📌 프로젝트 주제에 대한 자세한 설명은 [K8S] CI/CD Pipeline, 모니터링, 로깅 시스템 구축 프로젝트 - 프로젝트 소개 게시글을 확인해주세요.
쿠버네티스 모니터링 시스템 구축
모니터링 시스템은 Prometheus와 Grafana를 사용해 구축합니다.
모니터링 시스템을 구축하기 위한 진행 계획은 다음과 같습니다.
쿠버네티스 환경에서 Prometheus와 Grafana 구축 및 Traffic 매트릭 생성
첫 번째 단계: Prometheus와 Grafana 설치 및 구성
-
Prometheus와 Grafana를 쿠버네티스 클러스터에 배포합니다.
-
Prometheus 설정 파일을 수정하여 수집 대상을 정의합니다. (WAS자체에서 따로 Exporter 설정을 하지 않습니다)
두 번째 단계: Prometheus API를 활용하여 수집기 개발
- Prometheus API를 사용하여 WAS에서 오고가는 Network Packet을 크롤링합니다.
- 그리고 알맞게 DBMS에 하루 단위로 Insert하는 Job을 개발합니다.
세 번째 단계: Grafana 대시보드 구성
-
Grafana를 열어 새로운 대시보드를 생성합니다.
-
대시보드에 생성한 Traffic 매트릭을 시각화하기 위한 패널을 추가합니다.
그래프 또는 표 등을 사용하여 Traffic의 추이를 표시합니다.
📌 해당 대시보드의 패널을 개발합니다.
- 클러스터 전체에 떠있는 Pod 개수 추적
- 클러스터 전체에서 각 Pod의 Memory, Cpu 상태
- Unhealty 상태에 있는 Pod 개수 추적
- 기타 추가적으로 개발 하고 싶은 것이 있으면 개발하면 됩니다.
Prometheus & Grafana 설치
프로젝트에서 쿠버네티스 클러스터를 모니터링하기 위해서 Prometheus와 Grafana를 사용하기로 하였습니다.
이번 프로젝트에서는 클라우드 셸을 통해 헬름 차트를 사용해 Prometheus와 Grafana를 설치해주도록 하겠습니다.
⭐️ 클라우드 셸에는 기본적으로 헬름이 설치되어 있습니다.
그럼 GCP에서 클라우드 셸에 접속하여 다음의 과정들을 진행해보겠습니다.
헬름 리포지토리 추가
우선 먼저 클라우드 셸을 사용하여 Prometheus와 Grafana 헬름 리포지토리를 추가해주도록 하겠습니다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
Prometheus와 Grafana 배포
추가한 헬름 리포지토리를 사용해서 배포하기 위해서는 Prometheus와 Grafana의 설정 파일들을 작성해주어야 합니다.
Prometheus와 Grafana에 관련된 설정 파일들은 별도의 모니터링 디렉토리에 정리해주도록 하겠습니다.
mkdir monitoring
cd monitoring그럼 이제 생성한 디렉토리에 설정 파일들을 작성해주도록 하겠습니다.
우선 먼저 Prometheus의 설정파일입니다.
# values-prometheus.yaml
server:
enabled: true
persistentVolume:
enabled: true
accessModes:
- ReadWriteOnce
mountPath: /data
size: 100Gi
replicaCount: 1
## Prometheus data retention period (default if not specified is 15 days)
##
retention: "15d"다음으로는 Grafana의 설정파일입니다.
이 때, 그라파나의 아이디와 패스워드는 admin/test1234!로 구성되며, Grafana에 쉬운 접근을 위해서
LoadBalnacer 타입으로 서비스를 지정해주었습니다.
현재 진행하고 있는 프로젝트는 연습을 위한 목적이지만 모니터링 시스템은 외부에 노출되지 않도록 하는 것이 좋습니다.
replicas: 1
service:
type: LoadBalancer
persistence:
type: pvc
enabled: true
# storageClassName: default
accessModes:
- ReadWriteOnce
size: 10Gi
# annotations: {}
finalizers:
- kubernetes.io/pvc-protection
# Administrator credentials when not using an existing secret (see below)
adminUser: admin
adminPassword: test1234!위와 같이 Prometheus와 Grafana에 대한 설정 파일들을 작성해주었다면
작성한 설정 파일들을 사용하여 Prometheus와 Grafana 배포를 해보겠습니다.
kubectl create ns monitoring
helm install prometheus prometheus-community/prometheus -f values-prometheus.yaml -n monitoring
helm install grafana grafana/grafana -f values-grafana.yaml -n monitoring배포 확인
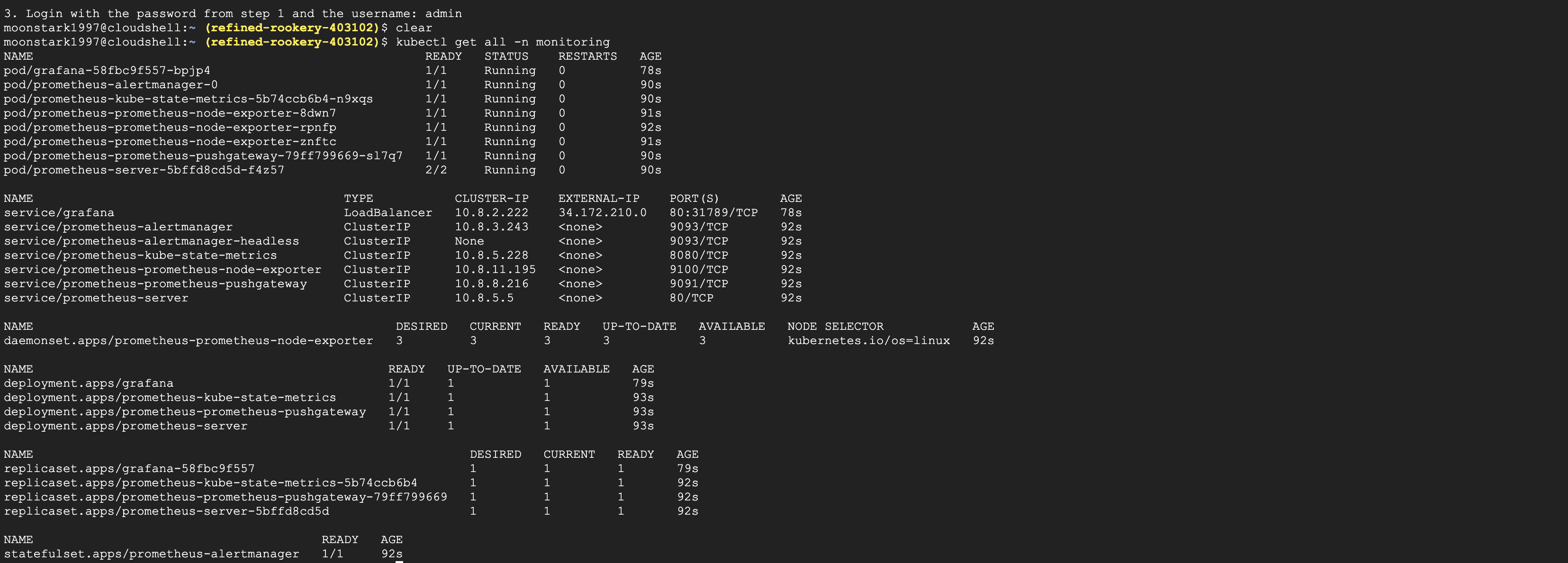
이제 Prometheus와 Grafana가 잘 구성되었는지 확인해보겠습니다.
kubectl get all -n monitoring핼름 차트와 설정 파일들을 사용하여 간편하게 Prometheus와 Grafana를 배포하였습니다.
Grafana 구성
Prometheus와 Grafana를 성공적으로 배포하였으니, Prometheus가 수집하는 메트릭을
Grafana를 통해서 간편하게 볼 수 있도록 구성해주겠습니다.
