
🗓️ 1122
❇️ Co-visitation Matrix 공부와 함께 다른 방법론 공부를 해서 정리하기로 했다. 즐거운 도르마무~ 내일 저녁에 있을 회의 준비를 위해 오늘은 집에서
✅ 참고자료 1

동시발생 그룹화(co-occurence grouping)는 객체 간의 연관성을 찾아내는 데이터 마이닝 기법이다. 동시발생 그룹화는 아이템 A가 발생하면 아이템 B도 발생할 가능성이 있다는 규칙이 일반적이다.
동시발생 행렬은 아이템 간의 동시발생 횟수를 행렬로 나타낸 것으로, 두 아이템이 동시에 발생한 횟수가 많을수록 더 많은 관련이 있거나 유사하다는 개념이다. 아래 그림은 동시발생 행렬과 사용자 선호 값을 이용하여 추천 벡터인 R을 계산하는 방법에 대해서 나타냈다.
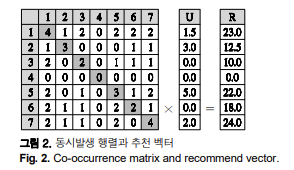
위 그림은 7개 아이템에 대한 동시발생 행렬로 7 x 7 행렬로 구성된다. 각 행은 특정 아이템과 다른 모든 아이템 간의 동시 발생횟수이며, 아이템 A와 아이템 B의 동시발생 횟수와 아이템 B와 아이템 A와의 동시발생 횟수는 동일하기 때문에 좌우대칭이다. 추천 벡터 R은 각 행과 사용자의 선호벡터의 내적을 통해서 계산된다. 사용자의 아이템 6에 대한 R을 계산할 수도 있다.
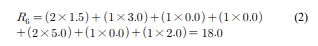
사용자는 아이템 1, 2, 5, 7에 대한 선호를 나타냈다. 따라서 추천은 아이템 3, 4, 5에 대해서 이루어져야 하므로, 가장 좋은 추천은 아이템 6이 된다. 이와 같이 특정 아이템이 사용자가 선호를 표시한 다른 아이템과 동시에 발생하거나 특정 아이템의 동시발생이 선호가 큰 아이템과 많이 겹친다면 R의 값은 커지게 된다.
✅ 참고자료 2

- Oreilly Media 학교 계정으로 로그인하면 볼 수 있다.
데사 교재가 여기서 나와? 상상도 못한 정체 ㄴㅇㄱ
- Co-occurrence grouping (also known as frequent itemset mining, association rule discovery, and market-basket analysis) attempts to find associations between entities based on transactions involving them.
- An example co-occurrence question would be: What items are commonly purchased together?
- While clustering looks at similarity between objects based on the objects’ attributes, co-occurrence grouping considers similarity of objects based on their appearing together in transactions.
- For example, analyzing purchase records from a supermarket may uncover that ground meat is purchased together with hot sauce much more frequently than we might expect.
- Deciding how to act upon this discovery might require some creativity, but it could suggest a special promotion, product display, or combination offer.
- Co-occurrence of products in purchases is a common type of grouping known as market-basket analysis. Some recommendation systems also perform a type of affinity grouping by finding, for example, pairs of books that are purchased frequently by the same people (“people who bought X also bought Y”).
- The result of co-occurrence grouping is a description of items that occur together. These descriptions usually include statistics on the frequency of the co-occurrence and an estimate of how surprising it is.
✅ 개념 정리
결국 Co-Visitaion Matrix = Co-Occurence Matrix = ARD 라는 것이다. 결국 내가 알고 있던 연관 분석이 Co-visitation이었던 것이다. 엉망진창호 그는 도대체 몇 수 앞을 내다본 것인지... 이제 Kaggle에 있는 Code를 좀 뜯어보면서 코드를 이해해보는 단계를 거쳐야 할 것 같다.
