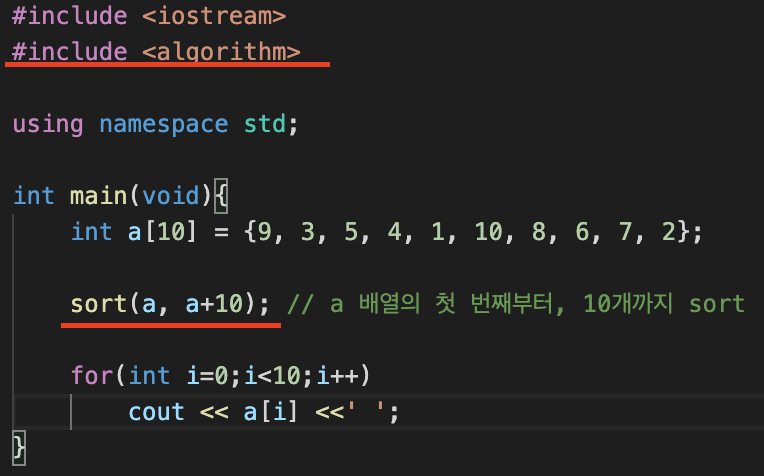
사용법
#include <algorithm>을 include 해주어야 한다.
sort(배열 변수 명, 정렬할 데이터 갯수);로 사용한다.
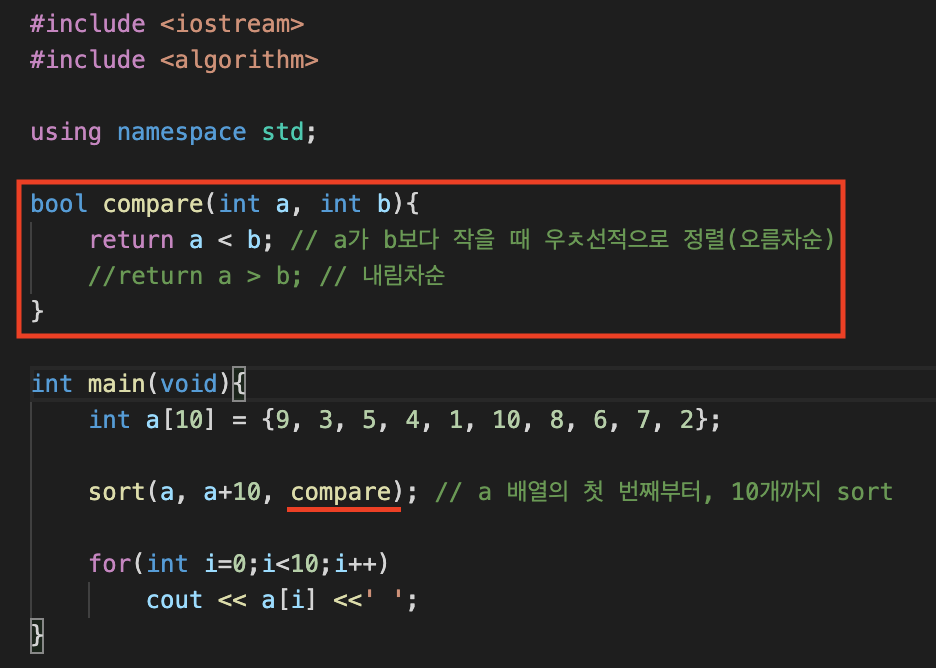
오름차순 & 내림차순
sort함수에 3번째 인자를 넣어주면, 오름차순 내림차순도 설정해 줄 수 있다.(Default 값은 오름차순이다.)
sort(배열 변수 명, 정렬할 데이터 갯수, 함수)
compare라는 함수를 만들어, 두 수를 비교하여, 처음 수가 작은 경우를 true로 return 해주면 오름차순. 그 반대는 내림차순이다.
실전 사용법
실무에서는 객체를 많이 사용한다. 이 경우 sort함수를 사용하는 법을 알아본다. 특정한 변수를 기준으로 정렬해주는 방법이다.