Grafana 서비스의 External IP에 접속해서 Grafana에 접근해주겠습니다.
우선 먼저 그라파나 설정 파일에서 생성한 유저의 아이디와 패스워드로 접속해주겠습니다.

Data Sources 추가
Data Sources를 추가해줌으로써 프로메테우스의 데이터를 가져올 수 있도록 하겠습니다.
홈 화면에서 [Data Sources]를 클릭
프로메테우스의 데이터를 가져오기 원하므로 데이터 소스 타입을 [Prometheus]로 선택해줍니다.
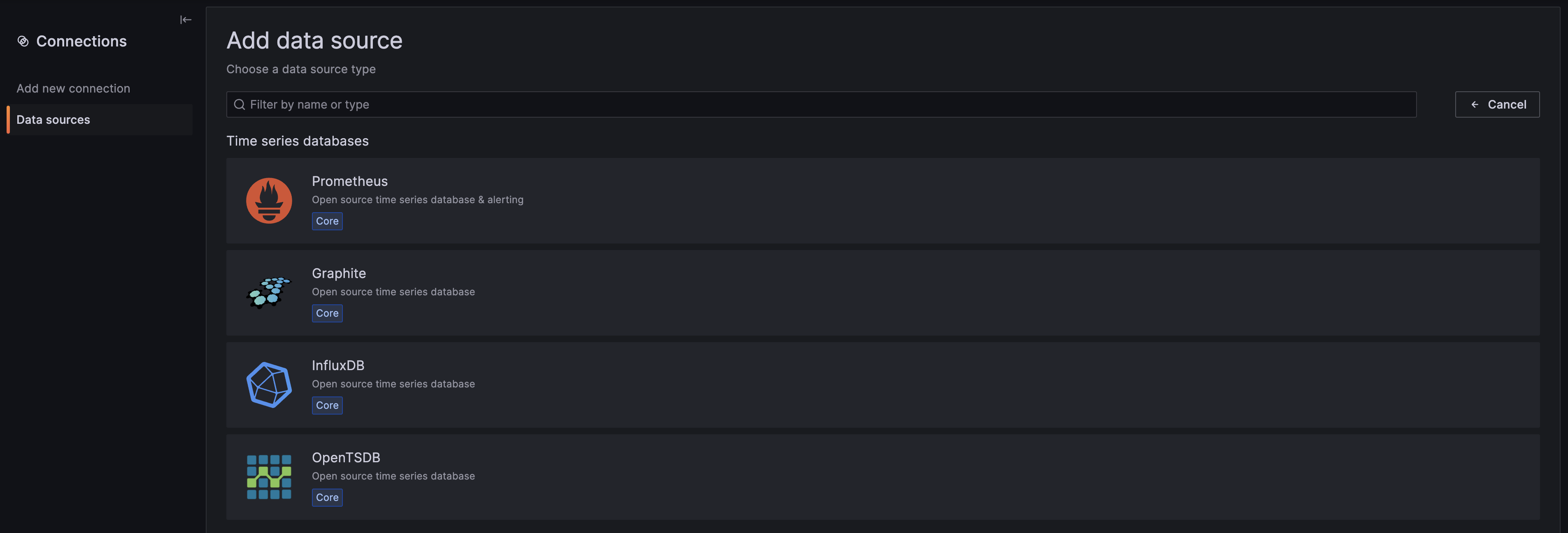
이제 HTTP 서버에 대한 URL 정보에 프로메테우스 서버의 도메인 정보를 입력해줍니다.
프로메테우스의 도메인 이름은 Service를 통해서 확인할 수 있습니다.
위에서 확인했던 것과 같이 service/prometheus-server 이름을 확인하였습니다.
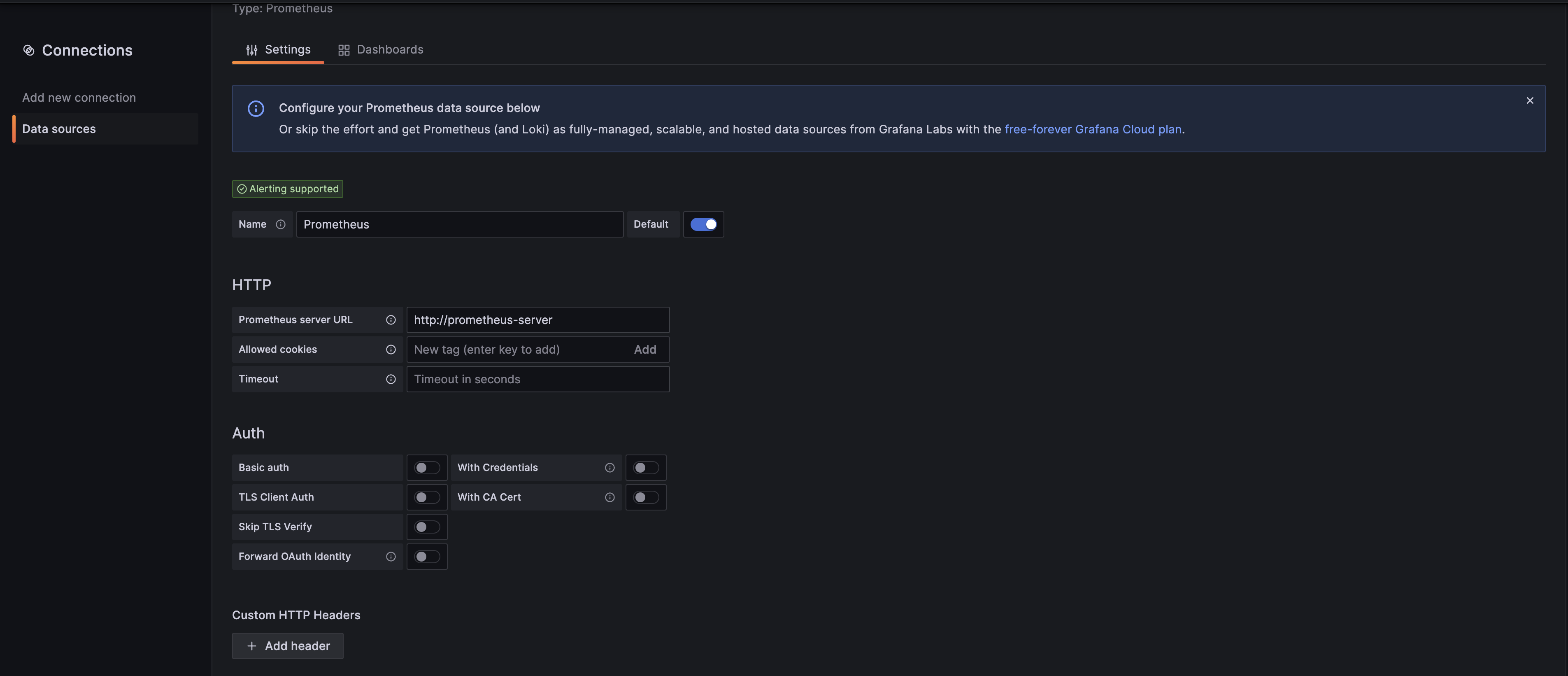
이외에는 따로 지정해줄 것이 없으므로 바로 [Save & Test]를 진행해주겠습니다.

Grafana 대시보드 구성
추가한 데이터 소스를 눈으로 보기 위해서 Grafana의 대시보드를 구성 해주겠습니다.
Grafana 대시보드를 구성하기 위해서 좌측 메뉴를 통해 Dashboards로 들어가줍니다.
그라파나 사이트에는 다양한 모양을 가진 대시보드 템플릿이 있습니다.
