
1. [1차] 뉴스 클러스터링
문제 설명
여러 언론사에서 쏟아지는 뉴스, 특히 속보성 뉴스를 보면 비슷비슷한 제목의 기사가 많아 정작 필요한 기사를 찾기가 어렵다. Daum 뉴스의 개발 업무를 맡게 된 신입사원 튜브는 사용자들이 편리하게 다양한 뉴스를 찾아볼 수 있도록 문제점을 개선하는 업무를 맡게 되었다.
개발의 방향을 잡기 위해 튜브는 우선 최근 화제가 되고 있는 "카카오 신입 개발자 공채" 관련 기사를 검색해보았다.
- 카카오 첫 공채..'블라인드' 방식 채용
- 카카오, 합병 후 첫 공채.. 블라인드 전형으로 개발자 채용
- 카카오, 블라인드 전형으로 신입 개발자 공채
- 카카오 공채, 신입 개발자 코딩 능력만 본다
- 카카오, 신입 공채.. "코딩 실력만 본다"
- 카카오 "코딩 능력만으로 2018 신입 개발자 뽑는다"
기사의 제목을 기준으로 "블라인드 전형"에 주목하는 기사와 "코딩 테스트"에 주목하는 기사로 나뉘는 걸 발견했다. 튜브는 이들을 각각 묶어서 보여주면 카카오 공채 관련 기사를 찾아보는 사용자에게 유용할 듯싶었다.
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는 "자카드 유사도"라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
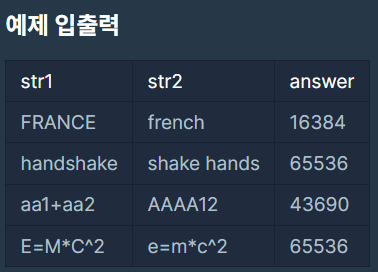
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
입력 형식
- 입력으로는 str1과 str2의 두 문자열이 들어온다. 각 문자열의 길이는 2 이상, 1,000 이하이다.
- 입력으로 들어온 문자열은 두 글자씩 끊어서 다중집합의 원소로 만든다. 이때 영문자로 된 글자 쌍만 유효하고, 기타 공백이나 숫자, 특수 문자가 들어있는 경우는 그 글자 쌍을 버린다. 예를 들어 "ab+"가 입력으로 들어오면, "ab"만 다중집합의 원소로 삼고, "b+"는 버린다.
- 다중집합 원소 사이를 비교할 때, 대문자와 소문자의 차이는 무시한다. "AB"와 "Ab", "ab"는 같은 원소로 취급한다.
출력 형식
- 입력으로 들어온 두 문자열의 자카드 유사도를 출력한다. 유사도 값은 0에서 1 사이의 실수이므로, 이를 다루기 쉽도록 65536을 곱한 후에 소수점 아래를 버리고 정수부만 출력한다.
예제
코드
//내 풀이 법
function solution(str1, str2) {
const setA = strToObj(str1);
const setB = strToObj(str2);
const intersection = new Map();
const union = new Map();
// A와 B의 교집합과 동시에 합집합을 넣어준다.
for (let [key, value] of setA){
if(setB.has(key)){
intersection.set(key, Math.min(value,setB.get(key)))
union.set(key, Math.max(value,setB.get(key)))
} else {
union.set(key, Math.max(value,setA.get(key)))
}
}
for (let [key, value] of setB){
if(!union.has(key)){
union.set(key, value)
}
}
const num = [...intersection.values()].reduce((a,b) => a+b,0);
const denom = [...union.values()].reduce((a,b) => a+b,0);
if(num === 0 && denom === 0){
return 65536
} else if (num === 0) {
return 0
} else {
return Math.trunc(num/denom*65536)
}
}
// 주어진 문자열을 길이가 2인 문자열로 쪼개면서 Map내에 빈도 수 저장하기
function strToObj(str) {
const strSet = new Map();
const regex = /^[a-zA-Z]+$/;
for(let i = 0 ; i < str.length - 1 ; i++){
const splitWord = str.substring(i,i+2).toLowerCase()
//쪼개진 문자내에 알파벳만 들어가 있는지 확인 후 Map에 추가
if(regex.test(splitWord)){
strSet.get(splitWord) ? strSet.set(splitWord,strSet.get(splitWord)+1) : strSet.set(splitWord,1)
}
}
return strSet
}🗒️코멘트
문제의 길이에 비해 생각보다 쉬웠던 문제이지만 과연 Map 자료구조를 사용해서 푸는 것이 맞나 싶은 문제였다.
