'단단한 머신러닝' 책과 스터디 내용을 기반으로 작성하였습니다.
2.1 경험오차 및 과적합
- 오차율: 전체 샘플 수()와 잘못 분류한 샘플 수()의 비율,
- 오차: 학습 데이터의 실제 예측값(모집단의 회귀식 추정)과 샘플의 실제 값 사이의 차이
- 훈련(경험) 오차: 훈련 데이터 상에서 만들어낸 오차
- 일반화 오차: 새로운 샘플(데이터) 상에서 만들어낸 오차
일반화 오차가 가장 작은 모델이 바람직하지만 현실에서 새로운 데이터를 미리 구하기란 어렵습니다.
따라서 경험 오차를 최소화하는 방법을 찾는 것이 중요!!
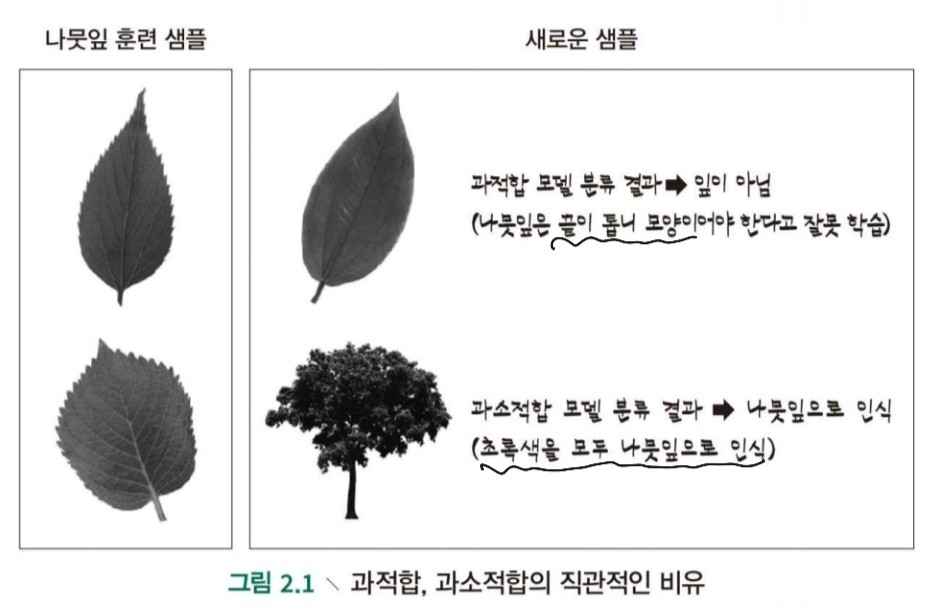
-
과적합
-
모델이 훈련 데이터로 학습을 '과도하게' 하여 훈련 데이터만의 특성을 모집단 데이터에 내재된 일반 성질이라고 학습되는 경우
-
때문에 새로운 샘플에 대한 성능이 떨어집니다.(일반화 성능 하락)
-
이에 대한 대비책을 학습 알고리즘들은 가지고 있습니다.
-
Regularization: 가중치 규제
- L1 규제(Lasso): 이상치에 강하고 중요한 변수들만 남습니다.
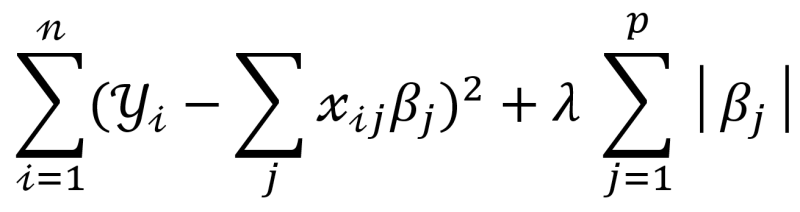
- "+" 기준으로 좌측에 있는 식이 MSE를 나타내고 있습니다.
- 우측에 있는 식이 Lasso 규제를 말하고 있는데 절댓값으로 처리되어 더해지고 있습니다.
