📌 네이버 랭킹 뉴스 크롤링
✅ 많이 본 뉴스
from urllib.request import urlopen
from bs4 import BeautifulSoup
from pytz import timezone
import pandas as pd
import datetime🔼 크롤링에 필요한 라이브러리(url, BeautifulSoup 등)와 수집일자를 출력하기 위한 라이브러리 임포트
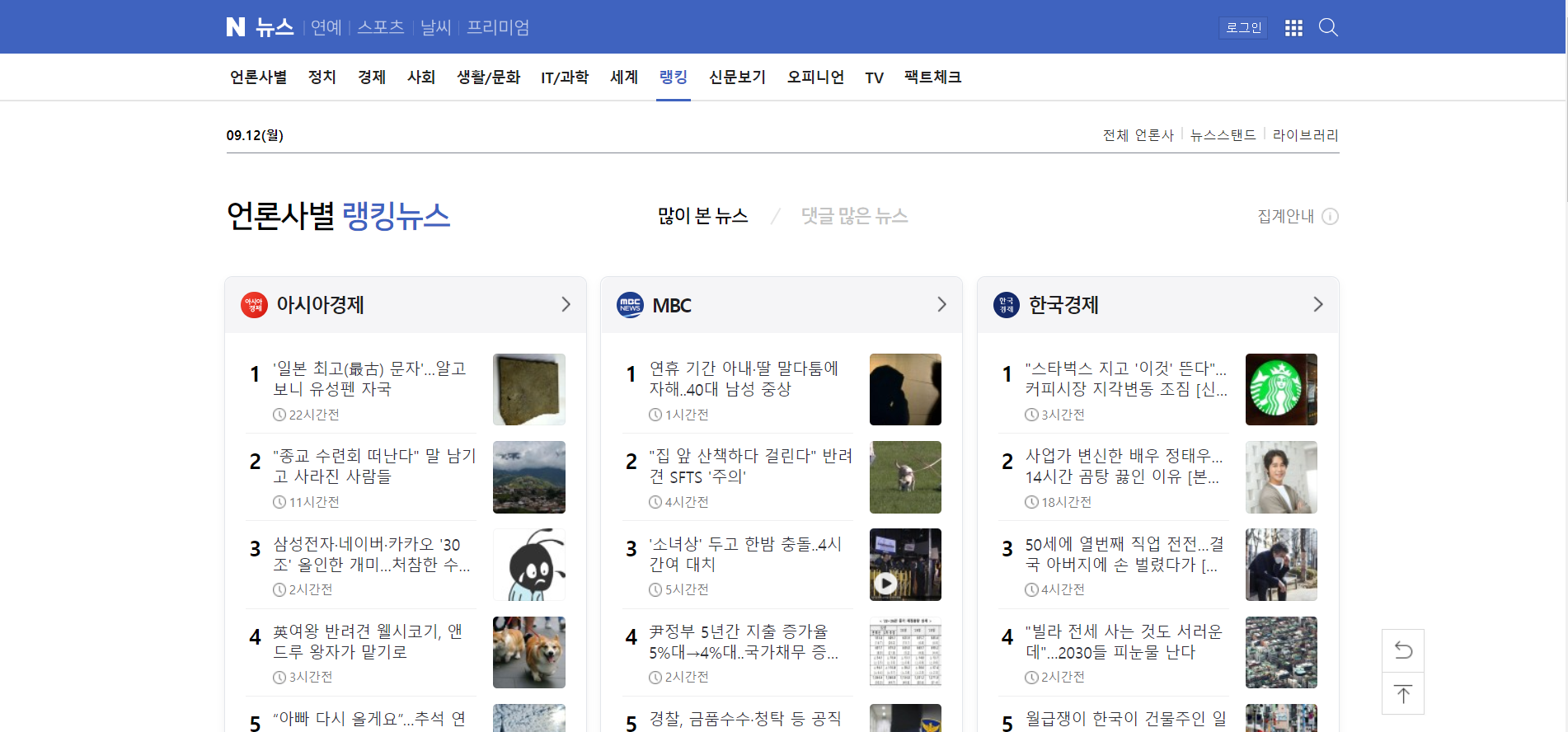
🔼 크롤링할 랭킹 뉴스 화면
개발자 모드로 보면 🔽
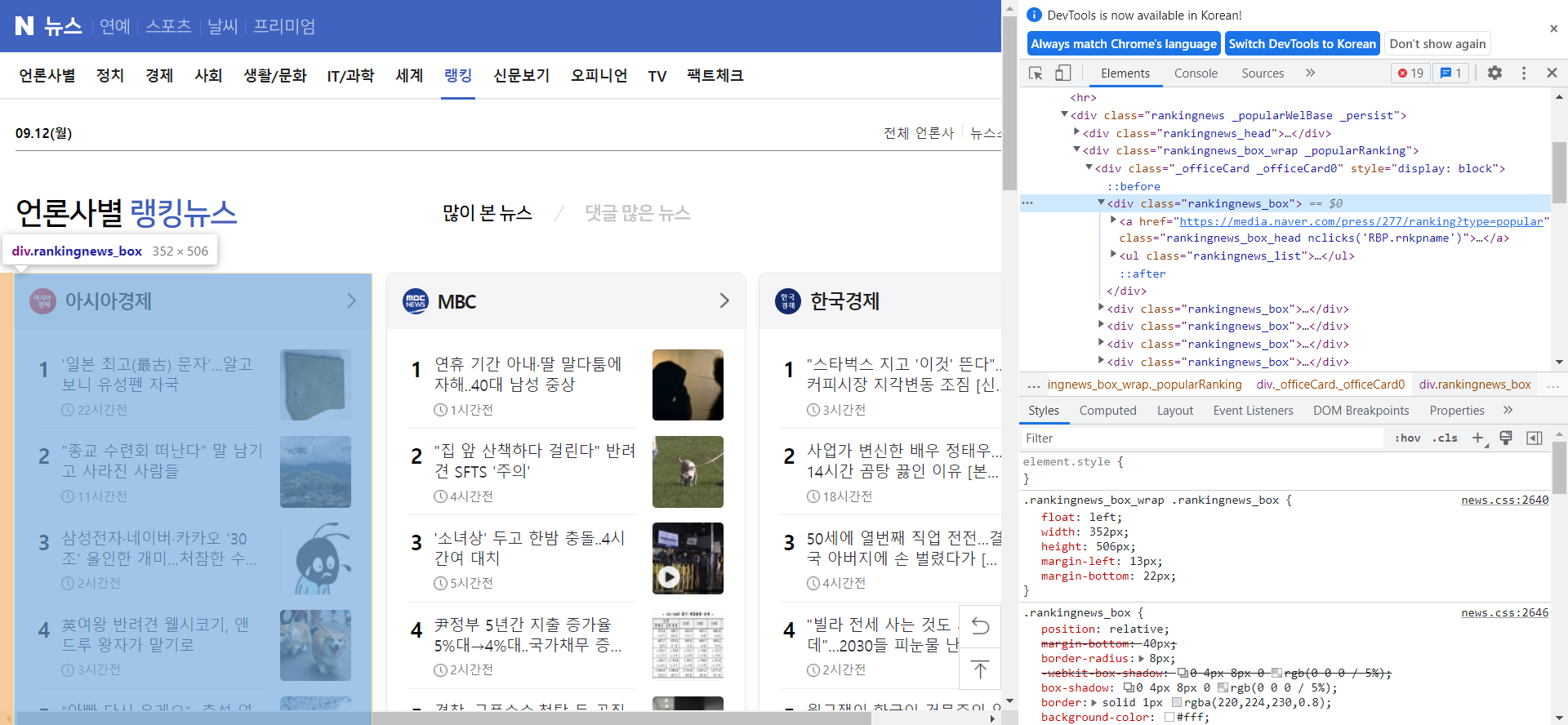
이런식으로 볼 수 있다. 이 html 태그들을 확인하면서 크롤링해야한다.
# 1) 데이터 프레임 생성
data = pd.DataFrame(columns=['언론사명', '순위', '기사제목', '기사링크', '수집일자'])
# 2) 네이버 랭킹 뉴스 접속 주소 준비 : https://news.naver.com/main/ranking/popularDay.naver
url = 'https://news.naver.com/main/ranking/popularDay.naver'
# 3) url에서 html 가져오기
html = urlopen(url)
# 4) html을 파싱할 수 있는 object로 변환
bsObject = BeautifulSoup(html, 'html.parser', from_encoding='UTF-8')🔼 먼저 크롤링한 것을 담을 데이터 프레임을 형성하고 url을 입력후 urlopen을 해준다. BeautifulSoup을 이용하여 파싱할 수 있게 변환.
