- 라우팅 알고리즘의 목표: 송신자로부터 수신자까지 라우터의 네트워크를 통과하는 좋은 루트를 결정하는 것
- 좋은 경로란?
- 일반적으로 최소 비용 경로
그래프
- G=(N,E)
- N
- 노드의 집합
- 노드: 패킷 포워딩 결정이 이루어지는 지점인 라우터를 나타냄
- E
-
edge의 집합
-
edge: 라우터들간의 물리 링크를 나타냄
-
edge는 그 비용을 나타내는 값을 가짐 (해당 링크의 물리적인 거리, 링크 속도, 링크와 관련된 금전 비용 등)
- 만약 노드쌍 (x,y)가 E에 포함되어 있지 않으면 c(x,y)=∞
-
모든 edge가 무방향성 그래프만을 고려
-
edge (x,y)가 집합 E에 속하면, 노드 y는 노드 x의 이웃(neighbor)이라고 한다.
-
- 경로는 노드의 연속(x1,x2,...,xp)이고, 노드 쌍 (x1,x2),(x2,x3),...,(xp-1,xp)는 집합 E에 속한 edge들
- 경로의 비용은 경로상 모든 에지 비용의 단순합
1) 중앙 집중형 라우팅 알고리즘
- 네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이의 최소 비용 경로를 계산
- 링크 상태(link-state,LS) 알고리즘
2) 분산 라우팅 알고리즘
- 최소 비용 경로의 계산이 라우터들에 의해 반복적이고 분산된 방식으로 수행
- 노드들은 모든 링크의 비용에 대한 완전한 정보를 가지고 있지 않고, 각 노드는 자신에 직접 연결된 링크에 대한 비용 정보만을 가지고 있음
- 거리 벡터(distance-vector, DV) 알고리즘
분류기준 2. 정적 알고리즘 VS 동적 알고리즘
- 정적 라우팅 알고리즘
- 경로가 아주 느리게 변함
- 동적 라우팅 알고리즘
- 네트워크 트래픽 부하(load)나 토폴로지 변화에 따라 라우팅 경로를 바꿈
- 네트워크 변화에 더 빠르게 대응할 수 있지만, 경로의 loop나 경로 oscillation과 같은 문제에 더 취약
분류기준 3. 부하에 민감한가
- 부하에 민감한 알고리즘에서 링크 비용은 해당 링크의 현재 혼잡 수준을 나타내기 위해 동적으로 변함
- 현재 혼잡한 링크에 높은 비용 -> 우회하는 경로 선택
- 오늘날 인터넷 라우팅 알고리즘은 링크 비용이 현재의 혼잡을 반영하지 않기 때문에 부하에 민감하지 않음
5.2.1 링크 상태(LS) 라우팅 알고리즘
네트워크 전체에 대한 완전한 정보
- 각 노드가 자신과 연결된 링크의 식별자와 비용을 포함하는 링크 상태 패킷을 네트워크 상의 모든 다른 노드로 브로드캐스팅해서 가능
- 링크 상태 브로드캐스트 알고리즘에 의해 수행
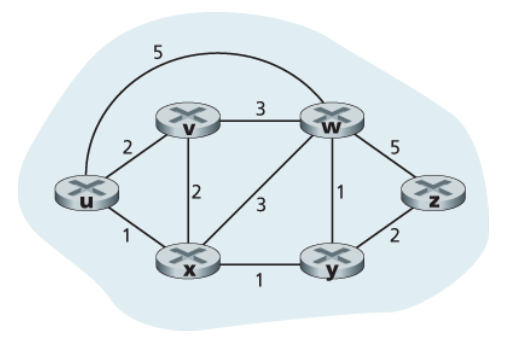
다익스트라 알고리즘 (Dijkstra's algortithm)
하나의 노드에서 네트워크 내 모든 다른 노드로의 최소 비용 경로를 계산
- 알고리즘의 k번째 반복 이후에는 k개의 목적지 노드에 대해 최소 비용 경로가 알려지며, 이 k개의 경로는 모든 목적지 노드로의 최소 비용 경로 중에서 가장 적은 비용을 갖는 k개의 경로
- D(v): 알고리즘의 현재 반복 시점에서 출발지 노드부터 목적지 v까지의 최소 비용 경로의 비용
- p(v): 출발지에서 v까지의 현재 최소 비용 경로에서 v의 직전 노드(v의 이웃)
- N': 노드이 집합. 출발지에서 V까지의 최소 비용 경로가 명확히 알려져 있다면, V는 N'에 포함됨
출발지 노드 u를 위한 링크 상태 알고리즘
Initialization:
N` = { u }
for all nodes v
if v is a neighbor of u
then D(v)= c(u,v)
else D(v) = INF
Loop
find w not in N` such that D(w) is a minimum
add w to N`
update D(v) for each neighbor v of w and not in N` :
D(v) = min (D(v), D(w) + c(W, v))
/* new cost to v is either old cost to v or known
least path cost to w plus cost from w to v */
until N` = N - 초기화 단계
- v,x,w까지 2,1,5로 초기화
- y,z는 u에 직접 연결 안되어 있으므로 ∞로 초기화
- 첫번째 반복
- 이전 반복 시점에서 최소 비용 1을 갖는 x를 N'에 추가
- u-x-w가 4로 더 작으므로 표에서 변경
- 두번째 반복
- 최소 경로 비용 2를 갖는 v,y 중 임의로 y를 N'에 넣음
...
