본 포스트는 Federated Learning의 실효성을 검증하기 위하여 사내에서 진행한 실험에 대한 내용을 담고있습니다.
참고한 논문에 실린 영어 표현은 따로 번역하지 않고 그대로 작성하려고 했습니다.
잘못됐다고 생각하시는 부분은 피드백을 주시면 바로 수정하도록 하겠습니다.
배경
마크애니에서는 지능형 선별관제 솔루션을 개발하고 있으며, 현재 다양한 지자체 소속 관제센터에서 저희 솔루션을 이용해주시고 계십니다. 지능형 선별관제란 관제사분들이 보다 편리하게 CCTV영상을 관제할 수 있게 도움을 드리기위한 기술로써, 자동으로 CCTV 영상을 분석하여 관제사분들께 관제에 도움이 될수있는 정보를 제공합니다.
"수배차량 실시간 추적" 골목길 CCTV 차량번호 자동인식
마크애니, AI 기반 영상 검색·대상자 이동경로 추적 기술 개발한다
저희가 다루는 데이터는 CCTV 영상이다보니 개인정보이슈와 뗄레야 뗄수 없는 데이터이며, 당연히 반출이 불가능합니다. 그렇다보니 학습 데이터셋 구축에 여러가지 애로사항이 존재합니다. 이러한 상황에서 고려해볼만한 방법으로는 Federated Learning이 있었습니다.
적용기
Federated Learning에 대한 개념은 잘 설명된 자료들이 많다 판단되어 해당 포스트에서는 개념과 그 방법은 자세히 다루지 않겠습니다.
Federated Learning에 대해서 저는 "Data Privacy 이슈 혹은 Computational Cost 이슈로 중앙화된 Server에 학습에 필요한 Data 들을 저장하고 처리하기 어려운 경우, Data는 분산된 다수의 Clients에만 저장하고 학습또한 Clients에서 한뒤에 학습으로 부터 나오는 모델의 Weights만을 잘 조합하여 보다 나은 성능을 갖는 Weights를 만들 수 있는 학습 기법이다." 로 이해했습니다.
먼저, 적용에 앞서 Federated Learning에 관한 초기 논문을 찾아보았고 구글에서 발표한 Communication-Efficient Learning of Deep Networks from Decentralized Data 논문을 살펴보고 해당 방법을 토대로 적용 계획을 세웠습니다.
논문과 자료들을 조사하며 Federated Learning을 실제로 적용하기 위해 어떤 어려움이 있을지 생각해보았습니다. 그리고 Federated Learning이 어떠한 케이스에서 적용하면 좋은 기술인지를 정의 해보았습니다.
1) 개발자가 학습에 필요한 데이터를 직접적으로 접근하는것이 어려움
2) 학습에 필요한 데이터가 클라이언트 단에서는 접근이 가능함
3) 학습에 필요한 데이터가 클라이언트 단에서는 학습에 유용한 형태로 가공될/할 수 있어야함
클라이언트 단에서 학습이 가능해야함
4) 서버와 클라이언트 간의 연결이 가능해야함
이러한 기준을 세우며 떠오른 Federated Learning 적용의 장벽은 두 가지가 있었습니다.
(1)Client 측에서 데이터를 학습에 유효하게 가공하기 위해 레이블링을 해야한다는 점이였습니다. 문제를 어떻게 풀어가냐에따라 Client 측에서 데이터를 레이블링 하는 방법은 매우 쉬울 수 있고 또 매우 어려워질 수 있습니다. 때로는 전문적인 도메인 지식이 요구되는 경우, Client 측에서 해당 지식을 보유하고 있는 레이블러가 존재하지 않는 이상 Client 측에서의 레이블링은 불가능해질 수 있습니다. 과연 구글은 실제 서비스에 Federated Learning을 접목시킴에있어 어떤식으로 Clinet 측에 레이블링을 전가했을지에 대한 의문점이 떠올랐습니다.