# 5) 네이버 랭킹 뉴스 정보가 있는 div만 가져오기
div = bsObject.find_all('div', {'class', 'rankingnews_box'})🔼 위의 캡쳐본을 다시 보면 확인할 수 있듯 랭킹 뉴스 정보가 div 태그 안에 rankingnews_box 라는 클래스로 선언되어 있는 것을 볼 수 있다.
find_all을 사용하여 이것들을 가져온다.
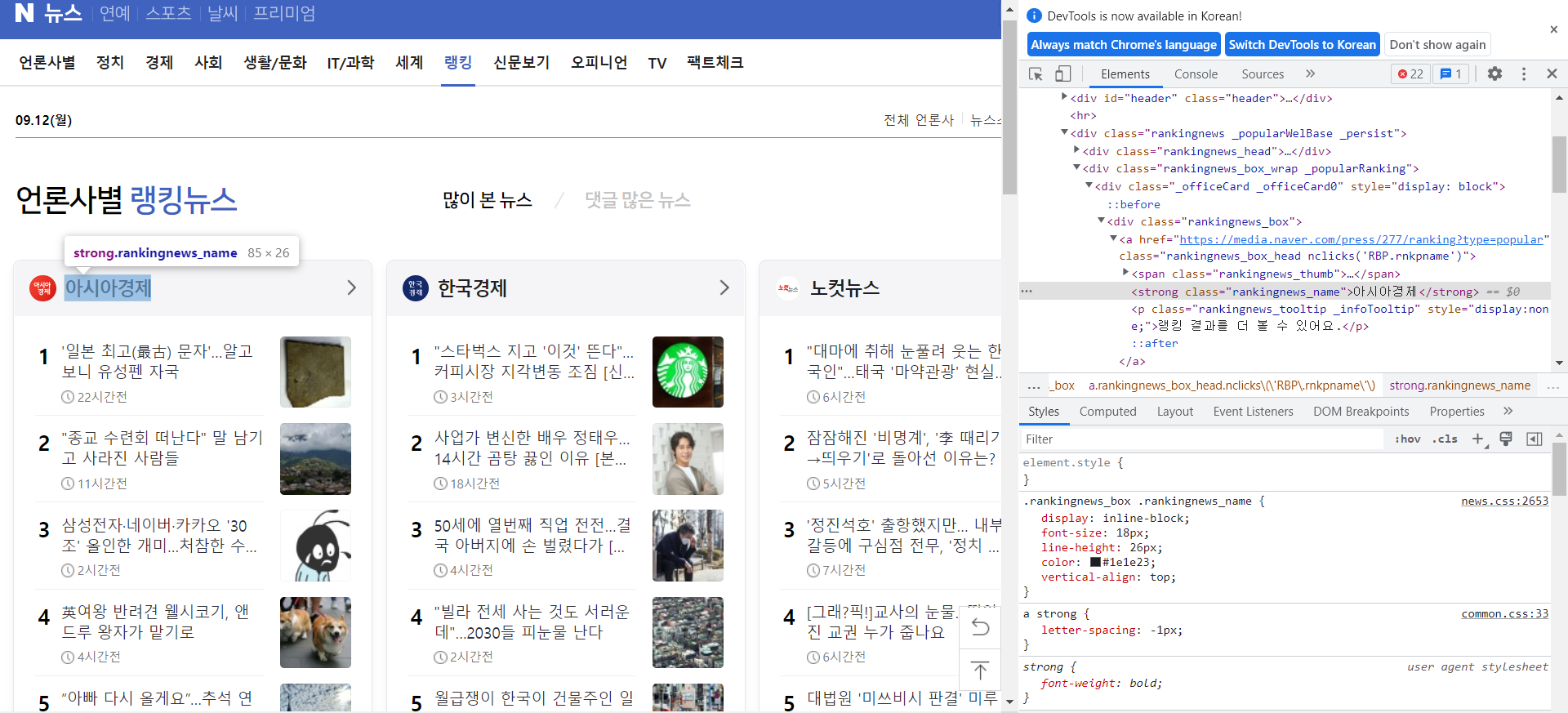
🔼 위의 캡쳐본을 확인해보면 언론사명이
<strong class="rankingnews_name">아시아경제</strong>
로 선언되어 있는 것을 볼 수 있다.