- 최소 경로 비용 2를 갖는 v,y 중 임의로 y를 N'에 넣음
네트워크에서 링크 상태 알고리즘을 수행한 결과
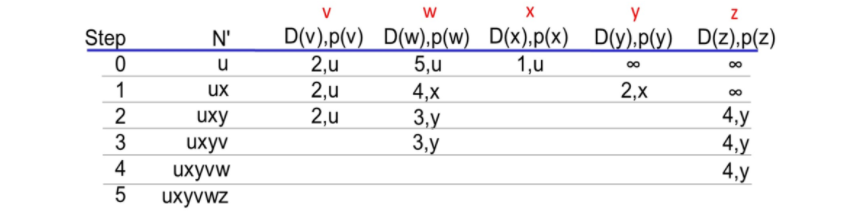
노드 u로부터의 최소 비용 경로와 노드 u의 포워딩 테이블
- 각 목적지에 대해 노드 u에서 그 목적지가지의 최소 비용 경로상의 다음 홉 노드를 저장하여 구상
- 계산 복잡도: O(n^2)
발생할 수 있는 문제 (진동 문제)
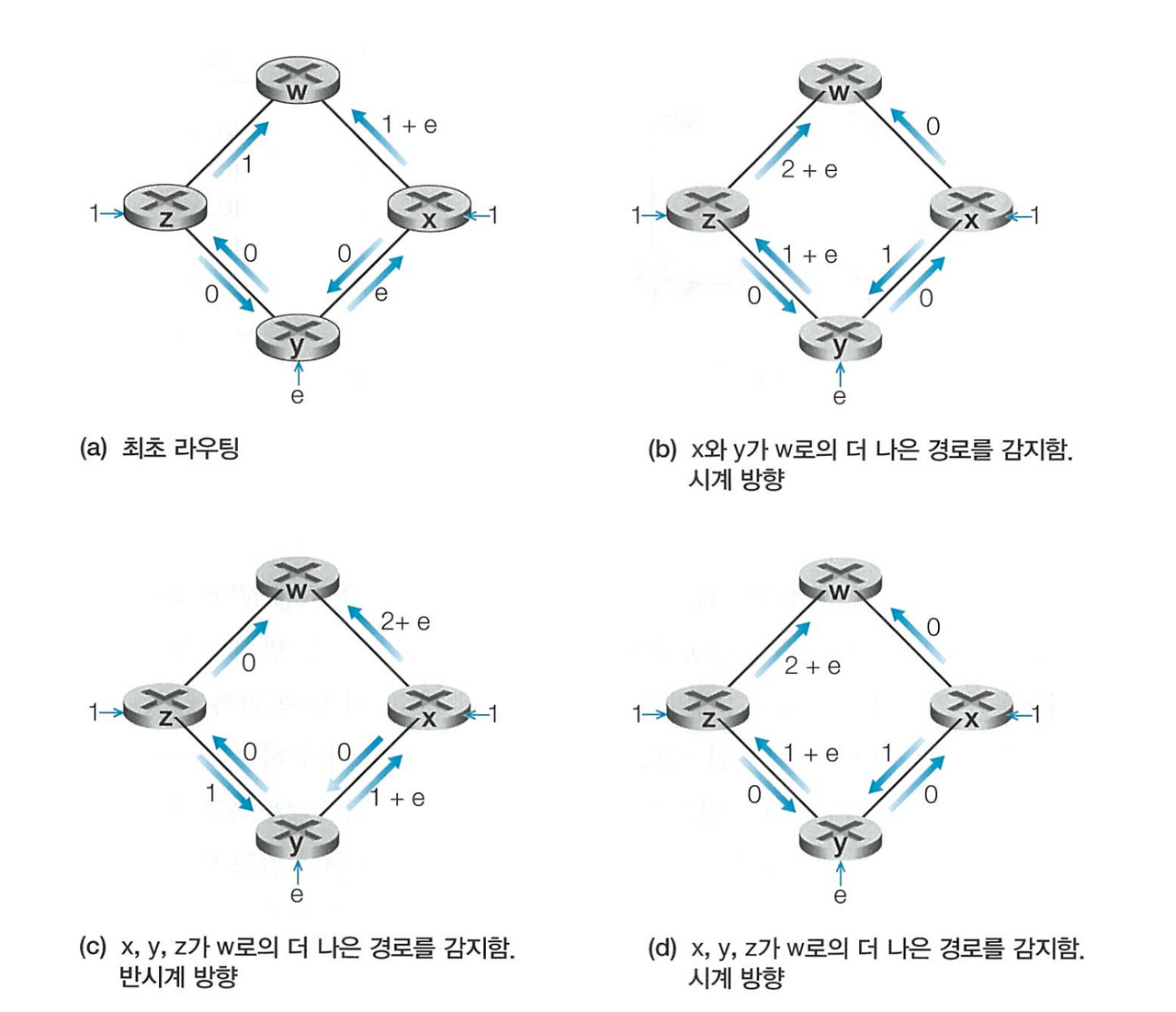
- 링크 비용은 대칭적이지 않음
- 트래픽의 양이 갱신 될 때마다 (b) 시계 방향, (c) 반시계방향, (d) 시계 방향으로 바뀌는 진동 문제가 발생
해결방안
- 링크 비용이 해당 링크가 전달하는 트래픽의 양에 의존하지 않도록 하기
- 라우팅의 한 가지 목적이 매우 혼잡한 링크를 회피하는 것으로 받아들이기 어려운 실행책
- 모든 라우터가 동시에 링크 상태 알고리즘을 실행하지 못하도록 하기
- 인터넷 라우터들은 서로 점진적으로 동기화되는 특성이 있음 (Floyd synchronization)
- 이러한 자기 동기화는 각 노드가 링크 상태 정보를 송신하는 시각을 랜덤하게 결정함으로써 회피 가능
5.2.2 거리 벡터(Distance vector) 라우팅 알고리즘
반복적이고 비동기적이며 분산적임
- 분산적(distributed): 직접 연결된 이웃으로부터 정보를 받고, 계산을 수행하며, 계산된 결과를 다시 그 이웃들에게 배포함
- 반복적(iterative): 이웃끼리 더 이상 정보를 교환하지 않을 때까지 프로세스가 지속됨
- 비동기적(asynchronous): 모든 노드가 서로 정확히 맞물려 동작할 필요가 없음
벨만-포드(Bellman-Ford) 식