- 값이 작아질수록 영향도가 줄어듭니다.
- 커질수록 변수들을 줄여가면서 일반화성이 증가합니다.
- L2 규제(가중치의 제곱): 특정 가중치가 비이상적으로 커지는 것을 방지합니다.

- "+"기준으로 좌측에 있는 식이 MSE를 나타내며 우측에 있는 값으로 영향을 주고 있습니다.
- 값이 커질수록 크기가 큰 계수를 줄이는 역할을 하며 완전히 0으로 수렴하지는 않습니다.
- L1 규제(Lasso): 이상치에 강하고 중요한 변수들만 남습니다.
-
Dropout
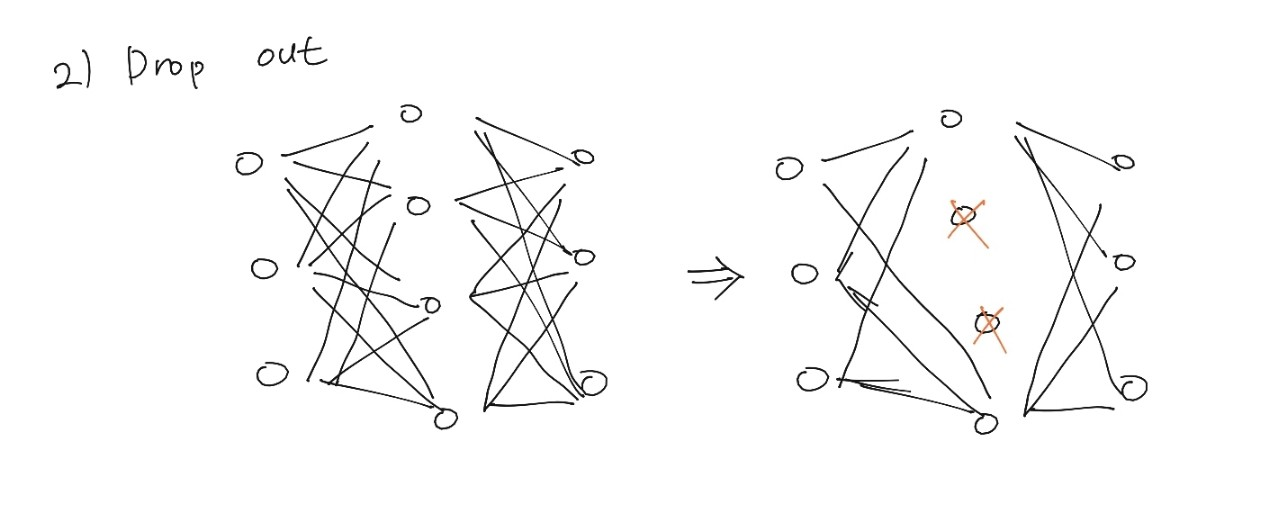
- 전결합 층에서 일부 뉴런이 제거, 특정 설명변수의 과도한 집중 방지
- 훈련에만 사용하며 검증이나 테스트에서는 사용하지 않습니다.
- 앙상블의 효과도 있습니다.
-
Early stopping: 검증손실이 개선되지 않을 때 학습을 중단시키는 역할
-
앙상블: 취약한 학습기를 모두 결합하여 더 정확한 결과 생성
- 배깅: 복원 추출 방식으로 사용될 특성을 뽑아 여러 번 반복하여 결과를 집계하여 사용합니다.
- 부스팅: 가중치를 활용하여 약한 분류기를 점점 강한 분류기로 만드는 방식입니다.
-
데이터 증강: 모델이 처리할 때 마다 조금씩 데이터를 변형하는 기술
-
-
과소적합
- 과적합의 반대로 모델이 훈련 데이터에 대해 학습을 잘하지 못한 경우
- 과적합에 비해 극복하기 수월합니다.