✅ 코드 뜯어보기 1

fraction_of_sessions_to_use = 1
if fraction_of_sessions_to_use != 1:
lucky_sessions_train = df.drop_duplicates(['session']).sample(frac=fraction_of_sessions_to_use, random_state=42)['session']
subset_of_train = df[df.session.isin(lucky_sessions_train)]
else:
subset_of_train = df
subset_of_train.index = pd.MultiIndex.from_frame(subset_of_train[['session']])
chunk_size = 30_000
min_ts = df.ts.min()
max_ts = df.ts.max()
from collections import defaultdict, Counter
next_AIDs = defaultdict(Counter)
sessions = df.session.unique()
df=df.drop(['Unnamed: 0'],axis=1)여기까지 실행하고 나면 df는 다음과 같은 형태가 된다.
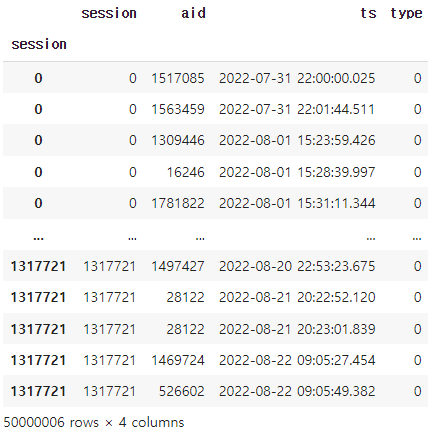
이제 가장 중요한 이 코드를 잘 이해하면 된다.
import datetime as dt
# 0부터 session row 개수 -1까지, 즉 session row 개수까지를 chunk_size만큼 건너뛰며 반복문을 돈다.
# chunk_size = 30000개씩 끊어가면서. i=0, 30000, 60000, ...
for i in range(0, sessions.shape[0], chunk_size):
# 현재 chunk = i번째 event 부터 chunk 크기 만큼까지의 행을 가져온다.
# min을 계산하는 과정은 맨 마지막에 chunk_size보다 남은 데이터가 적을 때를 위함.
# sessions.shape[0]-1 : sessions 총 개수. 즉 range의 끝 범위에 도달했을 때.
# i+chunk_size-1 : 다음 chunk까지의 길이. general case.
current_chunk = df.loc[sessions[i]:sessions[min(sessions.shape[0]-1, i+chunk_size-1)]].reset_index(drop=True)
# session 기준으로 groupby하고 나서 같은 session끼리 묶인 그룹 안에서
# nth : Take the nth row from each group if n is an int, otherwise a subset of rows.
# : n번째 행을 가져온다. => -30번째 행부터 -1번째 행까지 가져온다.
# session의 끝부분을 가져온다. -> 시작부분보다 끝부분이 더 좋을 확률이 높다
current_chunk = current_chunk.groupby('session', as_index=False).nth(list(range(-30,0))).reset_index(drop=True)
# session 열을 기준으로 자기 자신을 inner join(교집합)한다.
consecutive_AIDs = current_chunk.merge(current_chunk, on='session')
# 같은 aid가 중복된 경우를 뺸다.
consecutive_AIDs = consecutive_AIDs[consecutive_AIDs.aid_x != consecutive_AIDs.aid_y]
# str의 ts열을 datetime type으로 바꿔준다.
consecutive_AIDs.ts_y=pd.to_datetime(consecutive_AIDs.ts_y)
consecutive_AIDs.ts_x=pd.to_datetime(consecutive_AIDs.ts_x)
# y와 x의 시간 차이를 구한다.
time_diff=(consecutive_AIDs.ts_y - consecutive_AIDs.ts_x)
# 시간 차이를 consecutive_AIDS에 열로 추가한다.
consecutive_AIDs['days_elapsed'] = time_diff
# 시간 차이가 하루 이하인 날만 추출해서 저장한다.
consecutive_AIDs = consecutive_AIDs[(consecutive_AIDs.days_elapsed >= dt.timedelta(days=0)) & (consecutive_AIDs.days_elapsed <= dt.timedelta(days=1))]
for aid_x, aid_y in zip(consecutive_AIDs['aid_x'], consecutive_AIDs['aid_y']):
next_AIDs[aid_x][aid_y] += 1-
실행하고 나서 consecutive_AIDS는 다음과 같이 생겼다.