- x에서 y까지의 최소 비용은 모든 이웃 노드 v에 대해 계산된 중 최솟값
- 벨만-포드 식의 해답은 각 노드 포워딩 테이블의 엔트리를 제공
- 벨만-포드 식을 최소로 만드는 이웃 노드 v가 있다면 노드 x는 패킷을 노드 v로 전달해야 함
- 노드 x의 포워딩 테이블에는 최종 목적지 y로 가기 위한 다음 홉 라우터로 v*가 지정되어야 함
- DV 알고리즘에서 일어나는 이웃 간 통신의 형식을 제안함
- c(x,y): 각 이웃 노드 v 중에서 x에 직접 접속된 이웃 노드까지의 비용
- =[: y in N]: x로부터 N에 있는 모든 목적지 y로의 비용 예측값을 포함하는 벡터
- =[: y in N]: 이웃 노드들의 거리 벡터들
- 이 업데이트로 인해 노드 x의 거리 벡터가 변경된다면, 노드 x는 수정된 거리 벡터를 이웃들에게 보냄
- 모든 노드가 자신의 거리 벡터를 비동기적으로 교환하는 동작을 계속하다 보면, 비용 추정값 는 노드 x에서 노드 y까지의 실제 최소 비용 경로의 비용인 로 수렴함
거리 벡터(DV) 알고리즘
Initialization:
for all destinations y in N:
Dx(y) = c(x, y) /* if y is not a neighbor then c(x,y) = INF */
for each neighbor w
Dw(y) = ? for all destinations y in N
for each neighbor w
send distance vector Dx = [ Dx(y) : y in N ] to w
Loop
wait (until I see a link cost change to some neigh-bor w or
until I receive a distance vector from some neighbor W)
