c언어에서 어느 변수에 선언된 배열에 값을 추가할때 어떻게 해야할까?
배열의 크기를 우선 늘려야하는데, 그렇게 되면 다른 메모리 영역을 침범할 수 있다.
그래서 배열에 추가할 값의 길이 만큼 메모리 어딘가에 새로운 배열의 공간을 할당한 뒤,
기존 배열내용을 복사, 값을 추가하고 기존 배열 메모리를 free로 해제해준다. 그 다음 기존 변수를 새로운 배열에 선언한다.
포인터의 특성을 이용하면 이보다 간단하게 값을 바꿀 수 있는 자료구조를 만들 수 있다.
연결리스트(linked list)
배열은 각 인덱스의 값이 메모리상에 연이어서 저장 되어있다. 그러나 포인터의 특성을 이용하면 메모리상에 값이 산재 되어있어도 값을 연이어 읽어올 수 있다.
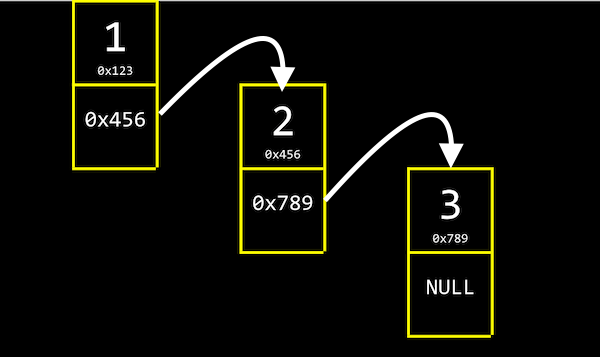
- 값 다음에 next(포인터 주소 default:null)가 오게하는 node 구조체를 만든다.
- 값을 읽고난뒤 next가 가리키는 곳으로 이동해 다음 순서의 값을 읽을 수 있게한다.
- 새로운 값을 추가하고 이전 next를 추가된 값 주소로 만들면 값을 연이어서 읽어 올 수 있다.
위 사진에서 2와 3사이에 2.5를 추가 하고싶다면 어떻게 해야할까?
- 우선 2.5 노드를 만들고,
- 2.5의 next를 2가 가리키던 주소(3주소)로 둔다.
- 그 다음 2의 next는 2.5의 주소를 가리키게하면 값을 연이어서 읽어 올 수 있다.
그러나 2.5 노드를 생성 할 때 2의 next를 2.5로 먼저 만들면 2.5의 next는 null인채로 남아, 나머지 연결리스트에 접근할 수 없게되고 메모리 누수가 발생한다.
연결리스트의 장점은 값을 추가할때 메모리를 다시 할당하지 않아도 된다.
그러나 연결리스트는 다음 포인터 주소 next를 명시해줄 메모리 공간이 더 필요하다.
또한 연결리스트는 임의 접근이 불가능하다.
배열은 n번째 인덱스의 값을 바로 접근할 수 있지만,
연결리스트는 첫번째 값부터 n번째까지 순서대로 타고 올라가야 비로소 접근 할수있다.
따라서 연결리스트는 O(n)의 탐색시간이 소요된다.
트리(binary search trees)
배열과 연결리스트의 장점만 가져올순 없을까?


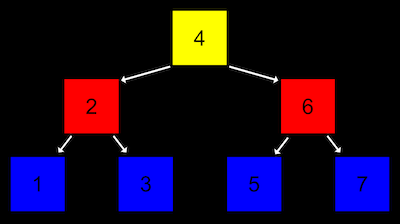
트리가 시작되는 노드를 ‘루트’라고 한다.
루트 노드는 다음 층의 노드들을 가리키고 있고, 이를 ‘자식 노드’라고 한다.
트리는 왼쪽값은 작고 오른쪽값은 큰 형태가 반복된다. 따라서 재귀적으로 구현할 수 있다.
트리 구조에서의 탐색시간은 O(log n)이다. 연결리스트의 탐색시간인 O(n)보다 줄었다.
트리 구조에서의 요소 추가시간은 O(log n)이다. 다만 이는 트리 균형 알고리즘이 적용된 경우이다. 요소가 한쪽 노드에만 계속 추가되는 불균형적인 경우엔 달라질 수 있다.
해시 테이블(hash table)
연결리스트와 트리의 탐색시간은 O(n), O(log n)이다. 이를 더 단축시킬 방법은 없을까?
해시 테이블은 ‘연결 리스트의 배열’이다.
효율적인 해쉬 함수를 만들어서 해시 테이블을 조직해야한다.
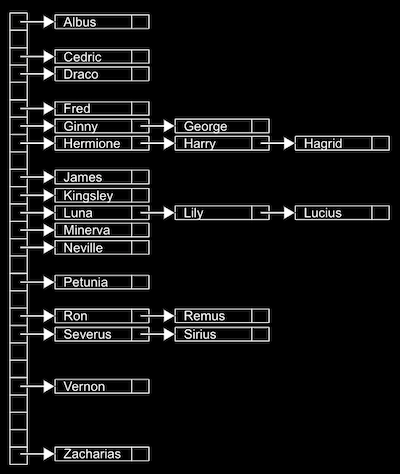
사진은 이름의 첫문자로 이름들을 나누는 해쉬 함수가 적용된 해쉬 테이블이다.
