임베디드 해킹 방법론.
Embedded 기기 해킹에서 펌웨어 추출은 크게 네 단계로 나눌 수 있다.
하드웨어 기판 분석
- Printed Circuit Board (PCB) : 전자 부품을 고정하고 전기적으로 연결된 기판. Multi Layer로 구성되어 있다.
- chip : 반도체 실리콘에 회로를 덧붇힌 전자 부품으로, 밑면에 Ball을 납땜한 BGA 형식과 핀을 배열한 PGA 형식이 있다.
- SoC (System on Chip) : CPU, GPU, 일부 I/O interface 등 여러 기능을 단일 칩에 집적한 집적 회로로, 임베디드 기기에서 사용. SoC에 전원이 인가되면 제일 먼저 실행되는 코드를 SoC Firmware라고 한다.
Bootloader -> bootloader가 kernel image 올리기 -> kernel 실행 -> OS 실행 -> OS가 File system 올리기 순서로 이루어진다. - voltage regulator : 외부 전원(배터리·어댑터 등)에서 들어오는 전압을 SoC나 주변 칩이 안전하게 쓸 수 있는 일정 전압(예: 3.3 V, 1.8 V)으로 바꿔주는 장치
- Capacitor (condensor) : 순간적으로 전기를 저장하고 꺼내 쓸 수 있어 안정적인 전압 유지
- Resistor (저항) : 전류 흐름을 제한하여 안정적인 전류 및 전압 유지
- Testing Point : PCB 기판 위에 있는 작은 납착 지점으로, 칩(=pin)과 보드가 제대로 연결되었는지 확인하거나 전압 신호를 테스트할 때 사용
- Trace : PCB 위의 전기가 통하는 도선
- Flash Memory : 비휘발성 메모리로, 쓰기/지우기 횟수가 제한되어 있다.
- Microcontroller Unit(=MCU) : CPU core + flash(ROM) + SRAM + UART 등 주변 장치를 한 칩에 집적한 임베디드 제어용 마이크로 프로세서
Debug
JTAG
칩에 내장된 디버깅 포트로, TCK, TMS, TDI, RDO 등 4-5개의 핀을 가지고 있다. 제조사가 header 형태로 노출해두는 경우도 있지만, 패턴(trace) 없이 testing point만 남겨서 직접 찾아야 하는 경우가 있다. 억지로 칩을 disordering 하고 jtag에 연결된 채로 다시 끼우거나 SoC/MCU reference 자료/패드 번호를 바탕으로 구글링을 통해 확인해야 한다.
연결만 하면 openocd + gdb로 SoC 내부 레지스터, 메모리, 플래시를 자유 자재로 읽고 쓸 수 있다. 일부 PCB는 보안 상의 이유로 내부 로직이나 펌웨어에서 JTAG를 disable하기도 한다.
UART (Serial Console)
VCC, GND, TX, RX 네 개의 핀을 찾아 serial 터미널로 연결하면 boot log를 확인할 수 있다. 또한 UART 핀은 input으로도 output(메시지)으로도 사용할 수 있어 interaction이 가능하기 때문에, UART를 찾는 것이 중요하다.
GND를 찾아야 기준 전위(reference)가 정해지고 나머지 신호를 올바르게 인식할 수 있기에, 보드 위 아무 패드를 찍어볼 때 그 패트가 GND에 속해 있으면 연속성 테스트나 다이오드 테스트 모드에서 낮은 저항으로 표시되는 것을 통해 찾아야 한다.
VCC는 전원 공급 or 외부 모듈 연결용 핀이고, TX는 기기가 내보내는 데이터이며 RX는 기기가 받는 데이터를 의미한다.
Firmware Dump & Carving
칩의 데이터시트(사용 설명서)에는 핀 배치, 전압 허용 범위, 지원하는 프로토콜 등을 기술한다. 이 중 SPI protocol을 확인하고 해당 프로토콜의 명령어 read, fast read, write disable 등을 통해서 dump를 구현할 수 있다. SPI 프로토콜은 master와 slave 장치 사이의 데이터를 주고받는 통신 규격으로, 해당 프로토콜의 바이너리를 통째로 받아올 수 있도록 해야 한다. Bootshell은 부트로더 내장된 Command Line Interface인데, Bootshell에서 dump하여 SPI flash 내용을 메모리(RAM)로 읽으면 serial port을 통해 PC에 옮길 수가 있으며 (sf read로 RAM에 복사 md로 serial 전송), binwalk로 filesystem (squashfs 등), 내부에 들어있는 zip, U-Boot/Intel HEX header 등을 스캔할 수 있다. 또한 --dd 옵션을 통해사 carving을 할 수 있다.
