캐싱을 사용하는 이유
캐싱을 하는 이유는 데이터를 효율적으로 재사용하기 위함이다. 컴퓨터에서 캐시는 일반적으로 일시적인 특징이 있는 데이터 하위 집합을 저장하는 고속 데이터 스토리지 계층인데, 캐싱을 할 경우 기본 스토리지에 액세스할 때보다 데이터를 더 빠르게 검색하거나 요청할 수 있다. 이런 점에서 캐시의 주요 목적은 데이터 처리 성능을 높이는 것이라고 할 수 있다.
1. 캐시(cache)
지역성(locality)을 이용하여 데이터 접근 속도를 빠르게 하기 위한 메모리 계층이다캐시 메모리: 실제 메모리와 cpu 사이에서 빠르게 전달을 위해서 미리 데이터들을 저장해두는 좀더 빠른 메모리
지역성(locality)이란?
① 시간지역성
- 데이터의 읽기/쓰기를 위해 특정 메모리가 사용됐을 때 가까운 시일 내에 해당 메모리가 다시 사용될 가능성이 높다는 것
② 공간지역성
- 공간 지역성은 특정 데이터와 가까운 주소가 순서대로 접근되는 경우를 말합니다. 한 메모리 주소에 접근할 때 그 주소뿐만 아니라 해당 블록을 전부 캐시에 가져옴으로써 공간 지역성의 효율을 높인다
③ 순차적 지역성
- 분기가 발생하는 비순차적인 실행이 아닌 이상, 명령어들이 메모리에 저장된 순서대로 실행된다는 특성을 이용하여 순차적일수록 데이터가 사용될 가능성이 높다는 것
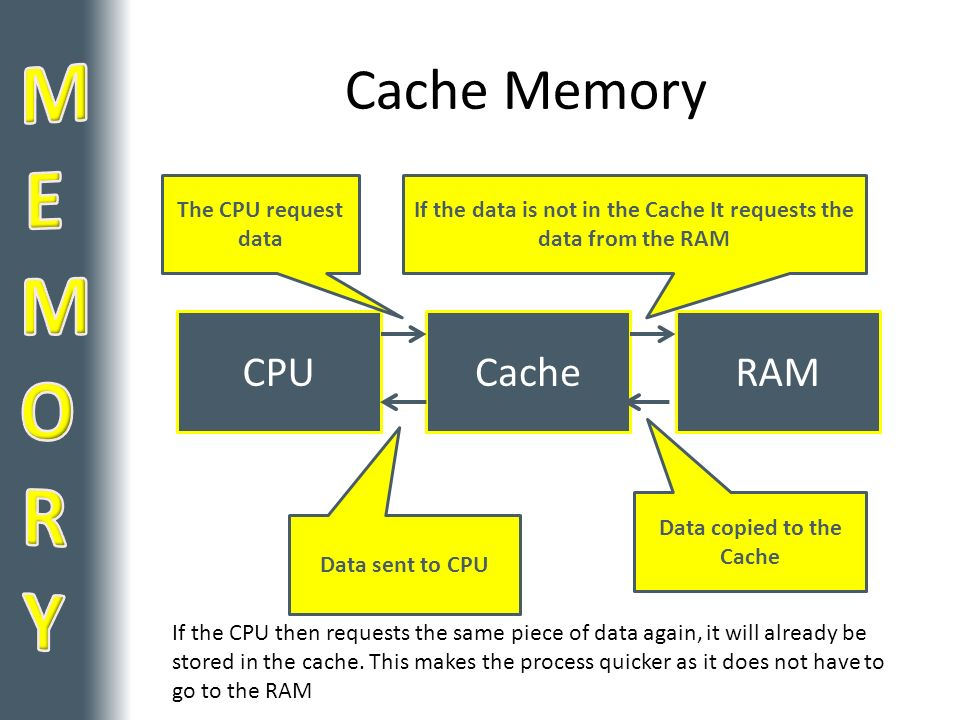
- CPU와 RAM의 속도 차이는
병목현상(bottleneck)을 유발하며 이는 성능 저하의 원인이 된다 - 캐시는 CPU와 램(DRAM) 사이에서 중간자 역할을 하며, 자주 사용되는 데이터를 캐시에 저장하면 CPU가 빠르게 꺼내어 사용할 수 있다
캐시 히트(cache hit): CPU에서 요청한 데이터가 캐시 안에 있을 때캐시 미스(cache miss): CPU에서 요청한 데이터가 캐시에 존재하지 않을 때
2. 캐싱(caching)