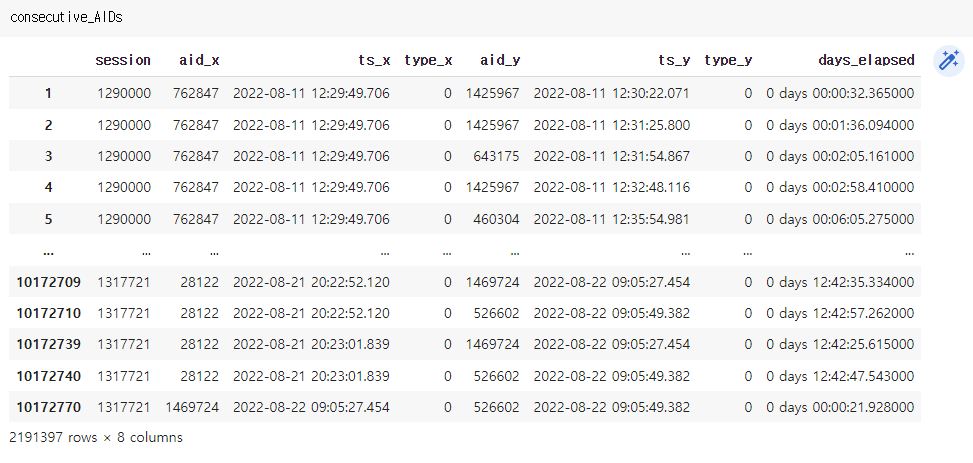
-
실행하고 나서 next_AIDS는 "collections.defaultdict" type으로 아래와 같이 생겼다. aid_x에 대해서(즉 모든 aid_x에 대해서) 중복되지 않는 제품인 aid_y가 동시에 count된 횟수를 세는 것 같다.

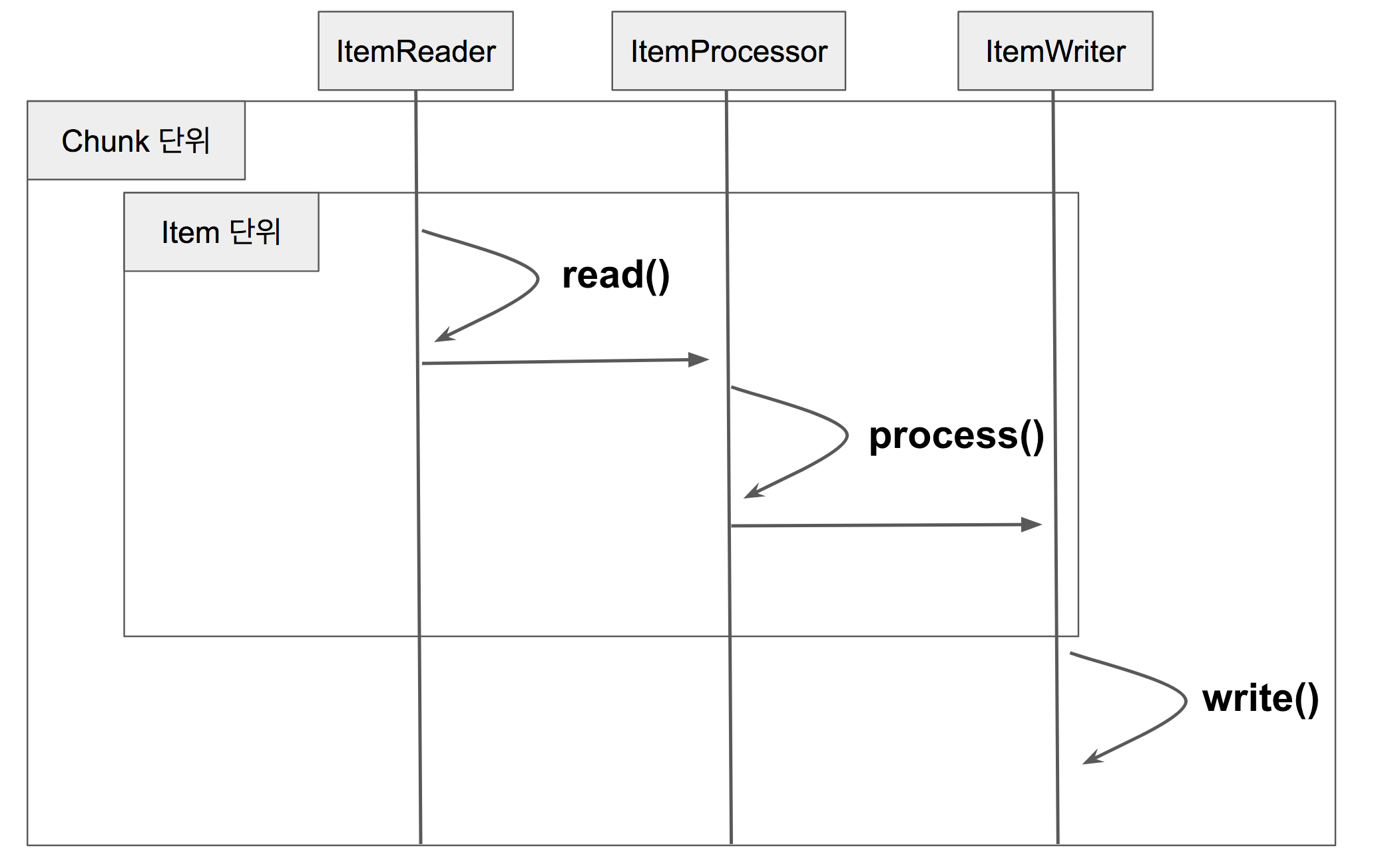
📌 Chunk
Chunk : 데이터 덩어리로 작업할 때 각 커밋 사이에 처리되는 row 수
Chunk 지향 처리 : 한 번에 하나씩 데이터를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 transactions을 다루는 것