- 학습의 강도를 강하게 하기위해 데이터를 추가
- 의사결정 트리의 경우 가지치기를 더 진행
- 신경망 학습의 경우 에포크(순전파와 역전파가 끝난 상태)의 횟수 증가
우리는 과적합을 완화하고 과적합이 일으키는 위험을 최소화하는 것에 만족해야 합니다.
2.2 모델 선택과 데이터 분리
1) 모델 선택
-
다양한 선택지의 학습 알고리즘들이 있는데 어떤 알고리즘, 어떤 파라미터를 사용해야 하는지는 "모델 선택"의 문제입니다.
-
테스트 샘플이 실제 샘플과 동일한 분포를 보이고 있다는 가정이 필요합니다.
+ 테스트 데이터와 훈련 데이터는 중복X -
테스트 세트를 활용하여 나타나는 테스트 오차는 실제 일반화 오차의 근삿값입니다.
우리가 모델의 학습을 통해 얻고자 하는 범용성은 더 어려운 문제를 해결할 수 있는 능력을 키우기 위함입니다.
- 테스트 데이터와 훈련 데이터의 중복은 시험 문제와 기출 문제가 동일한 것입니다.
-
데이터 세트를 적절히 처리(전처리)하여 훈련 세트와 테스트 세트로 잘 나누어 훈련과 평가를 진행하여야 합니다.
2) 데이터 분리
- 홀드 아웃(Hold-out)
- 데이터 세트가 겹치지 않는 임의의 두 집합으로 분할
- 가능하다면 데이터 분포를 동일하게 나누어야 합니다.
- 데이터가 많은 경우 잘 동작하지만 적은 경우 잘 동작하지 않을 수 있습니다.
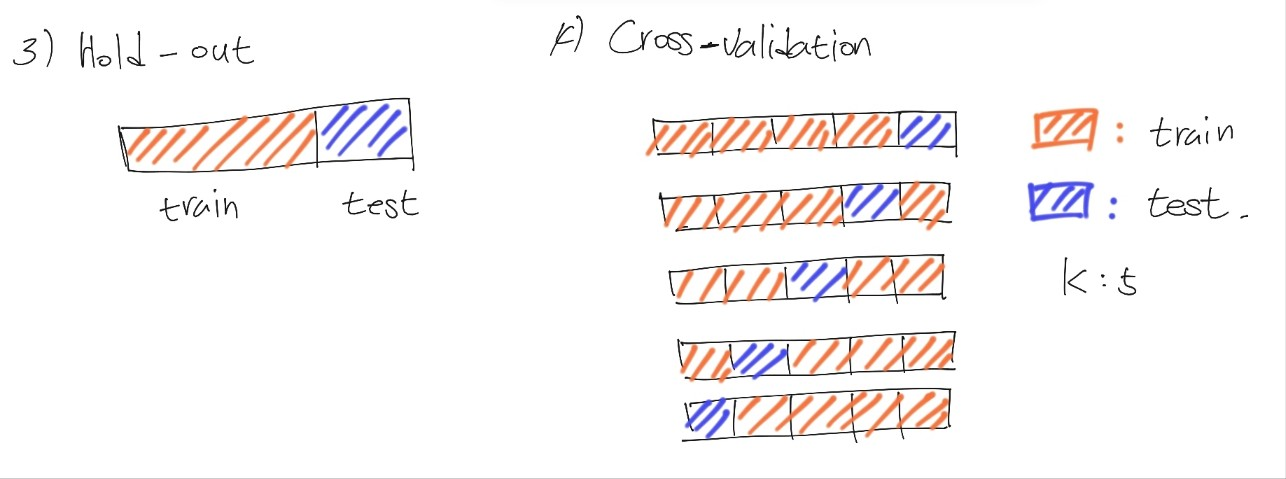
- 교차 검증(cross validation)
- K-Fold 교차검증
- 데이터 세트를 k개의 서로소 집합(공통원소가 없는 집합)으로 나누어 개의 부분집합을 학습 데이터로, 1개의 부분집합을 테스트 데이터로 사용합니다.