# 6) 네이버 랭킹 뉴스 상세 정보 추출
for index_div in range(0, len(div)):
# 6-1) 언론사명 추출
strong = div[index_div].find('strong', {'class', 'rankingnews_name'})
press = strong.text🔼 해서 find를 이용해서 'strong'안의 class 명 rankingnews_name을 입력해서 추출. 그 후 press라는 변수에 저장.
(✏️ find와 find_all의 차이는?
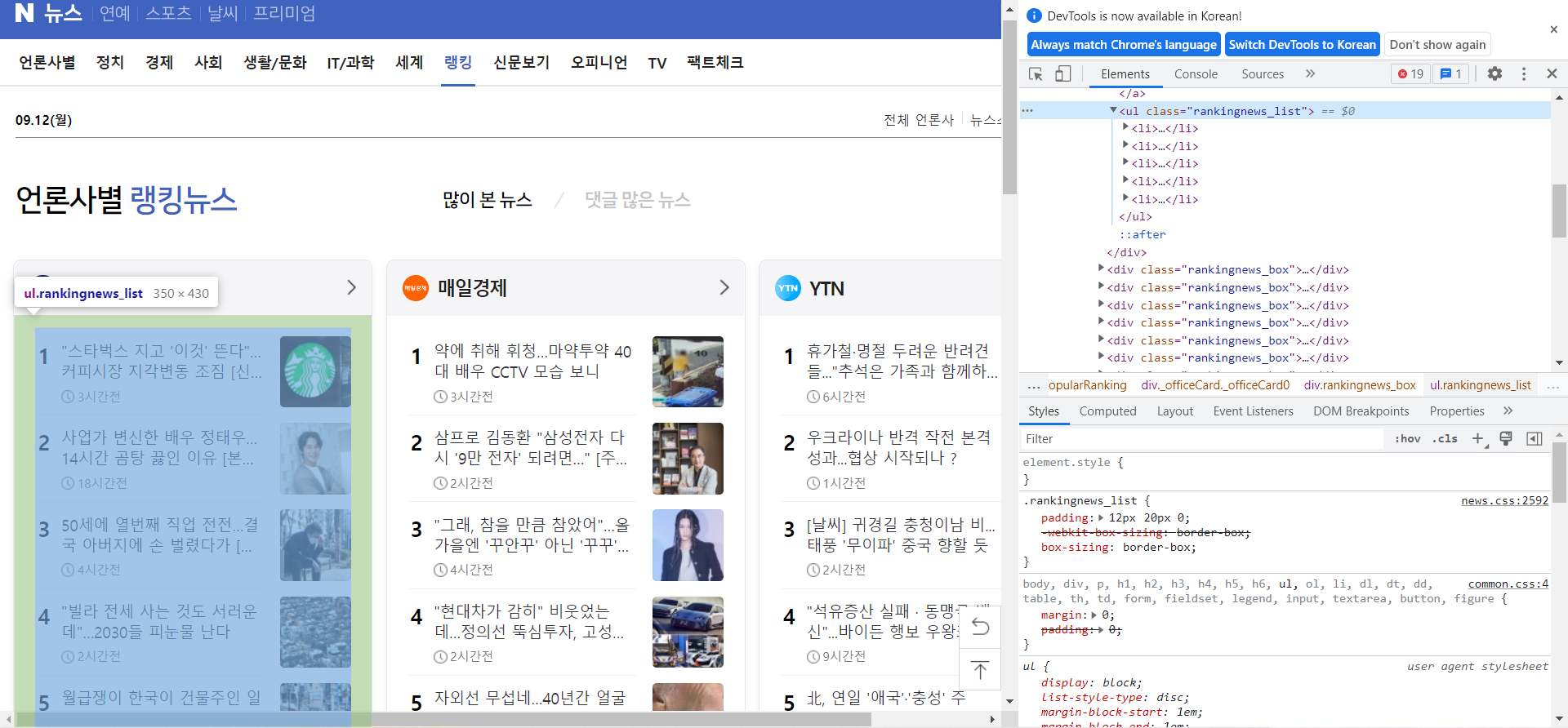
🔼 위를 보면 ul 태그 안 class = "rankingnews_list"로 선언되어 랭킹 뉴스들이 li 태그로 하나 하나 입력되어 있는 것을 볼 수 있다.
