📌 전국 의료 기관 데이터 분석
✅ 라이브러리 임포트 및 데이터 준비하기
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
df = pd.read_csv('/content/data.csv', encoding='EUC-KR')
# NaN 데이터 확인하기
df.isna().sum() -> 소재지전화, 의료기관종별명, 의료인수, 입원실수, 병상수, 진료과목내용명
# 컬럼별 데이터 확인 -> df.컬럼명.unique()✅ 데이터 분석하기
# 상세영업상태명 별 의료 기관 수
df['상세영업상태명'].value_counts()
gb_df = df.groupby(by=['상세영업상태명']).size().reset_index(name='의료기관수')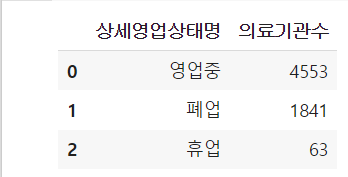
🔼 gb_df 입력해 출력해보면 이렇게 데이터프레임형식으로 나타난다.
# 영업상태별 의료기관수 확인
px.histogram(gb_df, x='상세영업상태명', y='의료기관수')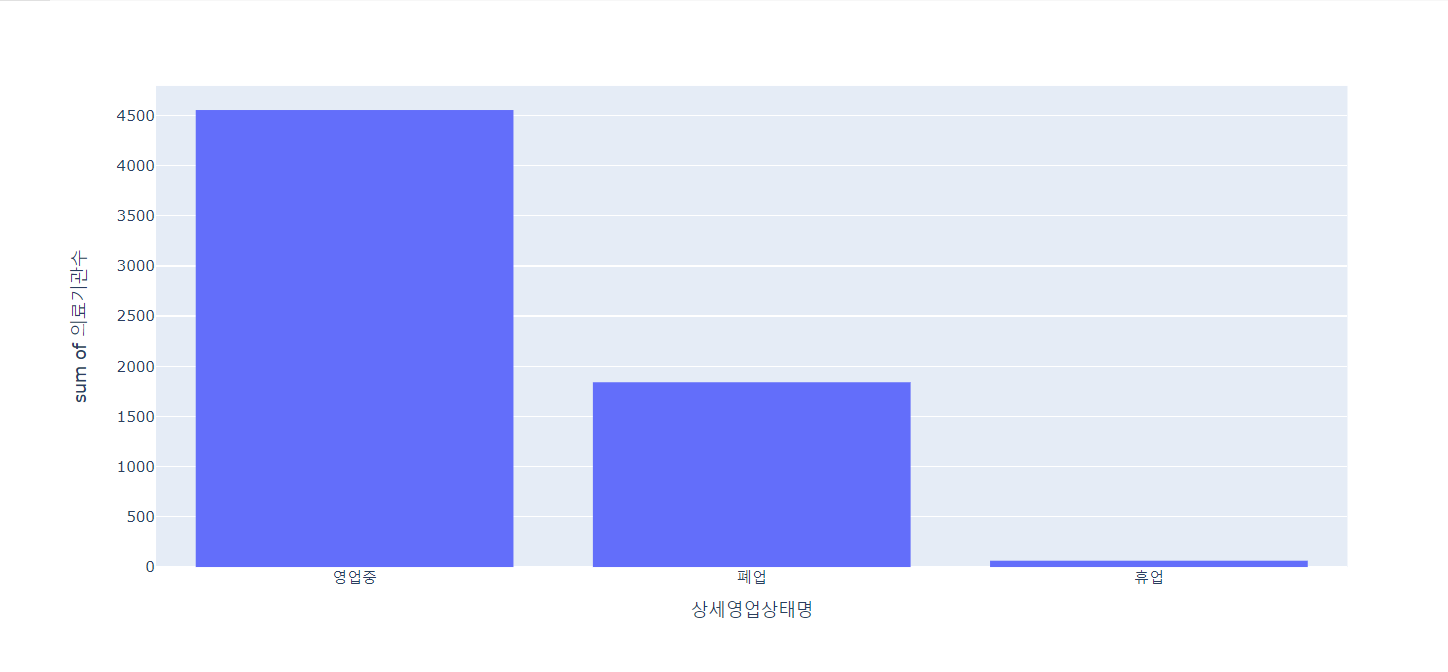
🔼 결과
# 파이차트
px.pie(gb_df, names='상세영업상태명', values='의료기관수')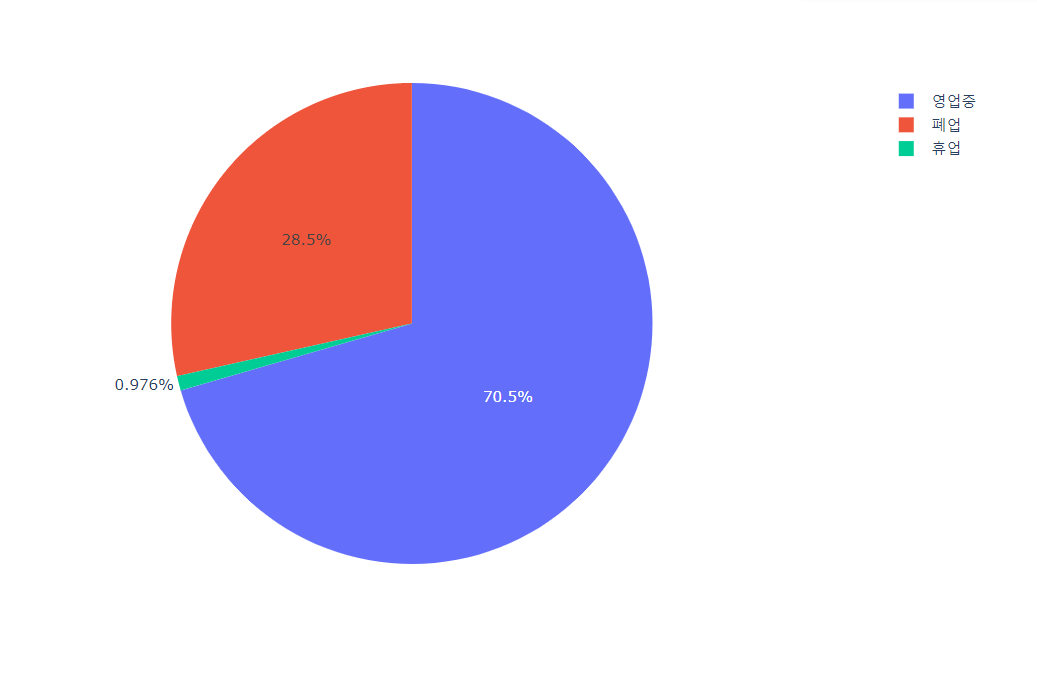
🔼 결과
# 지역명 별 의료 기관 수
df['지역명'].value_counts()