- 평가 결과의 안정성은 k의 값에 따라 달라집니다.
- 부트스트래핑
- 복원추출 방식으로 진행(여러 번의 훈련 데이터 생성)
- 수학적으로 계산할 경우 확률적으로 36.8%는 선택받지 못합니다.
- 데이터 셋이 비교적 적거나 훈련/테스트 데이터로 분류하기 힘든 경우에 주로 사용
+ 앙상블에 적용하기 용이- 생성된 데이터 세트들은 모집단 데이터 분포와 다를 수 있기에 편향 가능성 존재
- 앙상블에는 Bagging과 Boosting이 존재
- Bagging
- Bootstrap으로 조금씩 서로 다른 훈련 데이터를 생성하여 병렬로 처리하여 결과를 결합하는 방식
- 대표적으로 Randomforest 모델이 있습니다.
- Boosting
- 잘못 분류된 객체들에 집중하여 새로운 분류 규칙을 생성하는 단계를 반복하는 순차적인 학습 알고리즘
- 오답에 높은 가중치를 부여하고 정답에 낮은 가중치를 부여하여 오답을 정답으로 바꾸는데 집중하는 것입니다.
- 배깅에 비해 성능이 좋으나 속도가 느리고 과적합의 가능성이 있습니다.
- 데이터의 보유량이 적을 경우 Hold-out과 k-fold 방식을 자주 활용
3) 파라미터 튜닝과 최종 모델
-
알고리즘 파라미터
- 'Hyper parameter'라고 인지되는 파라미터들
- hidden state의 수, 학습률의 크기, k-nn에서의 k, ... 등
- 사용자가 직접 결정해주어야 하는 값
-
모델의 파라미터
- 모델 내부에서 결정되는 파라미터
- 데이터에 의해 자동으로 결정되는 값
- 회귀모델에서의 계수, 딥러닝 모델에서의 가중치 등
학습 알고리즘의 많은 파라미터는 실수 범위의 값을 가집니다.
경우의 수가 매우 많습니다. -
모델 선택과 파라미터 조율을 위해 테스트 데이터를 사용하기 전에 검증 데이터 집합을 추가로 분리하여 모델과 파라미터 조율을 진행할 수 있습니다.
결과적으로 데이터는 훈련/검증/테스트로 나누어집니다.
먼저 (훈련/검증)과 테스트로 나뉘고 훈련과 검증 데이터로 나눕니다.
2.3 모델 성능 측정
1) 평가지표
-
모델의 일반화 성능을 평가할 기준
-
프로젝트의 목적이 반영되어야 합니다.
- 회귀분석 - 평균제곱오차(),
- 기본적으로 회귀 모델에 많이 사용되는 평가지표, 이상치에 민감한 반응을 보입니다.
- 과도하게 커지는 평가지표를 두 가지 방법으로 낮추어 표현한 것이 MAE와 RMSE입니다.
- 오차들의 절댓값 평균으로 모든 샘플에 대한 오차에 동일한 가중치를 두고 있습니다.
- 상대적으로 이상치에 둔감합니다.
- 샘플들의 오차에 제곱한 값들의 평균을 제곱근한 값으로 오차들의 가중치가 같지 않습니다.
- 0과 1사이의 값들은 작은 가중치를 가지고 1을 초과하는 값들은 더 커진 오차값을 가집니다.
- 상대적으로 이상치에 민감합니다.
- 독립변수가 종속변수를 얼마나 설명하고 있는지를 나타내는 지표
- 평균과 실제 값의 면적값의 합으로 알고리즘으로 예측한 값과 실제값의 면적을 나누어 줍니다.
- (조정된 결정계수)
- 독립변수의 수가 증가하면 일방적으로 결정계수가 증가하는 단점을 극복
- 유용한 독립변수이면 값이 증가하고 유용하지 않으면 값이 감소합니다.
- 여러 평가 지표들을 바탕으로 종합적인 판단을 해야 합니다.