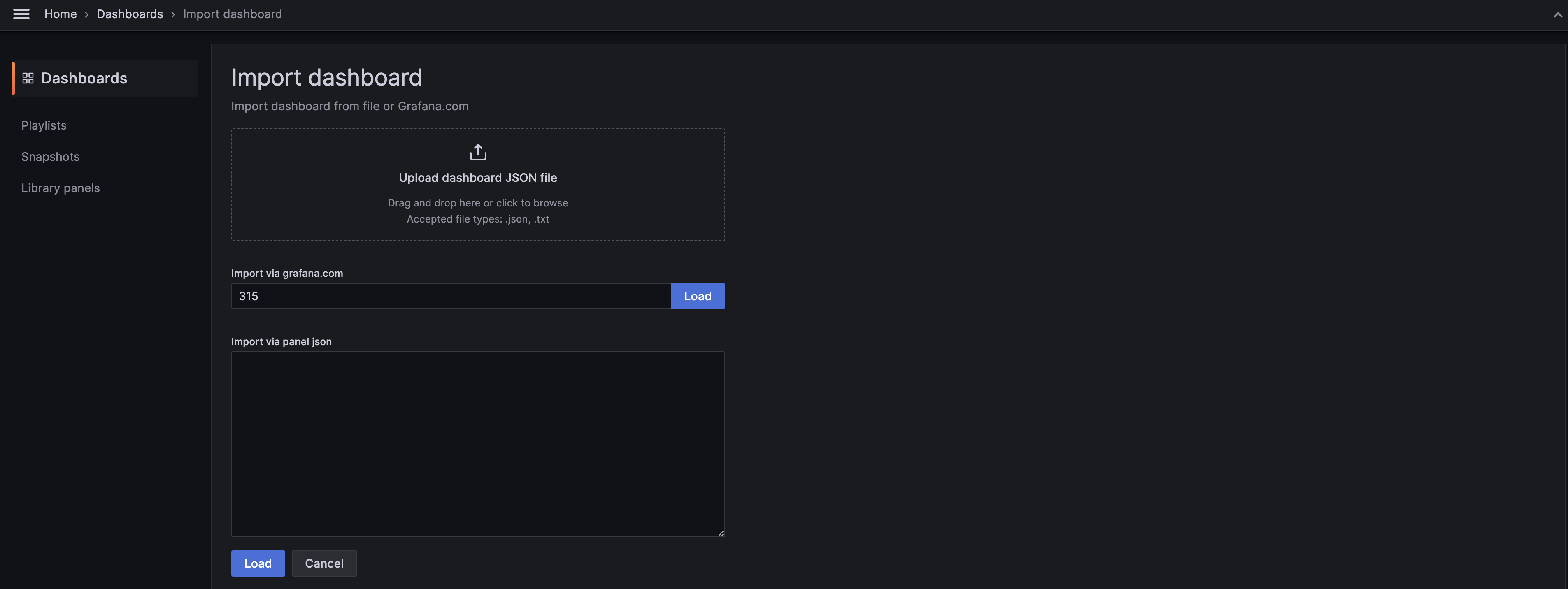
이 중에서 저는 315번 템플릿을 Import해서 대시보드를 구성해보겠습니다.
315번 대시보드 입력 후 [Load] 클릭
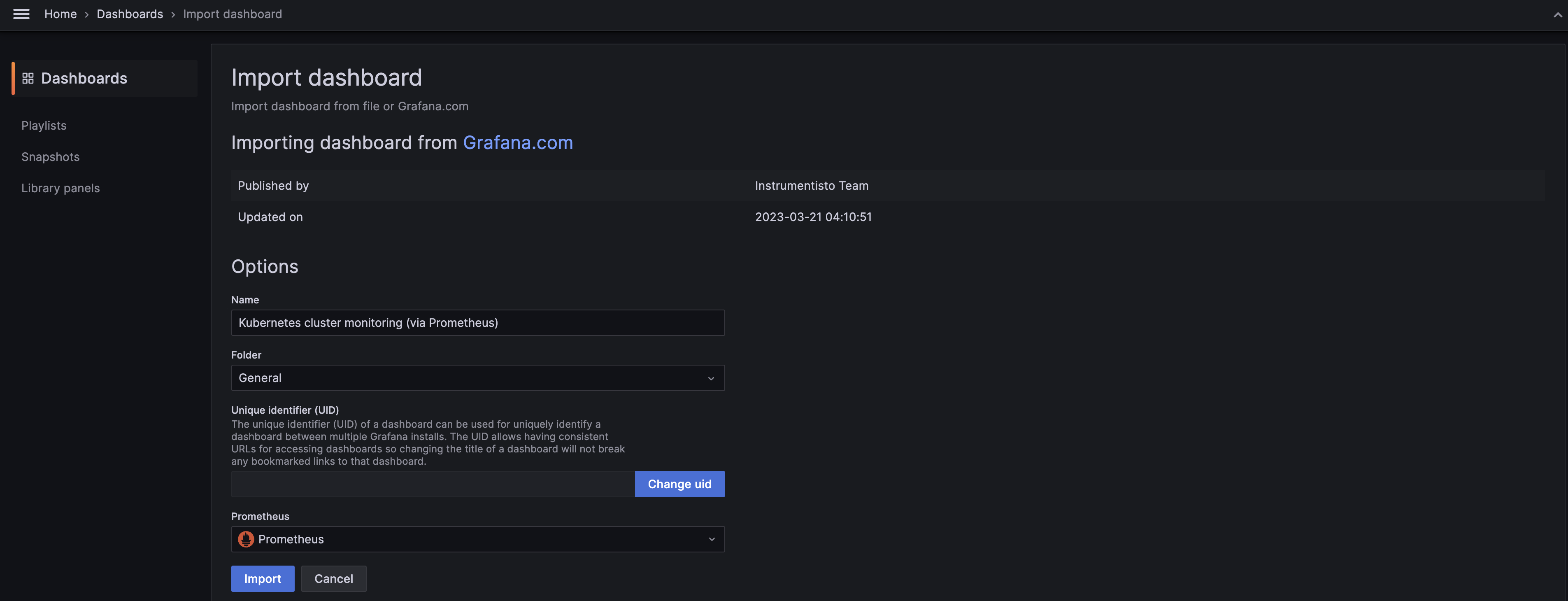
Select a Prometheus data source 에서 조금 전에 추가했던 프로메테우스 데이터 소스를
선택해주고 [Import] 하겠습니다.
그럼 다음과 같이 프로메테우스 데이터 소스를 간편하게 볼 수 있게 되었습니다.