Map으로 접근한 이유는 이번 문제는 중복 스트링을 허용했기 때문에 중복 스트링이 몇 번 등장했는지 알고 그 숫자를 통해서 교집합과 합집합을 쉽게 구할 수 있지 않을까 싶어서였다...다시 생각해보니 단순하게 요소들을 하나의 배열 안에 다 넣어버리고 그것의 length를 찾는 것으로 효율적이게 접근할 수 있지 않나 싶어서 다른 사람의 풀이를 보았고 역시나 Set을 사용한 풀이가 다음과 같이 있었지만...
function solution (str1, str2) {
function explode(text) {
const result = [];
for (let i = 0; i < text.length - 1; i++) {
const node = text.substr(i, 2);
if (node.match(/[A-Za-z]{2}/)) {
result.push(node.toLowerCase());
}
}
return result;
}
const arr1 = explode(str1);
const arr2 = explode(str2);
const set = new Set([...arr1, ...arr2]);
let union = 0;
let intersection = 0;
set.forEach(item => {
const has1 = arr1.filter(x => x === item).length;
const has2 = arr2.filter(x => x === item).length;
union += Math.max(has1, has2);
intersection += Math.min(has1, has2);
})
return union === 0 ? 65536 : Math.floor(intersection / union * 65536);
}직접적으로 비교해보기 앞서 두 코드를 chatGPT에게 리뷰를 부탁했고 다음과 같은 피드백을 얻어 건들지 않았다 (뿌듯)

2. 프린터
문제 설명
일반적인 프린터는 인쇄 요청이 들어온 순서대로 인쇄합니다. 그렇기 때문에 중요한 문서가 나중에 인쇄될 수 있습니다. 이런 문제를 보완하기 위해 중요도가 높은 문서를 먼저 인쇄하는 프린터를 개발했습니다. 이 새롭게 개발한 프린터는 아래와 같은 방식으로 인쇄 작업을 수행합니다.
- 인쇄 대기목록의 가장 앞에 있는 문서(J)를 대기목록에서 꺼냅니다.
- 나머지 인쇄 대기목록에서 J보다 중요도가 높은 문서가 한 개라도 존재하면 J를 대기목록의 가장 마지막에 넣습니다.
- 그렇지 않으면 J를 인쇄합니다.
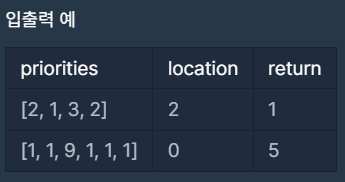
예를 들어, 4개의 문서(A, B, C, D)가 순서대로 인쇄 대기목록에 있고 중요도가 2 1 3 2 라면 C D A B 순으로 인쇄하게 됩니다.
내가 인쇄를 요청한 문서가 몇 번째로 인쇄되는지 알고 싶습니다. 위의 예에서 C는 1번째로, A는 3번째로 인쇄됩니다.
현재 대기목록에 있는 문서의 중요도가 순서대로 담긴 배열 priorities와 내가 인쇄를 요청한 문서가 현재 대기목록의 어떤 위치에 있는지를 알려주는 location이 매개변수로 주어질 때, 내가 인쇄를 요청한 문서가 몇 번째로 인쇄되는지 return 하도록 solution 함수를 작성해주세요.
제한사항
- 현재 대기목록에는 1개 이상 100개 이하의 문서가 있습니다.
- 인쇄 작업의 중요도는 1~9로 표현하며 숫자가 클수록 중요하다는 뜻입니다.
- location은 0 이상 (현재 대기목록에 있는 작업 수 - 1) 이하의 값을 가지며 대기목록의 가장 앞에 있으면 0, 두 번째에 있으면 1로 표현합니다.
예제
코드
function solution(priorities, location) {
let answer = 0;
let pos_map = []
let max_value = Math.max(...priorities);
for(let i = 0; i < priorities.length; i++){
pos_map.push(i);
}
while(priorities.length != 0){
if(priorities[0] < max_value){
priorities.push(priorities.shift());
pos_map.push(pos_map.shift());
}else {
answer+=1;
priorities.shift();
if(pos_map.shift() == location)
return answer;
max_value = Math.max(...priorities);
}
}
}🗒️코멘트
NULL
