
> 개요
원티드x위코드 프리온보딩 과제 수행간
개인적으로 흥미로웠던 점들을 정리하였습니다.
이번 과제는 기업 8percent에서 내주셨습니다.
과제와 관련 전반적 내용(README) 및 코드가 담긴 깃허브 주소는 다음과 같습니다.
🥕 과제 github 링크:
https://github.com/chrisYang256/8percent-assignment
> 중복없는 계좌번호 생성
▶︎ 은행처럼 계좌번호를 발급해보자
이번 프로젝트에서 저의 담당 API는 signup과 signin이었습니다.
우리는 회원가입 시 user와 account 테이블 동시 생성 및 계좌번호 발급을
해주기로 설계하였고 저는 진짜 은행처럼 랜덤한 숫자 + 중복되지 않은
고유 번호의 계좌번호를 발급해보고 싶었습니다.
일단 너무 길게 생각하지 않고 코드로 관련된 무엇이든 만들기 시작하는게
경험상 저에게 맞기에 바로 키보드를 어루만지기 시작하였습니다.
▶︎ 처음 써보는 재귀함수
일단 결과물은 다음과 같으며 중복 없는 데이터를 만들어낼 수 있었습니다.
def account_number():
def numbers():
number = random.randint(1000, 9999)
return number
account_number = f'{numbers()}-{numbers()}-{numbers()}-{numbers()}'
if not Account.objects.filter(number=account_number).exists():
return account_number
return account_number()
# 리턴값 예시: '9197-6853-7204-1115'제작 과정은 다음과 같습니다.
구글에서 random.randint()라는 함수를 찾아 1000~9999의 숫자를 랜덤하게
만들어낼 수 있었고 이것을 4번에 걸쳐 다른 결과가 나와야 했었습니다.
4회 동안 각각 다른 랜덤한 4자리의 수를 받기 위해 number1, number2...와 같이
변수를 4개 만드는 것은 조금 웃겼기에 함수로 만들어 4번의 리턴을 받아
목적을 이룰 수 있었습니다.
그리고 중요한 것은 기존 발급된 계좌번호와 중복되지 않는 고유한 수의
계좌를 발급하는 것이었는데 뜬금 잘 알지도 못하는 재귀함수가 생각났습니다.
아마도 "자기 자신을 호출한다"는 특성이 생각나서였던 것 같습니다.
그래서 함수 안에 계좌생성 로직과 중복검사를 하는 if문을 넣은 후
DB데이터와 대조하여 생성한 계좌가 중복인 경우 다시 자기 자신을
호출하는 과정을 반복하도록 하여 마치 실재 은행처럼 중복이 없는 계좌번호를
발급할 수 있게 하였습니다!
단순한 로직이지만 참고자료 없이 상상한 내용을 정리하고 관련된 도구(랜덤함수,
재귀함수)를 떠올리고 찾고 알맞게 조립하여 구현해 냈기에 행복했습니다.🥲(감-동)
> 은행 모델링
▶︎ 모델링 및 API 관련 참고사항
✔️ 주요 고려 사항은 다음과 같습니다.
- 계좌의 잔액을 별도로 관리해야 하며, 계좌의 잔액과 거래내역의 잔액의 무결성의 보장
- DB를 설계 할때 각 칼럼의 타입과 제약
- 거래내역이 1억건을 넘어갈 때에 대한 고려
✔️ 구현하지 않아도 되는 부분은 다음과 같습니다. - 문제와 관련되지 않은 부가적인 정보. 예를 들어 사용자 테이블의 이메일, 주소, 성별 등
✔️ API 목록 - 거래내역 조회 API
- 입금 API
- 출금 API
✔️거래내역 API는 다음을 만족해야 합니다. - 계좌의 소유주만 요청 할 수 있어야 합니다.
- 거래일시에 대한 필터링이 가능해야 합니다.
- 출금, 입금만 선택해서 필터링을 할 수 있어야 합니다.
- Pagination이 필요 합니다.
- 다음 사항이 응답에 포함되어야 합니다.
- 거래일시
- 거래금액
- 잔액
- 거래종류 (출금/입금)
- 적요
입금 API - 계좌의 소유주만 요청 할 수 있어야 합니다.
출금 API - 계좌의 소유주만 요청 할 수 있어야 합니다.
- 계좌의 잔액내에서만 출금 할 수 있어야 합니다.
잔액을 넘어선 출금 요청에 대해서는 적절한 에러처리가 되어야 합니다.