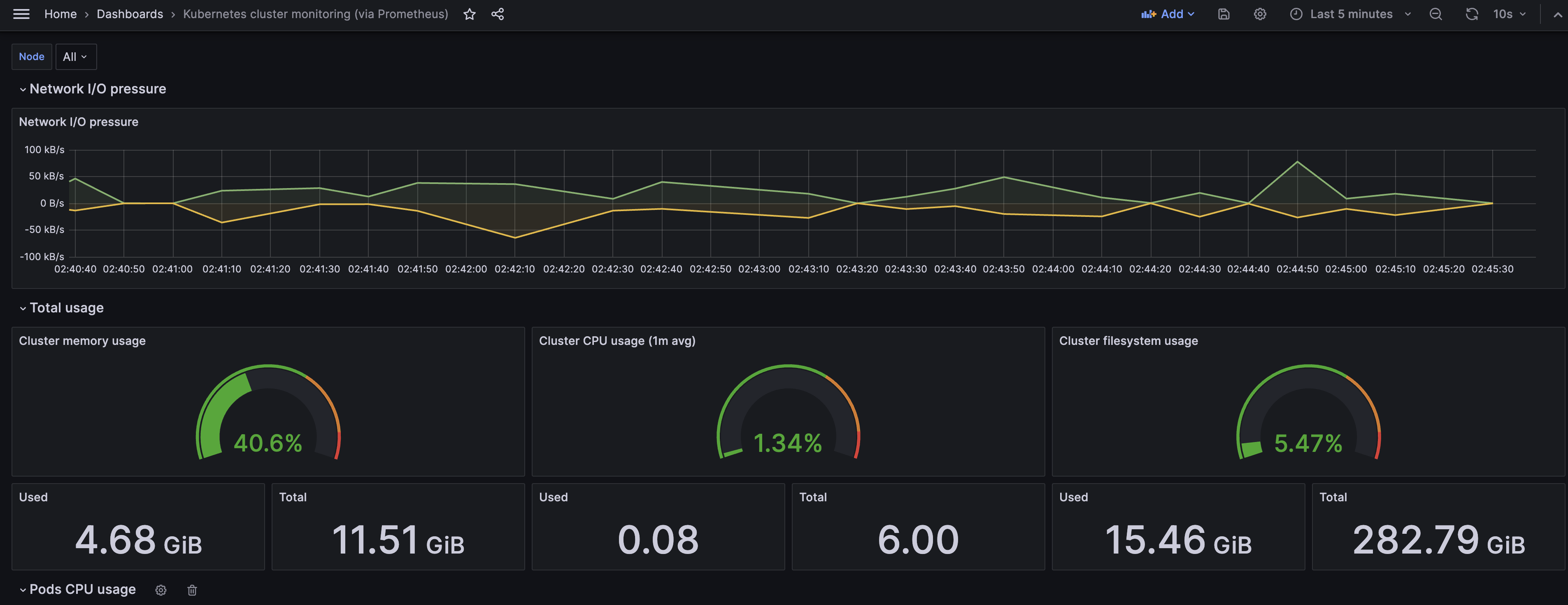
Promql을 사용해 대시보드 패널 추가
앞서서 Prometheus와 Grafana를 사용해서 쿠버네티스 Cluster의 정보를
간편하게 볼 수 있는 모니터링 시스템을 구축하였습니다.
하지만, 저의 프로젝트는 더 나아가 Cluster의 추가적인 정보를 보기 위해서
대시보드 패널을 Promql을 사용해 추가해주도록 하겠습니다.
추가하고자 하는 정보들은 다음과 같습니다.
- 클러스터 전체에 떠있는 Pod 개수 조회
- 클러스터 전체에서 각 Pod의 Memory, Cpu 사용량 조회
- Unhealty 상태에 있는 Pod 개수 조회
클러스터 전체에 떠있는 Pod 개수 조회
먼저 클러스터 전체에 떠있는 Pod의 개수를 볼 수 있는 대시보드 패널을 만들어 보도록 하겠습니다.
대시보드 패널을 추가하기 위해서는 상단에 있는 [Add] -> [Visualization] 버튼을 눌러줍니다.
그리고 우측 하단에 있는 Builder/Code 중에서 Code를 사용하여
우리가 보고자 하는 데이터인 전체 파드의 수를 조회할 수 있는 Promql을 작성 해주도록 하겠습니다.
sum(kubelet_running_pods)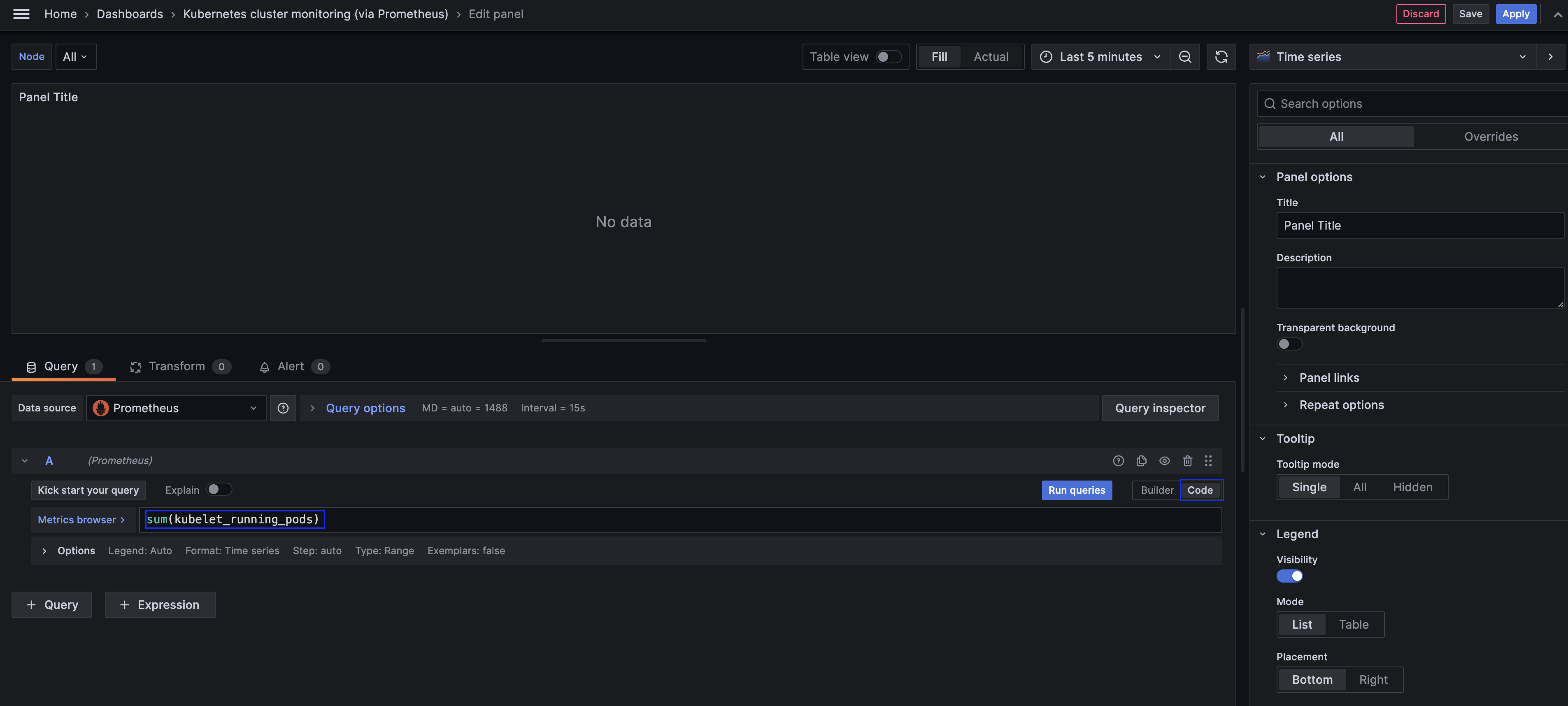
그럼 이제 [Run queries]를 눌러 작성한 쿼리를 실행해보면 아래와 같은 결과를 볼 수 있습니다.
