'단단한 머신러닝' 책과 스터디 내용을 기반으로 작성하였습니다.
4.1 의사결정 트리
1) 의사결정 나무
- 데이터 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타냅니다.
- 질문에 대한 작은 결정 및 작은 판단들을 통해 최종 결정을 진행합니다.
- 판단들로 분기되는 모양이 나무와 같아 트리 구조라고 불립니다.
- 일반화 성능이 뛰어난 트리를 얻는 것이 목표입니다.
2) 구조
-
root node: 초기 지점, 뿌리마디 입니다. 최초의 분기 조건이 있습니다.
-
internal node: 중간에 속해있는 노드
-
leaf/terminal node: 자식 노드가 없는 노드
4.2 분할 선택
노드의 순수도(Purity)가 높을수록 좋습니다.
1) 정보 이득
- 정보 엔트로피: 순수도를 측정하는데 자주 사용되는 지표
- 정보 엔트로피값이 균일하다면 아무 속성이나 선택하여 분할을 진행하면 됩니다.
- 정보 이득은 속성값의 종류가 많을수록 유리하게 작용합니다.
- 특정한 편향이 발생할 수 있습니다.
2) 정보 이득율
- 정보 이득을 속성의 내재값으로 정규화
- 내재값: 특정 속성을 사용하여 데이터를 분할할 경우 발생하는 분할의 균등정도
- 속성값의 종류가 많을수록 유리하게 작용하는 것을 방지
단순히 정보 이득율만이 아닌 정보이득이 평균보다 높고 이득률이 가장 높은 것을 선택
3) 지니계수
- CART 의사결정 트리에서 노드의 순도를 측정하는데 사용
- 한 노드의 모든 샘플이 같은 클래스에 속할 경우, 지니 불순도는 0이 되고 여러 클래스에 고르게 분포되어 있으면 지니 불순도는 1에 가까운 값이 됩니다.
- 따라서 지니 계수가 작은 속성을 분할 속성으로 사용합니다.
4.3 가지치기
- 과적합에 대응하기 위한 주요수단
- Greedy Algorithm으로 최대한 정확할 때까지 반복적으로 가지를 생산합니다.
1) 사전 가지치기
- 트리의 깊이나 필요한 leaf node의 수를 제한하여 과적합을 예방합니다.
- 사전에 예측하여 특정 깊이에 도달하면 멈추거나 포함하고 있는 데이터의 최소 갯수 등을 조정하여 조기에 종료하는 방법입니다.
2) 사후 가지치기
- 모델 생성을 끝내고 적은 데이터를 가지는 leaf node를 제거하여 과적합을 방지합니다.
- 상대적으로 일반화 성능이 더 높습니다.
- 훈련 시간이 깁니다.
4.4 연속값과 결측값
1) 연속값
- 연속 속성의 이산화 작업이 필요합니다.
- 이분법
- 임곗값을 기준으로 2개의 데이터 셋으로 분할합니다.
- 정보 이득을 최대화하는 방향으로 분할점을 찾아 분할합니다.
2) 결측값
- 다양한 이유들로 데이터가 수집되지 못하거나 누락되는 경우
- 결측값이 없는 샘플에 의존하여 속성들에 대한 정보 이득을 측정
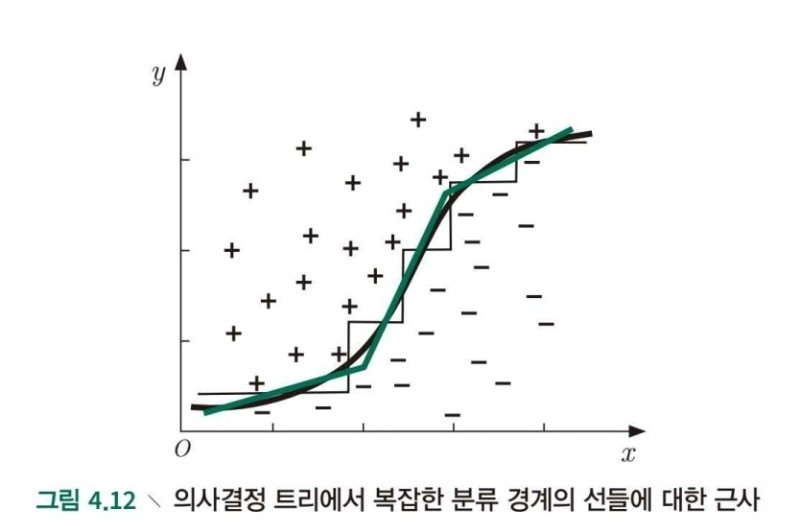
4.5 다변량 의사결정 트리
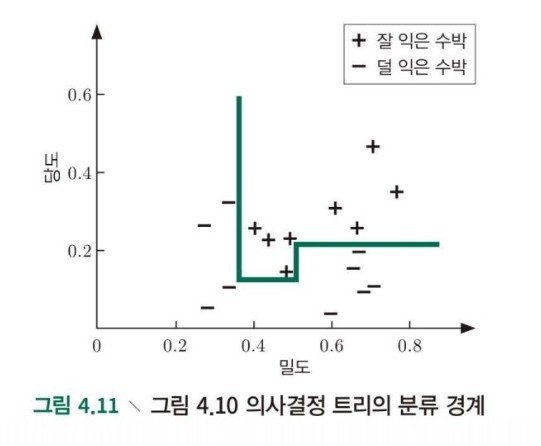
1) 기존 의사결정 나무
- 분류 경계선이 축에 평행합니다.
- 분류 경계는 비교적 높은 해석력을 가집니다.
- 현실의 문제는 많이 복잡할 것입니다.
2) 다변량 의사결정나무
- 각 분할에서 단일 속성 대신 여러 속성의 조합을 사용하여 결정을 내립니다.
- 대각선 분할을 통해 복잡한 분할을 진행합니다.
- 적당한 선형 분류기를 만드는 것이 목적입니다.