- 캐시 영역으로 데이터를 가져와서 접근하는 방식
- 속도가 느린 디스크의 데이터를 속도가 빠른 메모리로 가져와서 메모리 상에서 읽고 쓰는 작업을 수행하거나 메모리 상에 있는 데이터를 연산이 더 빠른 CPU 메모리 영역으로 가져와서 작업을 수행하는 것
1) 캐싱에 적합한 데이터
- 반복적이고 동일한 결과가 나오는 기능의 반환값
- 업데이트가 자주 발생하지 않는 데이터
- 자주 조회되는 데이터
2) 캐싱 전략
① Look aside cache (Lazy Loading)
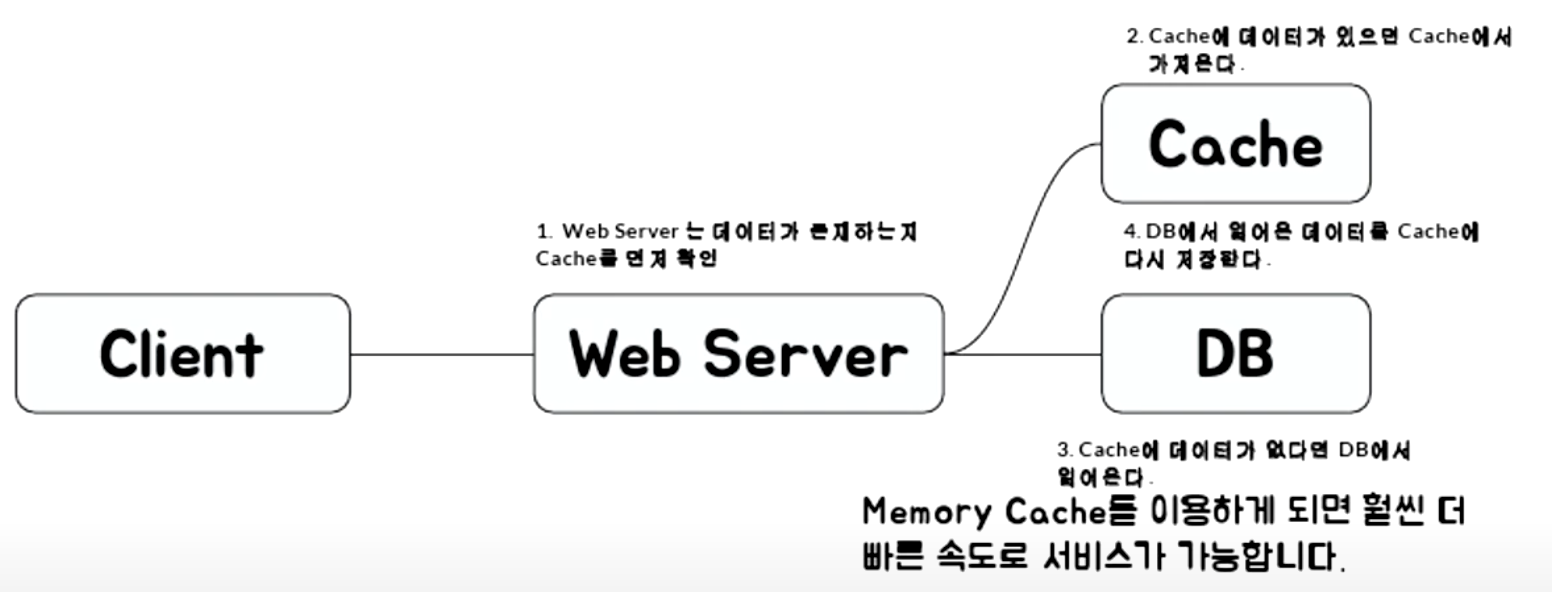
- 읽기 데이터를 캐시에서 찾고, 없으면 DB 에서 찾는다.
- look aside cache는 캐시를 한번 접근하여 데이터가 있는지 판단한 후, 있다면 캐시의 데이터를 사용하며 없다면 실제 DB 또는 API를 호출하는 로직으로 구현. 대부분의 cache를 사용한 개발이 해당 프로세스를 따른다.
② Write-Through
- 데이터를 추가하거나 업데이트할 때 캐시에 동시에 업데이트하는 전략
- 읽기 작업을 할 때는 DB에 접근할 필요 없이 캐시만 읽으면 된다.
③ Write-back
- 데이터를 캐시에 먼저 저장해놓고 일정기간 혹은 일정한 크기가 됐을 때 캐시에 모여있는 데이터를 DB에 저장한 후 캐시에 있던 데이터를 삭제하는 방식
참고
https://literate-t.tistory.com/73?category=762215
https://slideplayer.com/slide/9299556/
https://letitkang.tistory.com/165
https://velog.io/@now_iz/Redis-%EB%A1%9C-%EC%BA%90%EC%8B%B1%ED%95%98%EA%B8%B0
https://chihunmanse.github.io/cache/

개발자로서의 삶은 https://velog.io/@maxminos 에서 기록하고 있습니다 😀