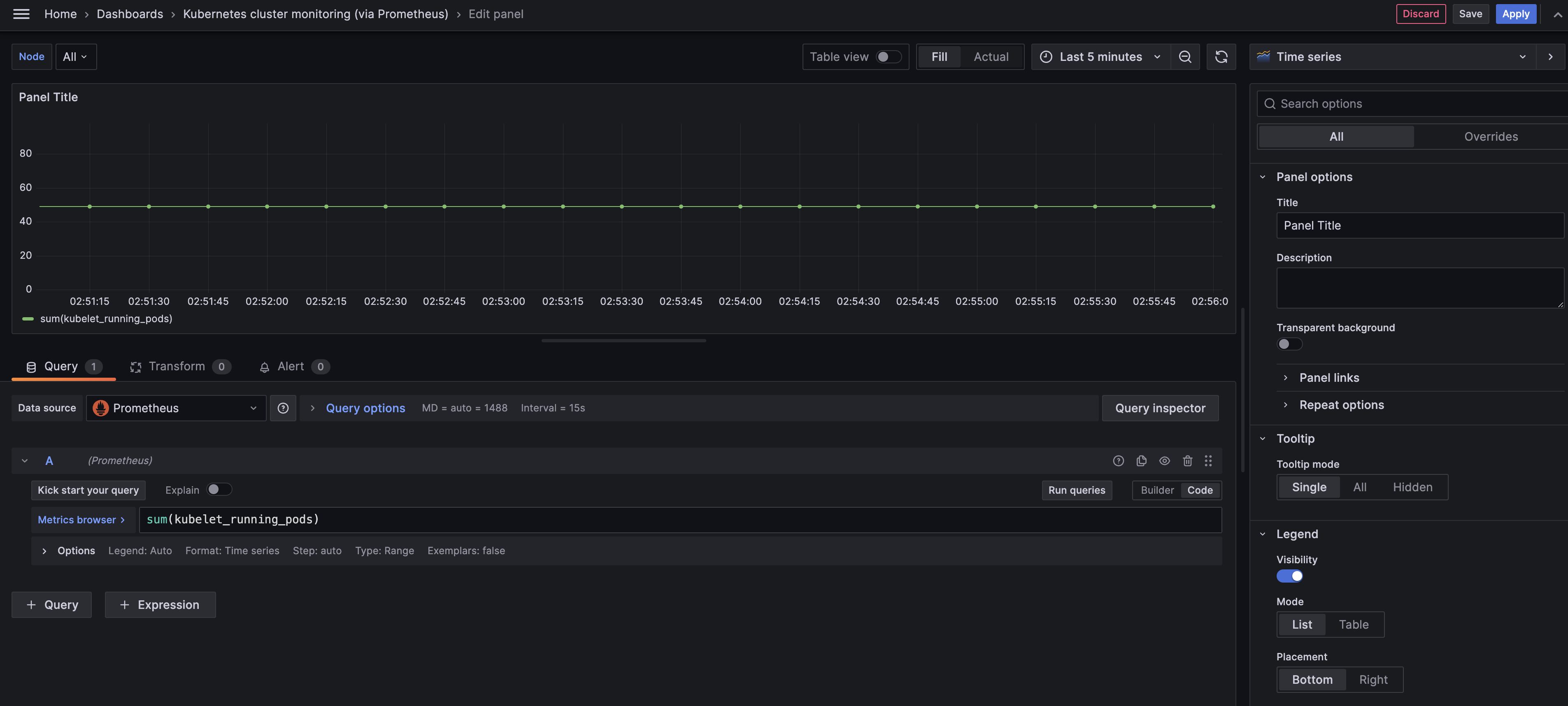
[Run queries]를 눌러 생긴 그래프는 우리가 보고자 하는 데이터를 보여주기는 하지만
한 눈에 정확한 정보를 알아보기에는 한계가 있습니다.
이를 위해서 그래프의 모양을 변경해 한 눈에 알아볼 수 있도록 변경해보겠습니다.
우리 상단에 있는 메뉴에 숫자로 쉽게 볼 수 있는 Gauge를 선택해주도록 하겠습니다.
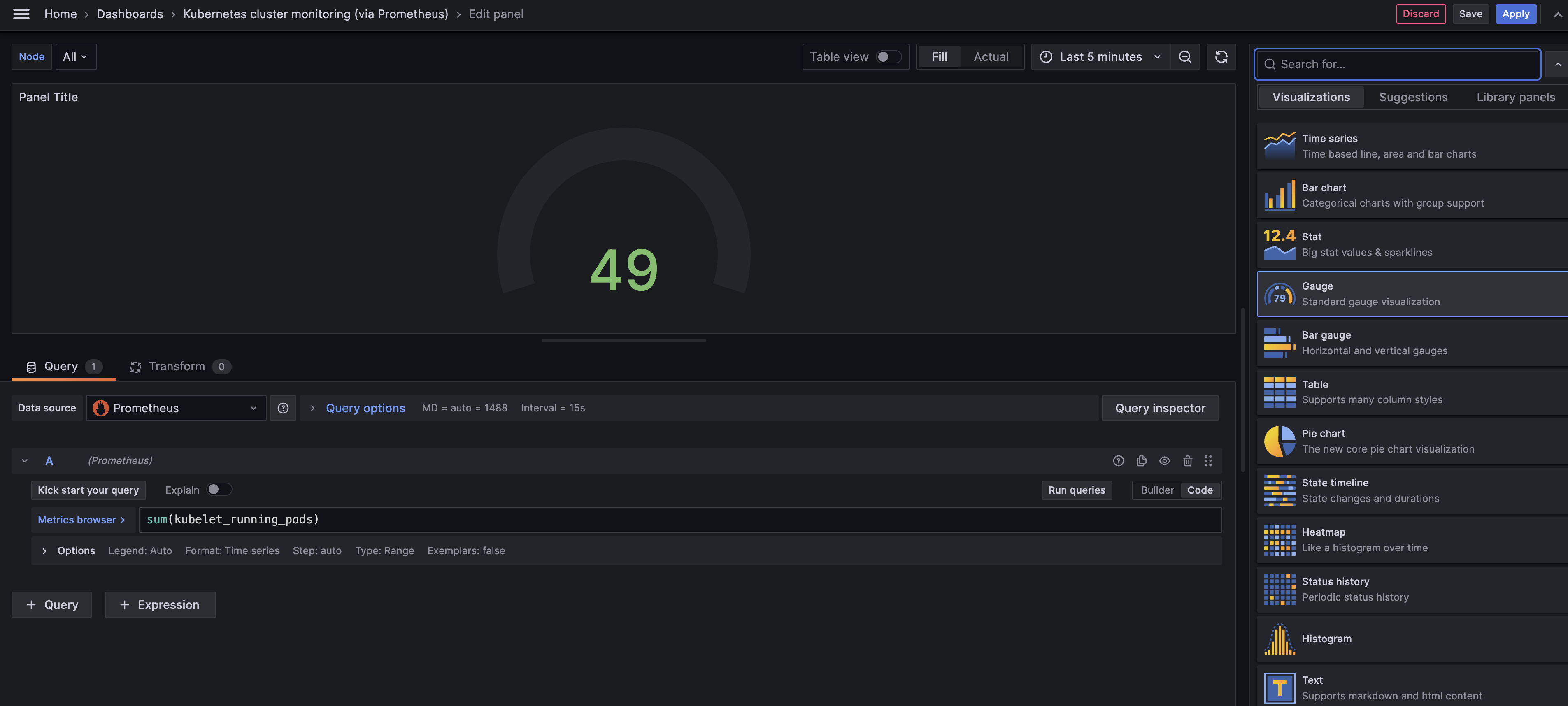
그리고 패널의 타이틀을 "Total Count of Running Pods in Cluster"로 지정해
대시보드에서 어떤 정보인지 알아볼 수 있도록 해줍니다.
그럼 이렇게 숫자로 한 눈에 알아볼 수 있도록 디스플레이 해줍니다.
여기서 우측 상단에 있는 [Apply] 버튼을 통해 직접 생성한 패널을 대시보드에 적용해줍니다.
대시보드로 돌아오면 기본에 Import 했던 대시보드에 직접 생성한 패널이 추가된 것을 볼 수 있습니다.