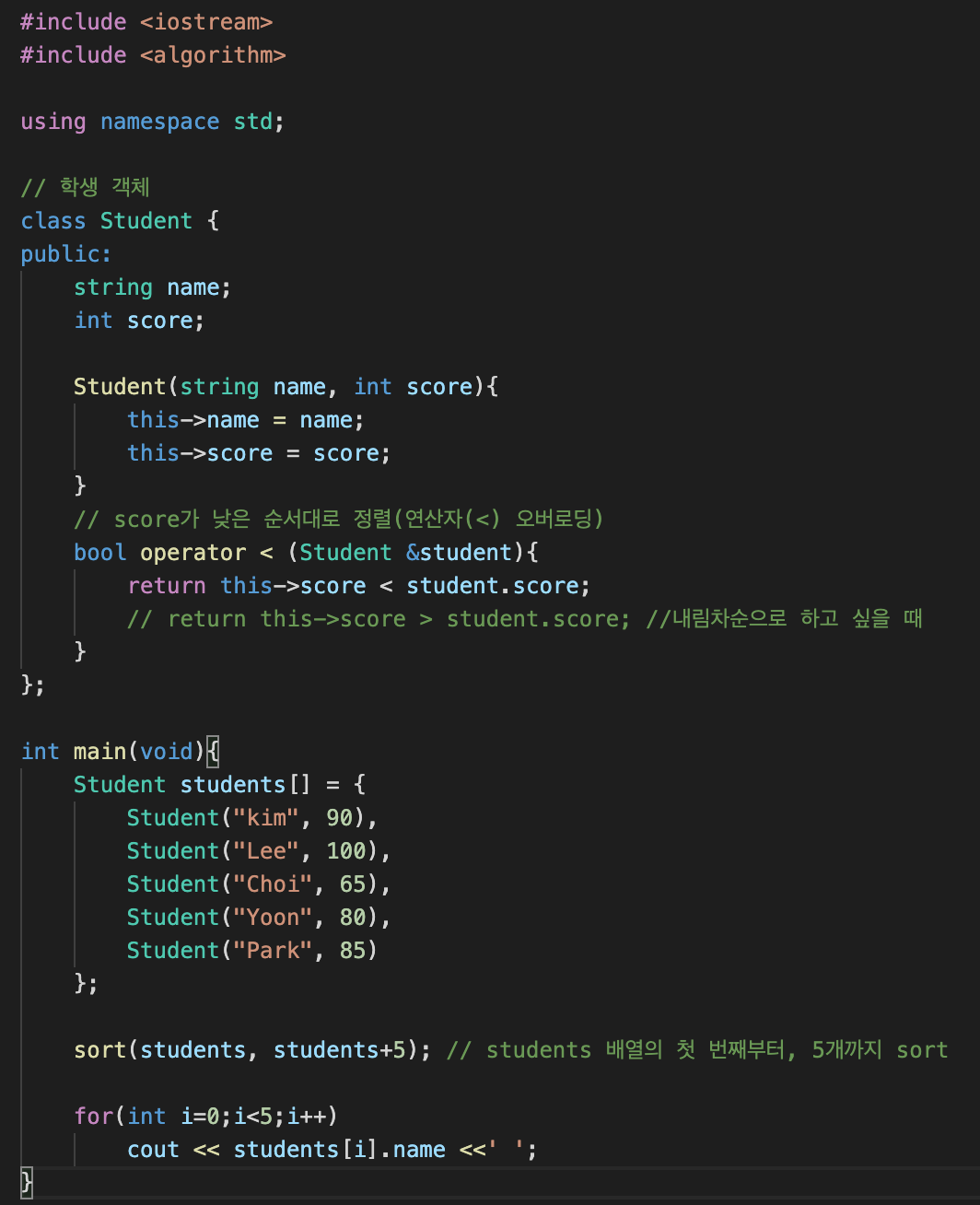
#include <iostream>
#include <algorithm>
using namespace std;
// 학생 객체
class Student {
public:
string name;
int score;
Student(string name, int score){
this->name = name;
this->score = score;
}
// score가 낮은 순서대로 정렬(연산자(<) 오버로딩)
bool operator < (Student &student){
return this->score < student.score;
// return this->score > student.score; //내림차순으로 하고 싶을 때
}
};
int main(void){
Student students[] = {
Student("kim", 90),
Student("Lee", 100),
Student("Choi", 65),
Student("Yoon", 80),
Student("Park", 85)
};
sort(students, students+5); // students 배열의 첫 번째부터, 5개까지 sort
for(int i=0;i<5;i++)
cout << students[i].name <<' ';
}알고리즘 대회 사용법
클래스를 만드는 것은 속도면에서 불리하다. 대신 Pair 라이브러리를 사용한다.