lgb_df = df.groupby(by=['지역명', '도시명', '상세영업상태명', '의료기관종별명']).size().reset_index(name='의료기관수')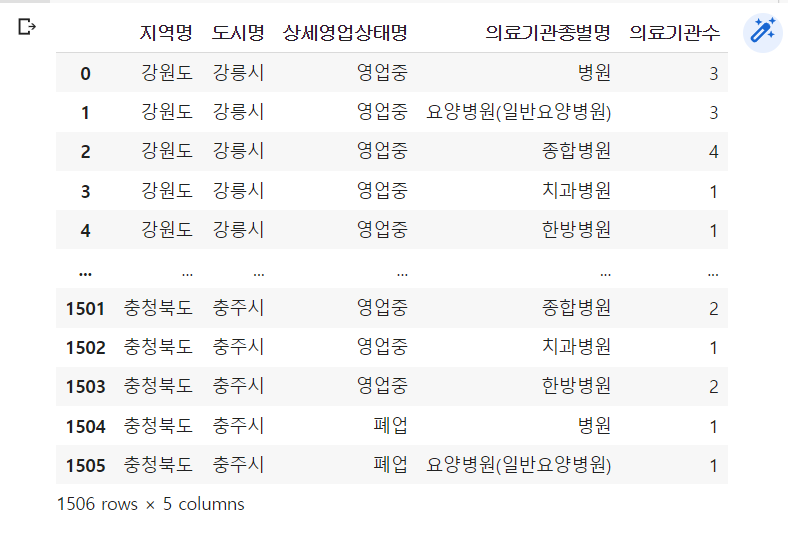
이 역시 변수명을 입력하여 출력할시 데이터프레임형태로 되어있는 것을 확인할 수 있다.
# 지역별 의료기관수 현황
px.histogram(lgb_df, x='지역명', y='의료기관수')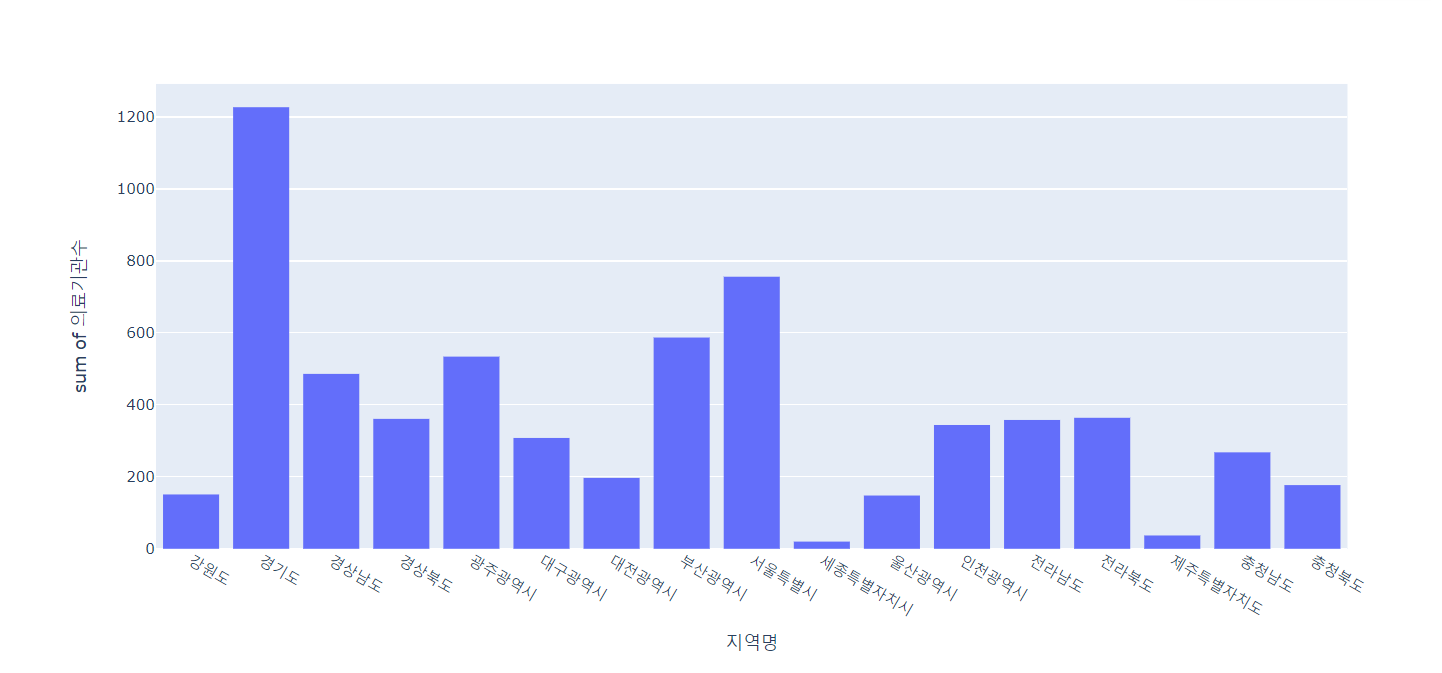
🔼 결과
# 지역에 따른 영업상태별 의료기관 수 확인
