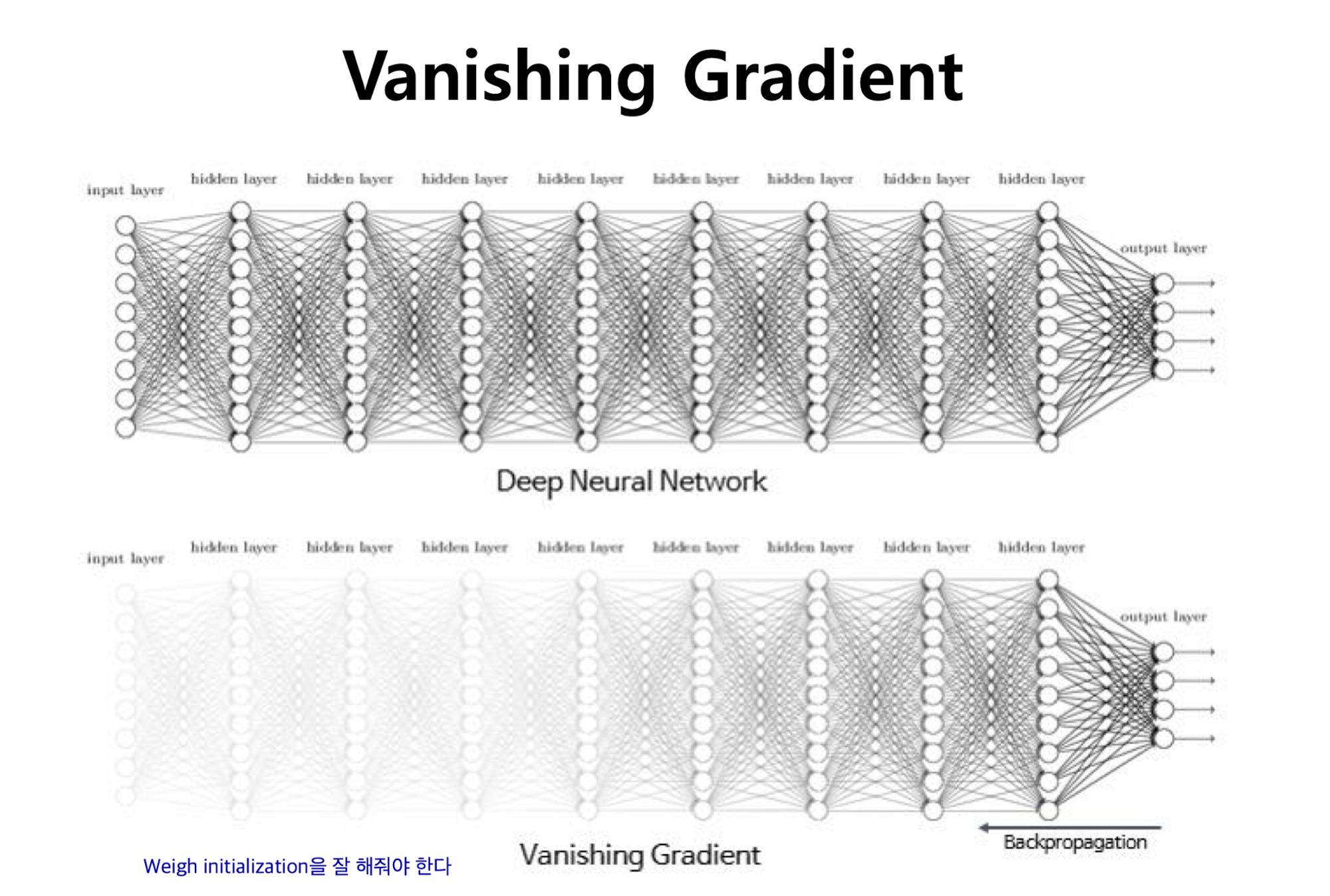
깊은 레이어로 Neural Network를 구성하게 되면 Vanishing gradient 현상이 발생한다.
