검색엔진에서 가장 일반적으로 사용되는 스코어 알고리즘에는 TF-IDF와 BM25가 있다.
루씬의 기본 알고리즘이 TF/IDF에서 BM25로 바뀌면서 Elasticsearch 또한 5.0버전 이후부터 _score 계산하는 기본 유사도 알고리즘도 BM25로 바뀌었다.
BM25가 검색의 정확도가 더 정교하다지만 각자 서비스하는 시스템에 따라 두 알고리즘의 차이점을 알고 적합한 알고리즘을 선택하는 것이 좋다. 때문에 두개의 유사도 알고리즘을 정리해본다.
TF/IDF
점수 계산은 단어가 얼마나 반복되는지와 얼마나 자주 사용되는 단어인지가 점수에 영향을 미친다. 하나의 문서에서 단어가 여러번 반복되면 관련성은 높아지지만 전체 문서에서 단어가 자주 반복된다면 오히려 관련성은 낮아지게 된다. 이를 TF/IDF라고 한다.
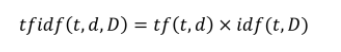
1. TF (Term Frequency)

- 텀(
term)이 문서에 등장하는 횟수로, 빈도수가 높을수록 문서의 검색 점수는 높아진다. - 즉, 문서내에 같은 단어가 여러번 등장하면 그 단어에 가중치를 주는 알고리즘이다.
2. IDF (Inverse Document Frequency)
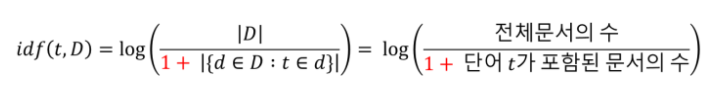
DF(특정 단어 t가 등장한 문서의 수)의 역수, 즉 DF에 반비례하는 수를 뜻한다.- 전체 문서에서 등장하는 텀(
term)의 빈도수가 작을수록 문서의 검색 점수는 높아진다. 즉, 여러 문서에 등장할수록 낮은 가중치를 주는 알고리즘이다. - 총 문서의 수 N이 커지면 커질 수록 값이 너무 커져버리기 때문에 log를 사용한 것이다.
- 특정 단어가 전체의 문서 안에 존재하지 않을 경우, 분모가 0이 되어버리는 상황이 발생한다. 이를 방지 하기 위해 분모에 1을 더해주는 것이 일반적이다.
예)
the,a,is와 같이 항상 등장하는 텀(term)은 실제로 큰 의미를 가지지 않음으로 검색 결과에 영향을 미치지 않도록 하기 위함이다. (🖍 불용어stop word라고 한다. )
3. Field-Length Norm
짧은 필드에 나타나는 텀(term)은 긴 필드에 나타나는 동일한 텀(term)보다 더 많은 가중치를 가진다. 즉, 문서 길이에 따른 가중치 이다.
BM25
BM25는 TF-IDF의 variation(변형)이다. TF와 IDF를 곱해준다는 시스템은 같지만 보정 파라미터들을 조금 추가해서 성능을 개선한 알고리즘이다.
- Q: 사용자가 입력한 쿼리
- D: 대조해보려는 문서
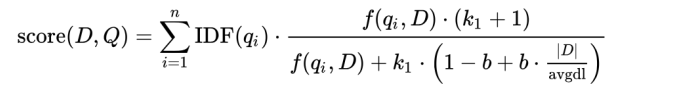
TF 계산
- freq: 문서에 매칭된 키워드 수
- k1: term saturation parameter (default: 1.2)
- b: (default: 0.75)
- dl: 실제 문서가 검색된 문서의 길이
- avgdl: 평균 필드의 길이
freq / (freq + k1 * (1 - b + b * dl / avgdl))IDF 계산
- n: 문서에 나타난 키워드 수
- N: 전체 문서의 수
log(1 + (N - n + 0.5) / (n + 0.5))왜 BM25가 더 나은가?
1. TF의 영향이 줄어든다.
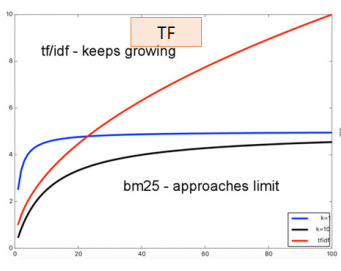
TF에서는 단어 빈도가 높아질수록 검색 점수도 지속적으로 높아지는 반면, BM25에서는 특정 값으로 수렴한다.
2. IDF의 영향이 커진다.
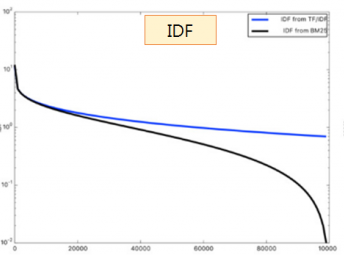
BM25에서는 DF가 높아지면 검색 점수가 0으로 급격히 수렴하므로, 불용어가 검색 점수에 영향을 덜 미친다.
3. 문서 길이의 영향이 줄어든다.
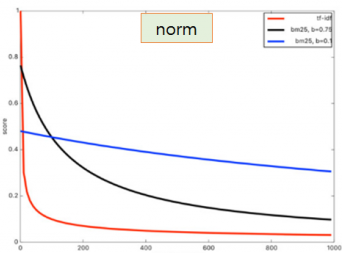
BM25에서는 문서의 평균 길이(avgdl)를 계산에 사용하며, 문서의 길이가 검색 점수에 영향을 덜 미친다.
4. Elasticsearch가 그렇게 하기 때문이다
Improved Text Scoring with BM25 참조
엘라스틱서치에서 지원하는 유사도 알고리즘
- BM25 (default)
- DFR
- DFI
- IB
- LM Dirichlet
- LM Jelinek Mercer
유사도 알고리즘의 자세한 사항은 similarity module에서 확인해보자.


좋은글 감사합니다!