/*각 노드는 이웃으로부터의 업데이터를 기다림*/
for each y in N:
Dx(y) = min_v{ c(x, v) + Dv(y) } /*노드 x는 v*(y)를 결정하고 목적지 y에 관련된 포워딩 테이블을 갱신*/
if Dx(y) changed for any destination y
send distance vector Dx = [ Dx(y) : y in N ] to all neighbors
/* 새로운 거리 벡터를 이웃들에게 배포*/
forever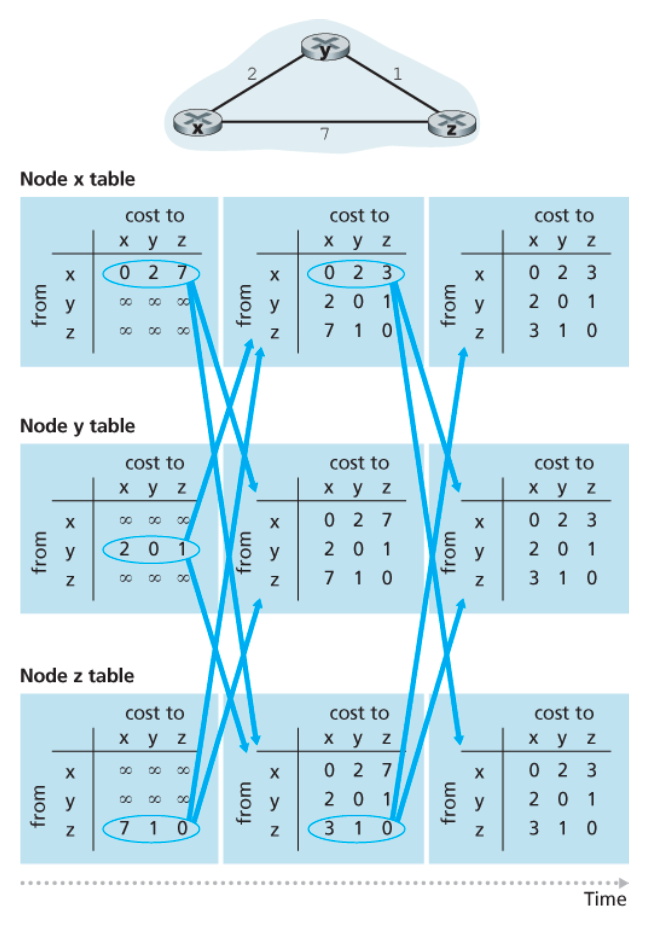
- 가장 왼쪽 열: 세 개 노드 각각의 최초 라우팅 테이블
- 두번째 열
- Dx(x)=0
- Dx(y)=min{ c(x, y) + Dy(y), c(x, z) + Dz(y) } = min(2+0,7+1)=2
- Dx(z)=min(2+1,7+0)=3
- 세번째 열
- 변화가 있다면 갱신된 거리 벡터를 다시 이웃들에게 보내기
- 더 이상 갱신 메시지가 없으면 라우팅 테이블 계산도 더 이상 없고 알고리즘은 정지 상태가 됨
- 즉, 모든 노드는 링크 비용이 변할 때까지 정지 상태로 대기
거리 벡터(DV) 알고리즘: 링크 비용 변경과 링크 고장
1) 링크 비용 감소
시각 t0.
y가 링크 비용 감소를 감지하고 자신의 거리 벡터를 업데이트한 후 변경값을 이웃에게 알림
시각 t1.
z는 y로부터 업데이트 정보를 받고 자신의 테이블 갱신(5->2)하고 이웃에게 자신의 새로운 거리 벡터를 전송
시각 t2.
y는 z로부터 업데이트 정보를 받고 자신의 테이블을 갱신, y의 최소 비용은 변화가 없으므로 y는 z에게 아무런 메시지를 보내지 않음
-> 알고리즘 정지 상태
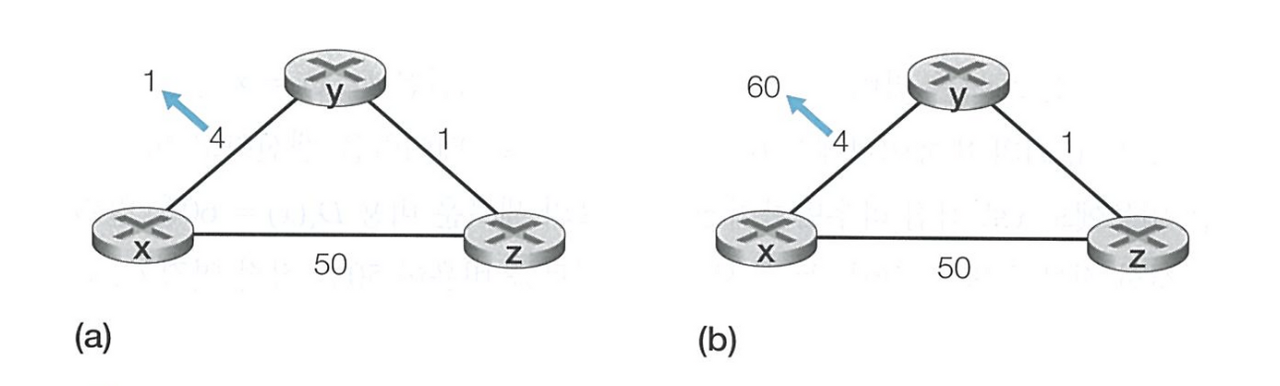
2) 링크 비용 증가
1.