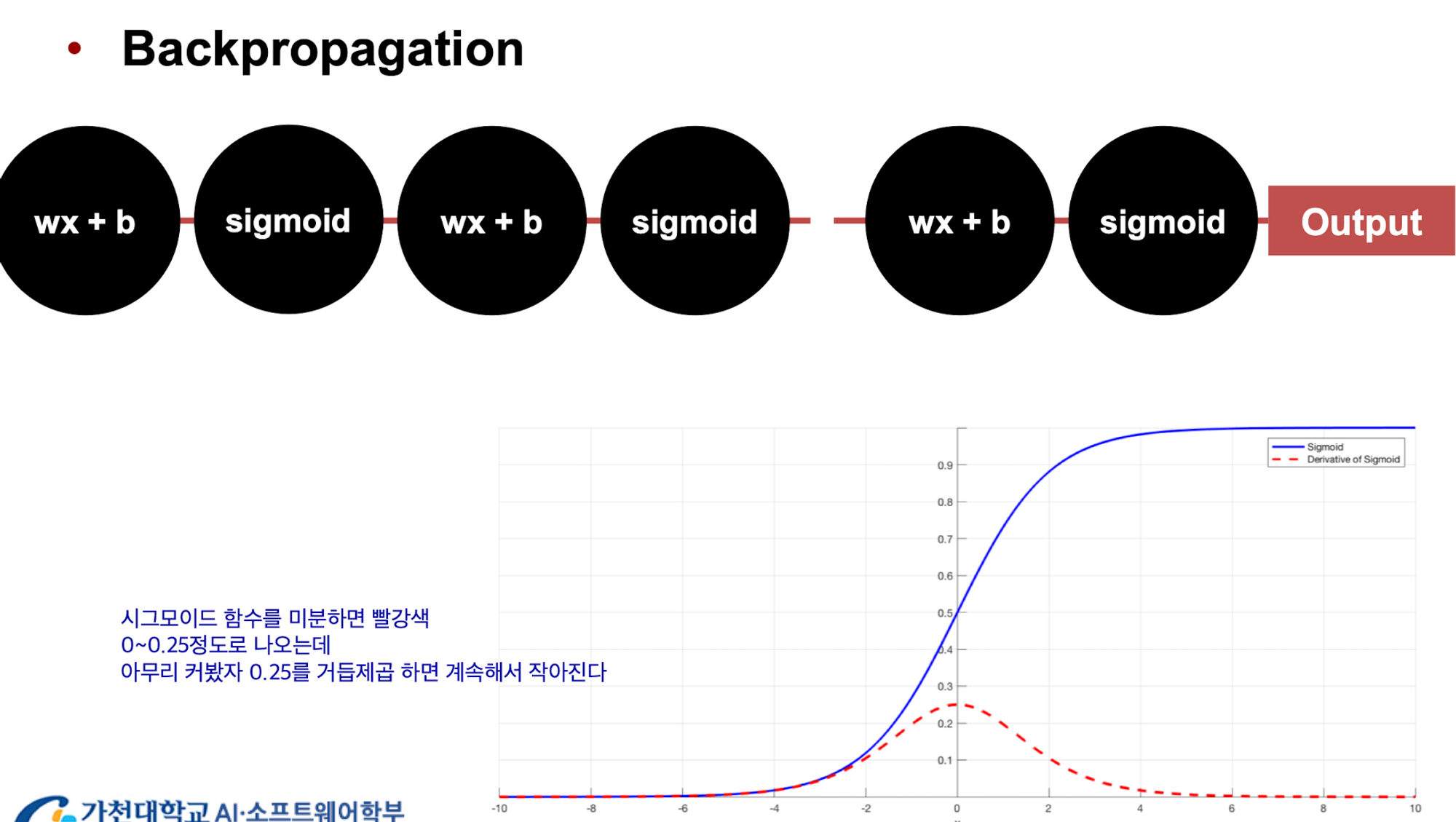
주로 Activation Function으로 사용하는 Sigmoid function을 미분하면 위 사진과 같은 붉은 함수로 그려지는데 최댓값이 0.25 언저리이다. 미분값을 통하여 weight를 업데이트하는 back propagation의 경우 레이어가 깊으면 깊을수록 결국 변화량이 매우 적어진다.
최대 변화량이라고 해도 0.25이니 이를 거듭제곱하면 점점 작아지는 것
Weight (parameter) initialization
- The initial weight setting plays a very important role in deep learning.