▶︎ 모델링 초안
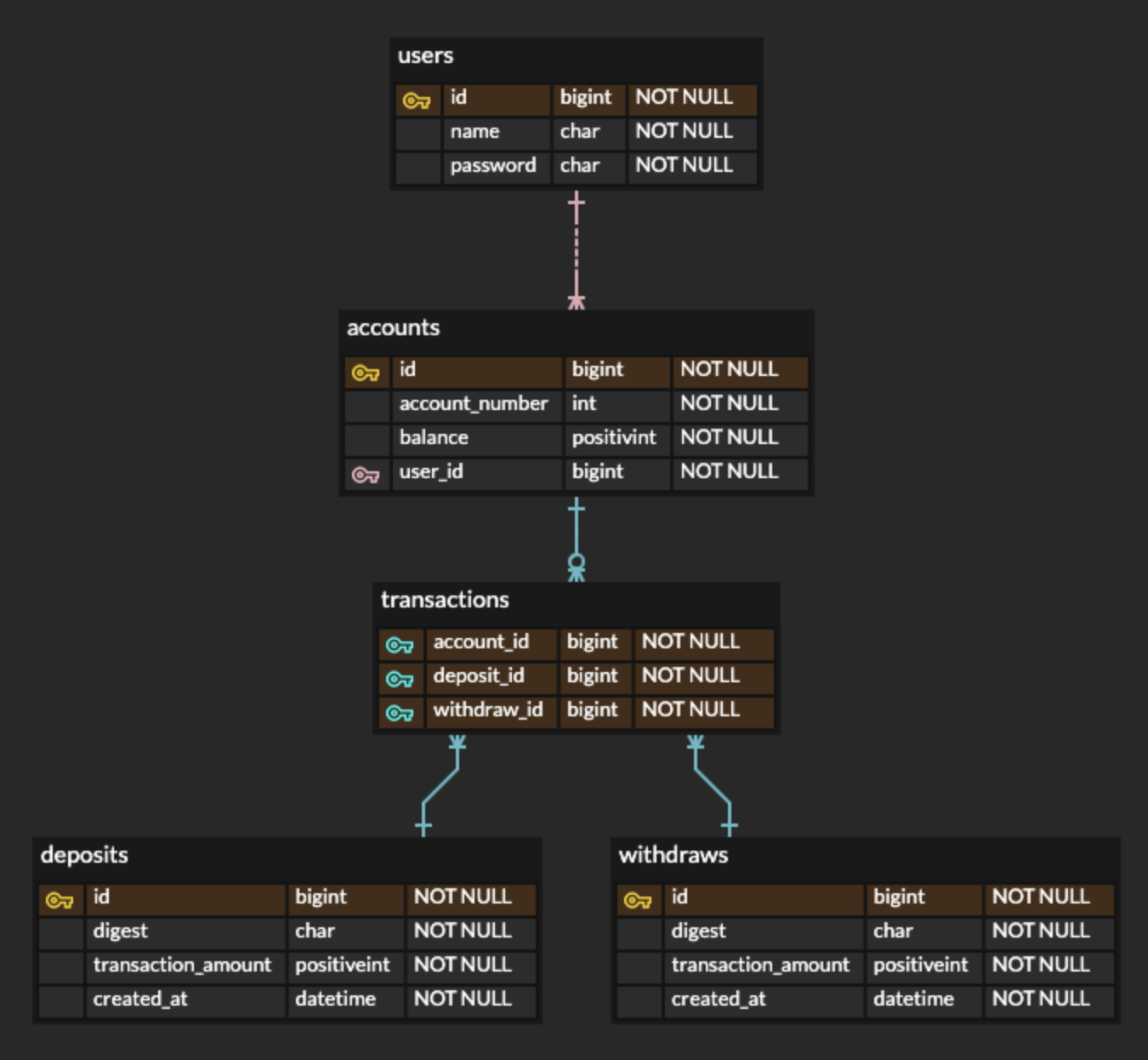
계좌(accounts)는 여러개일 수 있기 때문에 테이블을 나누었습니다.
거래(transactions)는 저장되는 데이터의 구분 및 조회 성능을 고려하여
입금과 출금 테이블을 나누었습니다.
이 테이블의 약점
일반적으로 입출금을 동시에 조회하는 경우가 많고 pagination을 하기 때문에
조회성능은 크게 중요한 사항은 아니라고 판단됐습니다.
기간을 몇 년 단위로 조회하는 경우에도 입출금을 동시에 조회하는 경우
table join을 해야하기 때문에 입출금을 따로 조회하지 않은 이상 메리트가 없습니다.
또한 쓸데 없는 테이블 및 중복 column으로 인한 데이터 낭비가 있습니다.
가장 큰 패착으로는 transaction 테이블에 잔액(balance)이 없다는 점입니다.
accounts 테이블에 있는 잔액은 최종/현재의 잔액이고 거래 내용을 알 수 없고
거래내역을 조회하기 위해서는 transaction 테이블에 거래 후 잔액이 있어야 했습니다.