Carving은 원시 RAW image 속에서 파일이나 FS같은 개별 데이터 조각을 signature 값을 기반으로 찾아서 잘라내는 기법을 말한다. 펌웨어나 디스크 이미지를 통째로 덤프하면 내부에 fs 정보나 파일 테이블이 없거나 손상되어 있을 수 있는데, 어디에 어떤 파일이 있는지 시그니처 값을 토대로 블록을추출하여 별도 파일로 복원한다. signature 값 + offset 값을 바탕으로 크기를 파악하고 추출하는 것이 원리이다.
squashfs-root 폴더 안에 백도어 스크립트 (daemon 설정이나 ssh key, init script 등)을 넣고 mksquashfs 명령어를 통해 새 이미지를 생성하고 펌웨어를 덮어쓰면 된다. 추출한 펌웨어를 수정해서 내 백도어 심고 flash에 다시 넣으면 수정한 바이너리대로 동작을 할 것이다.
보통은 그런데 이런 과정 안 거치고 flashrom 툴을 쓰면 펌웨어가 잘 뽑힌다. SPI는 속도 조절 및 안정성을 위해서 직접 command를 짜고 추출하는 경우에 많이 쓰인다.
UBI
NAND / NOR flash는 비휘발성 메모리로, NOR Flash는 바이트 단위 랜덤 액세스를 지원해 코드 실행에 유리하고, NAND Flash는 페이지/블록 단위 접근으로 대용량·저비용에 적합하다. Linux Kernel에서는 MTD (Memory Technology Device)라는 드라이버 계층이 존재하여, flash를 블록 단위로 추상화를 해서 저수준 인터페이스를 제공한다. 해당 인터페이스 위에서 Flash Filesystem이 동작한다. flash에 대해 flash cell을 모두 1 (또는 0)으로 되돌리는 과정을 erase이라고 하며, flash는 사용 전에 erase를 거쳐야 한다. 그러나flash는 erase 과정에서 횟수 제한이 있어 erase 횟수를 flash 전체에 고르게 분산시키는 기법인 Wear Leveling이 있다. 이 과정에서 flash에서 한 번에 지울 수 있는 최소 단위를 erase block (=Physical Erase Block,PEB) 라고 한다. 물론 사용 중 지워지지 않거나 데이터가 뒤섞여 오류가 발생하는 불량 블록들이 있어 잘 관리해주어야 한다.
UBI(Unsorted Block Images)는 flash 위에서 동작하는 블록 관리 레이어(계층) 로, PEB를 LEB로 매핑해주고 불량 블록 관리와 웨어 레벨링을 담당한다. UBI에서 관리하는 flash partition을 volume이라고 하며, 각 volume마다 이름과 크기 (LEB 개수)를 지정하고 volume 위에 filesystem을 올리는 방식으로 작동한다. UBI는 MTD와 UBIFS 같은 flash filesystem 사이에 위치하여 둘 사이를 중개한다. UBIFS는 log 구조를 가지고 동적으로 index를 할당해서 잦은 erase/write에도 안정적으로 동작한다. 임베디드 linux 장비에서 flash memory(NAND)를 사용할 때 UBIFS를 많이 사용한다.
UBI를 사용하는 원본 RAW 이미지는 binwalk 도구로 카빙해도 UBIFS layer까지 자동으로 추출되지 않는다. UBIFS가 그 자체로 독립적인 파일 시스템이 아니고 UBI 위에서 동작하는 파일 시스템이라서 그렇다. 원시 flash dump에는 EC header, VID header같은 UBI 고유 헤더가 PEB마다 끼워져 있어 binwalk같이 일반적인 파일 시스템이나 압축 파일의 시그니처 값을 찾아서 끝날 때 까지 한번에 스캔 및 카빙해주는 프로그램으로는 UBI header를 스캔하지 못한다. UBIFS의 시그니처인 hsqs 시그니처를 검출하더라도 그 앞뒤에 EC/VID 헤더(각 64바이트)가 삽입되어 있어 연속된 UBIFS LEB 데이터 덩어리로 인식되지 않는다. 또한 빈 LEB이 있을 수도 있고 raw dump 전체를 집어 넣으면 볼륨 경계나 PEB/LEB 매핑이 어긋나서 오류가 날 수도 있다.
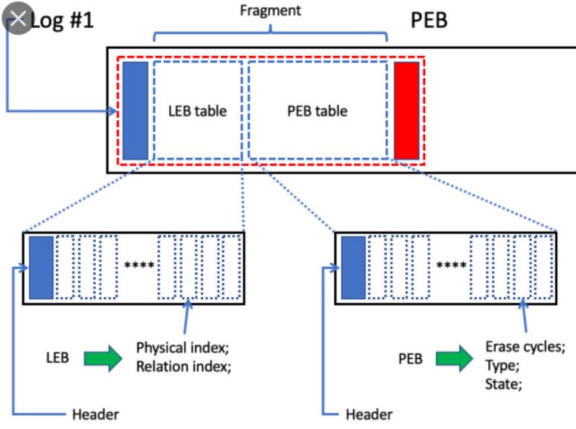
UBI는 EC 헤더와 VID 헤더 두 개를 관리하는데, EC는 erase 횟수를 count하는 영역이고 VID 헤더는 어떤 volume에 어떤 PEB가 속하는지, volume 내에서 LEB의 번호는 무엇인지 등을 저장한다.
