1. MongoDB
신속하게 데이터를 저장하고 그 데이터를 가공하는데 최적화 되어있는 NoSQL 솔루션
1) Introduction
- 10gen 사에서 개발한 솔루션(C++)
- Key-Value와 다르게 여러 용도로 사용이 가능(범용적)
- 스키마를 고정하지 않는 형태이기 때문에 스키마 변경으로 오는 문제가 없고, 데이터를 구조화해서 Json 형태로 저장 (데이터를 Key_Value화하여 저장)
- Join 이 불가능하기 때문에 Join이 필요없도록 데이터를 설계해야 한다
(빅데이터 처리 속도 향상을 위해 Join을 지원하지 않음) - 메모리맵 형태의 파일엔진 DB이기 때문에 메모리에 의존적
- 메모리 크기가 성능을 좌우
- 메모리를 넘어서는 경우 성능이 급격히 저하됨
- 쌓아놓고 삭제가 없는 경우가 적합 ex)
로그 데이터,이벤트 참여 내역,세션 - 트랜잭션이 필요한
금융,결제,빌링,회원정보등에는 부적합 -> 보안이 중요한 데이터에 대해서는RDBMS사용
2) Document Data Model
- 도큐먼트 데이터 모델 : 데이터 설계를 '종이문서' 설계하듯 설계해야 한다
- 속성의 이름과 값으로 이루어진 쌍의 집합
- 속성은 문자열이나 숫자, 날짜 가능
- 배열 또는 다른 도큐먼트를 지정하는 것도 가능
- 하나의 document에 필요한 정보를 모두 담아야 함
- 하나의 쿼리로 모두 해결이 되도록 collection model 설계를 해야 함
- Join이 불가능하므로 미리 embedding 시켜야 함
3) 도큐먼트 형태의 구조
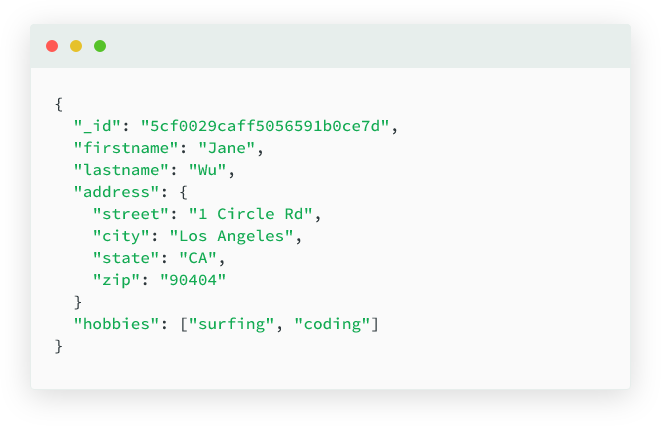
{ }이 중괄호가 하나의 도큐먼트- 데이터가 Key - Value 쌍으로 저장
JSON 이란?
개념
- JavaScript Object Notation이라는 자바스크립트의 object 개념을 차용
- lightweight data 교환 형식
- 사람이 읽고 쓰기 쉽고, 기계가 파싱하고 생성하기 쉬움
- JavaScript의 Array 문법으로 데이터 구조를 기술하는 방법으로 XML이 가지는 유연성과 구조적 데이터 표현기능을 확보하면서 XML이 가진 오버헤드를 줄이는 방법으로 사용됨
- 클라이언트에서 처리 퍼포먼스가 높음
- XML이 표현하는 구조적인 정보 모두 표현 가능
- 송수신 데이터로 XML을 사용하는 것에 비해 훨씬 빠르고 간편
표기법
- 각 객체는 중괄호
{ }로 시작하고 끝남- 문자열과 값으로 구성되어 있고 콜론
:으로 구분- 각 멤버들은 콤마
