
parallel
install
- GNU parallel package: https://ftpmirror.gnu.org/parallel/parallel-latest.tar.bz2
# wget 이나 curl로 위 링크를 받자
$ wget https://ftpmirror.gnu.org/parallel/parallel-latest.tar.bz2
$ tar -jxvf ./parallel-latest.tar.bz2 -C ./- 압축 푼 폴더가서 설치
(parallel-latest.tar.gz2) $ ./configure
(parallel-latest.tar.gz2) $ make
(parallel-latest.tar.gz2) $ sudo make install
Making install in src
...중략
/usr/local/bin...
# 대충 /usr/local/bin에 설치된다는 말
$ which parallel
/usr/local/bin/parallel
# /usr/local/bin에 잘 설치 되었음- man page: https://linux.die.net/man/1/parallel
- 참고 pdf: https://www.gnu.org/software/parallel/parallel.pdf
- 명령어를 argument로 하나씩 pass해서, parallel 하게 동작 시킬 수 있다.
parallel [options] [command] -- [argument ...]
parallel [options] -- [command ...]| Options | Description |
|---|---|
-j <num> | parallel thread 개수의 최대 |
-l <maxload> | 새 job을 시작할 때, 시스템의 로드 평균을 피하기 위해 필요한 wait |
-n | 한번에 커맨드에 pass할 argument의 갯수 (Default is 1)-i와 incompatible |
명령어 실행에 대해 알아야 할 것
$ find ./sstate-cache -name "sstate*" -delete라는 명령이 있다면 이 명령은 single thread로 동작하며,

thread 1개가 열심히 뒤지고 찾을 것이다. 이는 몹시 비효율적이다.
- 그렇다고
$ parallel -j 32 "find ./sstate-cache -name \"sstate*\" -delete"그대로 parallel 만 붙인다고 똑똑하게 처리 하지 않는다. 이대로 처리하면
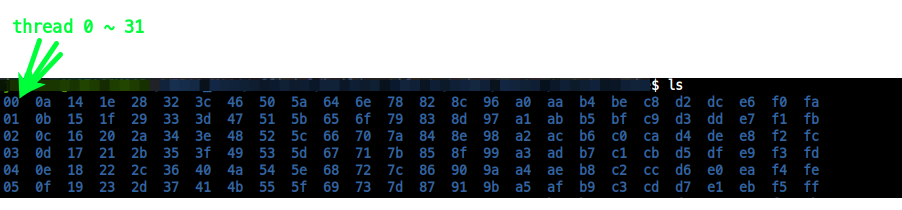
thread 32개가 같은 일을 하는 더 비효율적 동작을 한다.
1. 한 변수에 담기
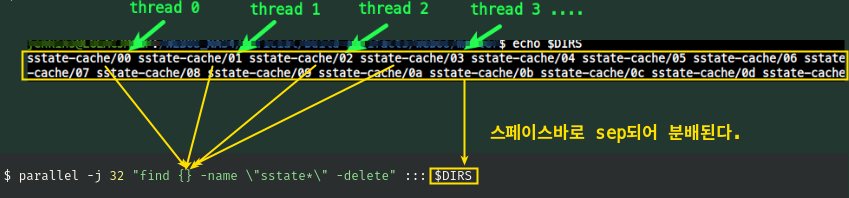
- 그렇다면! 스레드당 한 폴더만 팰수 있게 폴더를 한 변수에 잘 담아 처리해야한다.
- 한 변수 = '각' 디렉토리 경로에 담는다.
$ DIRS=$(find sstate-cache/?? -maxdepth 0 -type d) # 폴더 경로들이 담김- 디렉토리들이 ' ' 스페이스 공백문자를 seperator로 담겨져 있다. 이 것을 parallel에 넘겨야...

3-3. thread 당 분배되어 처리한다.
2. 간단한 디렉토리 삭제
$ # ./BUILD <-- 삭제 대상 디렉토리
$ DIRS=$(find ./BUILD -maxdepth 1 -type d)
$ parallel -j $(nproc) "rm -rf {}" ::: $DIRS3. PIPE 사용하기
- 위에 처럼 한 변수에 담기도, 내부 폴더나 파일이 극악으로 많으면 PIPE로 넘겨주기 방식을 사용하자.

