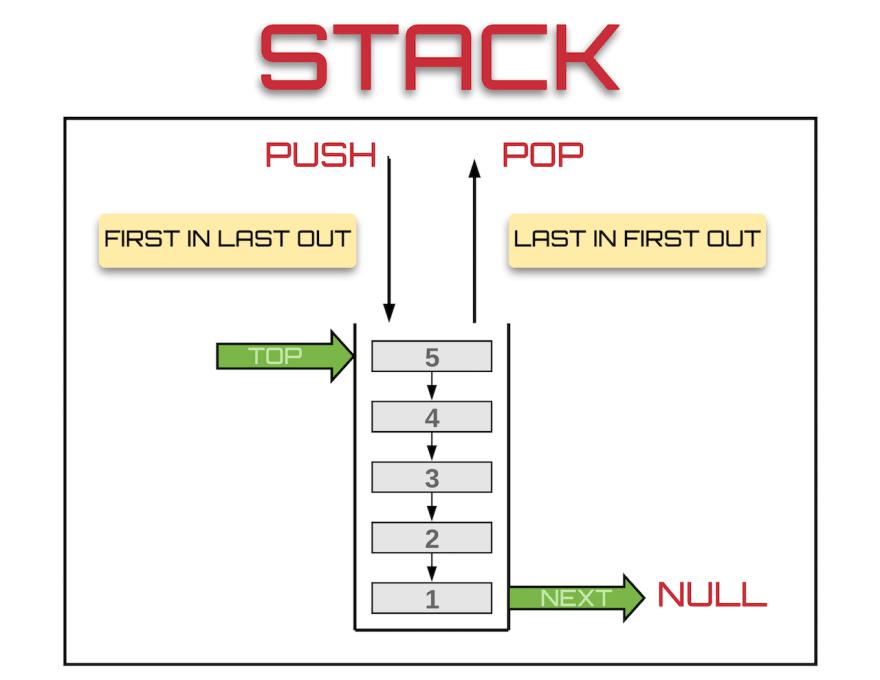
스택(Stack)?
스택='쌓아 올리다', 즉 데이터를 하나씩 위로 쌓아 올리는 방식을 뜻한다.
삽입되는 값은 위로 쌓이고 반환되는 값은 최근에 들어왔던 값이 빠지는 구조이다.
즉,LIFO(후입선출)구조이다. 그렇다면 이런 스택은 왜 쓸까??
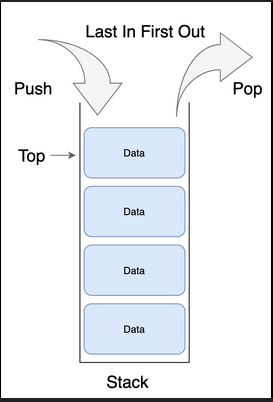
스택 사용처
- C/C++의 main() 함수안에서 사용되는 지역변수와 함수들은 모두 스택의 자료구조에 의하여 관리된다.
- 스택을 활용하면 "재귀함수"를 필요로하는 소스코드에 "재귀함수"를 사용하지 않고 구현할 수 있습니다.
- 웹 브라우저의 방문기록에서도 스택의 특징을 활용하여 "뒤로가기"를 구현할 수 있습니다.
- 프로그램의 실행취소((Undo)에서 활용됩니다.
- 후위표기 계산식에서 활용됩니다.
스택 구현(c언어)
<배열을 이용한 스택>
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
int stack[MAX_SIZE];
int top=-1;
void init_stack()
{
top=-1;
}//top을 -1로 초기화
int is_full()
{
return top==MAX_SIZE-1;
}// top이 MAX_SIZE-1이면 참을 반환
int is_empty()
{
return top==-1;
}// top이 -1이면 참을 반환
int size_stack()
{
return top+1;
}//top이 0부터 시작이기 때문에, ex)top이 3이라면 배열은 0부터 시작이기 때문에 사이즈는 4
int peek()
{
return stack[top];
}
void push(int n)
{
if(is_full())
{
printf("에러입니다");
}
stack[++top]=n;
}
int pop()
{
if(is_empty())
{
printf("에러입니다");
}
int x;
x=stack[top--];
return x;
}
int main()
{
int i;
init_stack();
for(i=1;i<10;i++)
{
push(i);
}
printf("스택 push 9회\n");
printf("\tpop()-->%d\n",pop());
printf("\tpop()-->%d\n",pop());
printf("\tpop()-->%d\n",pop());
}
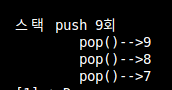
위와 같이 코드를 치면 결과는 1부터9까지 push되고 pop을 3번 했기 때문에 제일 늦게 들어온 순서대로 9,8,7이 나오게 된다.