이러한 의문점에 대한 힌트를 담은 글을 발견할 수 있었습니다. 바로 구글에서 작성된 Federated Learning: Collaborative Machine Learning without Centralized Training Data 에 힌트가 있었습니다.

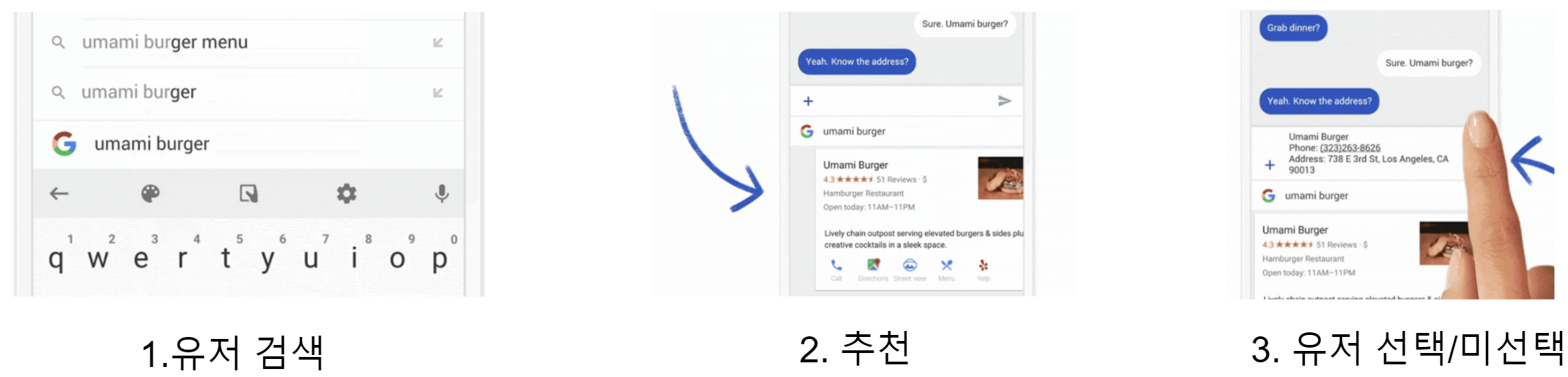
먼저, 구글은 Federated Learning을 구글의 키보드 어플 Gboard에 적용했다고 합니다. Gboard는 유저(=Client)의 검색에 대해 검색 결과를 제안하는 기능이 존재하는 것으로 보입니다. 이때 유저가 추천된 결과를 선택했는지에 대한 여부를 통해 검색 알고리즘이 제안한 결과가 적절한 제안인지 부적절한 제안인지를 모델을 학습시키기 위한 레이블로써 활용한것으로 추정됩니다.
유저는 앱을 이용하며 자연스럽게 레이블링을 하고 모델은 업데이트되고 다음엔 더 좋은 제안을 받는 선순환의 구조를 갖는 것으로 생각되었습니다. Federated Learning을 적용함에 있어 유저로 하여금 자연스러운 레이블링의 중요성은 논문에서도 언급이 되어있었습니다.

(2) 결국에 Server와 Client는 모델의 업데이트를 위해 연결 되어야한다는 점이 Federated Learning 적용의 어려움으로 다가왔습니다. 저희의 경우 Client는 곧 관제센터내에 위치한 PC가 될 것입니다. 그리고, Server는 외부에 위치한 PC가 될 것입니다. 이 경우에 CCTV 영상이 저장된 PC가 Server와 결국 연결되어야 한다는 의미이므로, 저희가 아무리 모델의 Weights만 Server와 Client간 교환한다고 하더라도 CCTV 영상이 보안 공격에 의해 외부망으로 노출될 수 있다는 보안 문제가 발생합니다. 무엇보다도 이 문제가 가장 큰 문제로 다가왔습니다. 각 Client 별로 한 번의 학습 사이클이 마치고 나서 단 한 번만 모델을 통합(=논문에서 언급된 One-shot averaging)하여 좋은 성능이 나와준다면, Client의 PC가 외부망과 연결되지 않아도 모델 Weights만 수동으로 반출 후 Server로 업로드하는 식의 방안이 될 수 는 있습니다. 그렇지만... 논문에서 이 또한 언급이 되어있습니다.