- 같은 MSE값이 나타난 모델이라도 MAE나 RMSE 값에 차익가 있으면 이상치의 분포 부분에서의 차이를 고려할 수도 있습니다.
-
분류분석 - 정확도, 오차율, 정밀도, 재현율, F1_score
-
Confusion Matrix
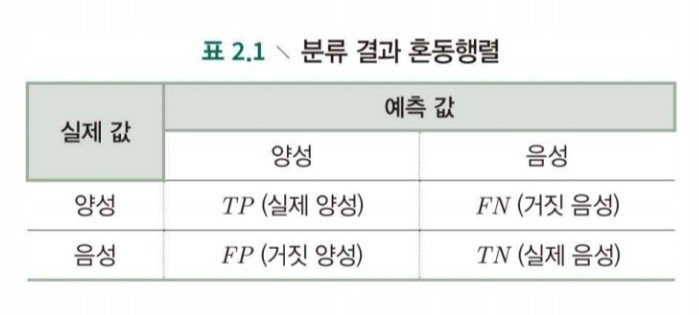
-
정확도(Accuracy):
- 전체에서 정확하게 분류한 비율
-
정밀도(Precision):
- 실제 Positive인 예측값 중 True인 비율, 양성 판정을 받은 사람 중 실제 병에 걸린 비율
-
재현율(Recall=Sensitivity):
- 실제 True(병에 걸린)인 사람 중 Positive(양성 판정) 예측을 받은 사람의 비율, 예측하지 못하는 것에 주의를 기울입니다.
-
특이도(Specify):
- 실제 True(병에 걸리지 않은 사람) 중 Negative(음성 판정을 받은 사람)인 비율
-
F1-score:
- 정밀도와 재현율의 조화평균으로 데이터 label이 불균형으로 구성되어 있을 경우에도 정확한 성능을 살펴볼 수 있습니다.
- 조화평균을 사용한 이유는 큰 비중의 bias가 미치는 영향이 줄어들기 때문입니다.
-
평가지표들은 종속변수의 class 별로 나타나게 되는데 이것까지 모두 고려하여 평가지표를 고려하고자 할 때 Macro와 Micro 평균을 구하는 방법이 있습니다.
- Macro
: 모든 혼돈 행렬의 대한 정밀도와 재현율을 계산하고 이를 평균한 값이 Macro입니다. - Micro
: 혼돈 행렬에 나타나는 TP, FP, TN, FN끼리의 평균을 먼저 구하고 이를 바탕으로 평가지표를 계산하는 경우 입니다. - 클래스 불균형(Imbalance) 문제가 있는 데이터셋에서는 Micro-average가 조금 더 효과적인 평가지표로 사용됩니다.
- Macro
-
- 회귀분석 - 평균제곱오차(),
-
P-R 그래프
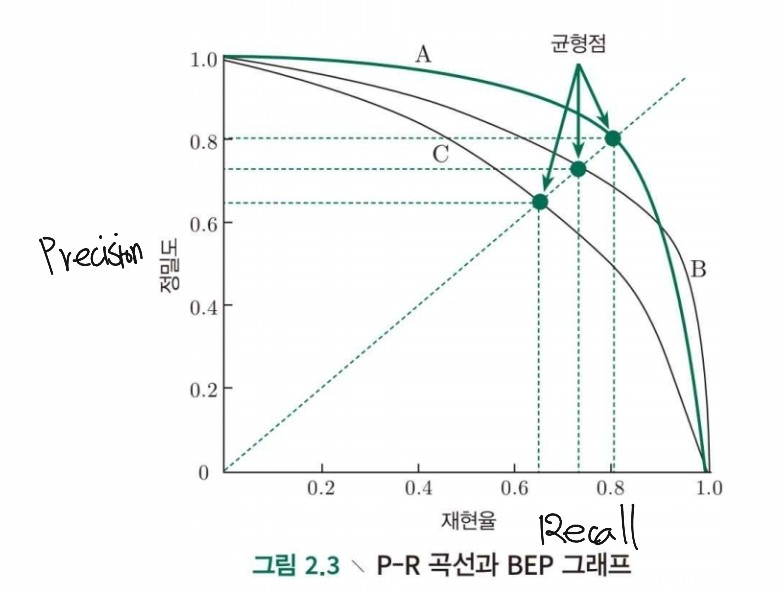
- 모델 C의 경우 모델 A와 B에 완전히 포함되기에 학습 성능이 떨어진다고 볼 수 있습니다.
