
GPU 병렬 연산: Warp Divergence 이해하고 해결하기
GPU 프로그래밍을 하다 보면 성능 최적화에서 자주 마주치는 개념이 바로 Warp Divergence입니다. 특히 셰이더 프로그래밍에서 이를 이해하고 적절히 대응하는 것은 성능에 큰 영향을 미칩니다. 이번 글에서는 Warp의 개념부터 Divergence가 발생하는 상황, 그리고 이를 해결하는 베스트 프랙티스까지 알아보겠습니다.
Warp란 무엇인가
GPU는 SIMT(Single Instruction, Multiple Threads) 아키텍처를 사용합니다. 이는 여러 스레드가 동일한 명령어를 동시에 실행하는 구조를 의미합니다.
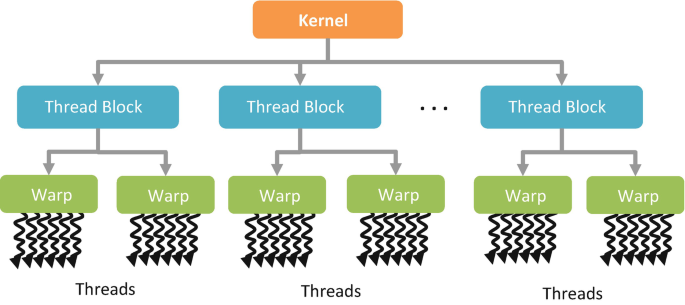
주요 GPU 아키텍처의 Warp 크기
- NVIDIA GPU: 32개의 스레드가 하나의 그룹으로 묶여 실행되며, 이를 Warp라고 부릅니다
- 최신 Ada Lovelace 아키텍처(RTX 40 시리즈)에서는 Thread Divergence 처리 성능이 개선되었습니다
- AMD GPU: 64개의 스레드가 하나의 그룹으로 묶이며, 이를 Wavefront라고 합니다
- Intel Arc GPU: EU(Execution Unit)당 다른 스레드 구성을 가지며, SIMD 실행 모델이 NVIDIA 및 AMD와 다릅니다
Warp 내의 모든 스레드는 같은 명령어를 동시에 실행하는 것이 가장 효율적입니다. 이러한 병렬 처리 방식 덕분에 GPU는 방대한 양의 데이터를 빠르게 처리할 수 있습니다.
Warp Divergence의 정체
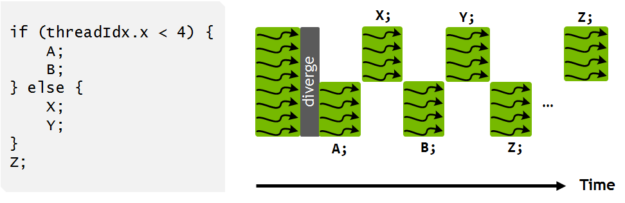
Warp Divergence는 같은 Warp 내의 스레드들이 서로 다른 실행 경로를 따라갈 때 발생합니다. 가장 흔한 예는 조건문에서 일부 스레드는 if 블록을 실행하고, 다른 스레드는 else 블록을 실행하는 경우입니다.
다음 GLSL 셰이더 코드를 살펴보겠습니다.
if (gl_GlobalInvocationID.x % 2 == 0) {
// 짝수 스레드: 경로 A
result = computeA();
} else {
// 홀수 스레드: 경로 B
result = computeB();
}이 경우 GPU는 다음과 같이 동작합니다. 먼저 Warp 내 짝수 스레드들이 computeA()를 실행하는 동안 홀수 스레드들은 대기합니다. 그 다음 홀수 스레드들이 computeB()를 실행하는 동안 짝수 스레드들은 대기합니다. 결과적으로 실행 시간이 두 경로의 합이 되어 성능이 저하됩니다.
최악의 경우 성능이 2배 가까이 느려질 수 있습니다.