최악의 경우에 Global 모델(= Client 의 모델들로부터 Server에서 업데이트되는 모델)은 Client 모델 보다 성능이 좋지 않을 수 있다고 합니다. 실제로 저희 실험에서도 해당 방법 적용시 성능이 완전히 저하되는 문제가 있었습니다. 논문에서 제안된 방법또한 주기적으로 E epochs 마다 Global 모델을 업데이트 하도록 설계한 것을 확인할 수 있습니다.

Client와 Server간의 통신 횟수를 최대한 줄일 수 있는 one-shot, few-shot federated learning 연구 또한 진행은 되고 있음을 확인할 수 있었습니다.
이런 장벽들을 마주하고나니 저희 환경에서 Federated Learning 을 실질적으로 적용하는 것은 어렵겠다는 생각이 들었습니다.
그렇지만! 시도는 해보고 싶었습니다. 정말로 다른 데이터로 학습된 모델의 Weights을 학습 과정에서 주기적으로 합산하는것이 성능을 올릴 수 있는 방안이 될 수 있는지 Real-world Data로 검증해보고 싶었습니다.
우선 (2)의 어려움을 제쳐두고 사내에서라도 Federated Learning의 실효성을 검증해보기 위해 간단하게 실험 환경을 구축하고 실험을 진행해보았습니다. 저희가 풀고 있는 문제 중에서 Client 측에서 비교적 간단하게 레이블링을 할 수 있는 문제 및 태스크인 차번 인식을 대상으로 Federated Learning을 적용해보았습니다.
실험
- Clients 수: 2, 각 Client 별로 Dataset Size는 약 8만장
- C: 1.0(round 별로 항상 두 Clients의 모델을 모두 사용하여 Global 모델을 업데이트)
- Total Epochs: 70
- Local Epochs E: 1, 5, 10, 20, 70(One-shot Averaging)
- Batch Size: 64
- Optimizer: Adam
- Learning Rate: 2.5e-4
- Learning Rate Warmup Iterations: 1,000
- Model: 자세히 작성하기가 어려우나 CNN기반의 모델로 생각하시면 됩니다. Client A와 Client B의 초기 모델은 동일한 시드로 동일한 초기화 방법을 따랐습니다.
여기서 round는 local models를 이용해 global model을 업데이트하는 단계를 의미합니다.
논문식 표현으로는 non-IID 보다는 IID 세팅에 가깝게하여 실험을 진행했습니다. 이 두 데이터셋을 A, B라고 표현하겠습니다. 두 데이터셋의 차이점이라하면 전처리 방식이 다릅니다. A는 번호판 이미지가 딱 번호판 영역이 핏하지 않게 Crop되어있고, B는 핏하게 Crop 되어있습니다. 데이터셋 A에 존재하는 이미지와 B에 존재하는 이미지를 그림으로 표현하면 아래와 같습니다. 본 실험에는 aihub 자동차 차종/연식/번호판 인식용 영상 이 활용됐습니다.