px.histogram(lgb_df, x='지역명', y='의료기관수', color='상세영업상태명')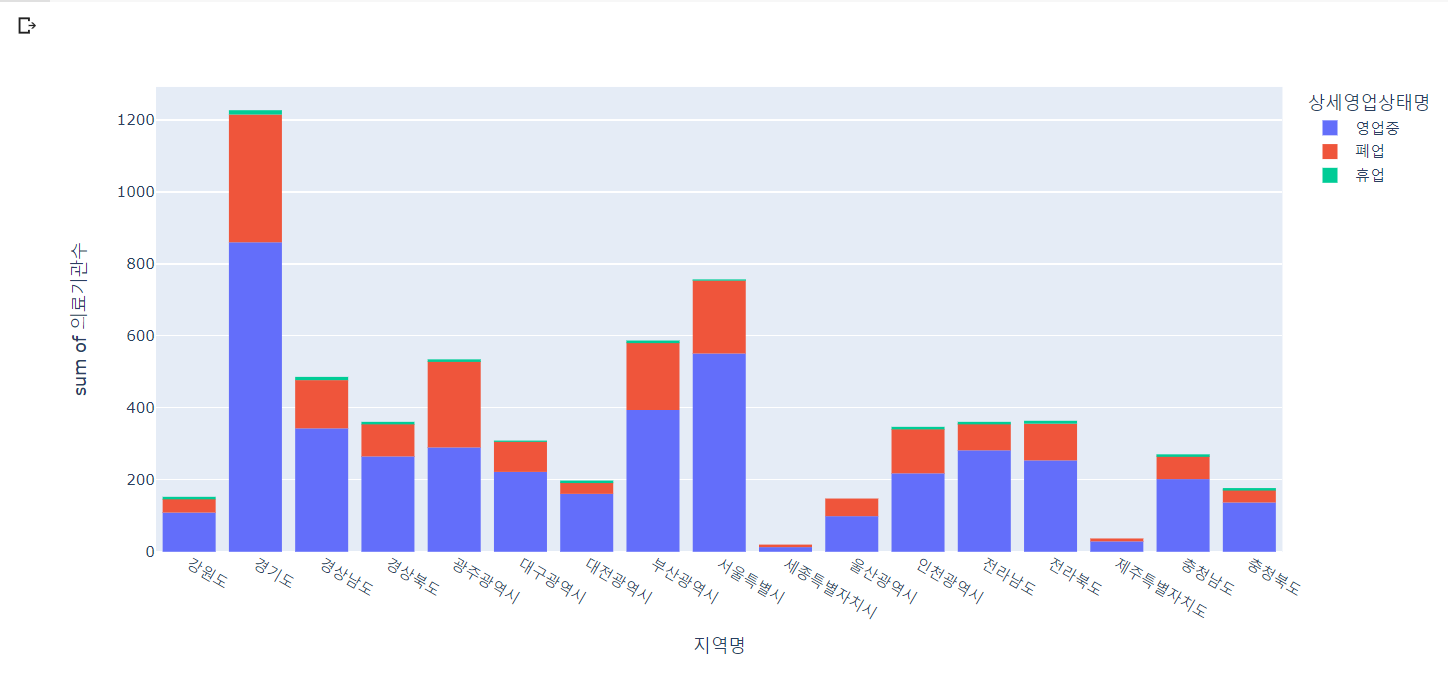
🔼 결과
# 지역에 따른 시군구별 의료기관 수 확인
px.histogram(lgb_df, x='지역명', y='의료기관수', color='도시명')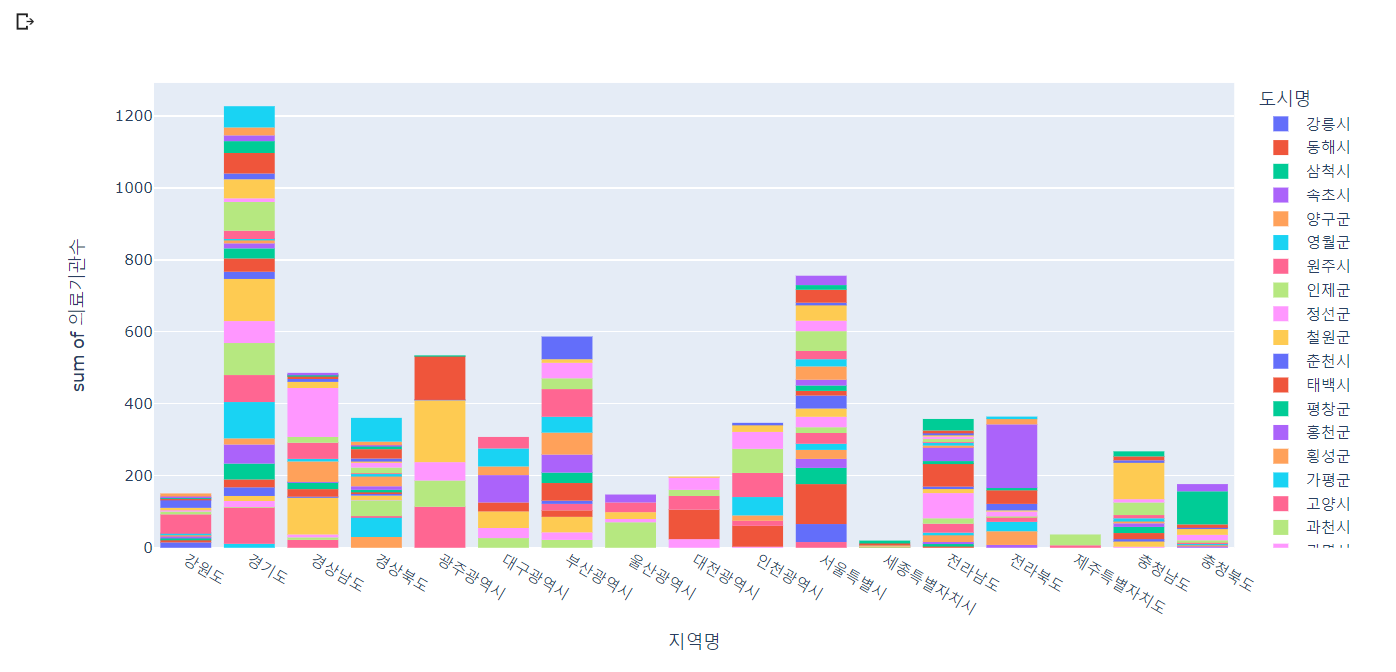
🔼 결과
# 지역에 따른 의료기관종류별 의료기관 수 확인
px.histogram(lgb_df, x='지역명', y='의료기관수', color='의료기관종별명')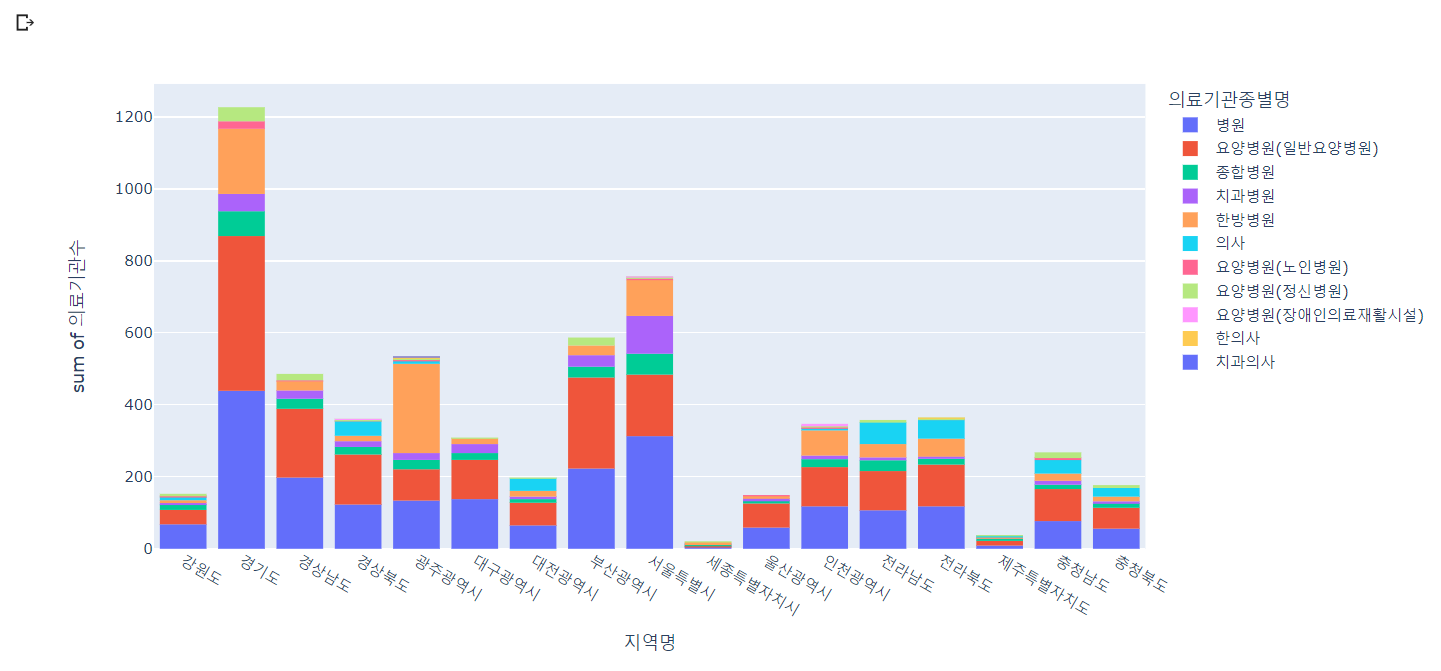
🔼 결과
