캐시와 카프카의 사용이유
아주 단순하게 서버를 구성한다면 서버 한 대면 충분하다. 유저가 가격 비교를 요청하고 외부 API를 연동해서 가격을 가져오면 된다. 그런데 트래픽이 많아진다면 이 한 대의 서버로 운영이 가능할까? 아마도 외부 API 응답을 기다리는 동안 스레드가 블로킹되기 때문에, 트래픽이 많아지면 스레드 풀이 모두 점유되어 서버가 더 이상 요청을 처리하지 못하게 될 수 있다.
나는 트래픽이 많은 상황을 가정하고 이를 어떻게 하면 효율적으로 서버를 운용할 수 있을지에 대해서 고민해보았다. 내가 찾은 답은 캐시 사용과 카프카를 사용하는 것이다!
캐시 사용의 이유
가격 비교의 경우 외부 API를 통해 N분 동안의 가격을 보장받는다면 N분 동안 캐시에 가격 정보를 넣어 조회 성능을 올릴 수 있다고 생각했다.
카프카 사용의 이유
외부 가격비교 연동 API의 응답은 오래 걸릴 수 있다. 여기서 생각해 볼 수 있는 방법은 호출부와 실행부 즉 프로듀서와 컨슘 서버를 나누어 보는 것이다. 이때 비동기 큐를 적용하여 구조를 분리할 수 있다. 비동기 큐의 장점은 유저의 호출에 빠른 답을 할 수 있고 컨슘 서버를 유연하게 구성할 수 있다는 점이다. 여기에 더해 카프카는 발급된 메시지를 저장하고 에러가 났을 경우 메시지 컨슘이 멈춘 지점부터 다시 시작할 수 있다는 장점이 있다.
캐시 히트와 캐시 미스
유저가 가격비교 버튼을 눌렀을 때 API의 동작 과정을 살펴보자
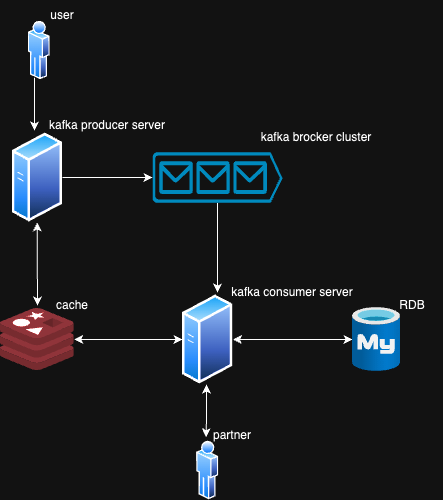
- 서버 설계도를 보면 우선 카프카 프로듀서 서버에 접근
- 캐시에서 가격 비교 결과 조회
- 캐시 HIT -> 캐시에서 조회 결과 반환
- 캐시 MISS -> 외부 가격 비교 API 수행하는 메시지 발행
카프카 적용
도커 컴포즈를 활용한 카프카 서버 실행
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.1
container_name: kafka0
ports:
- "9092:9092"
- "29092:29092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER1:PLAINTEXT,LISTENER1_INTERNAL:PLAINTEXT
KAFKA_LISTENERS: LISTENER1://0.0.0.0:9092,LISTENER1_INTERNAL://0.0.0.0:29092
KAFKA_ADVERTISED_LISTENERS: LISTENER1://localhost:9092,LISTENER1_INTERNAL://kafka0:29092
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER1_INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
docker-compose 파일이다. 개인 프로젝트라서 브로커는 1대만 설정했다.
topic 생성
kafka-topics --create --topic price-compare-requests --bootstrap-server kafka0:29092 --partitions 3 --replication-factor 1price-compare-requests 라는 토픽을 생성하고 파티션은 3개를 만들었다. Kafka는 파티션 구조를 이용해 병렬 소비가 가능하도록 설계되었다. 파티션 수만큼 컨슈머를 병렬로 확장할 수 있다. 파티션이 3개면 컨슈머 서버 총 3대로 병렬처리 할 수 있다. 브로커가 현재는 한 대라서 레플리카 팩터를 1로 설정했다.
producer 서버
suspend fun requestPriceComparison(productId: Long): PriceCompareResponse {
val cached = cacheRepository.get(CacheKey.priceComparison(productId), PriceComparisonResultSummary::class.java)
return cached?.let {
PriceCompareResponse.CacheHit(it)
} ?: run {
priceCompareProducer.sendCompareRequest(productId)
PriceCompareResponse.CacheMiss
}
}@Service
class PriceCompareProducer(
private val kafkaTemplate: KafkaTemplate<String, String>
) {
suspend fun sendCompareRequest(productId: Long) {
val message = """{"productId": "$productId"}"""
kafkaTemplate.send("price-compare-requests", productId.toString(), message)
}
}프로듀서의 서비스 코드이다. 캐시를 조회한 후 캐시에 가격 정보가 없다면 프로듀서를 통해 메시지를 발행한다.
참고로 캐시의 경우 lettuce를 사용해서 구현했다. 비동기와 논블로킹의 이점을 이용하기 위해 코루틴을 사용하여 suspend가 붙었다.
consumer 서버
@Service
class PriceComparisonConsumer(
private val priceComparisonService: PriceComparisonService
) {
private val log = logger()
@KafkaListener(
topics = ["price-compare-requests"],
groupId = "price-compare-consumer-group",
containerFactory = "kafkaListenerContainerFactory"
)
suspend fun consume(@Payload request: PriceCompareRequestMessage) {
priceComparisonService.startComparison(request.productId)
}
}
data class PriceCompareRequestMessage(val productId: Long)카프카 컨슘 서버 내부의 코드이다. 외부 API를 fire and forget 방식으로 호출하기 때문에 코루틴 빌더 launch를 사용하였다. 또한 supervisorScope를 사용한 이유는 일부 외부 API 호출이 실패해도 전체 가격 비교 작업이 중단되지 않도록 하기 위해서이다.