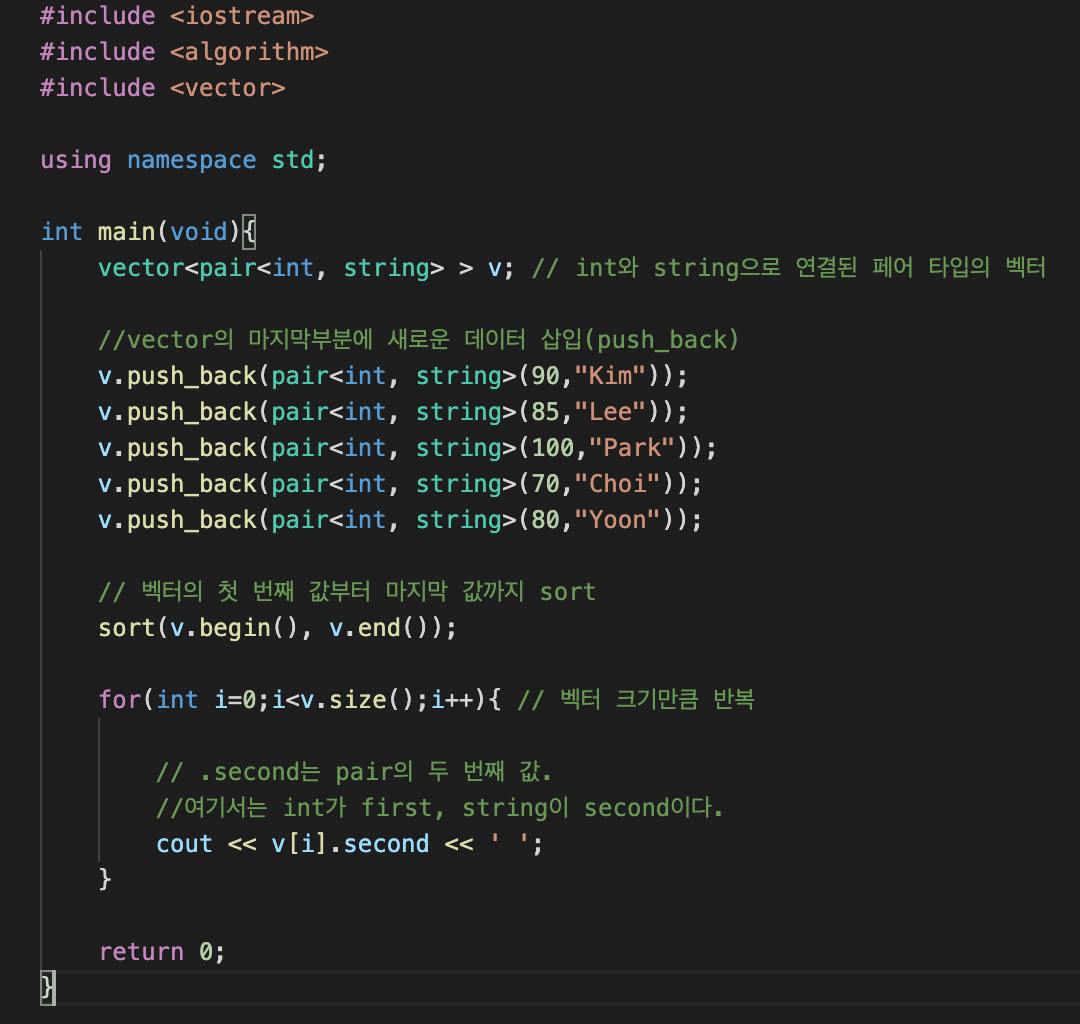
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(void){
vector<pair<int, string> > v; // int와 string으로 연결된 페어 타입의 벡터
//vector의 마지막부분에 새로운 데이터 삽입(push_back)
v.push_back(pair<int, string>(90,"Kim"));
v.push_back(pair<int, string>(85,"Lee"));
v.push_back(pair<int, string>(100,"Park"));
v.push_back(pair<int, string>(70,"Choi"));
v.push_back(pair<int, string>(80,"Yoon"));
// 벡터의 첫 번째 값부터 마지막 값까지 sort
sort(v.begin(), v.end());
for(int i=0;i<v.size();i++){ // 벡터 크기만큼 반복
// .second는 pair의 두 번째 값.
//여기서는 int가 first, string이 second이다.
cout << v[i].second << ' ';
}
return 0;
}위의 개념을 응용하여, 3개의 변수를 2개의 기준으로 정렬할 수도 있다.
벡터 타입을 Pair안에 Pair를 넣는 식으로 변수 갯수를 늘려줄 수 있다.
2개의 기준을 주기 위해서는 compare 함수를 정의해줘야한다.