chunk_size : 한 번에 처리될 transaction 단위
즉, 다음 단계를 거치게 된다.
- Reader에서 데이터를 하나 읽어온다.
- 읽어온 데이터를 Processor에서 가공한다.
- 가공된 데이터들을 별도의 공간에 모은 뒤, Chunk 단위만큼 쌓이게 되면 Writer에 전달하고 Writer는 일괄 저장한다.
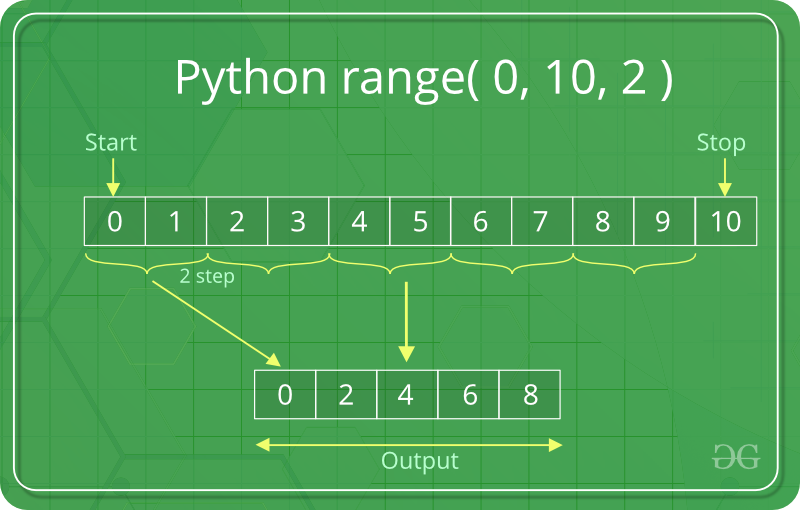
📌 range()
range 함수의 세 번째 파라미터는 step을 의미한다. 시작 인덱스부터 얼마씩 건너뛰며 살필지를 보는 것이다. 아래 그림을 보면 이해가 쉽다.