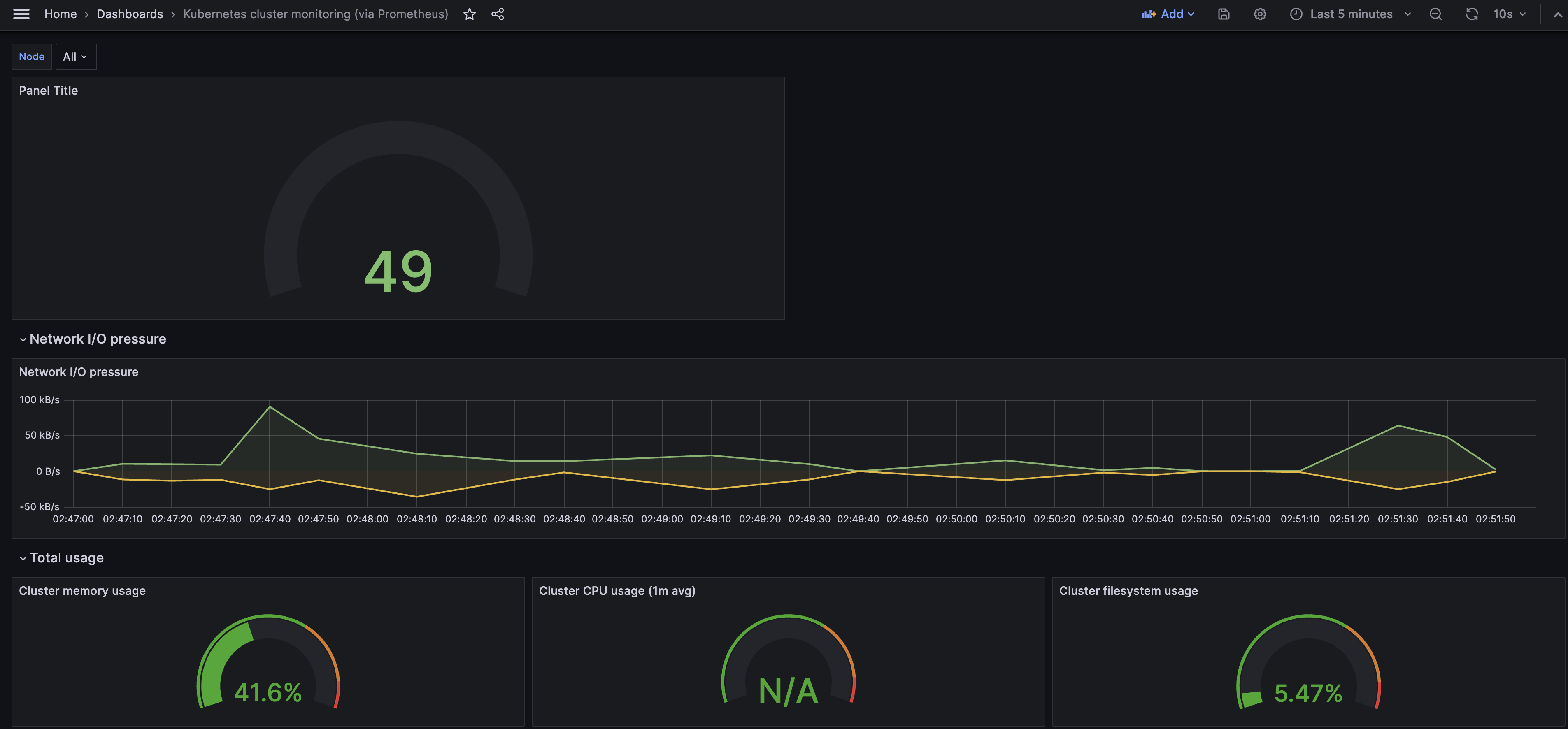
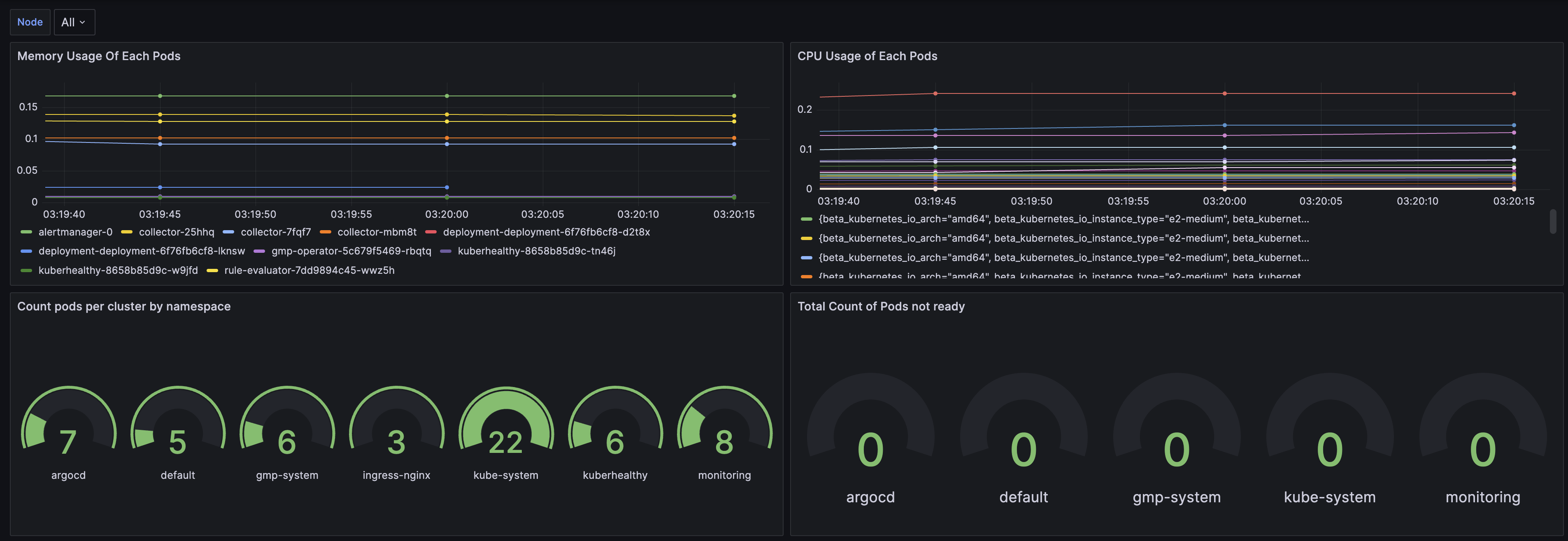
클러스터 전체에서 각 Pod의 Cpu 사용량
클러스터 전체에 떠있는 Pod 개수를 조회하는 과정에서 자세하게 설명하였으니
앞으로 뒤에 과정은 간략하게 설명하면서 넘어가겠습니다.