- 혹은
$ find ./<대상> -mindepth 1 -maxdepth 3 -type d > rmlist
$ cat ./rmlist | parallel "rm -rf {}"사용 예
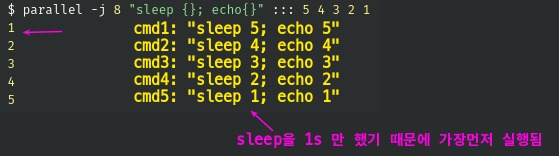
sleep {}; echo{};
$ parallel -j 8 "sleep {}; echo{}" ::: 5 4 3 2 1
1
2
3
4
5- 실행 경과
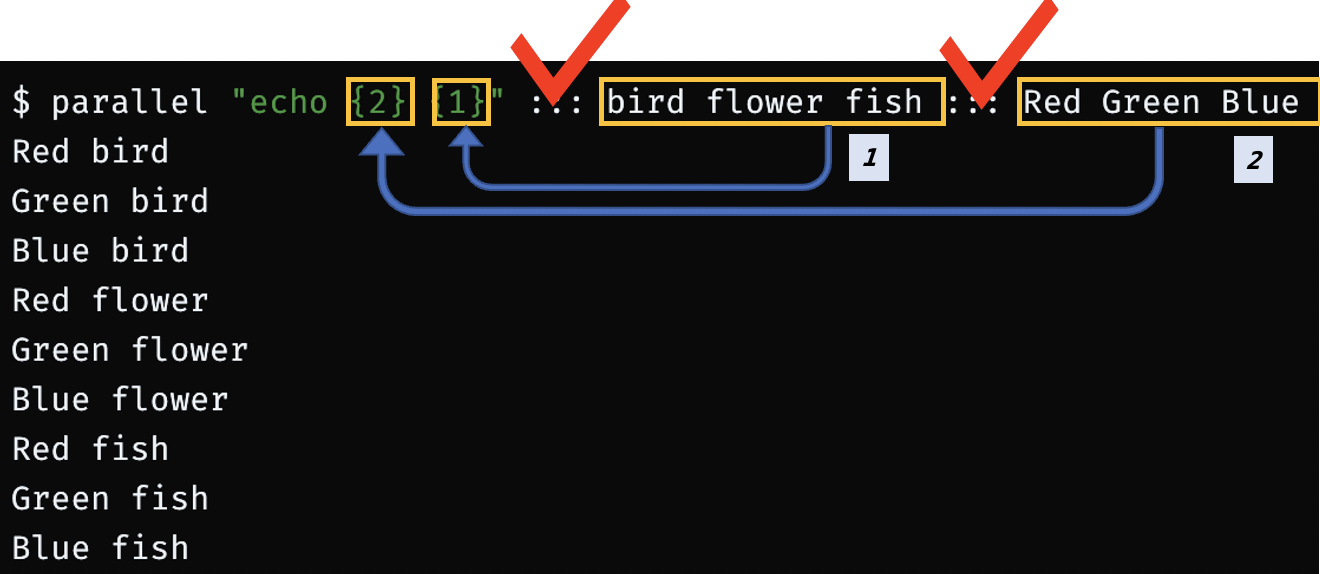
{2} {1} ::: VAR1 ::: VAR2
$ parallel "echo {2} {1}" ::: bird flower fish ::: Red Green Blue- parallel에
{2}와 같이 argument 순서를 지정할 수 있다.