- 모델 A와 B의 경우 성능차이를 간단하게 비교하기 어렵기에 합리적으로 아래면적의 크기를 비교하는 방법이 있습니다.
- 계산하기 어렵기 때문에 재현율과 정밀도를 고려한 지표를 만들게 되었는데 이 중 하나가 F1-Score입니다.
-
ROC와 AUC
- TPR(참 양성률)과 FPR(거짓 양성률)을 이용하여 각각 세로축과 가로축에 배치합니다.
- ROC의 경우도 P-R 그래프와 동일하게 포함되는 형태의 모델은 성능이 상대적으로 떨어지며 합리적인 판단 방법으로 면적 비교 방법인 AUC를 활용합니다.
-
P-R곡선과 ROC의 차이
- P-R곡선은 trade-off 관계를 고려하여 판단해야 할 경우나 unbalance한 경우 많이 사용합니다.
- ROC의 경우 일반적으로 많이 사용되는 지표입니다.
2.4 비교 검증
-
성능 비교에 앞서 다음의 고려사항들이 있습니다.
- 모델의 일반화 성능의 비교입니다.
- 테스트 세트 성능은 테스트 세트 그 자체와 큰 상관관계가 있습니다.
+ 다른 크기의 테스트 세트를 사용하면 결과는 달라질 것입니다.
+ 같은 크기의 데이터 세트를 사용하더라도 포함된 데이터가 다르면 결과값이 달라집니다. - 모델은 자체적으로 일종의 무작위성을 포함하고 있습니다.
-
통계가설 검정은 모델의 성능을 비교하기에 중요한 근거를 제공합니다.
-
모델이 A가 B보다 테스트 데이터 세트에서 성능이 좋다면 일반화 성능이 통계적으로도 좋은 것인지 알 수 있습니다.
1) 가설검정
-
가설
- 어떤 사실을 설명하거나 증명하기 위한 가정
- 두 개 이상의 변수의 관계를 검증 가능한 형태로 기술하여 변수 간의 관계를 예측하는 것을 의미
- 책에서는 오차율을 기준으로 설명
- 직관적으로 테스트 오차율은 일반 오차율과 크게 다르지 않을 것입니다.
- 오차율 분포에 관한 모종의 판단 or 가정
같은 모델의 경우
- 이항검정
ex) 해당 데이터 셋의 오분류율(오차율)이 0.3일 때, 10개의 샘플 중 3개가 잘못 분류될 확률이 높습니다.- 각 모델이 제시한 테스트 오차율에 관하여 적용합니다.
- T-검정
- k개의 테스트 오차율을 가지고 있을 때 이들의 평균 오차율과 분산을 구할 수 있습니다.
- 유의성 (0.01, 0.05, 0.1)에 대해 (1-유의성) 확률 내에서 관측 가능한 최대 오차율인 임곗값을 계산할 수 있다.
- 양측 검정을 기준으로 평균 오차율과 개인 오차율의 차이가 임곗값의 범위 내에 있다면 테스트 오차율의 평균이 모집단의 평균 오차율과 동일하다는 가설을 기각할 수 없습니다.
다른 모델의 경우 - 하나의 데이터 셋
- 교차검증 T-테스트
- 중요한 전제조건
- 테스트 오차율은 일반 오차율의 독립 표본이라는 가정
- 두 개의 모델에 대해 k-fold 교차검증을 한다면 테스트 오차율들을 얻을 수 있습니다.
- 두 모델의 k번째 모델은 동일한 훈련/테스트에서 산출된 값일 것이며 대응표본 T-검정으로 비교가 가능합니다.