Divergence가 발생하는 주요 상황
조건부 분기
스레드 ID를 기반으로 한 분기는 Warp Divergence를 일으키는 전형적인 사례입니다. 예를 들어, 스레드 ID가 16보다 작으면 처리 A를 수행하고, 그렇지 않으면 처리 B를 수행하는 코드는 Warp 내에서 스레드들이 서로 다른 경로를 따르게 만듭니다.
// 나쁜 예: 스레드 ID 기반 분기
if (threadID < 16) {
// 처리 A
} else {
// 처리 B
}루프의 불균등한 반복
각 스레드가 서로 다른 횟수만큼 루프를 반복하는 경우도 문제가 됩니다. 스레드마다 다른 반복 횟수를 가진 루프는 일부 스레드가 먼저 끝나고 나머지를 기다리게 만들어 전체 성능을 저하시킵니다.
// 나쁜 예: 스레드마다 다른 반복 횟수
for (int i = 0; i < threadID; i++) {
doWork();
}동적 배열 인덱싱과 메모리 접근 패턴
스레드마다 다른 메모리 접근 패턴을 가지는 경우도 성능 문제를 일으킵니다. 복잡한 계산을 통해 배열 인덱스를 결정하는 코드는 메모리 coalescing을 방해하여 메모리 접근 효율을 크게 떨어뜨립니다.
이는 Warp Divergence와는 다른 성능 이슈이지만, 종종 함께 발생합니다. Warp 내 스레드들이 연속되지 않은 메모리 주소에 접근하면 여러 번의 메모리 트랜잭션이 필요하게 되어 대역폭이 낭비됩니다.
// 나쁜 예: 스레드마다 다른 메모리 접근 패턴
int index = someComplexCalculation(threadID);
result = data[index];Early Return과 Discard
프래그먼트 셰이더에서 일부 픽셀만 폐기하는 경우도 Divergence를 발생시킵니다. alpha 값에 따라 일부 픽셀은 discard되고 나머지는 계속 처리되는 상황에서, 같은 Warp 내의 스레드들이 서로 다른 경로를 따르게 됩니다.
// 프래그먼트 셰이더에서
if (alpha < 0.1) {
discard; // 일부 픽셀만 폐기
}해결책과 베스트 프랙티스
Unity Shader에서 [branch] 속성 사용하기
Unity에서는 HLSL 셰이더에 [branch] 속성을 추가하여 컴파일러에게 동적 분기를 사용하도록 명시적으로 지시할 수 있습니다. 이는 Warp Divergence를 관리하는 중요한 도구입니다.
// Unity HLSL 셰이더에서
[branch]
if (complexCondition) {
// 비용이 큰 계산
result = expensiveComputation();
} else {
// 간단한 계산
result = simpleValue;
}[branch] 속성을 사용하는 이유는 다음과 같습니다.
첫째, 조건부 계산 비용이 매우 클 때 유용합니다. 한쪽 분기의 계산 비용이 매우 크고 다른 쪽은 매우 간단한 경우, Divergence로 인한 성능 손실보다 불필요한 계산을 건너뛰는 것이 더 이득일 수 있습니다.
둘째, 대부분의 스레드가 같은 경로를 따를 것으로 예상될 때 효과적입니다. 예를 들어 90% 이상의 픽셀이 동일한 분기를 실행한다면, 나머지 10%의 Divergence는 전체 성능에 큰 영향을 미치지 않습니다.
반대로 [flatten] 속성도 있는데, 이는 컴파일러에게 분기를 제거하고 두 경로를 모두 계산한 후 결과를 선택하도록 지시합니다.
[flatten]
if (condition) {
result = valueA;
} else {
result = valueB;
}
// 컴파일러는 이를 다음과 같이 변환
result = condition ? valueA : valueB;[flatten]은 각 분기의 계산 비용이 비슷하고 간단할 때 사용하는 것이 좋습니다. 이 경우 Divergence를 피하기 위해 두 경로를 모두 계산하는 오버헤드가 분기로 인한 손실보다 작습니다.