,로 구분- 값은 object, string, number, array, true, false, null 사용 가능
- 문자는 따옴표로 사용, 숫자는 따옴표 사용하지 않음
- 배열의 경우 대괄호
[ ]로 시작하고 끝남. 각 값은 콤마,로 구분
2. MongoDB 장점/단점
1) 장점
- Schema-less 구조
- 다양한 형태의 데이터 저장 가능
- 데이터 모델의 유연한 변화 가능 (데이터 모델 변경, 필드 확장 용이)
- 많은 양의 데이터에 대한 Read / Write 성능이 뛰어남
- Scale Out 구조
- 많은 데이터 저장 가능
- 장비 확장 간단
- Json 구조 : 데이터 직관적 이해 가능
- 사용 방법 쉽고, 개발이 편리함
빅데이터 처리에 특화
- Memory Mapped (데이터 쓰기 시에 OS의 가상 메모리에 데이터를 넣은 후 비동기로 디스크에 기록하는 방식 )를 사용
- 방대한 데이터를 빠르게 처리 가능
- OS의 메모리를 활용하기 때문에 메모리가 차면 하드디스크로 데이터 처리하여 속도가 급격히 느려짐
- 하드웨어적인 측면에서 투자가 필요
2) 단점
- 데이터 업데이트 중 장애 발생 시, 데이터 손실 가능
- 많은 인덱스 사용 시, 충분한 메모리 확보 필요
- 데이터 공간 소모가 RDBM 에 비해 많음 (비효율적으로 Key 중복 입력)
- 복잡한 Join 사용 시 성능 제약이 따름
- transactions 지원이 RDBMS 대비 미약함
- 제공되는 MapReduce 작업이 Hadoop 에 비해 성능이 떨어짐
데이터의 양이 많을 경우
- 일부 데이터 손실 가능성 존재
- 샤딩(데이터를 분산해서 저장하는 것)의 비정상적인 동작 가능성
- 레플리카 프로세스의 비정상 동작 가능성 -> 데이터 복제 문제 발생
- 결국 데이터 부분 부분의 유실 가능성 존재
3) MongoDB vs MySQL
- 동일한 데이터를 가지고 CRUD를 수행할 때, 대부분 MongoDB의 결과가 빠르게 나옴
- MongoDB의 경우, Single Node와 Multi Node 간의 성능 차이는 거의 없음
(Delete 연산을 제외하고 대부분 Multi Node 가 근소하게 빠름) - MongoDB Multi Node의 Insert 연산 중에 연산 실패가 일어나는 경우 발생
- 분산을 목적으로 DBMS를 선택할 경우, RDBMS에 비해 낮은 비용과 빠른 성능을 제공하는 MongoDB가 유리함
3. MongoDB 주요 기능
MongoDB Query
- 몽고DB도 자체적으로 CRUD를 실행하는 Query문을 가지고 있다