# 지역별 의료기관수 확인하는 파이 차트
px.pie(lgb_df, names='지역명', values='의료기관수')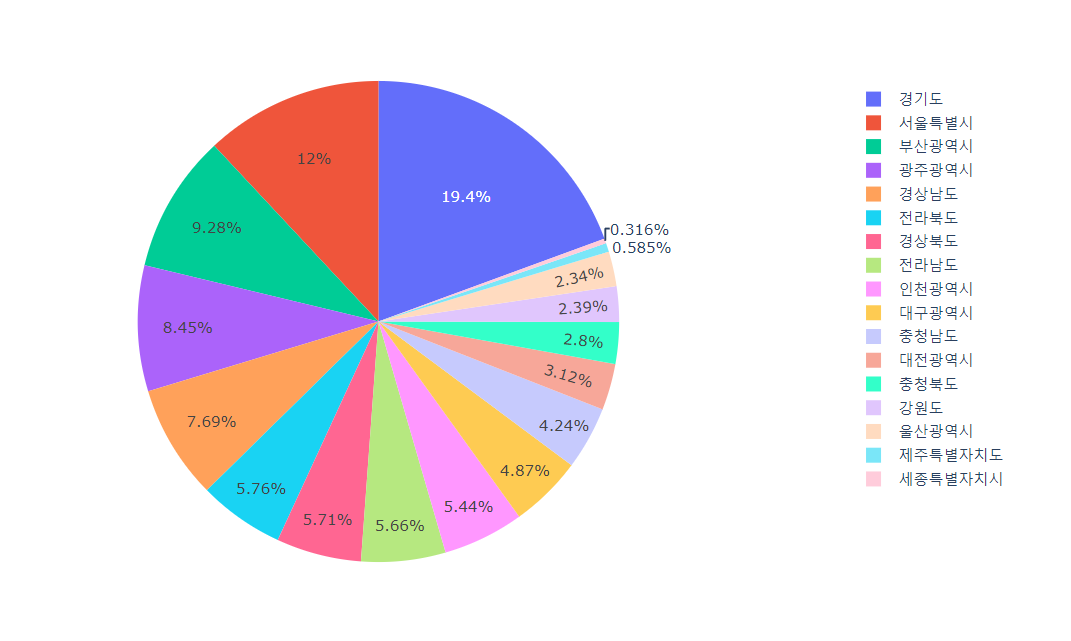
🔼 결과
# 의료기관종별 의료기관수 현황
px.histogram(lgb_df, x='의료기관종별명', y='의료기관수')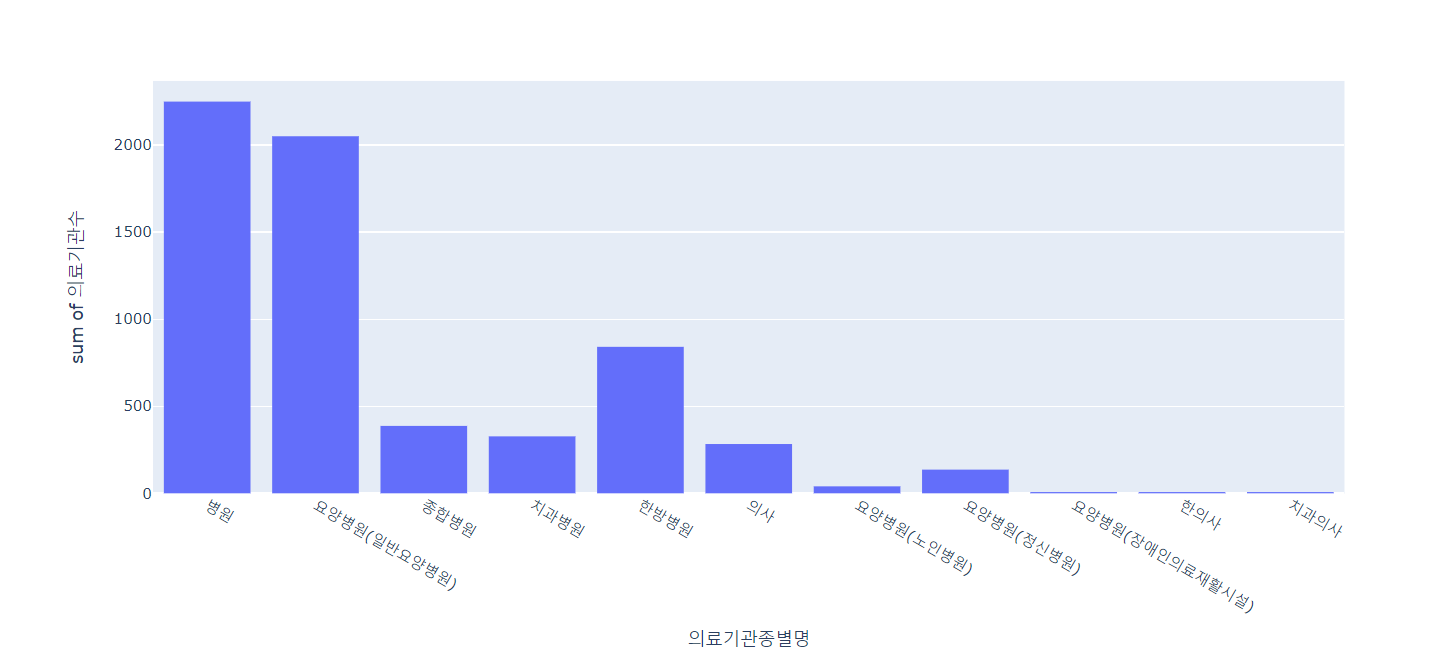
🔼 결과
# 의료기관종별 의료기관수 확인하는 파이 차트
px.pie(lgb_df, names='의료기관종별명', values='의료기관수')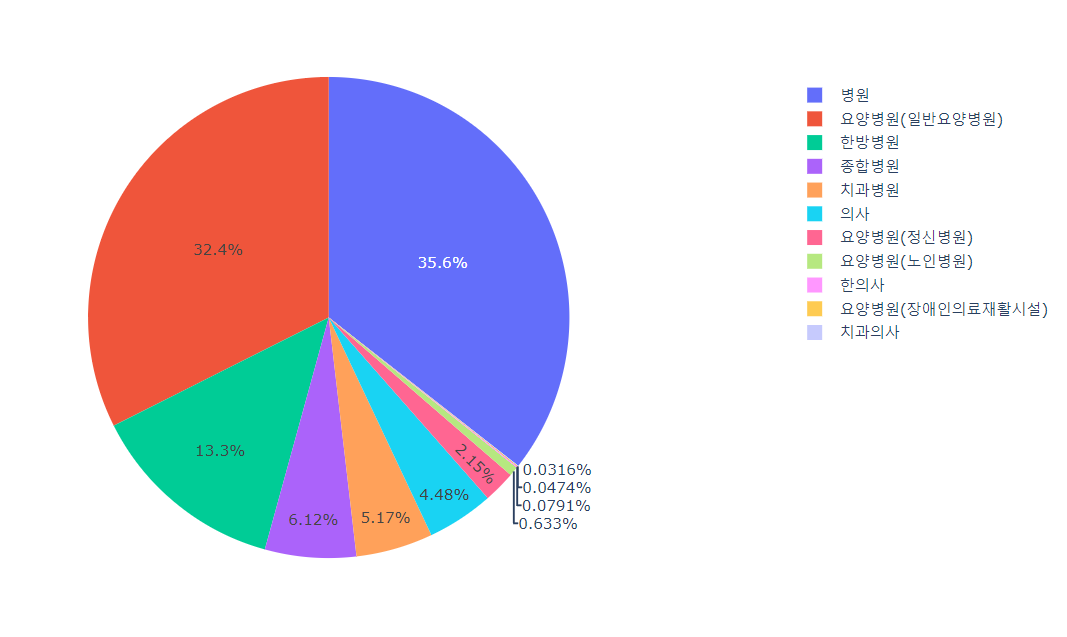
🔼 결과
✅ 워드 클라우드 시각화
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 진료과목명을 하나의 text 형태로 변환
text = " ".join(cont for cont in df.진료과목내용명.astype(str))🔼 워드 클라우드 시각화를 위한 전처리 과정
(진료과목내용명으로 워드 클라우드 시각화)
plt.subplots(figsize=(25, 15))
wordcloud = WordCloud(background_color='black', width=1000, height=700, font_path=fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
위와 같은 결과가 나온다.