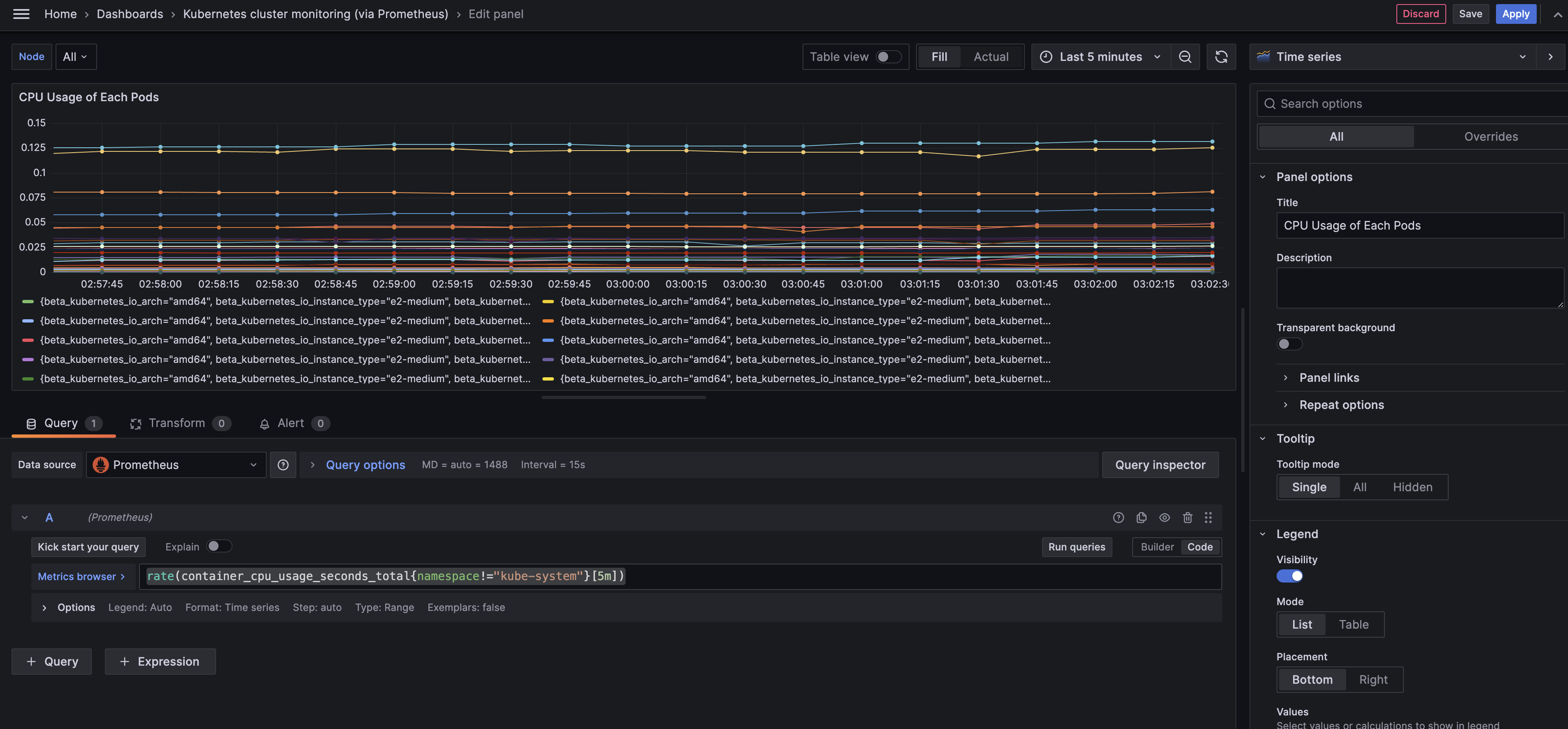
패널 타이틀: CPU Usage of Each Pods
Panel Type: Time series
rate(container_cpu_usage_seconds_total{namespace!="kube-system"}[5m])저는 개인적으로 kube-system 네임스페이스에 속한 파드의 정보까지 함께 나오면
그래프가 너무 조밀하게 보여 kube-system 네임스페이스에 속한 파드는 제외하였습니다.
클러스터 전체에서 각 Pod의 Memory 사용량
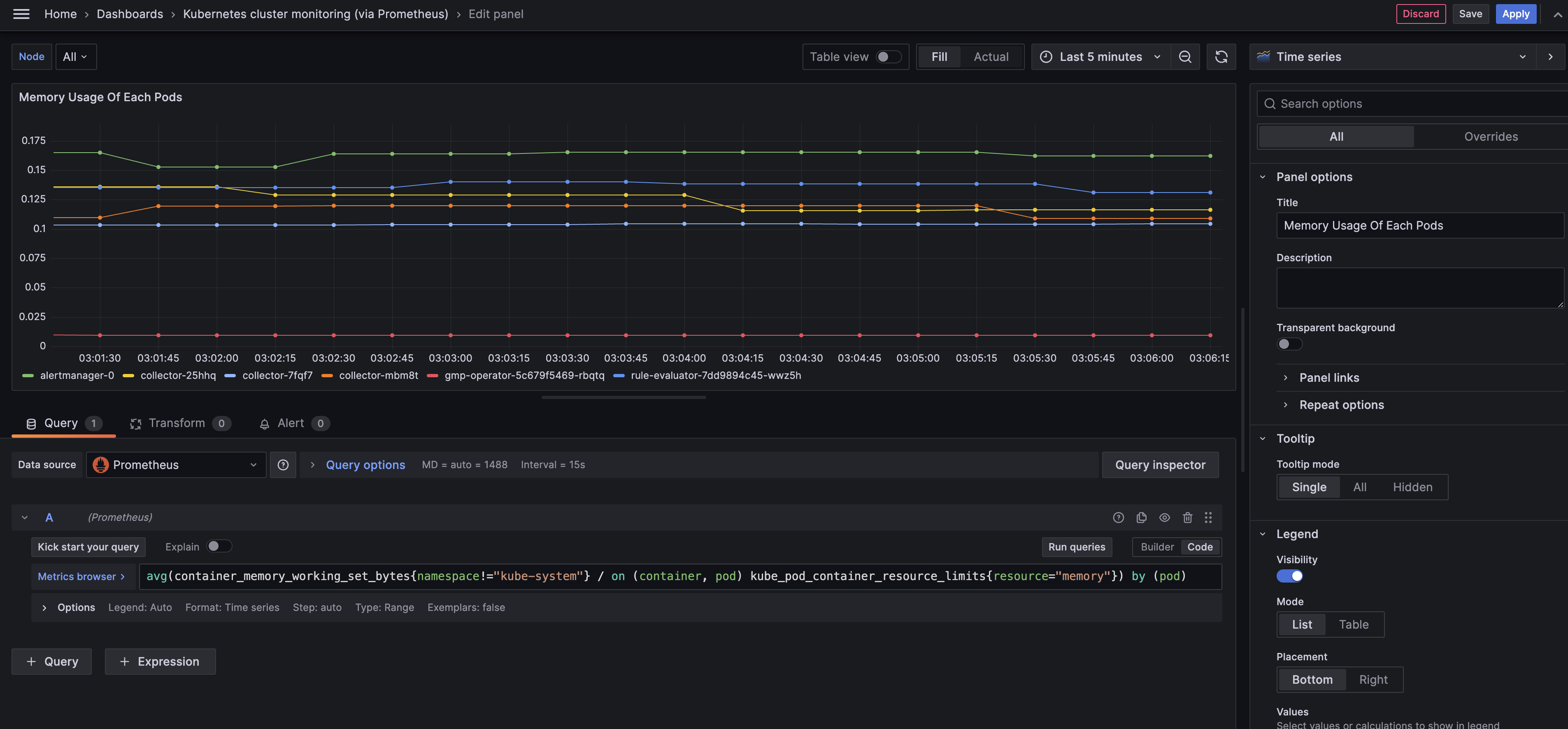
패널 타이틀: Memory Usage Of Each Pods
Panel Type: Time series
avg(container_memory_working_set_bytes{namespace!="kube-system"} / on (container, pod) kube_pod_container_resource_limits{resource="memory"}) by (pod)메모리 정보도 CPU와 같은 이유로 kube-system 네임스페이스에 속한 파드는 제외하였습니다.
Unhealty 상태에 있는 Pod 개수
이번 프로젝트를 진행하면서 GKE 환경에 Ingress를 통해서 서비스를 라우팅하는 과정에서
Unhealty와 관련된 이슈를 만난적이 있기 때문에 Unhealty 상태에 있는 Pod 개수를 조회해보도록 하겠습니다.
하지만 지금 프로젝트에서 구축한 Prometheus에서는 Pod의 Healthy에 대한 메트릭을 수집하고 있지는 않습니다.
이를 위해서 Prometheus에 Pod의 Healthy에 대한 메트릭을 수집할 수 있도록
Kuberhealthy를 Document를 참고해 Prometheus와 Grafana와 마찬가지로
헬름 차트를 사용해 설치하여 간편하게 추가해주도록 하겠습니다.