연결리스트를 이용한 스택을 하기전에 공부하면 좋은 개념은 동적 할당이다.
이번 코드에서는 동적 노드를 생성하는데 그 이유는 다음과 같다.
1.메모리효율성
- 연결 리스트는 필요할 때마다 메모리를 할당받아 사용한다.
- 배열처럼 고정된 크기를 설정할 필요가 없으므로, 실제 사용량에 맞게 메모리를 할당할 수 있다.
2.유연한 크기 조정
- 배열은 미리 크기를 설정해야 해서 크기가 제한적이지만, 연결 리스트는 필요에 따라 동적 할당을 통해 크기를 조절할 수 있다.
- 데이터의 양을 미리 예측하기 어려운 경우 동적 노드 생성이 매우 유리하다.
3.빠른 삽입과 삭제
- 동적 노드 할당을 통해, 노드를 자유롭게 추가하거나 제거할 수 있다.
- 연결 리스트에서는 중간에 노드를 삽입하거나 삭제할 때, 단순히 노드의 포인터만 변경하면 되므로 배열보다 훨씬 효율적이다.
그렇다면 쓰는 방법은??
C 언어에서 동적 노드는 malloc 함수를 사용하여 생성합니다. malloc은 메모리를 할당하고, 그 주소를 반환합니다. 반환된 주소를 통해 노드에 접근할 수 있다.
<연결 리스트를 이용한 스택>
typedef struct Node
{
int data;
struct Node* next;
}Node;
Node* top = NULL;
void init()
{
top = NULL;
}
int is_empty()
{
return top == NULL;
}
void push(int n)
{
Node* p = (Node*)malloc(sizeof(Node));
p->data = n;
p->next = top;
top = p;
}
int pop()
{
if (is_empty())
{
printf("에러입니다.\n");
}
Node* p;
int n;
p = top;
top= p->next;
n = p->data;
free(p);
return n;
}
int peek()
{
if (is_empty())
{
printf("에러입니다.\n");
}
return top->data;
}
int size()
{
Node* p;
int count=0;
for (p = top; p->next != NULL; p = p->next)
{
count++;
}
return count;
}
int main()
{
int i;
for (i = 1; i < 10; i++)
{
push(i);
}
printf("\t%d\n", pop());
printf("\t%d\n", pop());
printf("\t%d\n", pop());
printf("\t%d\n", peek());
}
연결리스트는 배열에 비해서 코드 난이도가 좀 있으니 나눠서 자세히 봐보자
typedef struct Node { int data;//데이터 필드:데이터 값 struct Node* next;//링크 필드:다음 포인터를 가리킴 }Node; Node* top = NULL; //top 헤드 포인터 선언을 해주면서 NULL로 초기화=>여기서 내가 가진 의문점, typedef를 이용해서 Node라는 구조체를 만들었는데 왜 그안에 자기 자신 참조 코드인 Node* next;에 왜 struct를 또 썼을까?
=>C 언어에서 구조체가 완전히 선언되기 전까지는 typedef로 별칭이 적용되지 않기 때문이다.
void init() { top = NULL;//NULL로 초기화 } int is_empty() { return top == NULL;//top==NULL이면 true을 반환 }
void push(int n) { Node* p = (Node*)malloc(sizeof(Node)); //동적 노드 생성 p->data = n; //노드 p에 데이터필드에 값 삽입 p->next = top;//p의 링크 필드를 현재 top에 가리키게 만듬 top = p;//헤드포인터인 top을 p노드로 설정 }
int pop() { if (is_empty()) { printf("에러입니다.\n"); } Node* p; int n; p = top; top= p->next; n = p->data; free(p); return n; }=>여기서 내가 가진 의문점,왜 push에서는 동적 노드를 생성했는데 pop이나 size에는 Node p;이런식으로 선언을 했을까?
=>push같이 새로운 노드를 만들 때는 malloc을 사용하여 동적 메모리 할당을 해야하지만 pop이나 size같이 이미 존재하는 노드를 다루는 작업을 할때에는 동적 메모리 할당 없이 Node p;처럼 포인터만 선언하여 사용한다.
int peek() { if (is_empty()) { printf("에러입니다.\n"); } return top->data; //헤드포인터에 있는 값 출력 }
int size() { Node* p; int count=0; for (p = top; p->next != NULL; p = p->next) { count++; }//노트 p의 다음 링크 필드가 NULL이 되면 카운트값 출력 return count; }=>여기서 내가 가진 의문점,왜 push에서는 동적 노드를 생성했는데 pop이나 size에는 Node p;이런식으로 선언을 했을까?