✅ 내 위치와 가장 가까운 의료기관 찾기
✏️ 단 영업중인 병원만 검색되도록 하기
✏️ 내 위치는 도로명 주소로 입력 받고 가장 가까운 의료기관은 5개만 추출하여 지도 시각화
✏️ 내 위치 마커와 병원 마커를 표시하고 병원 마커를 클릭하면 병원명이 나오도록
✔️ 라이브러리 임포트 및 데이터 준비하기
# 1) 라이브러리 임포트
import folium
import pandas as pd
# 2) 파일 업로드
df = pd.read_csv('/content/drive/MyDrive/data.csv', encoding='EUC-KR')
# NaN 데이터 확인하기
# df.isna().sum()✔️ 내 위치 주소를 입력하고 가까운 병원 5개만 추출하여 저장하기
# 3) 주소를 좌표로 변환할 함수 준비
from geopy.geocoders import Nominatim
def geocoding(address):
geolocoder = Nominatim(user_agent = 'South Korea', timeout=None)
geo = geolocoder.geocode(address)
crd = {"lat":float(geo.latitude), "lng":float(geo.longitude)}
return crd
# 4) 사용자에게 주소를 입력받기
address = input("당신의 주소를 입력하시오.")
crd = geocoding(address)
# 5) 주소 좌표로 변환하여 tuple 형태로 변수에 담기
from geopy.distance import geodesic
myhome = folium.Map(location=[crd['lat'],crd['lng']], zoom_start=14)
# 6) 병원데이터 dataframe에 거리 계산하여 담기
hpt = pd.DataFrame(columns=['사업장명', '도시명', '의료기관종별명', '상세영업상태명', '위도', '경도', '거리'])
myhome = (crd['lat'], crd['lng'])
adr_s = address.split(' ')[0]
df = df.loc[df.지역명.str.contains(adr_s)]
for n in df.index:
hpt_loc = (df.loc[n, '위도'], df.loc[n, '경도']) # tuple 형태
# hpt dataframe에 담기
hpt.loc[n] = [df.loc[n, '사업장명'],
df.loc[n, '도시명'],
df.loc[n, '의료기관종별명'],
df.loc[n, '상세영업상태명'],
df.loc[n, '위도'], df.loc[n, '경도'],
geodesic(myhome, hpt_loc).kilometers]
# 7) 내 위치에 가장 가까운 영업중인 병원 5개 뽑기
my_hpt = hpt.loc[hpt['상세영업상태명'] == '영업중']
my_hpt = my_hpt.sort_values(by=['거리']).head(5)✔️ 지도 시각화
# 8) 지도 준비
my_map = folium.Map(location=[crd['lat'], crd['lng']], zoom_start=14)
for n in my_hpt.index:
folium.Marker([my_hpt.loc[n, '위도'], my_hpt.loc[n, '경도']],
popup='<pre>'+my_hpt.loc[n, '사업장명']+'</pre>',
icon=folium.Icon(icon='hospital-o', prefix='fa')).add_to(my_map)
folium.Marker([crd['lat'], crd['lng']], icon=folium.Icon(color='red', icon='glyphicon glyphicon-home')).add_to(my_map)
my_map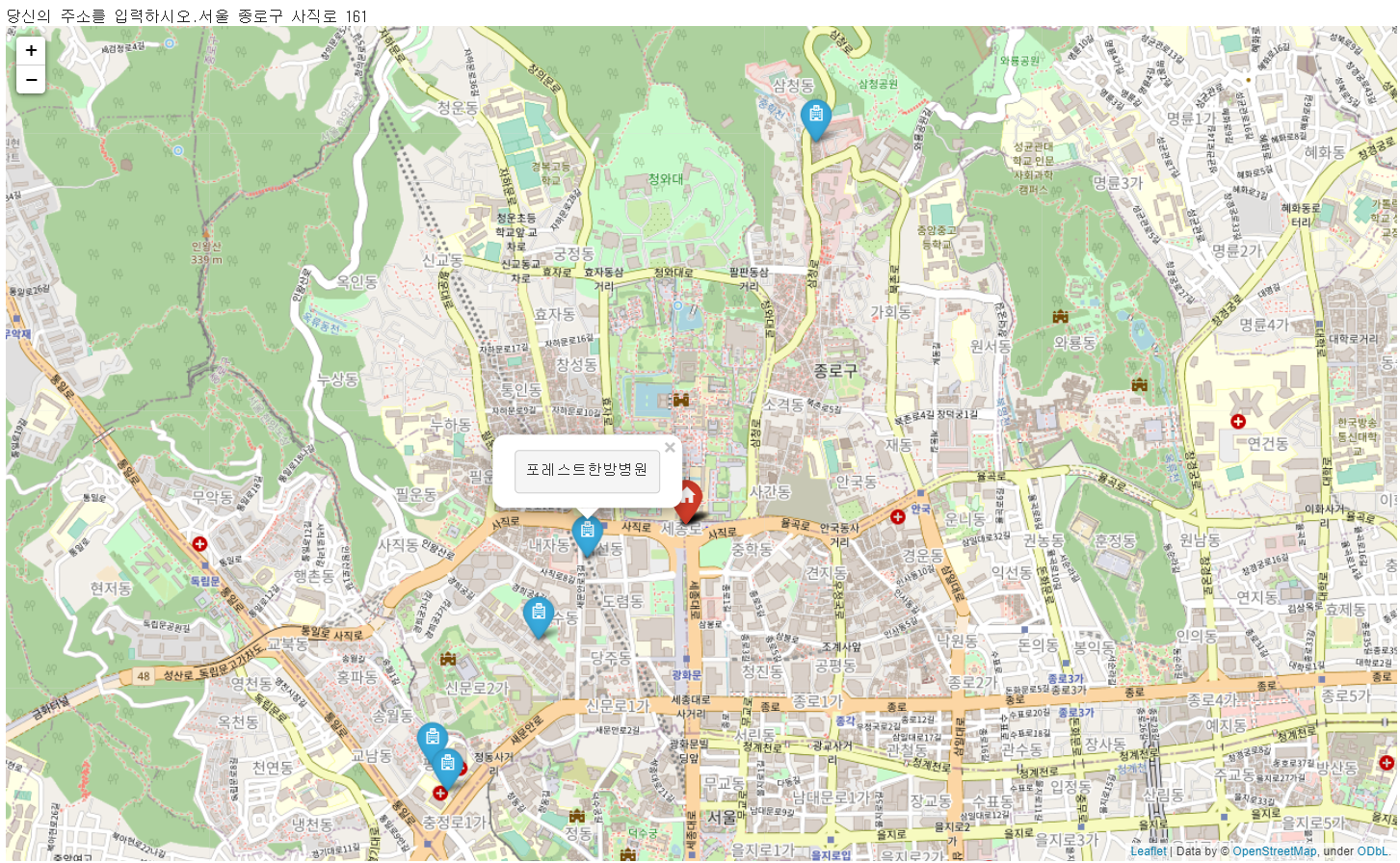
🔼 지도 시각화 결과
📌 네이버 공감뉴스 크롤링
#이 부분은 처음 한번만 실행하면 됨
!pip install selenium
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin셀레니움 라이브러리 사용을 위한 설치
# 1) 라이브러리 임포트
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time
from pytz import timezone
import datetime
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 2) 데이터 프레임 생성
data = pd.DataFrame(columns=['순위', '공감종류', '기사제목', '기사링크', '기사내용', '공감수', '수집일자'])