 위와 같이 꼴로 사용되니 주의할 것
위와 같이 꼴로 사용되니 주의할 것
{#}: job sequence
$ parallel "echo {#} {2} {1}" ::: bird flower fish ::: Red Green Blue
1 Red bird
2 Green bird
3 Blue bird
4 Red flower
5 Green flower
6 Blue flower
7 Red fish
8 Green fish
9 Blue fish--keep-order : thread keep in the order
$ parallel --keep-order "echo {#} {2} {1}" ::: bird flower fish ::: Red Green Blue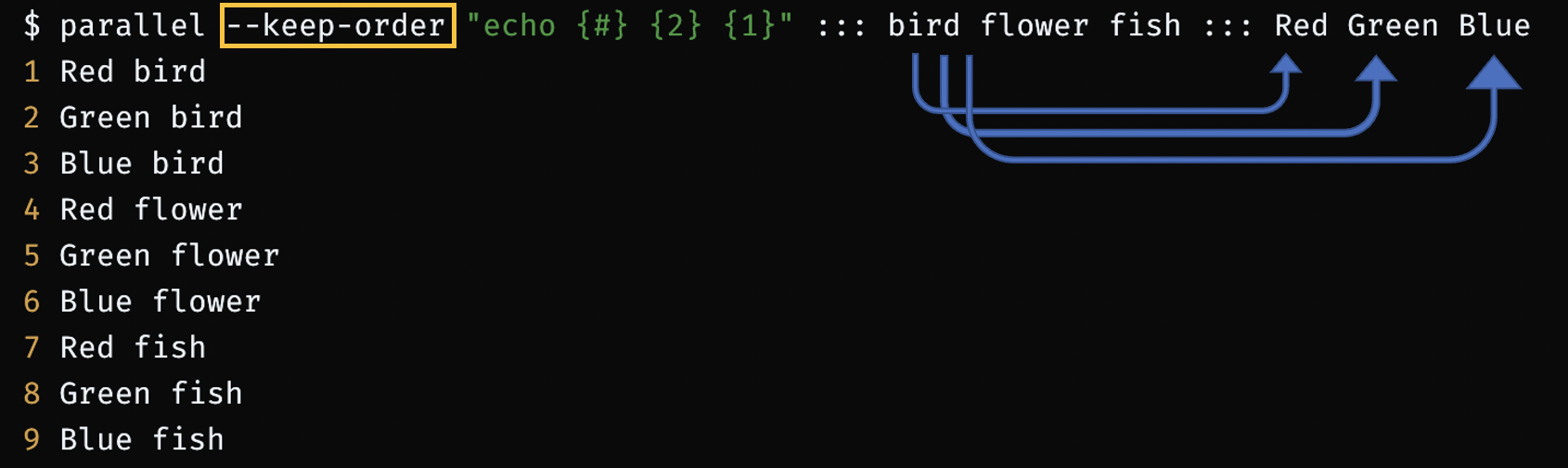
${ARR[@]}: 배열 쓸 경우
CMD+=("'ssh -p 23' mark@10.23.456.7:~")
$ parallel "rsync $HOME/hello.txt -e {}" ::: ${CMD[@]}
# ======== 실제 실행 결과 ========= #
rsync $HOME/hello.txt -e 'ssh
rsync $HOME/hello.txt -e -p
rsync $HOME/hello.txt -e 23'
rsync $HOME/hello.txt -e mark@10.23.456.7:~
과 같이 어이 없는 경우가 생기는데, 이는 parallel 자체가 space를 가지고 알아서 separator 하기 때문임find와 연계
- find와 연계할 수 있다.
- 하지만 그냥 막 쓰지 말고 짱구를 좀 굴려라.
- parallel을 효율적으로 사용하려면 각 Separated dir에 job을 할당하자!!
- 만약에 기존 사용하던 명령어가 아래와 같다고 하자.
$ find ./sstate-cache -mindepth 1 -name "sstate*" -atime +10이 명령어를 어떻게 하면 효율적으로 할 수 있을까?