- Backpropagation is sensitive to inital conditions
- Effect of Initial weights
- Can get stuck in Local minima
- May converge too slowly
- Achieved generization can be poor
초기 weight값을 잘 설정해야 좋은 딥러닝 결과를 얻을 수 있다.
초기값을 설정하는 방법으로 세가지를 공부했다
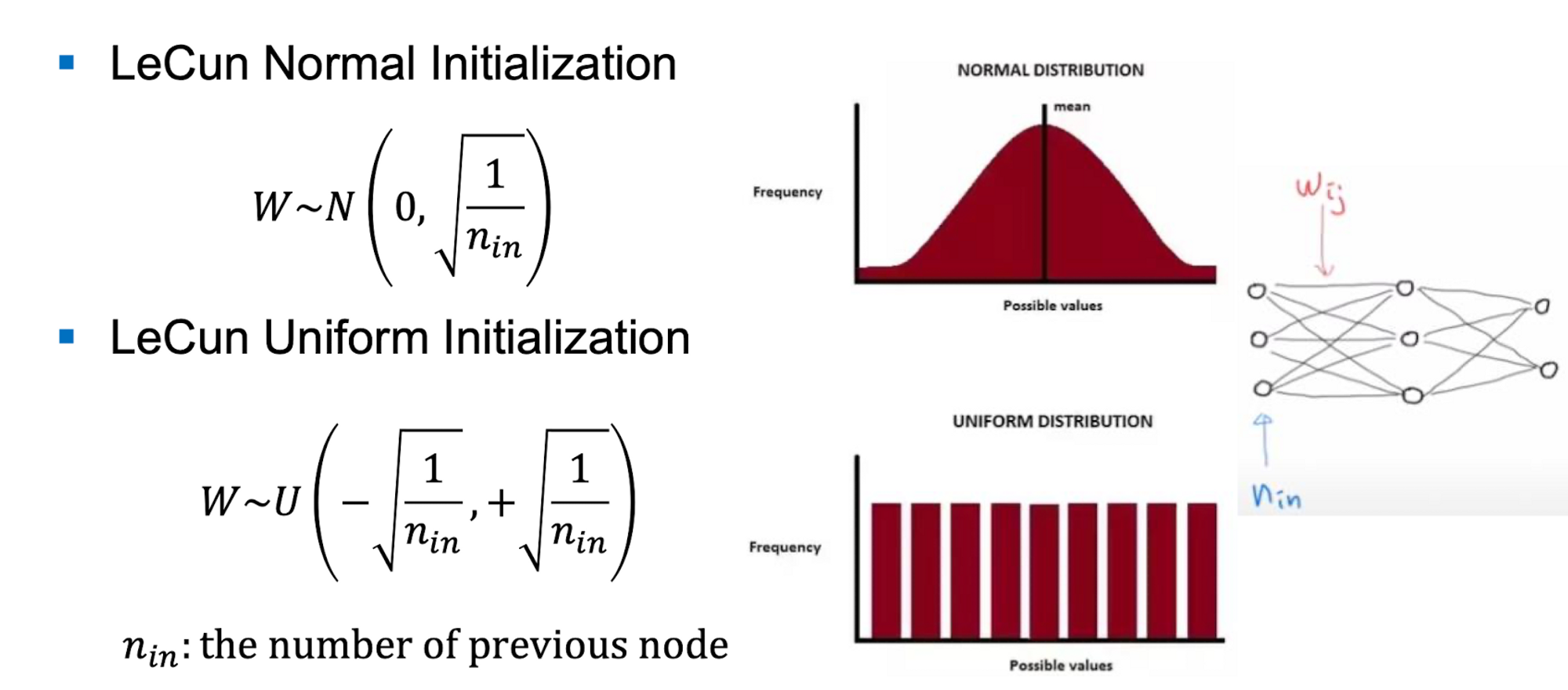
1. LeCun Initialization
LeNet을 만든 사람의 initialization 방법
input 노드들의 개수를 생각해서 initialization 한 것 이다. Input 값이 많을수록 초기값을 작게 하고 input이 적으면 초기값을 크게 할당한다.
