데이터 관계가 넘넘 헷갈려서 따로 정리했다. one to one, one to many, many to many가 이해가 갈 듯하면서 안 간다. 공식처럼 정리하고 외워야겠따 . . .
실제 데이터를 모델링하면서 개념 외 실용적인 부분에 대해서도 여기에 추가로 정리해야지 😤
1. foreign key
테이블을 연결할 수 있는 수단이다. 그런데 참조하는 것의 개념이 너무 어려워서... 우선 위키피디아에서 외래 키에 대한 정의를 가져왔다.
관계형 데이터베이스에서 외래 키(외부 키, Foreign Key)는 한 테이블의 필드(attribute) 중 다른 테이블의 행(row)을 식별할 수 있는 키를 말한다.
외래 키는 참조하는 테이블에서 1개의 키(속성 또는 속성의 집합)에 해당하고,
참조하는 측의 관계 변수는 참조되는 측의 테이블의 키를 가리킨다.참조하는 테이블의 속성의 행 1개의 값은, 참조되는 측 테이블의 행 값에 대응된다. 이 때문에 참조하는 테이블의 행에는, 참조되는 테이블에 나타나지 않는 값을 포함할 수 없다.이러한 참조 관계는 2개의 테이블을 연관시키기 위한 관계
정규화의 본질적인 부분이다. 참조하는 테이블의 행 여러 개가, 참조되는 테이블의 동일한 행을 참조할 수 있다.
🌈참조 하는 & 참조 되는
보통 테이블을 만들면 첫 번째는 primary key이자 auto increment되는 id를 넣게 된다. 요 id를 가진 테이블이 참조 되는 것이고, foreign key를 가진 테이블이 참조하는 입장이다. fk name은 보통 참조되는 table의 이름에 언더스코어를 붙인다.
관계의 종류
- one to one
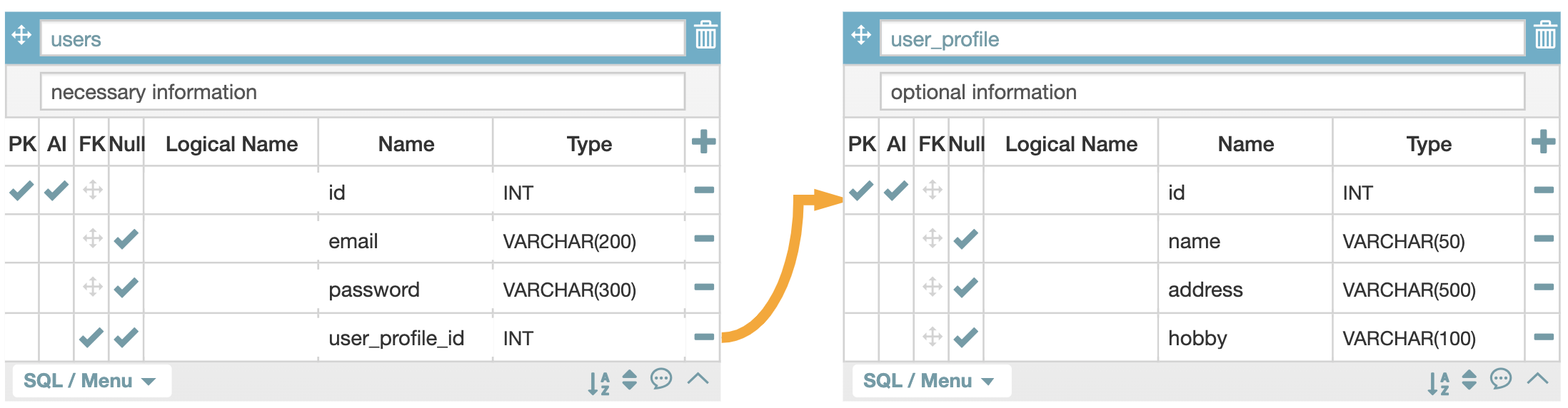
테이블 A의 로우와 테이블 B의 로우가 정확히 1:1로 매칭되는 것. 예를들어 로그인 데이터를 가진 테이블과 유저의 프로파일을 가진 테이블이 있을 때, 한 유저는 하나의 프로파일 데이터와만 매칭된다.