UBIFS는 일반적인 압축과는 다르게 mount 과정이나 복잡한 메타데이터 해석을 필요로 한다. Mount는 linux에서 파일 시스템이나 블록 장치 (partition, flash image 등)을 directory tree에 연결해서 사용할 수 있게 만드는 과정이다. 예를 들어, linux는 단일 계층의 directory tree 구조를 가져 / 아래로 디렉토리가 이어지는 구조를 가진다. HDD, USB, ROM, UBIFS 등 서로 다른 저장 장치는 독립된 파일 시스템 포맷을 가지기 때문에 특정 디렉토리에 연결하는 마운트 과정을 통해 / 아래 경로로 접근할 수 있게 하는 것이다. 따라서 binwalk같은 도구로 시그니처 파싱만 하고, ubireader_extract_files 과 같은 다른 도구로 UBIFS 구간만 구분하여 추출하는 방식이 실무 표준이다.
위에 언급했듯이 UBIFS는 UBI volume 위에서 작동하는 flash 전용 filesystem으로 EC, VID 헤더가 있고 LEB도 매핑해야 하며, CRC, sequence number 등 메타 데이터도 존재한다. 단순히 시그너치만 탐지하는 binwalk로는 UBIFS의 내부 영역을 구분할 수 없는 것은 당연하다.
carve-join
ubireader_extract_files 프로그램으로도 ubifs를 정상적으로 추출하지 못하는 경우가 많은데, LEB 중 파손 데이터가 있으면 추출을 중단하기 때문이다. 실제 flash dump에서는 빈 블록이나 불량 블록이 많기 때문에 실무 임베디드 분석에서는 정보의 신뢰성은 좀 떨어지더라도 더 많은 데이터와 파일을 확보하기 위해 carve-join 방식을 사용하는 것이 더욱 유효하다.
Carve-Join 방식은, UBI image을 PEB 크기 단위인 128KiB 단위로 스캔하고, 유효한 LEB만 추출한다. LEB 조각에서 timestamp 등으로 생성 시간을 파악하고, LEB를 순서대로 이어 붙이는 원리이다. NAND flash memory는 물리적 블록 단위로 저장되고 각 블록은 volume으로 묶여 UBI 위에서 동작하여 EC/VID 헤더를 확인할 수 있다. PEB에서 EC 헤더의 magic number와 버전을 확인하여 유효한 블록인지 판단하고, VID 헤더의 sqnum 필드와 LEB 번호, volume ID, 데이터의 시작 위치를 추출하여 PEB가 어떤 volume의 몇 번째 LEB인지를 파악할 수 있다. 같은 LEB 번호를 가져도 sqnum 값을 통해 최신 데이터만을 추출해낼 수 있는 것이다. 이후 합치는 과정을 거치면 volume 별로 완전한 UBIFS image를 생성할 수 있으며, 최대한 데이터를 추출해낼 수 있다.
코드로 구현한다면 UBI image에서 PEB/LEB 데이터를 추출하는 Carving 단계, LEB를 LEB 번호 순서대로 합쳐서 UBIFS volume image를 재조립하는 Joining 단계로 나누면 된다.
python으로 짰다. image 파일을 mmap으로 열어서 PEB block size 단위인 0x20000로 나누어 블록 수를 계산하고, 각 블록마다 EC와 VID 헤더의 magic number를 찾아서 필요한 정보를 추출한다. VID header는 EC 헤더에서 일정 거리의 offset만큼 떨어져있기 때문에 쉽게 위치를 알 수 있고, VID 헤더의 정보들도 offset을 이용하여 다 추출할 수 있다. 추출할 정보는 data_offset, pad size, volume ID, LEB 번호 (lnum), seqnum이다. 이를 바탕으로 데이터 영역에 접근하고, 데이터가 erase 되어 있는 경우는 제외한다. 이후 해당 LEB들을 추출하여 저장할 때 쉽게 join하기 위해서 이름에 메타 데이터 정보들을 저장해둘 것이다. 그러면 나중에 정규 표현식을 통해서 join기 쉬워진다. join 할 때는 기본적으로 volume ID별로 나누고, 각 volume에서 lnum을 기준으로 파일을 이어 붙일건데, 만약 ln이 같으면 sq가 더 큰 조각을 dictionary에 남겨서 최종적으로 정렬 후 파일로 이어 붙이면 된다.