일반적인 가이드라인은 다음과 같습니다. 분기 내 계산이 매우 간단하면 [flatten]을 사용하고, 계산이 복잡하고 비용이 크면 [branch]를 사용합니다. 확실하지 않은 경우 프로파일링을 통해 실제 성능을 측정하여 결정하는 것이 가장 좋습니다. 유니티 컴파일러는 이 속성들을 어떻게 처리할까?
Unity는 내부적으로 셰이더 컴파일러를 사용하여 HLSL 코드를 GPU가 실행할 수 있는 형태로 변환합니다. [branch]와 [flatten] 속성이 처리되는 과정을 개념적으로 이해해보겠습니다.
1단계: 속성 인식
컴파일러가 셰이더 코드를 읽을 때 [branch]나 [flatten] 같은 특수 키워드를 발견하면, 이를 내부적으로 사용할 상수값으로 변환합니다.
// 개념적 동작
if (속성 이름 == "branch")
→ EatBranch 플래그로 변환
if (속성 이름 == "flatten")
→ EatFlatten 플래그로 변환2단계: if 문에 플래그 저장
컴파일러가 if 문을 만나면, 앞에 어떤 속성이 붙어있는지 확인하고 해당 if 문 데이터에 표시를 남깁니다.
// 개념적 동작
함수: if문에_속성_적용(if문, 속성들):
속성들을 순회:
만약 속성이 EatFlatten이면:
if문.평탄화_가능 = true
만약 속성이 EatBranch이면:
if문.평탄화_금지 = true이는 마치 if 문에 붙이는 포스트잇 같은 역할을 합니다:
[flatten]→ "이 조건문은 평탄화해도 좋아요" 메모[branch]→ "이 조건문은 진짜 분기로 남겨주세요" 메모
3단계: 내부 데이터 구조
if 문을 표현하는 내부 데이터 구조에는 플래그를 저장하는 변수들이 있습니다.
// 개념적 구조
클래스 조건문노드:
변수:
평탄화_가능: 불리언
평탄화_금지: 불리언
메서드:
평탄화_설정() { 평탄화_가능 = true }
평탄화_금지_설정() { 평탄화_금지 = true }각 if 문은 두 개의 스위치를 가지고 있어서, 어떤 최적화 힌트가 주어졌는지 기억합니다.
4단계: GPU 중간 언어로 변환
셰이더를 GPU가 이해할 수 있는 중간 언어(SPIR-V)로 변환할 때, 저장해둔 플래그를 제어 마스크로 변환합니다.
// 개념적 동작
함수: 제어_마스크_변환(if문노드):
만약 if문노드.평탄화_가능 == true:
return 평탄화_마스크
만약 if문노드.평탄화_금지 == true:
return 평탄화금지_마스크
그렇지 않으면:
return 기본_마스크이 과정에서 우리가 붙여둔 "포스트잇"을 GPU가 이해할 수 있는 언어로 번역합니다.
5단계: 실제 GPU 명령어 생성
최종적으로 if 문을 처리할 때 변환된 제어 마스크가 GPU 명령어에 포함됩니다.
// 개념적 동작
제어_정보 = 제어_마스크_변환(현재_if문)
GPU_명령어_생성(조건, 제어_정보, 빌더)제어_정보에 담긴 힌트(Flatten, DontFlatten, 또는 None)가 GPU 드라이버에게 전달됩니다.
결과적으로 어떻게 동작하는가?
전체 흐름을 정리하면:
- 여러분이 셰이더에
[branch]또는[flatten]을 작성 - 컴파일러가 이를 인식하여 내부 플래그로 저장
- GPU 중간 언어로 변환할 때 제어 마스크로 변환
- GPU 드라이버가 이 힌트를 보고 최적화 결정
핵심은 "힌트"라는 점입니다. 이 속성들은 명령이 아니라 제안입니다. GPU 드라이버는 다음과 같은 요소들을 종합적으로 고려합니다:
- 하드웨어 특성 (모바일 GPU vs 데스크탑 GPU)
- 분기 내부 코드의 복잡도
- 레지스터 사용량
- 다른 최적화 기회들
그래서 [flatten]을 붙였는데도 GPU가 "아니, 이 경우엔 분기가 더 나을 것 같은데?"라고 판단하면 평탄화하지 않을 수 있습니다. 반대로 [branch]를 붙였는데도 GPU가 "이건 평탄화하는 게 낫겠어"라고 판단할 수도 있습니다.