해당 명령어들을 클라우드 셸에 입력해줍니다.
kubectl create namespace kuberhealthy
helm repo add kuberhealthy https://kuberhealthy.github.io/kuberhealthy/helm-repos
helm install --set prometheus.enabled=true -n kuberhealthy kuberhealthy kuberhealthy/kuberhealthy잘 설치 및 배포가 되었는지 확인해줍니다.
kubectl get all -n kuberhealthy
Kuberhealthy가 잘 배포되는 것을 확인하였으니 다시 Grafana로 돌아가서
Unhealty 상태에 있는 Pod 개수를 조회하는 패널을 만들 수 있습니다.
추가) 네임스페이스별 실행중인 Pod의 수
패널 타이틀: Count pods per cluster by namespace
Panel Type: Gauge
sum by (namespace) (kube_pod_info)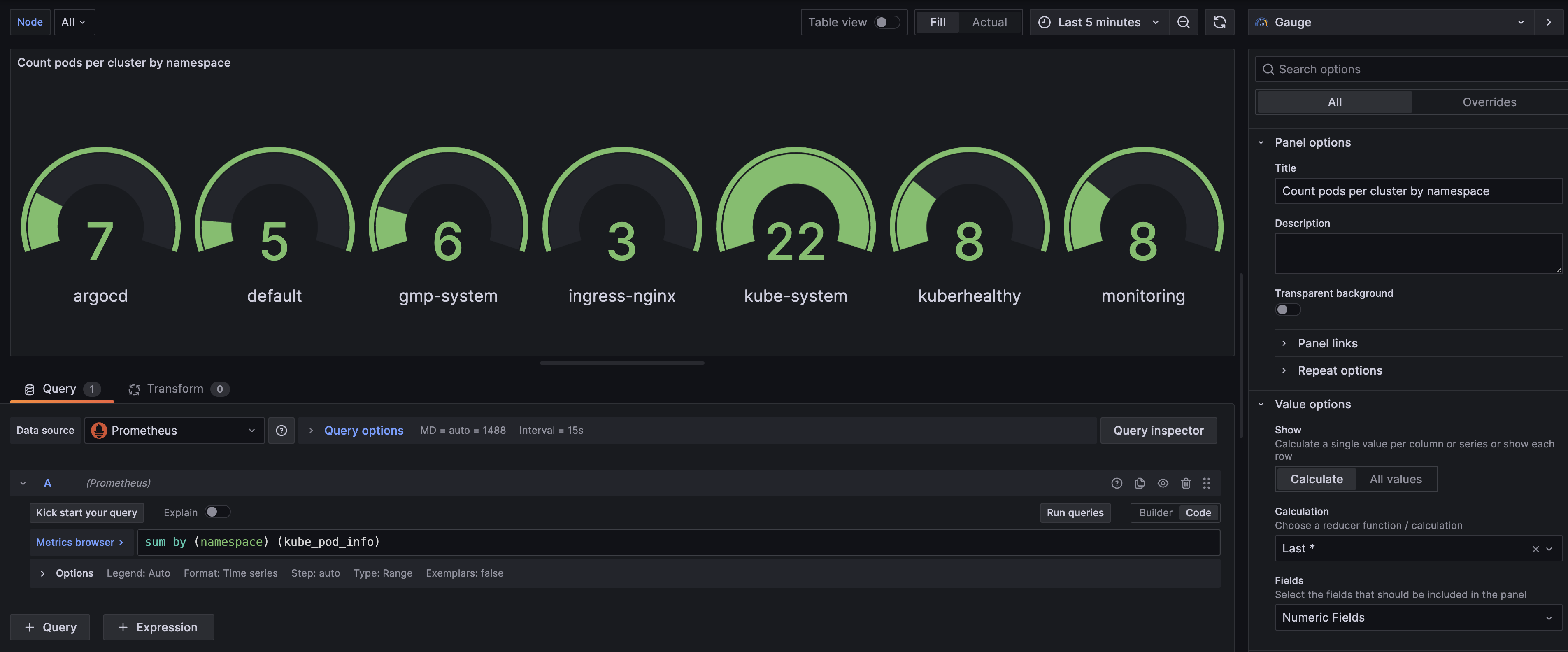
추가) 네임스페이스별 실행하지 않는 Pod의 수
패널 타이틀: Total Count of Pods not ready
Panel Type: Gauge
sum by(namespace) (kube_pod_status_ready{condition="false", namespace!="ingress-nginx", namespace!="kuberhealthy"})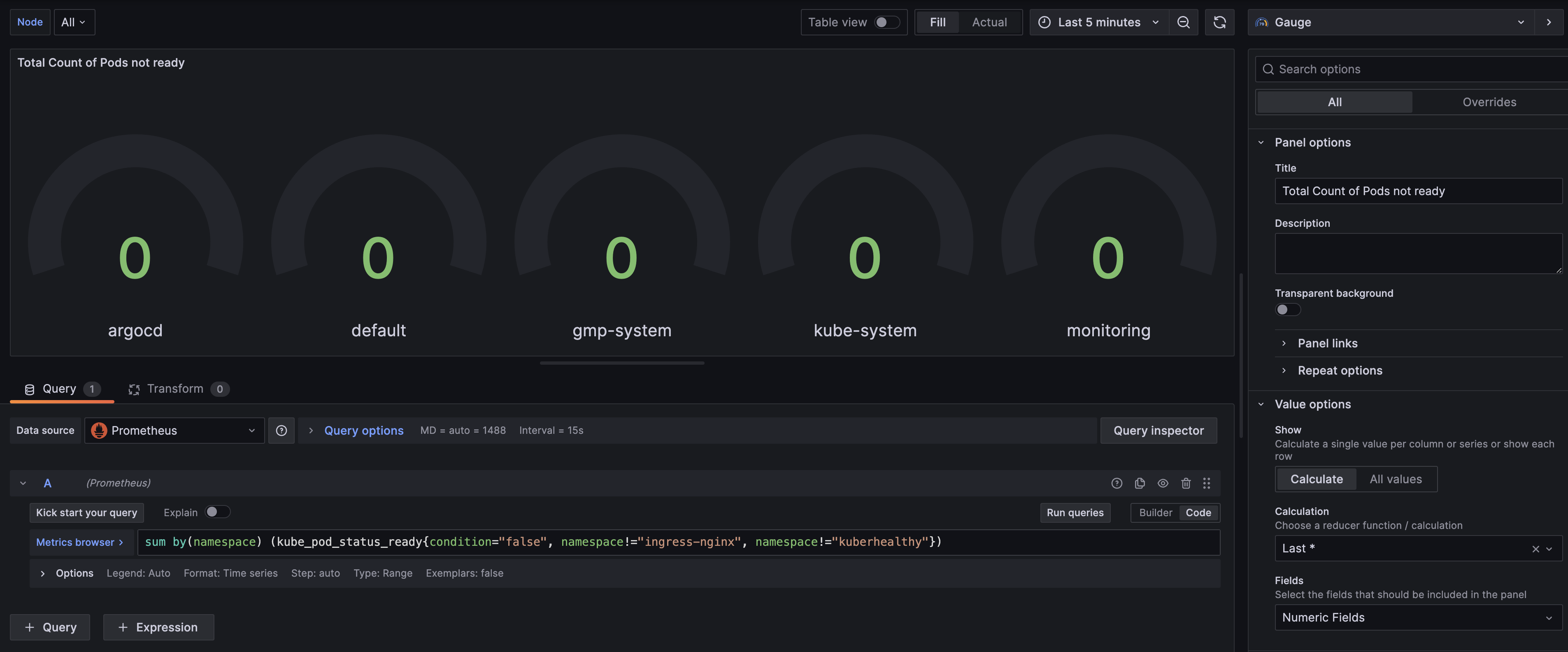
최종 결과 확인
Cluster의 추가적인 정보를 보기 위해 대시보드 패널을 Promql을 사용해 직접 추가하였습니다.
대시보드에 가면 최종적으로 아래와 같은 결과를 모니터링할 수 있습니다.