- 가장 왼쪽은 range(0,25)의 알파벳 26개를 나눌 수 있는 배열이다 (편의상 세로로 표시).
- 화살표는 연결리스트의 포인터를 말한다.
배열은 임의접근이 가능하니 알파벳 순서에 맞게 요소를 한번에 추가할 수 있다 O(1).
요소가 추가될때 H열처럼 중복 되어있다면 배열은 이를 처리하기 어려울 것이다. 그러나 연결 리스트가 적용 되어있기 때문에 동적으로 값을 처리할 수 있다.
문제는 한 곳에만 요소들이 계속 추가되는 최악의 상황에선 연결리스트는 첫번째 요소부터 n번째 요소까지 탐색을 해야한다 O(n).
이를 완화하려면 해시함수에서 이름의 첫문자로 나누는 것이 아닌 두번째(26*26배열), 세번째 문자(26*26*26배열)까지 판단해서 중복될 수 있는 요소를 가진 이름들을 나누게 처리하는 방법 등이 있다.
부작용은 배열이 지나치게 길어져서 차라리 연결리스트로 n번 탐색하는게 나아질 수 도 있다.
일반적으로는 최대한 많은 바구니를 만들어 각 바구니에 단 하나의 값들만 담는 해시 함수를 사용하기 때문에 거의 O(1)에 가깝다고 볼 수 있다.
트라이(trie)
어원 : retrieval (검색)
문자열의 길이가 일정한 경우 이 문자열들을 저장하고 관리하는데 최적의 자료 구조는 무엇일까?
트라이는 트리형태의 자료구조이다.
트리의 각 노드를 배열로 구성했다.
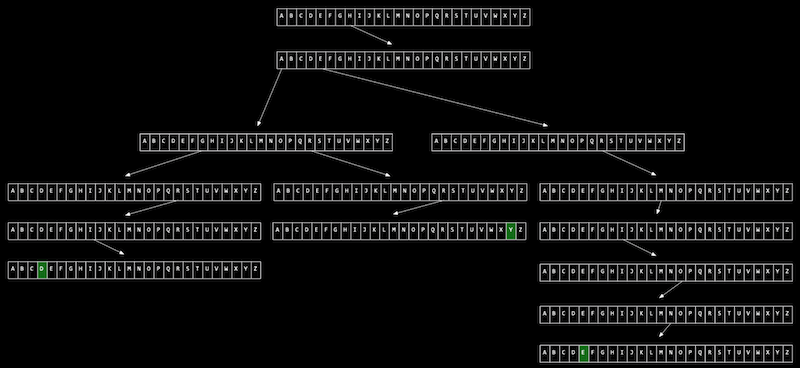
사진은 알파벳 26개를 배열에 속하게 했다.
다른 자료구조들은 요소의 개수에 따라 실행시간이 길어진다.
그러나 트라이 구조는 자기가 찾을 문자만 검색하면 되기에 일정한 실행시간이 소요된다.
‘Harry’를 찾으려면 다른 요소들의 이름을 볼 필요도 없이 각 노드의 배열에서 H,a,r,r,y만 찾으면 된다.
따라서 문자열의 길이가 일정하면 탐색, 추가하는 시간이 상수로 정해져있다 O(1).
그러나 트라이 구조는 O(1)이라는 빠른 시간을 제공하기 위해 메모리를 많이 사용한다.
큐(queue)
큐는 메모리 구조에서 살펴봤듯이 값이 아래로 쌓이는 구조이다.
값을 넣고 뺄 때 가장 먼저 들어온 값이 가장 먼저 나가는
‘선입 선출(FIFO)’ 방식을 따른다.
배열이나 연결 리스트를 통해 구현 가능하다.
- enqueue 줄에 서는것
- dequeue 줄에서 나오는것
스택(stack)
메모리 구조에서 처럼 값이 위로 쌓이는 구조이다.
가장 나중에 들어온 값이 가장 먼저 나가는 ‘후입 선출(LIFO)’라는 방식을 따른다.
역시 배열이나 연결 리스트를 통해 구현 가능하다.
- push 스택에 요소를 밀어넣는다
- pop 가장 위의 요소를 뺀다
메모리 영역에서의 스택(call stack)에서 주로 스택 자료구조가 쓰이는 것은 맞으나, 다른 개념이다.
딕셔너리
딕셔너리는 ‘키’와 ‘값’이라는 요소로 이루어져 있다.
‘키’에 해당하는 ‘값’을 저장하고 읽어오는 것이다.
예시로 대학교에서 ‘학번’에 따라서 ‘학생’이 결정되는 것과 동일하다.
일반적인 의미에서 ‘해시 테이블’과 동일한 개념이라고도 볼 수 있습니다.
파이썬에서 dict 자료구조는 해시 테이블을 이용한다고 한다.
딕셔너리에서는 ‘키’를 어떻게 정의할 것인지가 중요하다.