따라서 실제 타겟 플랫폼에서 프로파일링하는 것이 필수입니다. 같은 코드라도 Android, iOS, PC, PlayStation에서 각각 다르게 최적화될 수 있기 때문입니다.
조건문을 수학 연산으로 변환하기
가능한 경우 조건문 대신 수학 연산을 사용하는 것이 좋습니다. GPU는 수학 연산을 병렬로 처리하는 데 매우 효율적이므로, 조건문을 수학 함수로 대체하면 Divergence를 완전히 피할 수 있습니다.
예를 들어, 값이 0보다 크면 그대로 사용하고 그렇지 않으면 0을 사용하는 로직은 max 함수로 간단히 대체할 수 있습니다.
// 나쁜 예
float result;
if (value > 0.0) {
result = value;
} else {
result = 0.0;
}
// 좋은 예
float result = max(value, 0.0);또한 boolean을 float로 캐스팅하는 방식으로 조건부 값을 직접 계산할 수 있습니다.
// 나쁜 예
float factor;
if (condition) {
factor = 1.0;
} else {
factor = 0.0;
}
// 좋은 예
float factor = float(condition);균일한 분기 사용하기
Warp 내 모든 스레드가 같은 경로를 따르도록 조건을 설계해야 합니다. 스레드 ID 기반 분기 대신 uniform 변수를 사용한 분기는 모든 스레드가 동일한 경로를 따르므로 Divergence가 발생하지 않습니다.
// 나쁜 예: threadID 기반 분기
if (threadID % 2 == 0) {
// ...
}
// 좋은 예: uniform 변수 기반 분기
uniform bool useAlternativeMethod;
if (useAlternativeMethod) {
// 모든 스레드가 같은 경로
}데이터 구조 재구성하기
작업을 사전에 분류하여 같은 처리가 필요한 데이터끼리 모아두는 방식도 효과적입니다. 혼합된 데이터를 처리하는 대신 각 타입별로 별도의 패스로 나누어 처리하면, 각 패스 내에서 모든 스레드가 같은 작업을 수행하게 됩니다.
컴퓨트 셰이더에서 이 접근법을 적용하면 다음과 같습니다. 하나의 루프에서 타입을 검사하며 분기하는 대신, TYPE_A만 처리하는 패스와 TYPE_B만 처리하는 패스로 나누는 것입니다.
// 나쁜 예: 혼합된 데이터
for (int i = 0; i < dataCount; i++) {
if (data[i].type == TYPE_A) {
processA(data[i]);
} else {
processB(data[i]);
}
}
// 좋은 예: 사전 분류된 데이터
// Pass 1: TYPE_A만 처리
for (int i = 0; i < typeACount; i++) {
processA(typeAData[i]);
}
// Pass 2: TYPE_B만 처리
for (int i = 0; i < typeBCount; i++) {
processB(typeBData[i]);
}벡터 연산 활용하기
SIMD 연산을 최대한 활용하여 조건문을 제거하는 것도 좋은 방법입니다. 각 컴포넌트마다 조건을 검사하는 대신, 모든 값을 계산한 후 mix 함수를 사용해 마스크를 적용할 수 있습니다.