- one to many
하나의 주체가 여러개의 상태값을 가질 수 있는 형태를 말한다. 예를 들어 아이디 하나에 여러가지 주문이 있거나, 한 카테고리에 여러 제품이 들어있는 것이다. one to one과 다르게, 여러 개의 orders table이 하나의 user를 바라보게 된다.

- many to many
두 개의 entity를 참조하는 집합. 말이 뭔가 어려운데 테이블 두 개의 관계를 참조하는 또 하나의 테이블이 있는 상황이다.
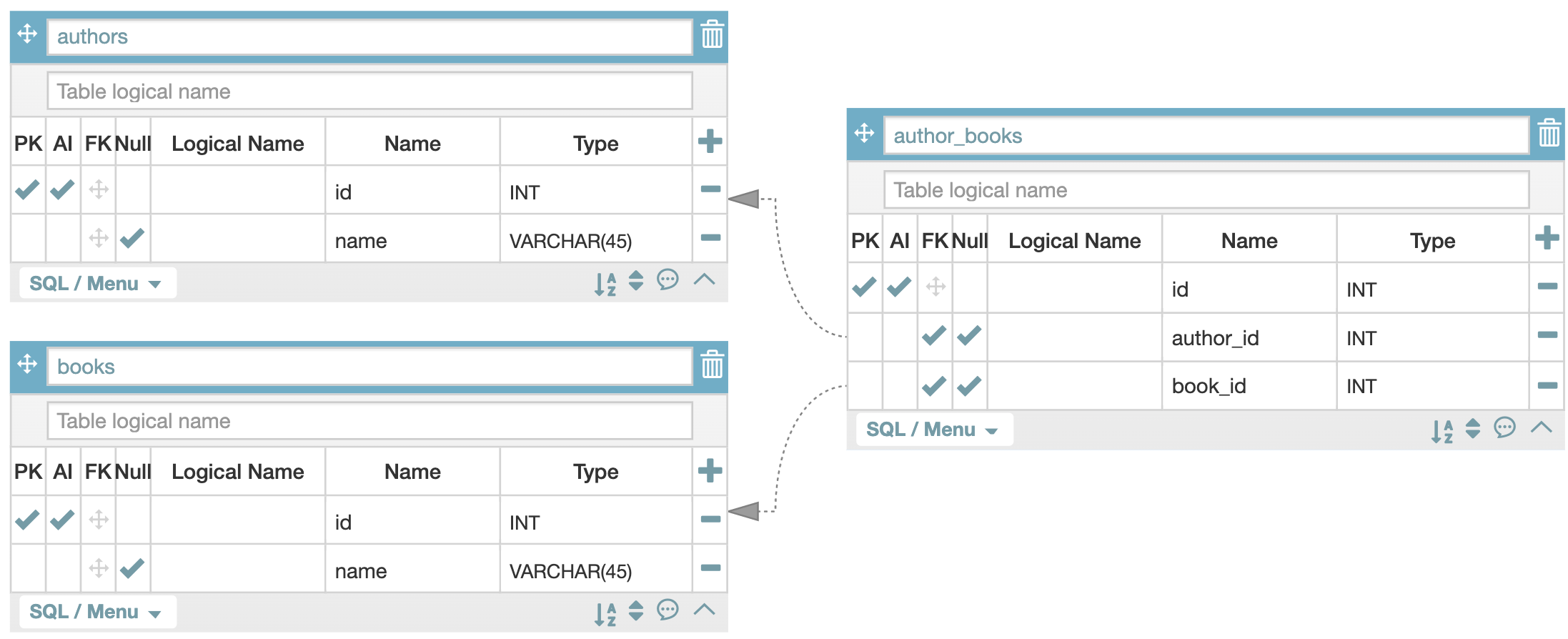
이해가 안 돼서 위키피디아로 추가 설명을 봤다. 예를 들어 저자와 책의 관계에 대한 데이터베이스가 있다고 생각해보자. 한 명의 저자는 여러 책을 쓸 수 있고, 한 권의 책 또한 여러 명의 저자가 있을 수 있다.