# 6-2) 랭킹 뉴스 정보 추출
ul = div[index_div].find_all('ul', {'class', 'rankingnews_list'})
for index_r in range(0, len(ul)):
li = ul[index_r].find_all('li')
for index_l in range(0, len(li)):
try: # 예외처리
# 순위
rank = li[index_l].find('em', {'class','list_ranking_num'}).text
# 뉴스 제목
title= li[index_l].find('a').text
# 뉴스 링크
link = li[index_l].find('a').attrs['href']
# 7) dataframe 저장(append)
data = data.append({'언론사명':press,
'순위':rank,
'기사제목':title,
'기사링크':link,
'수집일자':datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')}, ignore_index=True)
except:
pass
print('Complets of ' + rank + ' : ', title)
print('----------------------------------------')
print(data)🔼 해서 for문을 사용해 ul 태그 안에 li 태그들을 하나하나 불러온다.
그 후 또 for문과 try를 이용하여 li 태그 속 순위, 뉴스 제목, 뉴스 링크를 데이터 프레임에 append한다.
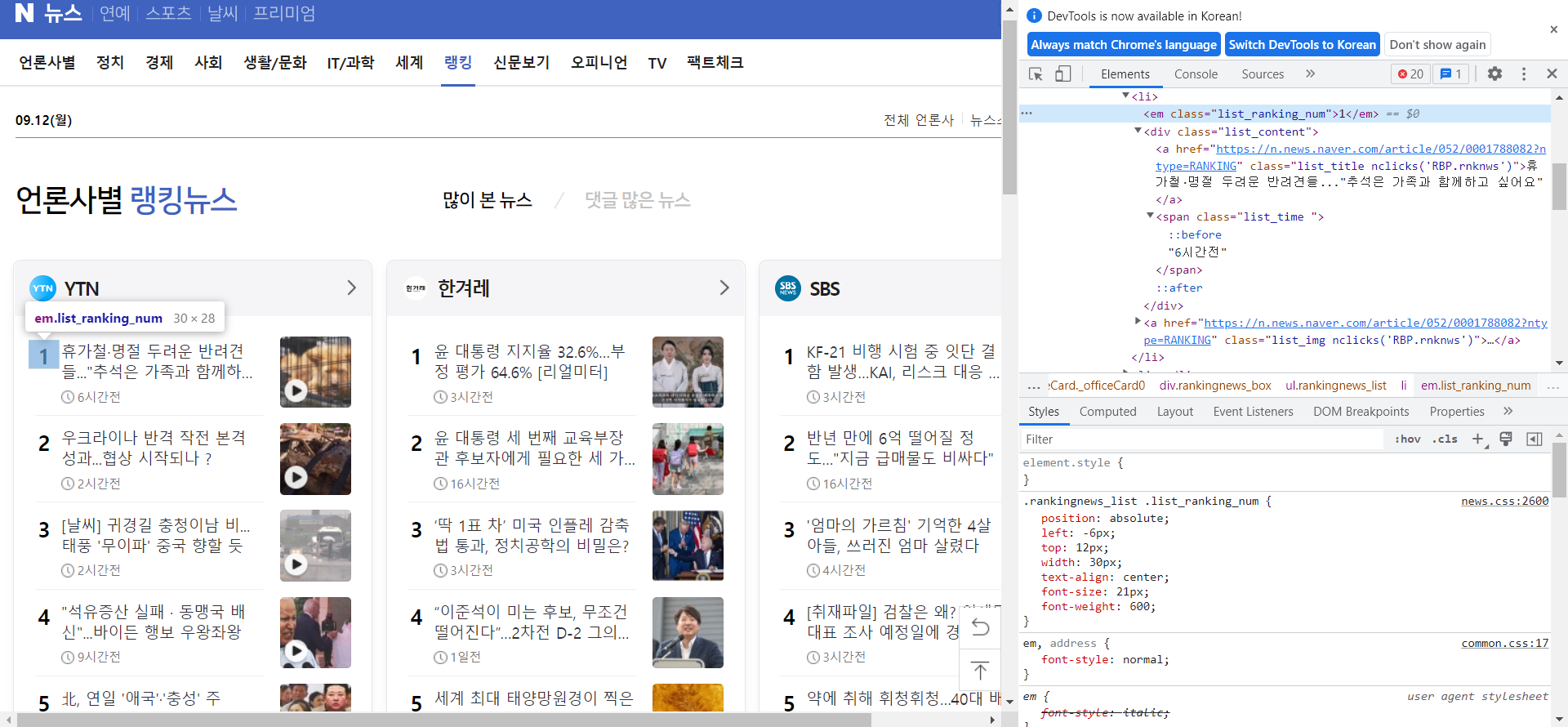
🔼 이를 보면 순위는 <em class="list_ranking_num">1</em>,
기사 제목과 링크는
<a href="https://n.news.naver.com/article/052/0001788082?ntype=RANKING" class="list_title nclicks('RBP.rnknws')">휴가철·명절 두려운 반려견들..."추석은 가족과 함께하고 싶어요"</a>
(a 태그 안에 같이 있지만 링크는 href로 선언되어있어서 attrs['href']로 추출하고 제목은 텍스트므로 .text로 추출)
수집일자는 위에서 임포트한 라이브러리를 활용하여 현재시간을 한국시간으로 변환하여 출력.
data.to_csv('네이버랭킹뉴스_많이본뉴스_크롤링_20220901.csv', encoding='utf-8-sig', index=False)🔼 크롤링한 데이터는 저장!!
day_df = pd.read_csv('/content/네이버랭킹뉴스_많이본뉴스_크롤링_20220901.csv')🔼 그 후 데이터 프레임 형식으로 불러온다.