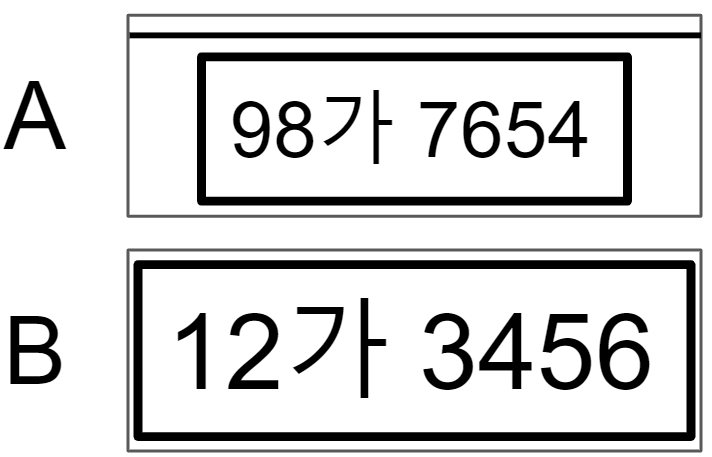
Validation Set은 약 11,000장으로 데이터중 약 90%는 A와 유사하게 전처리되어 있으며, 약10%는 B와 유사하게 전처리되어 있습니다. 즉 Validation Set에 대한 성능은 Client A에서 더 높게 나올것이라고 예상할 수 있습니다.
학습 코드를 직접적으로 카피해왔습니다. 빠르게 실험을 진행하기 위해 Clients의 개수를 2개로 제한하였고, 이에 따라 단순히 코드를 구현했습니다.
# Train
for epoch in range(start_epoch, optimizer_option_a["OPTIMIZER"]["EPOCHS"]+1):
print(f'Epoch [{epoch}/{optimizer_option_a["OPTIMIZER"]["EPOCHS"]}]')
train(args,
device,
epoch,
model_a,
training_set_a_dataloader,
dataset_option_a,
optimizer_a,
optimizer_option_a,
lr_scheduler_a,
scaler_a,
logger)
train(args,
device,
epoch,
model_b,
training_set_b_dataloader,
dataset_option_b,
optimizer_b,
optimizer_option_b,
lr_scheduler_b,
scaler_b,
logger)
if epoch % args.e == 0 or epoch == optimizer_option_a["OPTIMIZER"]["EPOCHS"]:
state_dict_a = model_a.state_dict()
state_dict_b = model_b.state_dict()
state_dict_global = model_global.state_dict()
# average weights
for key in state_dict_a.keys():
state_dict_global[key] = (state_dict_a[key] + state_dict_b[key])/2
model_global.load_state_dict(state_dict_global)
model_global.eval()
acc = validation(device, epoch, model_global, validation_set_dataloader, dataset_option_a, logger)
print(f"acc: {acc}")
checkpoint = {
'epoch': epoch,
'model_state_dict': model_global.state_dict(),
'acc': acc,
}
if best_acc < acc:
best_acc = acc
torch.save(checkpoint, os.path.join(args.save_folder, 'best_acc.pth'))
torch.save(checkpoint, os.path.join(args.save_folder, 'epoch_' + str(epoch) + '.pth'))
# update model_a and model_b by model_global
model_a.load_state_dict(model_global.state_dict())
model_b.load_state_dict(model_global.state_dict())두 Clients 로부터 학습된 Weights 를 Averaging할때, 데이터셋 사이즈가 서로 거의 같았기에 데이터셋 사이즈에 따른 가중적인 Weights을 곱하지 않고 단순하게 산술평균으로 Global Model을 업데이트 했습니다.
먼저, Client A와 Client B를 각각 학습시켰을때와 합쳐서 학습시켰을때의 정확도를 측정해보았습니다. 합쳐서 학습시켰을때의 정확도를 Federated Learning 성능의 상한선이라고 보고 실험을 진행했습니다.
| Dataset | Accuracy(%) |
|---|---|
| Client A | 93.67 |
| Client B | 63.87 |
| Client A + Client B | 98.64 |
다음은 Federated Learning에 대한 실험입니다. 실험 진행시 E 와 상관없이 마지막 에폭에서 aggregation 되도록 했습니다.
| Training Method | Accuracy(%) |
|---|---|
| One-shot Averaging | 0.04 |
| Federated Learning, E =1 | 98.61 |
| Federated Learning, E =5 | 98.50 |
| Federated Learning, E =10 | 98.35 |
| Federated Learning, E =20 | 98.09 |
먼저, 내심 잘되길 바랬던 One-shot Averaging 방법은 제 실험 환경에서는 효과가 전혀 없음을 검증할 수 있었습니다.