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headless -> 창을 띄우지 않고 가상으로 진행하는 것
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage') # deb/shm 디렉토리 사용X
driver = webdriver.Chrome('chromedriver', options=options)
url_list = ['https://entertain.naver.com/ranking/sympathy/love',
'https://entertain.naver.com/ranking/sympathy/cheer',
'https://entertain.naver.com/ranking/sympathy/congrats',
'https://entertain.naver.com/ranking/sympathy/expect',
'https://entertain.naver.com/ranking/sympathy/surprise',
'https://entertain.naver.com/ranking/sympathy/sad']
# https://entertain.naver.com/ranking/sympathy/cheer
# https://entertain.naver.com/ranking/sympathy/congrats
# https://entertain.naver.com/ranking/sympathy/expect
# https://entertain.naver.com/ranking/sympathy/surprise
# https://entertain.naver.com/ranking/sympathy/sad
for i in range(len(url_list)):
driver.get(url_list[i])
driver.implicitly_wait(3)
time.sleep(1.5)
driver.execute_script('window.scrollTo(0,800)')
time.sleep(3)
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
li = soup.select('li._inc_news_lst3_rank_reply') #ul.news_lst news_lst3 count_info > li
# 공감종류
sym = url_list[i].split('.')[2].split('/')[3]
for index_l in range(0, len(li)):
try:
# 순위
rank = li[index_l].find('em', {'class', 'blind'}).text.replace('\n', '').replace('\t', '').strip()
# 뉴스 제목
title = li[index_l].find('a', {'class', 'tit'}).text.replace('\n', '').replace('\t', '').strip()
# 뉴스 내용
summary = li[index_l].find('p', {'class', 'summary'}).text.replace('\n', '').replace('\t', '').strip()
# 뉴스 링크
link = li[index_l].find('a').attrs['href']
# 공감수
sym_s = li[index_l].find('a', {'class', 'likeitnews_item_likeit cheer'}).text.replace('\n','').replace('\t','').strip().split('수')[1]
# dataframe에 저장 (append)
data = data.append({'순위' : rank,
'공감종류' : sym,
'기사제목' : title,
'기사링크' : 'http://entertain.naver.com' + link,
'기사내용' : summary,
'공감수' : sym_s,
'수집일자' : datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')}, ignore_index=True)
except:
pass
print('Complets of ' + rank + ' : ' + title)
print('---------------------------------')
print(data)코드는 이렇게 짜봤었는데 사실 이렇게 하면 안된다!!!!!
print('Complets of ' + rank + ' : ' + title)
요 부분은 잘 출력되는데 데이터 append 과정에서 문제가 있는듯하다..
cheer만 데이터 프레임에 저장됨
글서 일단은 걍 포기하겟습니당👍