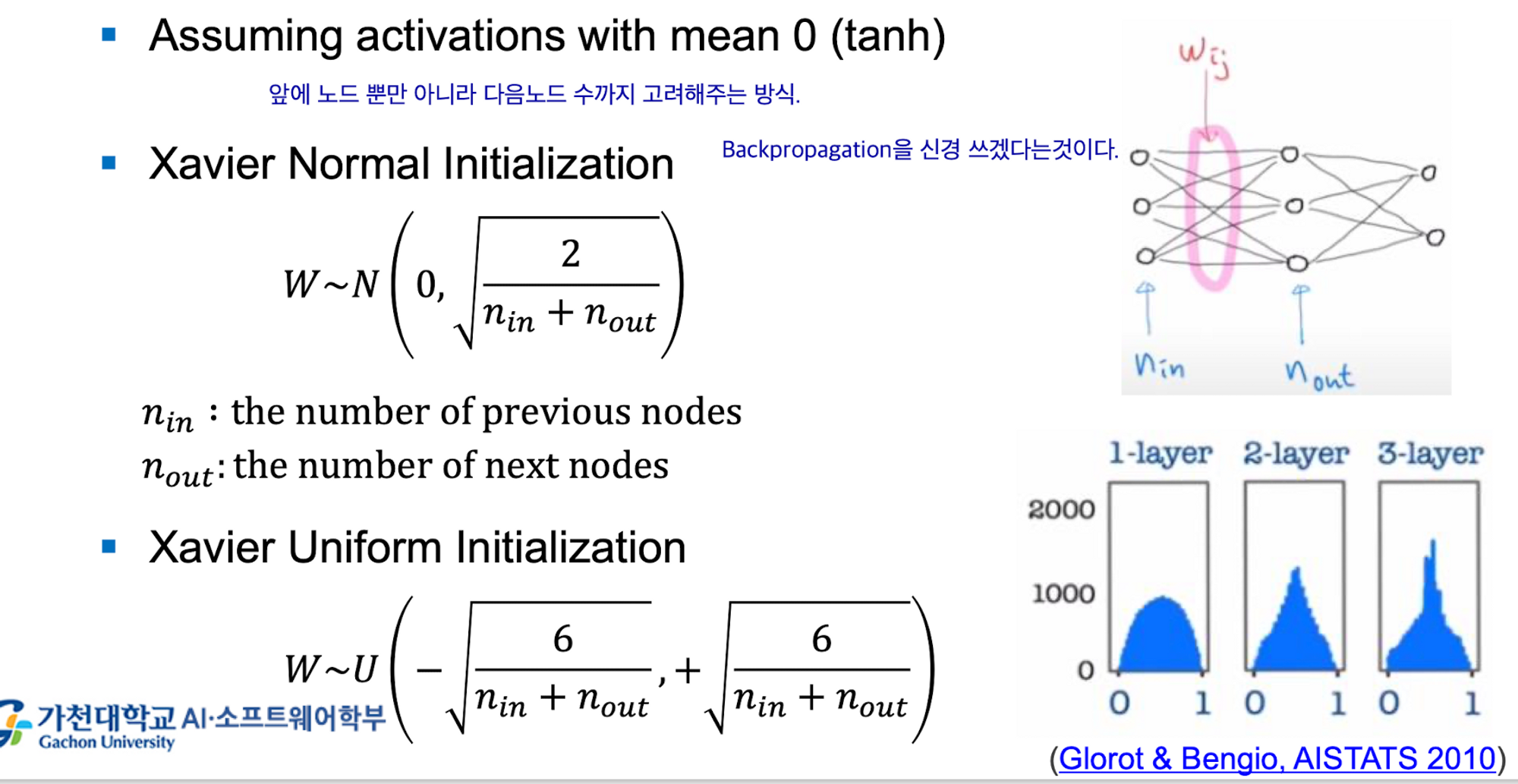
2. Xavier Initialization
맨 앞 input 노드 뿐 아니라 다음 노드들까지 고려하는 방식이다.
3. He Initialization
ReLU를 쓸때 위 방식이 잘 들지 않아 생긴 방법이다.
ReLU함수는 음수일때 전부 0이므로 0이 많이 나온다

Summary
Sigmoid, Tanh → Xavier Initialization
ReLU activatoin function → He Initialiation
요새는 대체로 He initializationd을 주로 쓴다