- 기본적인 가정은 "두 모델의 테스트 오차율이 동일할 것"입니다.
- k겹 교차검증으로 만들어진 k-쌍의 테스트 오차율에 대해 매 쌍의 결과의 차를 구합니다.
- 이 차이값들의 평균과 분산을 통해 임계값을 구하고 해당 임계값 보다 작을 경우 가설을 기각할 수 없습니다.
- 교차 검증 중 일부 교차 검증의 방법의 경우
- 완화하기 위해 2겹 교차검증을 5번 반복
- 이들의 평균과 분산을 이용하여 임계값을 구합니다.
- 중요한 전제조건
- 이항검정
2) 맥니마 검정
- 각 관측치 간의 독립성이 만족하지 못할 경우 사용합니다.
- 독립성을 만족할 경우 카이제곱 검정을 시행하면 됩니다.
- 가설은 "두 모델의 성능이 같다"이며 오차율이 같아야 합니다.
- 유의성이 임계값보다 작을 경우 가설을 기각하지 못합니다.
2.5 편향과 분산
- 편향과 분산 분해는 학습 알고리즘의 일반화 성능을 해석할 수 있는 중요한 도구입니다.
- 기본적으로 모델이 심화되면 편향이 작아지고 분산이 커지는 모습을 보입니다.
- 학습 알고리즘의 기대 일반화 오차를 분해합니다.
- 일반 오차는 편향, 분산, 노이즈의 합으로 분해할 수 있습니다.
- 편향: 학습 알고리즘의 기대 예측값이 실제 데이터에서 떨어진 정도
- 학습 알고리즘의 능력
- 분산: 크기가 같은 데이터 셋의 변화가 있을 때 발생하는 성능의 변화
- 충분한, 적합한 데이터
- 노이즈
- 학습문제의 본질적인 난이도
편향과 분산이 모두 낮은 경우가 제일 좋지만 일반적으로 편향과 분산은 상충하는 부분이 있습니다.
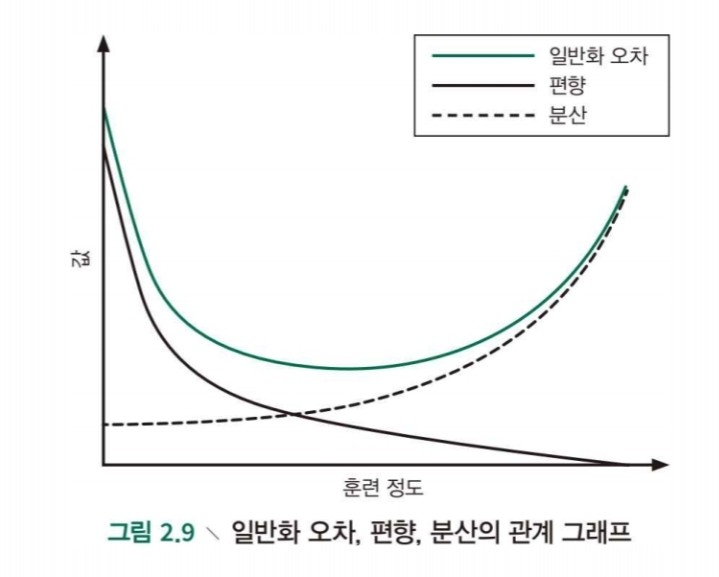
- 알고리즘의 훈련 정도를 지정할 수 있다고 가정
- 훈련이 부족하면 적합능력이 떨어지지만 데이터가 조금 변경된다고 해서 성능에 크게 변화가 오지는 않습니다.
- 따라서 편향이 원인이라고 생각될 수 있습니다.
- 모델의 훈련이 깊어지고 판단된 이후의 변화는 분산이 오차율의 원인이라고 생각될 수 있습니다.
- 훈련이 충분하고 적합 능력이 좋음에도 발생하는 변화는 과적합입니다.