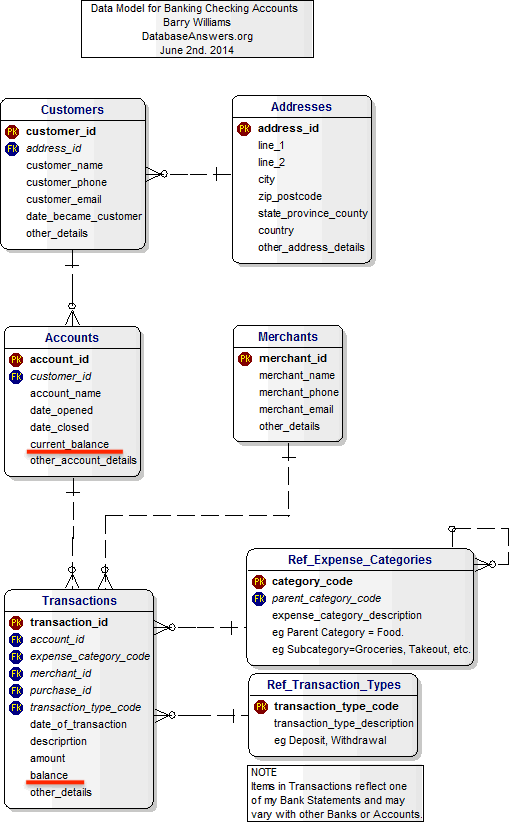
위 ERD처럼 현재 잔액과 거래당시 잔액 데이터를 따로 저장시켜야 합니다.
또한 앞서 말한대로 입출금 테이블은 특별한 정책이 있는 것이 아니면
따로 분리시키지 않는 것이 좋아보입니다.
그 외 거래형태를 구분하기 위한 transaction type 테이블을 별도로 두었습니다.
▶︎ 모델링 최종안

사실 코드를 구동해보기 전 까지 저를 포함하여 함께한 팀원들은
transaction 테이블의 balance 컬럼의 의미를 제대로 이해하지 못했습니다.
그저 잔액의 정확성을 위해 accounts의 balance와 비교하기위해
존재하는줄로만 생각하고 있었습니다.
하지만 거래내역을 조회하려다보니 거래 당시의 잔액에 대한 데이터가
없다는 것을 알고는 아차 하면서도 즐거웠던 기억이 납니다.
> DataBase 누적 Data에 대한 고찰
▶︎ 거래내역이 1억건을 넘어갈 때에 대한 고려
처음 "거래내역이 1억건을 넘어갈 때"라는 조건을 보았을 때
재미있게도 팀원 모두 조회 성능향상만을 생각했습니다.
그 결과중 하나가 아래와 같이 DataBase Indexing이었습니다.
class Transaction(models.Model):
amount = models.PositiveIntegerField()
balance_after_transaction = models.PositiveIntegerField()
sum_up = models.CharField(max_length=100)
account = models.ForeignKey(Account, on_delete=models.CASCADE)
transaction_type = models.ForeignKey(TransactionType, on_delete=models.CASCADE)
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = 'transactions'
indexes = [models.Index(fields=['account_id'])]그러나 pagination을 사용하므로 데이터 로딩에 큰 차이가 없기도 했고
개인이 1억건의 거래내역을 조회할까? 라는 현실성 없는 상황을 배제하니
이것도 아닌거라는 결론이 팀원들 사이에 나오기 시작했습니다.
그러던 중 어느 팀원분이 database table partitioning이라는 개념을
찾으셨고 날짜 등을 기준으로 테이블을 나눌 수 있는 기능을 확인했습니다.
하지만 sqlite에는 해당기능 없음 + 프로젝트 마감 직전이었기에
우선 기존 코드를 잘 마무리하고 다음 프로젝트 때 시도하는 것으로
팀원 전부 동의하며 프로젝트를 마쳤습니다.
🌈 작은 회고 🤔
이번 과제를 하면서 테이블을 한 번에 만드는 것이 어렵다는 사실을
다시 한 번 마주쳤습니다.
물론 참고할 좋은 모델이 있다면 바로 모방할 수 있겠지만
아마도 나 자신의 창의력을 일부 막을 수 있다는 생각에
우선은 혼자만의 판단들로 테이블을 만들어보고는 합니다.
이번에는 참고한 모델을 보고도 API를 만들기 전 까지
참고하는 테이블의 의도를 완전히 알지 못했다는 점이 새롭기도 했는데
좌절같은 부정적인 감정이 아닌 "오호라?" 하는 흥미를 느끼는 스스로를 보며
약간은 더 긍적적으로 변하는 본인의 내면이 기분 좋기도 했습니다.
이런 긍정적 변화들이 앞으로도 자주 생겨서 저의 코딩생활과 인생 전반에
더 많은 행복을 가져다 주기를 바라게 되는 날입니다.😃