- step: [optional] integer value, denoting the difference between any two numbers in the sequence.
📌 pandas - merge
merge 메소드 는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할때 사용한다.
- default : DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None
- right : 오른쪽 데이터프레임
- left_on : 기준열 이름이 다를 때, 왼쪽 기준열
- right_on : 기준열 이름이 다를 때, 오른쪽 기준열
- left_index / right_index : 인덱스 기준 병합 시 True로 하면 해당 객체의 인덱스가 병합 기준이 된다.
- on : (두 데이터프레임의 기준열 이름이 같을 때) 기준열
- how : 조인 방식 {'left', 'right', 'inner', 'outer'} 기본값은 'inner'
- sort : 병합 후 인덱스의 사전적 정렬 여부
- suffixes : 병합할 객체들간 이름이 중복되는 열이 있다면, 해당 열에 붙일 접미사
- copy : 사본을 생성할지 여부
- indicator : True로 할경우 병합이 완료된 객체에 추가로 열을 하나 생성하여 병합 정보를 출력
- validate : {'1:1' / '1:m' / 'm:1' / 'm:m'} 병합 방식에 맞는지 확인할 수 있다. 만약 validate에 입력한 병합방식과, 실제 병합 방식이 다를경우 오류가 발생한다
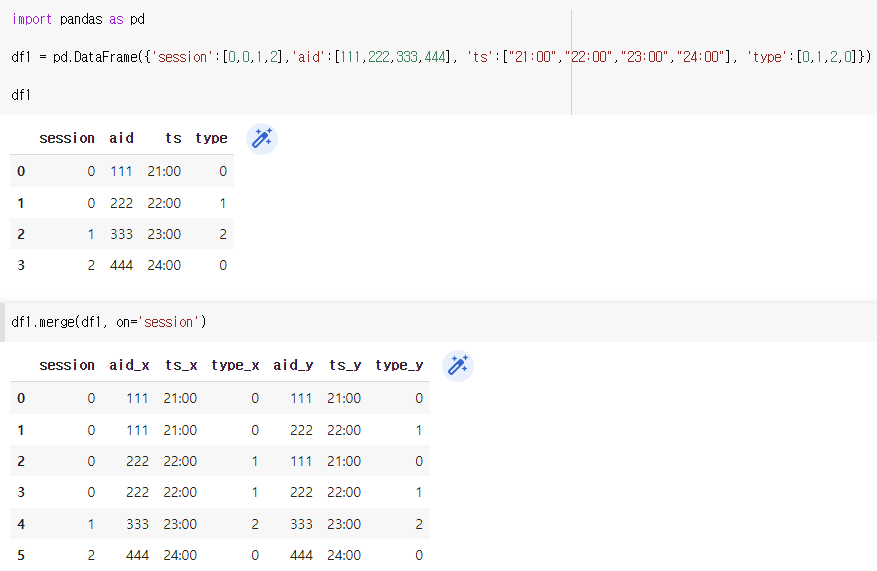
- 간단하게 데이터셋과 비슷한 dataframe을 만들고 테스트 해보았다.
📌 nth
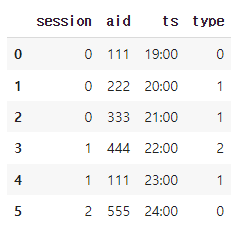
대충 이렇게 생긴 DataFrame이 있다고 가정하자.