- Create
db.person.save({'name':'minho'}); - Read
db.person.find(); - Update
db.users.update({'name':'taehoon'}, {'name':'simon', 'language':'[spanish', 'english']}); - Delete
db.users.remove({'name':'soo'})
인덱스
- 다수 인덱스 설정 가능
- 복합 인덱스 지원
- 빠른 검색 지원
- 도큐먼트에 저장된 데이터와 중복 저장 문제
- 메모리가 부족한 시스템에서는 검색 속도 저하 문제
복제
- MongoDB는 기본적으로 분산 시스템이기 때문에 복제가 중요하다
- Master-Slave 구조로 구성
- 데이터 복사본을 Slave에 배치
- Master 장애에 따른 데이터 손실 없이 Slave 데이터 사용 가능
- Master 장애가 발생했을 때, slave에서 master 선출 가능 (중단없는 서비스 가능)
- 데이터 손실을 최소화하기 위해 저널링 지원(MongoDB의 데이터 변화에 따른 모든 연산에 대한 로그 적재)
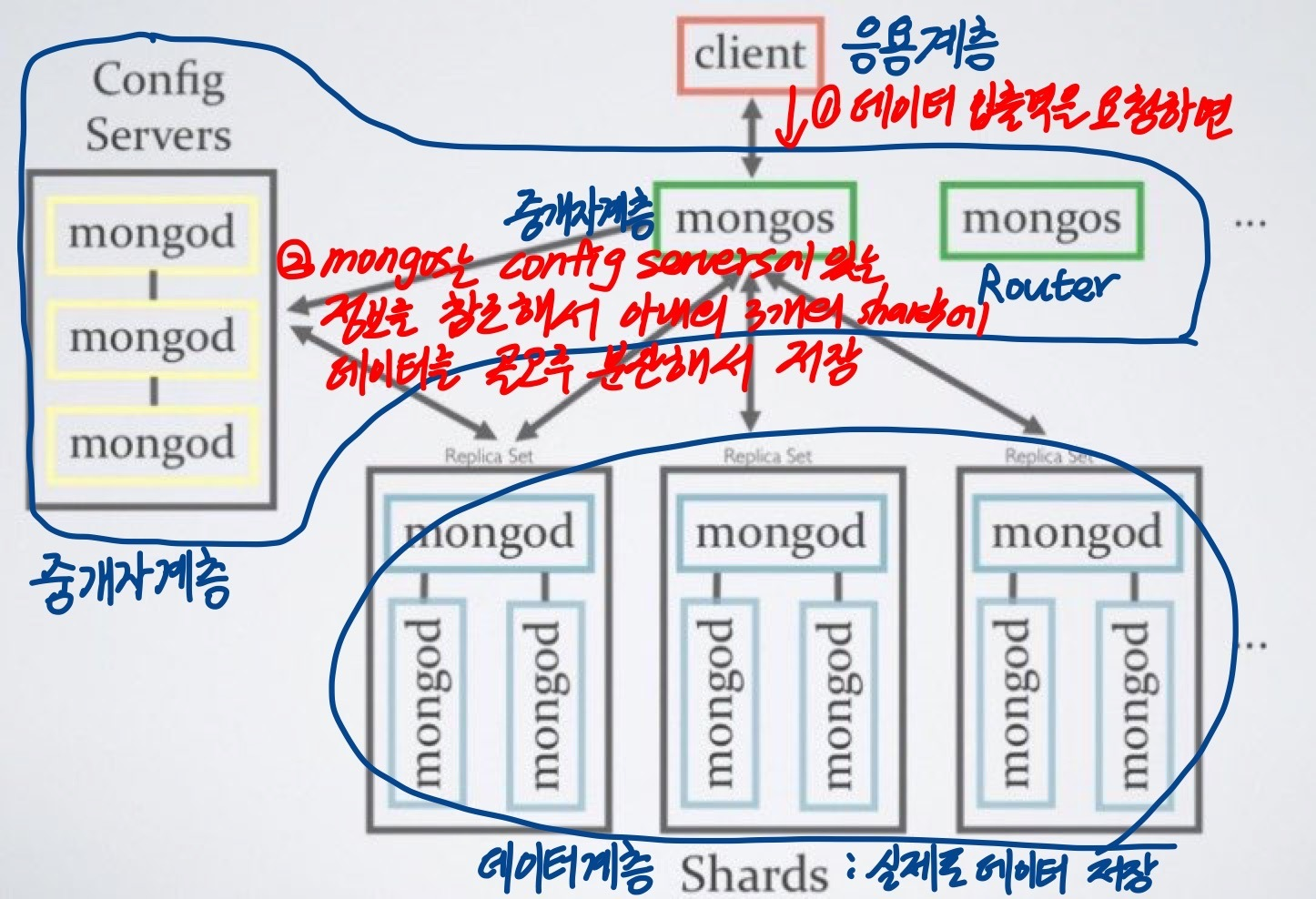
Sharding ( 데이터 분산 저장 )
- 대용량의 데이터를 저장하기 위한 방법
: 소프트웨어적으로 데이터베이스를 분산시켜 처리하는 구조 - 샤딩 방식
- 데이터베이스가 저장하고 있는 테이블을 테이블 단위로 분리하는 방법
- 데이터베이스가 저장하고 있는 테이블 자체를 분할하는 방법
- 분산 데이터베이스의 전통적인 분할 3계층 구조 지원
- 응용 계층, 중개자 계층, 데이터 계층
- 응용 계층은 데이터에 접근하기 위해 중개자를 통해 모든 데이터의 입출력을 처리
- 추상화된 한개의 데이터베이스가 존재하는 것처럼 운용
MapReduce ( 데이터 분산 연산 )
- 대용량의 데이터를 안전하고 빠르게 처리하기 위한 방법
- 데이터를 분산하여 연산하고 다시 합치는 기술
- 맵과 리듀스 단계로 나누어 처리하며, 사용자가 임의 코딩 가능
- 입/출력 데이터는 Key - Value 형탤 구성
- 한 대 이상의 하드웨어를 활용하는 분산 프로그래밍 모델
- 분산을 통해 분할된 조각으로 처리한 다음, 다시 모아서 훨씬 짧은 시간에 계산 완료
- 대용량 파일에 대한 로그 분석, 색인 구축 검색 등에 활용
- 일괄처리 방식으로 전체 데이터 셋을 분석할 필요가 있는 문제에 적합

개발자로서의 삶은 https://velog.io/@maxminos 에서 기록하고 있습니다 😀