- 각 디렉토리 別 job을 할당
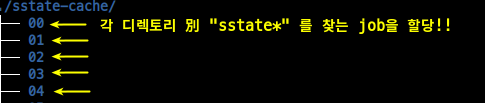
2-1. 하위 디렉토리 경로를 변수에 담자
$ DIRS=$(find ./sstate-cache/* -maxdepth 0 -type d) # DIRS 라는 변수에 그냥 담았음
2-2. 변수를 사용하여 각 디렉토리 別 job 할당
$ parallel -j 64 "find {} -name \"sstate*\" -atime +10" ::: $DIRS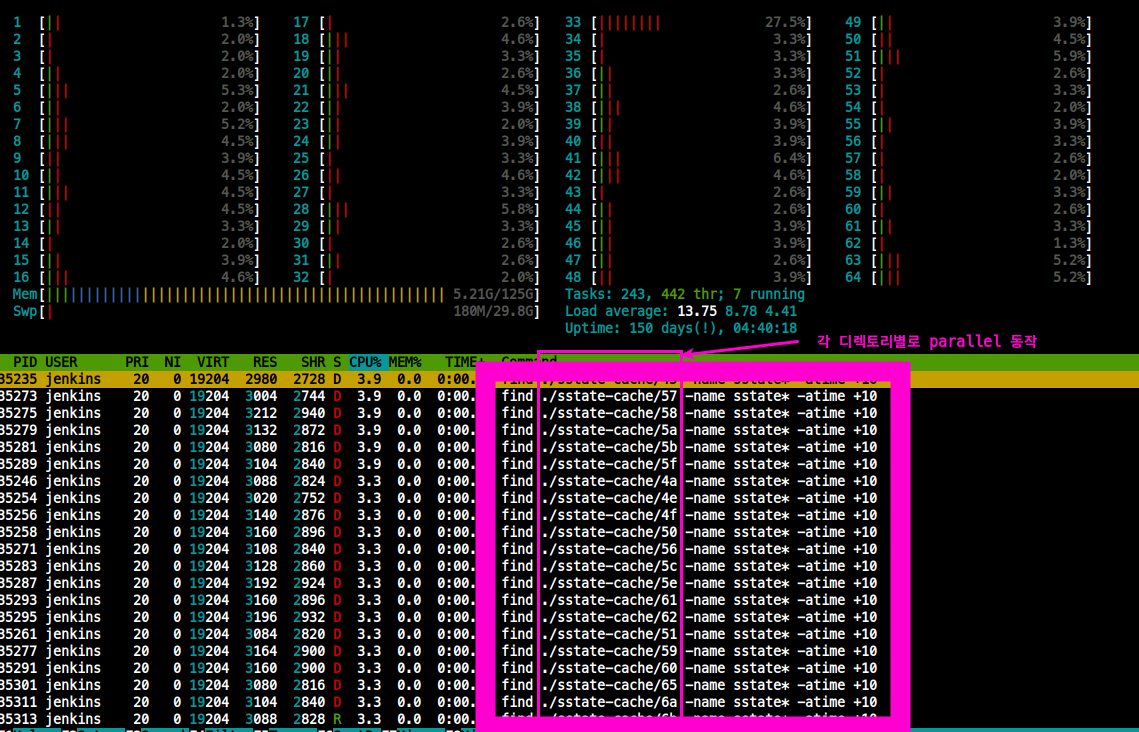
awk와 연계
$ parallel "diskus {} | awk '{if(\$1 >= 300*1024**3) print(\"{}\")}'" ::: $PWD
내가 쓰는 명령어가 잘 먹히나?
- 역시 먼저 echo로 확인해보는게 낫다...
parallel "echo {1} {2}" ::: ${ARR1[@]} ::: ${ARR2[@]}xargs
xargs는 1)기본적인 명령어 뒤에 파이프로 추가해 사용 2) 파이프 이전에 명령을 인자로 받아 명령어를 실행
$ xargs [option] 명령어| option | Description | e.g. |
|---|---|---|
-a | 표준 입력 대신, 파일에서 항목을 읽음. 이 옵션을 사용하여 명령을 실행하면 stdin은 변경되지 않는다. 그렇지 않으면 stdin이 /dev/null에서 리다이렉션 된다. | |
-0--null | 공백이나 특수 문자를 찾을 때 사용 (문자를 그대로 사용) | find /opt -name "*.[ch]" | xargs touch: 여기서 파일 이름에 공백이 있을 경우 각각 분리된 파일로 넘겨지는데,find /opt -name "*.[ch]" -p print0 | xargs -O touch 형식으로 사용하면 -print0는 파일 사이의 공백을 \0으로 분리자로 출력하고 xargs는 \0으로 표시된 분리자를 인식하여 하나의 파일이름으로 인식하고 다음 인자로 넘어감 |
-d | 입력된 문자를 그대로 사용한다. (", \) 단순히 문자가 스페이스로 분리되어 있을 때, 사용 가능 하지만 다른 인수와 같이 처리되는 데는 불가능 | |
-n | 지정된 숫자만큼 행 출력 앞에서 들어오는 인자의 수를 제한한다. | |
-p | 사용자에게 각 명령 행을 실행할지 여부, 터미널에서 행을 읽는 것에 대한 여부 묻는다. (yes/no) | |
