성능 자원 증설
문제점
- 데이터베이스 서버 하드웨어에는 한계가 있다.
- SPOF(Single Poing Of Failure)로 인한 위험성
- 비용이 많이 든다.
수평적 확장
샤딩
- 대규모 데이터베이스를 shard 라고 부르는 작은 단위로 분할하는 기술
- 모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
고려사항
- 데이터의 재샤딩해야하는 경우
-> 데이터가 너무 많아져서 하나의 샤드로는 더이상 감당하기 어려울때
-> 샤드 간 데이터 분포가 균등하지 못해서 어떤 샤드에 할당된 공간소모가 다른 샤들에 비해 빨리 진행될때 (샤드 소진). 샤드 키 변경하고 데이터 재배치 해야됨 - 유명인사 문제
-> 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제
-> 케이티페리, 저스틴비버와 같은 유명인사가 전부 같은 샤드에 저장되면 과부하가 될 수 있음
-> 유명인사 각각에 샤드 할당 / 더 잘게 쪼개기 - 조인과 비정규화
-> 하나의 데이터베이스를 여러 샤드 서버로 쪼개면, 조인하기 어려움.
-> 데이터베이스를 비정규화. 하나의 테이블에서 질의가 수행되도록 한다.
요약
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 한 많은 데이터를 캐시할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN을 통해 서비스 할 것
- 데이터 계층은 샤딩을 통해 그 규모를 확장할 것
- 각 계층은 독립적 서비스로 분할할 것
- 시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것

훌륭한 글이네요. 감사합니다.