- Dy(x)=min{c(y,x)+Dx(x),c(y,z)+Dz(x)}
=min{60+0,1+5}=6 - 우리는 네트워크 전체를 한 눈에 볼 수 있기 때문에 y가 z를 경유하는 것이 잘못되었다는 것을 알 수 있지만 y 입장에서는 아님
- y는 z, z는 y로 경로 설정하는 라우팅 루프가 발생
- 노드 y는 x까지의 새로운 최소 비용을 계산했으므로 t1 시각에 z에 새로운 거리 벡터를 알림
- z는 y로부터 갱신 정보를 받고 새로운 최소 비용을 계산
- Dz(x) = min{50+0, 1+6} = 7
x까지의 z의 최소 비용이 증가했으므로, 새로운 거리 벡터를 y에 알림
- y는 z로부터 새로운 거리 벡터를 수신하고 새로운 최소 비용을 계산
- Dy(x) = min{60+0, 1+7} = 8
새로운 거리 벡터를 z에 알림 - 이 프로세스가 44번 반복됨
- 이런 문제를 무한 계수 문제(count-to-infinity problem)이라고 함
거리 벡터 알고리즘: 포이즌 리버스 추가
- 루핑 시나리오는 포이즌 리버스(poisoned reverse)라는 방법을 사용해 회피할 수 있음
- z는 y에게 x까지의 거리가 무한대라고 거짓말함
-> y는 z를 통해 x로 가는 경로를 시도하지 않을 것 - 하지만, 포이즌 리버스는 세개 이상의 노드를 포함한 루프는 감지할 수 없으므로 모든 무한 계수 문제를 해결할 수 없음
링크 상태 알고리즘과 거리 벡터 라우팅 알고리즘 비교
경로 계산 방법
- LS 알고리즘
- 전체 정보를 필요로 함
- 각 노드는 다른 모든 노드와 통신하지만, 오직 자신에 직접 연결된 링크의 비용만 알림
- DV 알고리즘
- 오직 직접 연결된 이웃과만 메시지를 교환하지만, 자신으로부터 네트워크 내 모든 노드들로의 최소 비용 추정값을 이웃들에게 제공
메시지 복잡성
- LS 알고리즘
- O(|N| |E|)개의 메시지가 전송
- 링크 비용이 변할 때마다 새로운 링크 비용이 모든 노드에게 전달되어야 함
- DV 알고리즘
- 링크 비용이 변하고, 이 새로운 링크 비용이 이 링크에 연결된 어떤 노드의 최소 비용 경로에 변화를 준 경우에만 수정된 링크 비용을 전파
수렴 속도
- LS 알고리즘
- O(|N|^2) 알고리즘
- DV 알고리즘
- 천천히 수렴하고 라우팅 루프나 무한 계수 문제가 발생할 수 있음
견고성
- LS 알고리즘
- 연결된 링크에 대해서 잘못된 비용 정보를 브로드캐스트 할 수 있음
- 노드는 전송된 링크 상태 브로드캐스트 부분을 변질시키거나 폐기할 수 있음
- 그러나, 각 링크 상태 노드는 자신의 포워딩 테이블만 계산하므로 경로 계산이 어느 정도 분산되어 수행되고 어느 정도의 견고성을 제공함
- DV 알고리즘
- 노드는 잘못된 최소 비용 경로를 어떤 혹은 모든 목적지에 알릴 수 있음
- 각 반복마다 한 노드의 거리 벡터 계산이 웃에게 전달되므로, 한 노드의 잘못된 계산은 전체로 확산될 수 있음
결국 어느 알고리즘이 명백히 낫다고 말할 수 없고 모두 인터넷에서 사용되고 있음