-P | 하나의 명령에 프로세스를 지정한다. -n옵션과 같이 사용한다.0으로 지정시 한번에 사용할 수 있는 프로세스를 모두 사용한다. | |
-t | xargs를 통해 구성된 명령어를 표준 에러로 출력 (디버깅 시 유용) | |
-s | 한 라인에 들어갈 수 있는 문자열 수 지정 기본적으로 128K 안으로 문자열을 만들어 하나의 명령을 실행하나 해당 옵션은 최대 1024K까지 사용 가능하게 한다. | |
-x | -s로 지정한 크기가 초과되면 종료시킨다. | |
--show-limits | xargs의 버퍼 크기 선택 및 -s 옵션에 대한 길이 제한 출력 | |
-E | 문자열 끝을 eof-str로 설정한다. | |
-I | xargs에 전달된 라인 전체를 뒤에 나오는 명령어의 인자로 사용 | - |
-i | xargs에 전달된 라인 전체를 {} 로 인자로 사용함 | find . -name "*.c" | xargs -i sh -c 'echo -n {} >> c_file.txt; stat -c %Y {} >> c_file.txt': 하위 모든 폴더에서 .c로 끝나는 파일들을 찾아 파일이름과 날짜를 c.file.txt에 저장 |
-l | 해당 명령을 사용하면, 명령어 뒤에 공백이 있으면 다음행으로 인식하는게 아닌 다음 줄에 입력 라인에 있어도 논리적으로 이어지게한다. 이 옵션을 사용하면 읽어들이는 각 행은 내부적으로 버퍼링된다. -l옵션만 사용하는 경우 허용하는 버퍼의 상한이 있어 제한이 걸리는데, 대량의 파일이나 행을 읽어들이는 경우 -s옵션과 함께 사용하면 -s옵션으로 지정된 버퍼 크기를 늘릴 수 있으며 매우 긴 행이 발생되지 않도록 할 수 있다. | |
--null | xargs로 넘어오는 인자에 NULL문자 (\0)가 있으면 NULL을 문자열의 끝으로 인식함 | 예제 2. 참고 |
예제
1. $ ls <PATH> | xargs CMD{}
ls명령으로 나오는 출력을 PIPE로 연결해 1줄 씩 명령을 실행하는데, 동시에 5개 프로세스 사용
$ ls ./sstate-sync | xargs -i -P 5 -n 1 bash -c "rsync -aq {} /DST_PATH"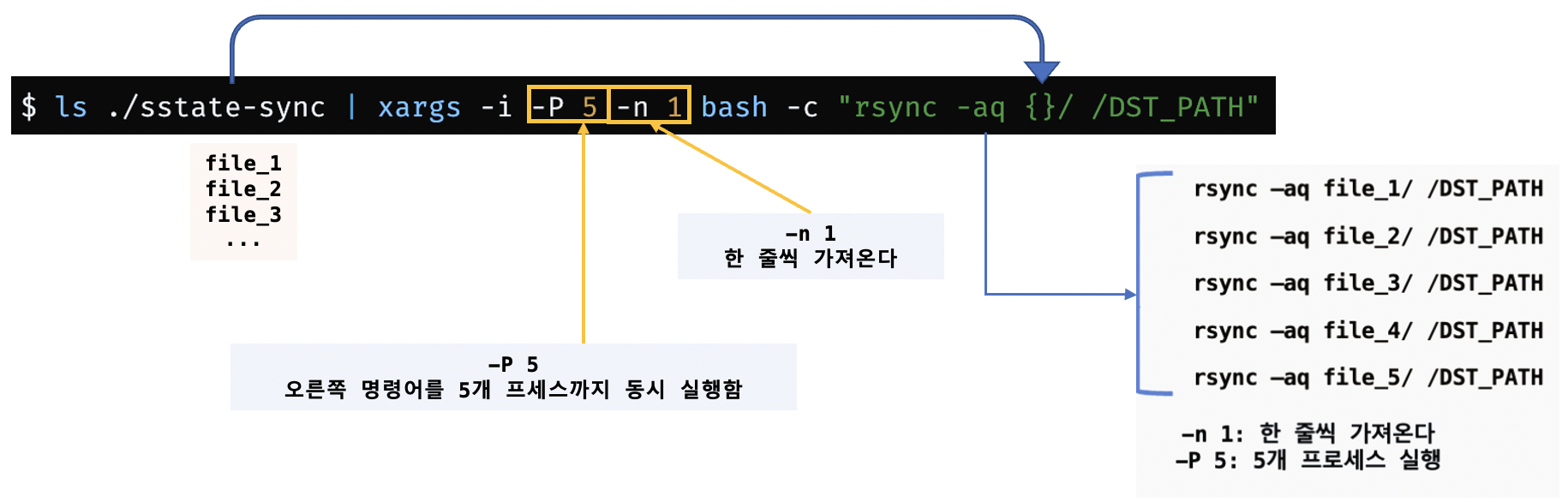
- 주의!!!!:
ls명령어는 절대경로로 출력되지 않음!!- 그래서,
$ ls ./sstate-sync | xargs -i P 5 -n 1 bash -c "rsync -aq {} /DST_PATH하면,{}속에 스크립트 현재 스크립트 위치 기반인"${PWD}/'ls 출력물'"이 담긴다.