// 나쁜 예
vec4 result;
if (mask.x) result.x = computeX();
if (mask.y) result.y = computeY();
if (mask.z) result.z = computeZ();
if (mask.w) result.w = computeW();
// 좋은 예 (각 compute 함수의 비용이 작을 때만 유효)
vec4 computed = vec4(computeX(), computeY(), computeZ(), computeW());
vec4 result = mix(vec4(0.0), computed, mask);주의: 이 방식은 모든 compute 함수를 무조건 실행하므로, 각 함수의 계산 비용이 작을 때만 효과적입니다. 만약 compute 함수들이 매우 복잡하고 비용이 크다면, 조건부 실행의 이점을 완전히 잃게 되어 오히려 성능이 더 나빠질 수 있습니다.
Early-Z 및 컬링 최적화
프래그먼트 셰이더에서 discard를 피하고, 가능하면 하드웨어 컬링을 활용하는 것이 좋습니다.
discard의 성능 문제:
- Warp Divergence를 발생시킵니다 (일부 픽셀만 폐기)
- Early-Z 최적화를 비활성화시켜 불필요한 프래그먼트 셰이더 실행을 유발합니다
- 이 두 가지 문제가 결합되어 심각한 성능 저하를 일으킬 수 있습니다
discard를 사용해야 한다면 최대한 빨리 처리하여 불필요한 계산을 줄이는 것이 중요합니다.
// 나쁜 예
void main() {
if (alpha < 0.1) discard;
// 복잡한 계산...
}
// 좋은 예: Alpha Testing을 파이프라인 설정으로 이동
// 또는 계산 전에 최대한 빨리 처리
void main() {
// 최소한의 계산
float alpha = texture(albedoMap, uv).a;
if (alpha < 0.1) discard; // 최대한 일찍 처리
// 복잡한 계산은 그 이후
}동적 분기를 정적 분기로 전환하기
가능하면 컴파일 타임에 결정되도록 하는 것이 좋습니다. 런타임 분기 대신 여러 셰이더 변형을 사용하면 각 모드별로 최적화된 코드 경로를 생성할 수 있습니다.
// 나쁜 예: 런타임 분기
uniform int shaderMode;
if (shaderMode == 0) {
// Mode A
} else if (shaderMode == 1) {
// Mode B
}
// 좋은 예: 여러 셰이더 변형 사용
// 각 모드별로 별도의 셰이더 컴파일성능 측정 방법
프로파일링 도구 활용
NVIDIA Nsight Graphics/Compute를 사용하면 다음 메트릭들을 확인할 수 있습니다:
- Warp Execution Efficiency: Warp 내 활성 스레드 비율을 측정합니다
- Branch Efficiency: 분기문이 실제로 얼마나 효율적으로 실행되었는지 표시합니다
- SM Activity: Streaming Multiprocessor의 활용도를 확인합니다
RenderDoc과 AMD Radeon GPU Profiler도 유사한 메트릭을 제공하며, Warp의 실행 패턴을 시각화하고 병목 지점을 파악하는 데 도움을 줍니다.
GPU Occupancy를 확인하는 것도 좋은 방법입니다. Warp Divergence는 GPU Occupancy, 즉 활성 Warp 수를 감소시키므로 이 지표를 통해 간접적으로 문제를 파악할 수 있습니다.
무엇보다 최적화 전후의 프레임 타임을 직접 비교하며 벤치마크를 수행하는 것이 실질적인 성능 향상을 확인하는 가장 확실한 방법입니다.
정리
Warp Divergence는 GPU 병렬 프로그래밍에서 피할 수 없는 현실이지만, 몇 가지 원칙을 따르면 크게 개선할 수 있습니다.
조건문을 수학 연산으로 대체하고, 균일한 실행 경로를 설계하며, 데이터 구조를 재구성하여 같은 작업끼리 그룹화하는 것이 기본입니다. 또한 벡터 연산을 적극 활용하고, 가능한 경우 정적 분기를 선호해야 합니다.
특히 셰이더에서는 모든 스레드가 같은 코드 경로를 따르도록 설계하는 것이 핵심입니다. 작은 최적화들이 모여 큰 성능 향상으로 이어질 수 있으므로, 이러한 원칙들을 실무에 적용해보시기 바랍니다.

너무 잘 읽었습니다!! 감사합니다~