day_df['기사제목'].replace('[^\w]', ' ', regex=True, inplace=True)🔼 그 다음에는 기사제목에 있는 특수부호들을 없애기 위한 전처리를 해준다.
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator🔼 워드클라우드를 위한 라이브러리 임포트.
코랩은 한글 깨짐 방지 코드도 실행시켜주어야 함!!
# wordCloud 라이드버리에서는 하나의 문자열로 제공해야함
# 391의 기사제목을 하나의 text로 데이터 전처리
day_text = " ".join(li for li in day_df.기사제목.astype(str))
day_text🔼 워드클라우드를 위한 데이터 전처리
plt.subplots(figsize=(25,15))
wordcloud = WordCloud(background_color='white', width=1000, height=700, font_path=fontpath).generate(day_text)
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()🔼 워드클라우드를 실행시키면!

🔼 이런 결과가 나온다. 이는 9월 12일자 기준으로 크롤링된 데이터를 가지고 한 워드 클라우드이다.
✅ 댓글 많은 뉴스
댓글 많은 뉴스도 링크만 수정하고 코드는 위와 동일하게 하면 된다.
(링크:https://news.naver.com/main/ranking/popularMemo.naver)
data.to_csv('네이버랭킹뉴스_댓글많은뉴스_크롤링_20220901.csv', encoding='utf-8-sig', index=False)
memo_df = pd.read_csv('/content/네이버랭킹뉴스_댓글많은뉴스_크롤링_20220901.csv')🔼 데이터 저장 후 데이터를 불러온 다음
import re
def clean_text(inputString):
text_rmv = re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', ' ', inputString)
return text_rmv
# text 붙이면서 데이터 전처리
memo_text = " ".join(clean_text(li) for li in memo_df.기사제목.astype(str)) # df.기사제목 = df['기사제목']많이 본 뉴스와 다른 방식으로 데이터 전처리. re라는 것을 임포트 한 후 특수기호를 삭제하는 함수를 선언한다. 그후 join을 이용해 텍스트를 붙일 때 데이터 전처리까지 한번에 하는 방식.
그 후 워드 클라우드를 해주면(코드는 위와 동일하다)

🔼 이런 결과가 나온다(이 역시 9월 12일자 랭킹뉴스 기준 시각화)