- 그래서,
2. 명령어에 '공백'이 있으면 \0 로 넘기기!
CMD="'ssh -p 22' mark@10.100.12.1:~/hello.txt"
위 명령어는 '공백'이 포함되어 있음. 따라서 공백 명령어 끝에 \0(NULL) 문자 넣고,
xargs에서는 -0(--null) option을 주어 null 문자를 만날 때 까지 한 명령이라고 보게 해야함.
CMD="'ssh -p 22' mark@10.100.12.1:~/hello.txt\0" # 마지막에 \0 문자 추가
echo "$CMD" | xargs -i -0 bash -c "rsync {}"
- 잘못된 명령
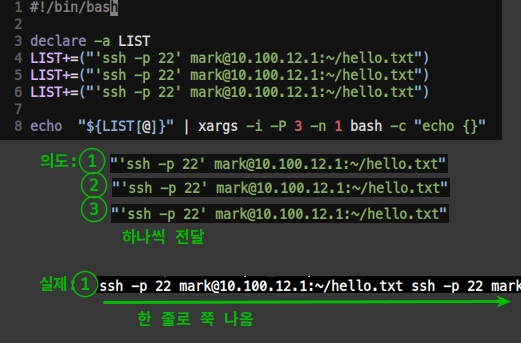
- 의도는 배열 내, 하나의 idx씩 넘어가길 바람 (실제로 idx 0,1,2에 들어가있음)
- 하지만 실행 시, 한줄로 쭉 이어져서 나옴
- PIPE로 보내는 echo에
-e옵션 추가, 각 배열 문자열 마지막에\0문자 추가,xargs --null추가
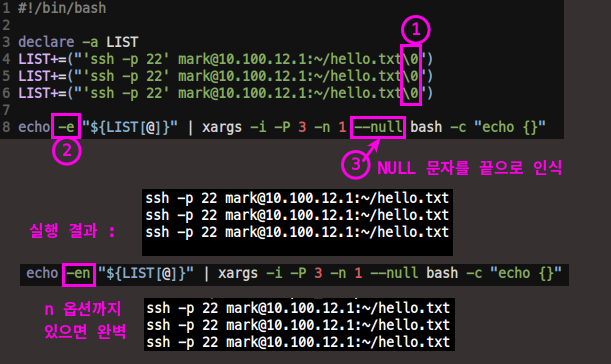
#!/bin/bash
declare -a LIST
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
echo -en "${LIST[@]}" | xargs -i -P 3 -n 1 --null bash -c "echo {}"
# ======= 출력 ======= #
ssh -p 22 mark@10.100.12.1:~/hello.txt
ssh -p 22 mark@10.100.12.1:~/hello.txt
ssh -p 22 mark@10.100.12.1:~/hello.txt- rsync 사용해보면?
#!/bin/bash
declare -a LIST
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
LIST+=("'ssh -p 22' mark@10.100.12.1:~/hello.txt\0")
echo -en "${LIST[@]}" | xargs -i -P 3 -n 1 --null bash -c "rsync -av file1 -e {}"
# ============================================================================================ #
rsync -av file1 -e 'ssh -p22' mark@10.100.12.1:~hello.txt
로 잘먹음3. xargs " " , xargs ' '
$ echo ar1 ar2 ar3 | xargs bash -c "echo $0 $1 $2"
-bash
$ echo ar1 ar2 ar3 | xargs bash -c 'echo $0 $1 $2'
ar1 ar2 ar3
" "를 사용하면 child shell 의 argument가 됨' '를 사용하면 xargs 의 argument가 됨

pllpokko@alumni.kaist.ac.kr