count(*) 쿼리 성능 개선
select 절에 * 는 모든 컬럼을 가지고 오기 때문에 성능 문제가 발생한다
따라서 불필요한 자원을 낭비하는 것
-
count(*): 단순 행을 세는 역할을 한다
(Mysql 내부적으로 데이터를 읽지않고 행의 갯수를 흝고 지나간다는 것) -
count(컬럼): 행의 값을 세는 역할을 한다 (데이터를 읽는 것)
1. PRIMARY KEY가 가장 빠른 인덱스
- 만약 where 절이 있는 5만건의 데이터를 count로 가져오는 경우 5만건을 모두 수행하게 된다
PRIMARY KEY 말고 인덱스가 하나도 없어도 적용할 인덱스가 없기 때문에 여전히 느립니다.
select count(*)
from t_like
where post_id = 1;- count(PK 컬럼)
select count(like_id)
from t_like
where post_id = 1;속도 : count(distinct(컬럼)) < count(컬럼) < count(*) 순서
-
불필요한 데이터를 셀 필요없이 행의 갯수만 얻고 싶다면 * 를 쓰는것이 빠르다
-
COUNT를 하려는 테이블의 총 로우 개수가 100개 미만이라면 COUNT가 더 빠르다.
100개 이상이면 sysindexes이 더 빠르다
(COUNT 키워드를 실행하게 되면 table scan
대체 쿼리에서는 해당 rows값을 가져오기 때문에 더 빠르다.) -
따로 count index 컬럼을 만들어서 사용하는 방법도 있습니다
ex)
SELECT rows FROM sysindexes WHERE id = OBJECT_ID('TestTable') AND indid < 2;쿼리 성능 측정
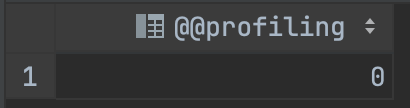
1. profiling 옵션 확인
SELECT @@profiling;- 0이면 off 1이면 on
2. profiling 활성화
SET profiling=1;- 쿼리 실행 후 다시 확인하면 1로 변경된다
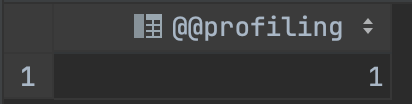
3. 성능 측정
- 성능 측정할 쿼리를 날린다
select count(like_id)
from t_like
where post_id = 1;- SHOW profiles로 확인
SHOW profiles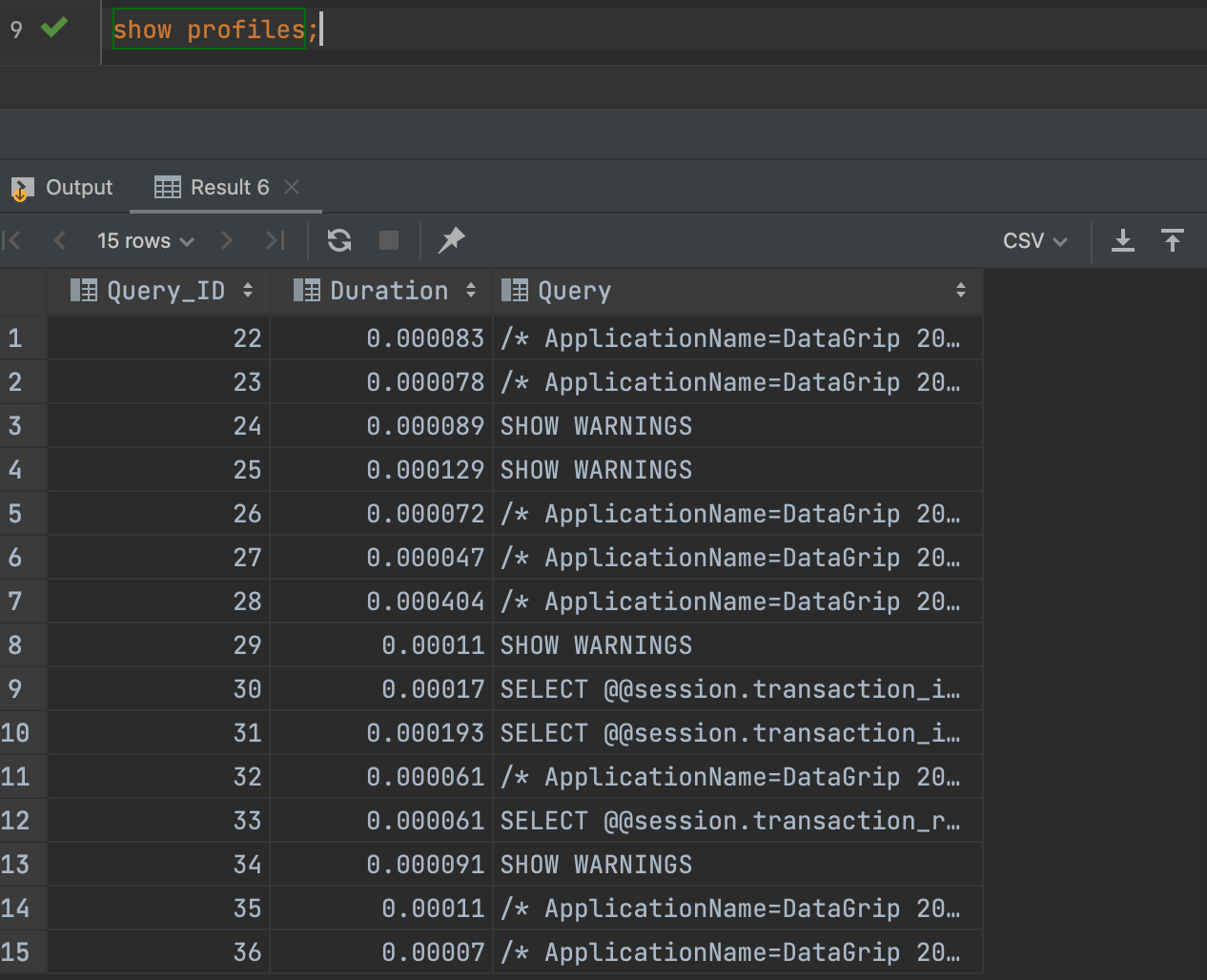


측정 결과 count(*)가 더 빠르다
3. 쿼리 성능 상세 조회
- SHOW profiles로 확인하는 경우 쿼리문 1개에 대한 성능 전체 내용이 나온다
만약 sql문을 블록 단위로 쪼갠 상세 정보를 얻고 싶다면 쿼리 아이디로 조회 할 수 있다
SHOW profile FOR QUERY 22;- cpu 사용량 체크
SHOW profile CPU FOR QUERY 22;📌 profile을 통해 조회할 수 있는 목록

참고 블로그
- https://m.blog.naver.com/birdparang/221574304831
- https://yjh5369.tistory.com/entry/MySQL-COUNT%EC%9D%98-%EC%9E%98%EB%AA%BB%EB%90%9C-%EC%9D%B8%EC%8B%9D%EA%B3%BC-%EC%86%8D%EB%8F%84-%EC%B0%A8%EC%9D%B4
- sysindexes: https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sqlpro&logNo=90163761135
- sql 속도 개선 : https://velog.io/@myong/Query-%EC%86%8D%EB%8F%84%EB%A5%BC-%EC%98%AC%EB%A6%AC%EB%8A%94-%EC%B2%B4%ED%81%AC%EB%A6%AC%EC%8A%A4%ED%8A%B8-7

하루 일지 보단 행동 고찰 과정에 대한 개발 블로그