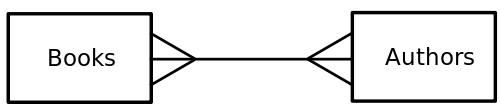
이런 관계는 associative table(=joint table, junction table)을 통해 완성될 수 있다. 저자-책의 many-to-many 관계는 one-to-many 관계가 연결된 짝 테이블이라고 보면 된다. 수강 신청을 예로들 수도 있다.
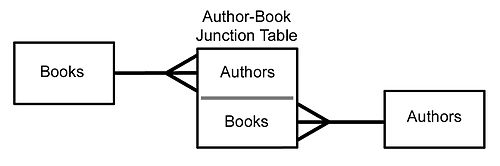
In systems analysis, a many-to-many relationship is a type of cardinality that refers to the relationship between two entities A and B in which A may contain a parent instance for which there are many children in B and vice versa.
⭐️ tips
데이터의 양이 많아지게 된다면 many to many가 좋지만, 사이즈(tall/ grande/ venti) 정도라면 one to many도 괜찮다.
2. 이해가 어렵다면
관계를 이해하는 것이 어렵다면, 표를 직접 그려보는 것을 추천한다. 뒤에 나오는 Aquery tool은 편하다는 장점이 있지만, 뭔가 사람이 생각할 때 떠오르는 표의 구조가 아니라서 개념을 이해하는 것이 힘들다.
그리고 사실 데이터를 넣는다거나 fk설정이 양방향으로 가능한 조건도 있기 때문에, 직접 그려보고 어떤 조건이 데이터를 효율적으로 사용하는 상황인지를 그려볼 필요가 있다.
fk와 화살표
화살표 방향 요게 굉장히 헷갈린다. 일단 기억하기 쉽게 설명하자면 화살표는 fk에서 나온다고 보면 된다. 참조되는 테이블은 화살표를 받는다. 예를 들어 products tblae이 nutritions table을 참조한다면, 화살표를
참조 된다(id) <---- 참조 한다(nutritions_id)
로 보면 쉽다. 괄호 안의 내용은 column값이다.
자세한 예시
one to one, one to many는 아래 처럼 생각하면 조금 더 쉽다. 먼저 one to many부터 파악해보자. 제품 테이블이 있고 상세 설명 테이블이 있다고 하자. 어떤 제품은 상세 설명이 2개고, 어떤 제품은 1개고, 어떤 제품은 없다.
이 상황에서 제품 테이블이 제품 설명 테이블을 참조하면 나는 불필요한 열을 만들게 된다. 데이터 모델링을 할 때 설명을 200자 정도로 설정한다면, 그 데이터가 비었을 때 200자만큼의 공간을 낭비하게 되는 것이다. (이해를 돕기 위해 O, X로 표시했지만 실제로 빨간 테이블의 O에는 설명 데이터가 들어갈 것이고, X는 null값이 된다)

 하지만 제품 설명 테이블이 제품을 참조하게 된다면, 나는 제품 id값에 따른 설명을 입력하면 된다. 하나의 주체가 여러 상태값을 가진다는 것이 바로 초록 테이블의 상태다. 제품이 설명 여러개를 가지고, 없는 테이블은 생략될 수 있는 것이다. 그려보니까 완전 쉽다 🥺❤️
하지만 제품 설명 테이블이 제품을 참조하게 된다면, 나는 제품 id값에 따른 설명을 입력하면 된다. 하나의 주체가 여러 상태값을 가진다는 것이 바로 초록 테이블의 상태다. 제품이 설명 여러개를 가지고, 없는 테이블은 생략될 수 있는 것이다. 그려보니까 완전 쉽다 🥺❤️


위 내용을 이해하면 one to one이 더 쉽게 다가온다. one to one은 데이터를 참조할 때 하나의 형식이고 모든 정보를 포함하고 있다면 쓸 수 있다. 예를 들어 제품 별로 영양 정보 테이블 요소는 모두 똑같다.
그러니까 하나의 제품이 '똑같이' 하나의 영양 정보를 갖고 있을 때. 이 때는 제품에서 fk를 사용하게 된다. 데이터 낭비 없이 1:1로 매칭이 된다.