=>push같이 새로운 노드를 만들 때는 malloc을 사용하여 동적 메모리 할당을 해야하지만 pop이나 size같이 이미 존재하는 노드를 다루는 작업을 할때에는 동적 메모리 할당 없이 Node p;처럼 포인터만 선언하여 사용한다.
이렇게 c언어의 배열과 연결리스트 방식을 이용해 스택을 구현해봤다. 그렇다면 자바에서는 어떻게 쓰일까?
자바에서의 스택(stack)
자바에는 c언어와 달리 내가 직접 하나하나 구현을 하지 않아도 클래스로 존재하여 쓰기는 더 편하다.
그렇다면 스택 클래스안에 메서드들을 하나씩 자세히 봐보자!
1.선언
- import java.util.Stack;
- Stack<자료형> stack = new Stack<>();
=>위 같은 경우는 자료형에 넣은 자료형만 삽입, 삭제 가능- Stack 변수명 = new Stack();
=>위 같은 경우는 어떤 자료형이든 삽입, 삭제 가능(이전에 int형을 넣었어도 String형 삽입 가능)
다음으로 메서드이다.
1.push(삽입)
public E push(E item)
- 매개변수:1개
- 기능:Pushes an item onto the top of this stack. This has exactly the same effect as:
addElement(item)
=>요소추가를 하는 기능- 함수내 어떻게 작동하는가: item - the item to be pushed onto this stack.
=>항목 - 이 스택에 푸시할 항목- 리턴값:the item argument
2.pop(삭제)
public E pop()
- 매개변수:x
- 기능:Removes the object at the top of this stack and returns that object as the value of this function.
=>스택의 맨 위에 있는 개체를 제거하고 해당 개체를 이 함수의 값으로 반환- 리턴값:The object at the top of this stack (the last item of the Vector object).
=>이 스택의 맨 위에 있는 개체
3.peek
public E peek()
- 매개변수:x
- 기능:Looks at the object at the top of this stack without removing it from the stack.
=>스택에서 개체를 제거하지 않고 이 스택의 맨 위에 있는 개체를 찾는다.- 리턴값:the object at the top of this stack (the last item of the Vector object).
=>이 스택의 맨 위에 있는 개체
4.empty
public boolean empty()
- 매개변수:x
- 기능:Tests if this stack is empty.
=>이 스택이 비어 있는지 테스트- 리턴값:true if and only if this stack contains no items; false otherwise.
=>이 스택에 항목이 없는 경우에만 참이고 그렇지 않은 경우에는 거짓
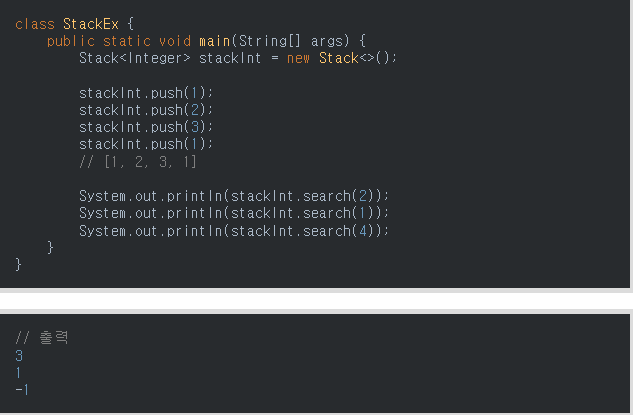
5.search
public int search(Object o)
- 매개변수:1개
- 기능:Returns the 1-based position where an object is on this stack. If the object o occurs as an item in this stack, this method returns the distance from the top of the stack of the occurrence nearest the top of the stack; the topmost item on the stack is considered to be at distance 1. The equals method is used to compare o to the items in this stack..
=>메서드의 인자를 스택에서 검색하여 해당 위치를 반환한다. 만약 해당 인자가 여러 개일 경우, 마지막 위치를 반환한다. 여기서 위치는 인덱스가 아닌 빠져나오는 순서를 뜻한다.
또한, 찾는 값이 스택에 없을 경우 -1을 반환한다.- 리턴값:the 1-based position from the top of the stack where the object is located; the return value -1 indicates that the object is not on the stack.
=>객체가 위치한 스택의 상단에서 1을 기준으로 한 위치, 반환 값 -1은 객체가 스택에 없음을 나타낸다.
하지만 이런 스택 메서드는 성능과 효율성 측면에서는 ArrayDeque보다 불리하다.
여기서 ArrayDeque란? 배열 기반의 덱(Deque) 자료구조이다.
이 부분은 다음에 더 자세히 알아볼 것이다.