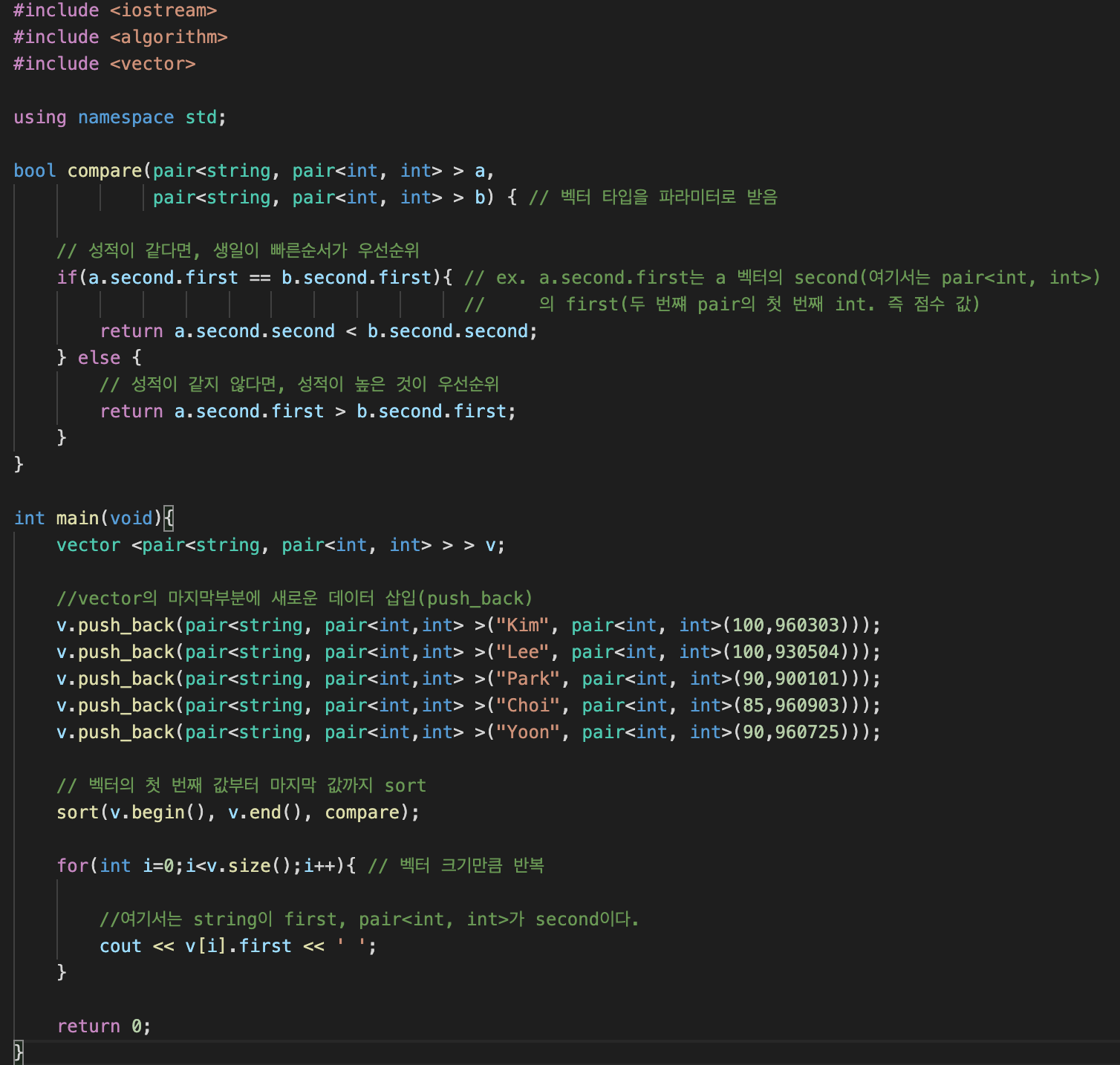
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
bool compare(pair<string, pair<int, int> > a,
pair<string, pair<int, int> > b) { // 벡터 타입을 파라미터로 받음
// 성적이 같다면, 생일이 빠른순서가 우선순위
if(a.second.first == b.second.first){ // ex. a.second.first는 a 벡터의 second(여기서는 pair<int, int>)
// 의 first(두 번쨰 pair의 첫 번째 int. 즉 점수 값)
return a.second.second < b.second.second;
} else {
// 성적이 같지 않다면, 성적이 높은 것이 우선순위
return a.second.first > b.second.first;
}
}
int main(void){
vector <pair<string, pair<int, int> > > v;
//vector의 마지막부분에 새로운 데이터 삽입(push_back)
v.push_back(pair<string, pair<int,int> >("Kim", pair<int, int>(100,960303)));
v.push_back(pair<string, pair<int,int> >("Lee", pair<int, int>(100,930504)));
v.push_back(pair<string, pair<int,int> >("Park", pair<int, int>(90,900101)));
v.push_back(pair<string, pair<int,int> >("Choi", pair<int, int>(85,960903)));
v.push_back(pair<string, pair<int,int> >("Yoon", make_pair(90, 960725))); // 이런식으로 make_pair를 사용해도 된다.
// 벡터의 첫 번째 값부터 마지막 값까지 sort
sort(v.begin(), v.end(), compare);
for(int i=0;i<v.size();i++){ // 벡터 크기만큼 반복
//여기서는 string이 first, pair<int, int>가 second이다.
cout << v[i].first << ' ';
}
return 0;
}reference: https://blog.naver.com/ndb796/221227975229
