세그먼테이션(Segmentation)
프로세스의 주소공간을 이루는 스택, 데이터, 코드 힙 등의 의미 단위의 세그먼트로 나누어 물리적 메모리에 올리는 기법이다. 프로세스의 주소 공간 전체를 크게 하나의 세그먼트로 볼 수도 있다.
- 세그먼트는 이 처럼 특정 크기 단위로 나눈 것이 아니라 의미를 가질 수 있는 논리적 단위로 나눈 것이므로 크기가 균일하지 않음
프로세스의 주소 공간이 나누어져 각각 메모리에 적재되는 면에서는 페이징 기법과 유사하다고 볼 수 있다. 그러나 페이징 기법과 달리 크기가 제각기 다른 세그먼트들을 메모리에 적재하는 부가적인 관리 오버헤드가 뒤따르게 된다.
논리적 주소가 <세그먼트 번호, 오프셋>으로 나뉘어 사용된다.
- 세그먼트 번호: 해당 논리적 주소가 프로세스 주소 공간에서 몇 번째 세그먼트에 속하는지 나타냄
- 오프셋: 세그먼트 내에서 얼마만큼 떨어져 있는지에 대한 정보
마찬가지로 주소 변환을 위해 세그먼트 테이블을 사용한다. 각 항목은 기준점(base)와 한계점(limit)를 갖고 있다. 세그먼트의 크기가 균일하지 않기 때문에 페이징 기법과는 달리 항목마다 길이 정보까지 포함하고 있다.
- 기준점: 물리적 메모리에서 그 세그먼트의 시작 위치를 나타냄
- 한계점: 그 세그먼트의 길이
주소 변환 할 때,
- 세그먼트 테이블 기준 레지스터(STBR): 현재 CPU에서 실행 중인 프로세스의 세그먼트 테이블이 메모리의 어느 위치에 있는지 그 시작 주소를 담음
- 세그먼트 테이블 길이 레지스터(STLR): 그 프로세스의 주소 공간이 총 몇 개의 세그먼트로 구성되는지 나타냄
논리적 주소를 물리적 주소로 변환
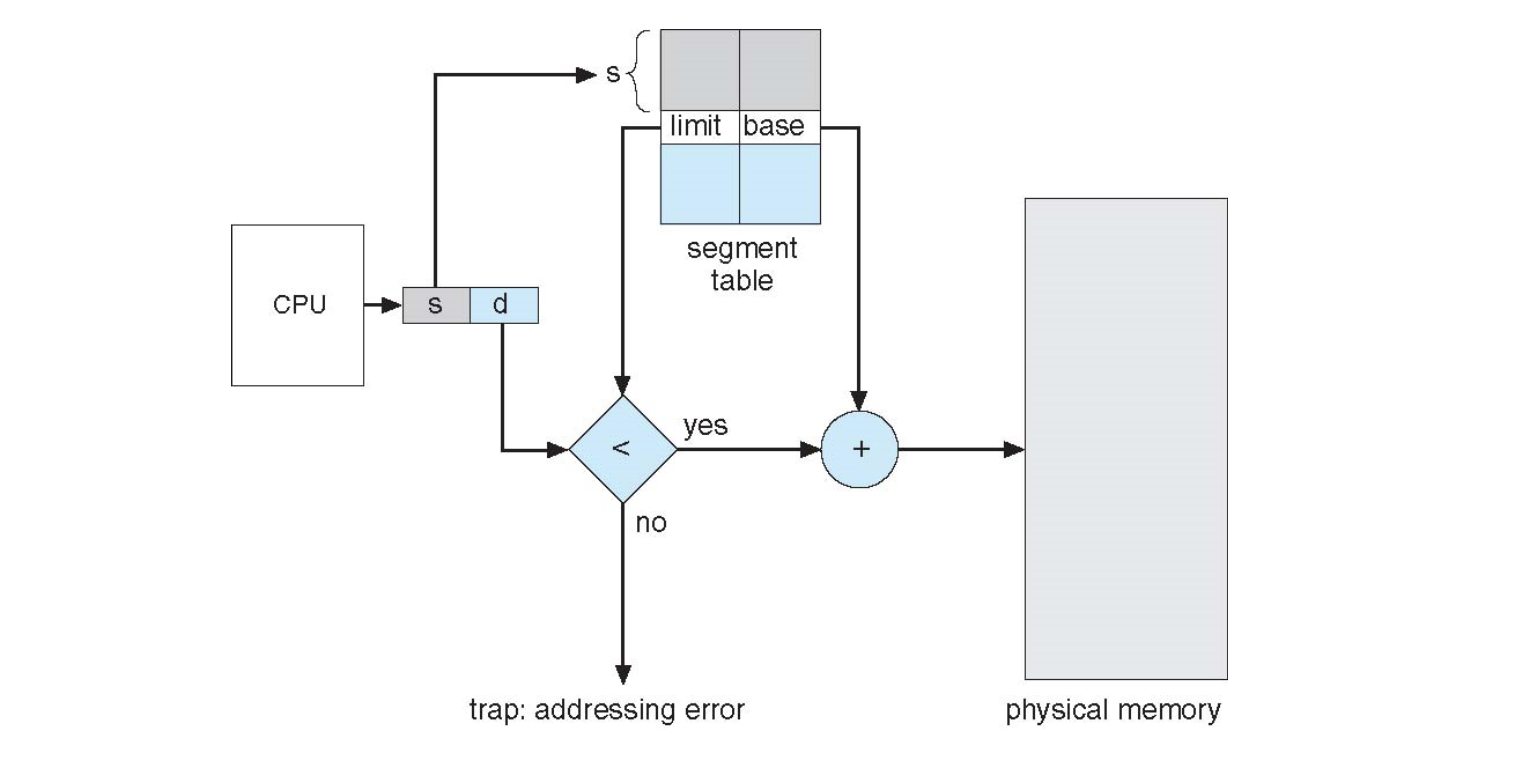
변환하기 전, 먼저 두 가지 사항을 체크한다.