또한, E 가 증가할수록 성능이 감소되는 것을 확인할 수 있었습니다.
다음은 epoch별 Validation Set에 대한 정확도 추이입니다. E 가 높더라도 학습이 진행됨에 따라 수렴되는 것을 확인할 수 있었습니다.
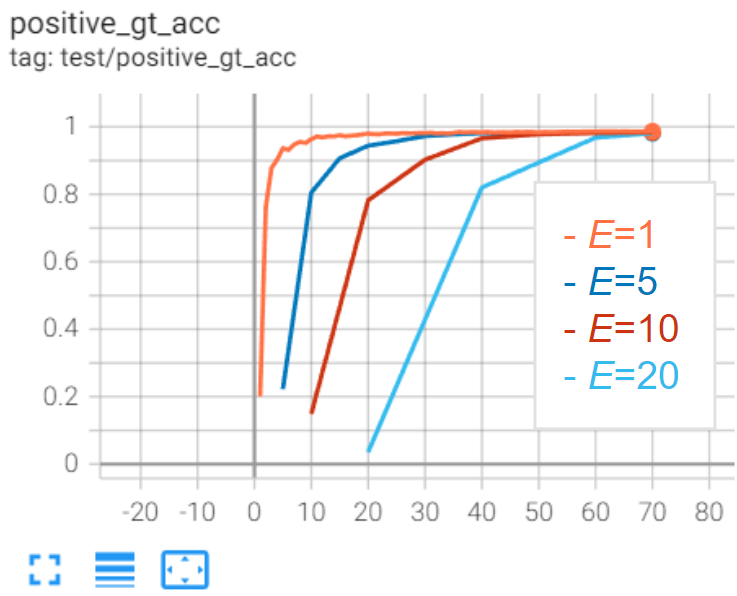
결론
상당히 이상적으로 환경을 세팅해두고 실험을 진행했다는 생각이 많이 들지만 Federated Learning 적용의 긍정적인 가능성정도는 볼 수 있었습니다. 실제로 같은 데이터셋에서 학습되어지는 Weights를 Averaging하여 모델의 성능을 높이려고했던 테크닉은 timm 라이브러리의 ema 기법등으로 접할기회가 있었지만, 다른 데이터셋에서 학습되어지는 Weights 를 Averaging 해가며 학습했을때 성능이 개선될지는 긴가민가했는데 정말 개선이 돼서 놀라웠습니다.
그렇지만... Clients 모델들을 주기적으로 동기화해야한다는 점은 반드시 Server와 Client PC간에 연결이 원활한 환경이 보장되어야함을 의미합니다. 그렇게 되면 Client PC에 존재하는 데이터들이 외부로 유출될 수 있는 환경에 놓이기에 여전히 보안 이슈는 남게 됩니다. 앞으로 현재의 제한된 환경에서 Federated Learning을 정말 적용해보려 한다면 최대한 round 수를 줄일 수 있는 Few-shot, One-shot Federated Learning에 대한 연구를 계속해서 진행해야할 거 같습니다. 그리고, Client측에서의 레이블링에 대한 부담을 최소화할 수 있는 방법들에 대한 연구를 진행해야 할 것으로 판단됩니다.
감사합니다.
참고 자료
Communication-Efficient Learning of Deep Networks from Decentralized Data
Federated Learning: Collaborative Machine Learning without Centralized Training Data
SOO-YONG SHIN/Federated Learning
개인적으로 신수용 교수님의 글을 정말 재밌게 읽었습니다. Federated Learning을 실제로 접목하시려고 하신다면 읽어보시는 것을 추천드립니다.
MARKANY_둘러보기