- 요청된 세그먼트 번호가 STLR에 저장된 값보다 작은 값인지
- 논리적 주소의 오프셋 값이 그 세그먼트의 길이보다 작은 값인지
두 가지 사항이 모두 만족한다면 유효한 멤모리 접근 요청으로 판단해 주소 변환 작업이 수행된다.
세그먼트 테이블에서도 각 항목에 보호비트와 유효비트를 둔다.
- 보호비트: 각 세그먼트에 대해 읽기/쓰기/실행 등 권한이 있는지 확인
- 유효비트: 각 세그먼트의 주소 변환 정보가 유효한지 확인(해당 세그먼트가 현재 물리적 메모리에 적재되어 있는가)
공유 세그먼트(Shared segment)

세그먼테이션 기법도 여러 프로세스가 특정 세그먼트를 공유해 사용하는 공유 세그먼트를 지원한다. 공유 세그먼트는 이 세그먼트를 공유하는 모든 프로세스의 주소 공간에서 동일한 논리적 주소에 위치해야 한다.
장점
세그먼트는 공유와 보안 측면에서 페이징 기법보다 훨씬 효과적이다.
- 주소 공간의 일부 공유, 특정 주소 공간에 읽기 전용 등 접근 권한 제어를 할 경우: 단순히 크기 단위로 이루어 지지 않고 의미 단위로 이루어진다.
또한, 페이징 기법에서는 동일한 크기로 주소 공간을 나누기 때문에, 공유하려는 코드와 사유 데이터 영역이 동일 페이지에 공존하는 경우가 발생할 수 있는데, 세그먼테이션 기법에서는 이러한 현상이 발생하지 않는다.
내부 단편화 문제도 발생하지 않는다.
단점
세그먼트의 길이가 균일하지 않아 물리적 메모리 관리에서 외부 단편화가 발생하게 되며 세그먼트를 어느 가용 공간에 할당해야 될지 결정하는 문제가 발생한다.
- 세그먼트를 가용 공간에 할당하는 방식: first fit, best fit 방식
페이지드 세그먼테이션(Paged segmentation)
페이징 기법과 세그먼테이션 기법의 장점만 이용한 주소 변환 기법이다. 세그먼테이션 기법처럼 프로그램을 의미 단위의 세그먼트로 나누는데 단, 모든 세그먼트들은 동일한 크기 페이지들의 집합으로 구성되어야 한다. 그리고 물리적 메모리에 적재하는 단위는 페이지 단위로 한다.
이 기법은 하나의 세그먼트 크기를 페이지 크기의 배수가 되도록 함으로써 세그먼테이션 기법에서 발생하던 외부 단편화 문제가 발생하지 않고 세그먼트 단위로 프로세스 간 공유나 프로세스 내의 접근 권한 보호가 이루어짐므로 페이징 기법의 단점을 해결할 수 있게 된다.
페이지드 세그먼테이션의 2단계 테이블
하나의 세그먼트가 여러 개의 페이지로 구성되므로 각 세그먼트마다 페이지 테이블을 갖는다.
- 외부의 세그먼트 테이블
- 내부의 페이지 테이블
논리적 주소는 <세그먼트 번호, 오프셋>으로 구성되어 있고 물리적 주소로 변환하는 과정은 아래와 같다.
논리적 주소를 물리적 주소로 변환
논리적 주소의 상위 비트인 세그먼트 번호를 통해 세그먼트 테이블의 해당 항목(세그먼트 길이와 세그먼트의 페이지 테이블 시작 주소 포함)에 접근한다.
- 세그먼트 길이를 넘어서는 메모리 접근 시도인지 확인: 세그먼트 길이값과 오프셋 체크
- 오프셋 값을 다시 상위, 하위 비트로 나눔: 상위 비트는 세그먼트의 페이지 번호로 사용, 하위 비트는 페이지 내에서 변위로 사용
- 페이지 시작 위치에서 페이지 번호만큼 떨어진 페이지 테이블 항목으로부터 물리적 메모리의 페이지 프레임 위치를 얻음
- 이 위치에서 페이지 내의 변위만큼 떨어진 곳이 물리적 메모리 주소가 됨
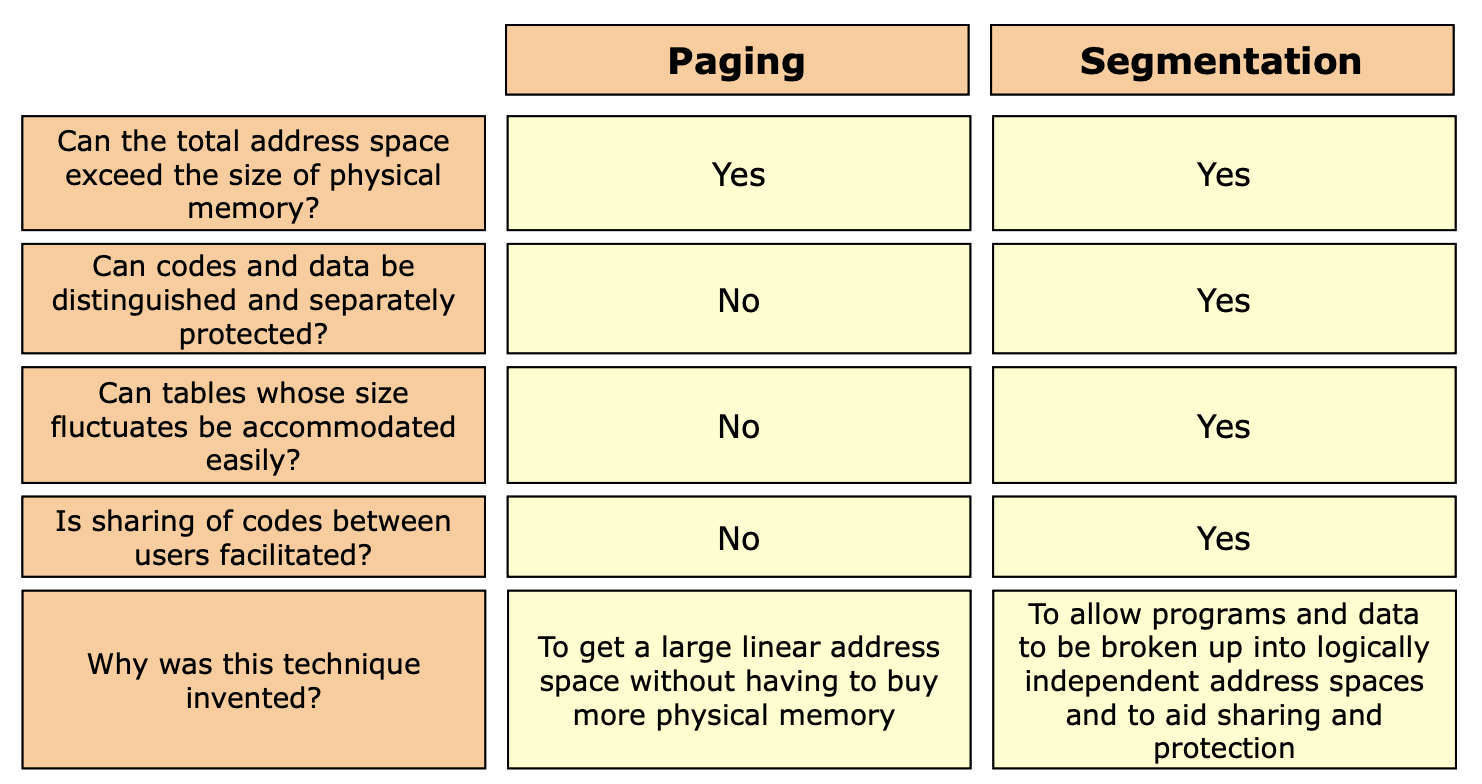
페이징과 세그먼테이션 차이