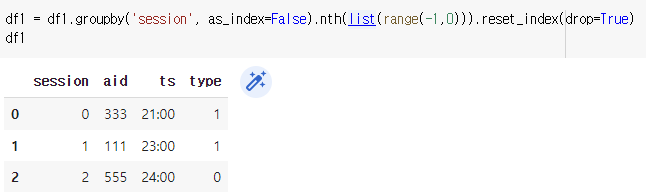
(1) nth의 range를 (-1,0)으로 설정 : -1
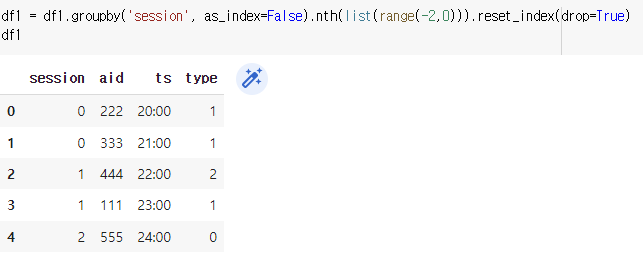
(2) nth의 range를 (-2,0)으로 설정 : -2 -1
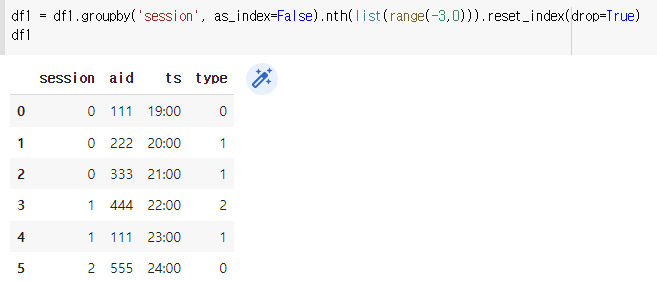
(3) nth의 range를 (-3,0)으로 설정 : -3 -2 -1
- 결론 : 같은 session끼리 groupby된 그룹 각각에서 'list안에 들어있는 값'번째 행렬을 가져온다.
이제 test set 취급을 하는 df3에 적용해보기로 했다.
del df
test=pd.read_csv("/content/drive/MyDrive/khuda_recosys_kaggle/df_sample3.csv")
session_types = ['clicks', 'carts', 'orders']
test_session_AIDs = test.reset_index(drop=True).groupby('session')['aid'].apply(list)
test_session_types = test.reset_index(drop=True).groupby('session')['type'].apply(list)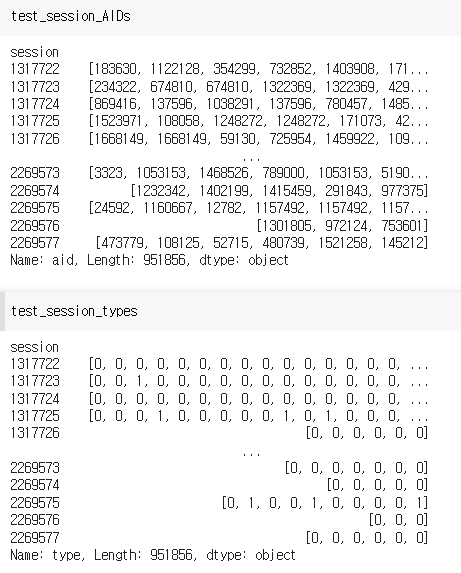
labels=[]
no_data = 0
no_data_all_aids = 0
type_weight_multipliers = {0: 1, 1: 6, 2: 3}
for AIDs, types in zip(test_session_AIDs, test_session_types):
# 만약 test_session_AIDS에 AID가 20개 이상인 경우
if len(AIDs) >= 20:
# 0.1부터 1까지를 AIDS 개수만큼 쪼갠다. 그리고 이 값에서 1을 뺴서 가중치 리스트를 구한다.
# 왜 test_session_AIDS의 AIDs에 해당하는 리스트 원소의 인덱스가 클수록 가중치가 클까.
# 길이는 어떤 의미일까.
# 리스트가 어떻게 정렬되어있는 형태인가? = ?
weights=np.logspace(0.1,1,len(AIDs),base=2, endpoint=True)-1
# 비어있는 defaultdict 생성
aids_temp=defaultdict(lambda: 0)
# w =
# type_weight_multipliers[t] : type(click, cart, order)에 따른 가중치. hyperparam
for aid,w,t in zip(AIDs,weights,types):
aids_temp[aid]+= w * type_weight_multipliers[t]
# aids_temp에서 정렬을 한 다음에 aid number만 뽑는다.
sorted_aids=[k for k, v in sorted(aids_temp.items(), key=lambda item: -item[1])]
# top 20개만 뽑는다.
labels.append(sorted_aids[:20])
# 만약 test_session_AIDS에 AID가 20개보다 적게 있는 경우
else:
# AIDS[::-1] 처음부터 끝까지 역순으로 ( 끝->처음 )
AIDs = list(dict.fromkeys(AIDs[::-1]))
#
AIDs_len_start = len(AIDs)
# 후보군 담을 빈 집합을 만든다.
candidates = []
# test에 있는 aid에 대하여 for문 실행
for AID in AIDs:
# 만약 aid가 next_AIDs에 들어있다면, 후보군 리스트에 해당 aid의 next_AIDs에서
# 제일 많이 Count 되었던 aid top20개를 넣는다.
if AID in next_AIDs: candidates += [aid for aid, count in next_AIDs[AID].most_common(20)]
# 생성된 후보군 집합의 Top40의 aid number를 가져오고
# 이 Top40에서 이미 AIDs에 들어간 aid number은 제외한다.
AIDs += [AID for AID, cnt in Counter(candidates).most_common(40) if AID not in AIDs]
# AIDS 리스트에서 top 20만 선정하여 labels에 담는다.
labels.append(AIDs[:20])
# 데이터 없는 경우(후보군 리스트가 비어있는 경우가 된다.)
if candidates == []: no_data += 1
#
if AIDs_len_start == len(AIDs): no_data_all_aids += 1
📌 numpy.logspace
numpy.logspace(start, stop, num, endpoint, base, dtype)
logspace는 설정한 범위에서 로그로 분할한 위치의 값을 출력한다.
- start - 시작 값
- stop - 값의 마지막 값. 단, endpoint가 True이면 포함되고, False이면 포함되지 않는다.
- num - 배열 맴버의 개수입니다. default=50
- endpoint - stop 값을 포함 여부를 확인하는 것입니다. True - 포함, Fasle -미포함
- base - Log 값의 베이스 값입니다. default=10
- dtype - 배열의 데이터 타입
- 예시

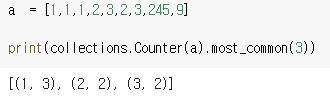
📌 Counter( ) , most_commons( ) module
- collections.Counter(a) : a에서 요소들의 개수를 세어, 딕셔너리 형태로 반환합니다. {문자 : 개수} 형태
- most_common() 함수 - 최빈값 구하기
collections.Counter(a).most_common(n) : a의 요소를 세어, 최빈값 n개를 반환합니다. (리스트에 담긴 튜플형태로)

labels_as_strings = [' '.join([str(l) for l in lls]) for lls in labels]
predictions = pd.DataFrame(data={'session_type': test_session_AIDs.index, 'labels': labels_as_strings})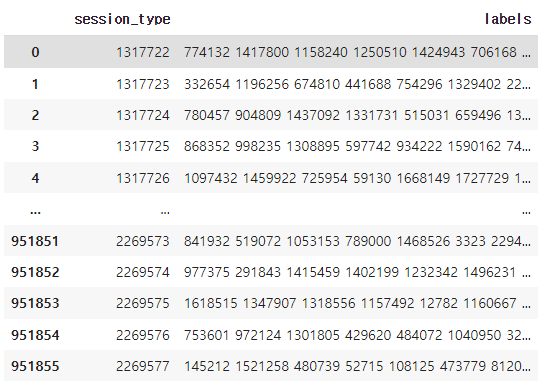
labels_as_strings = [' '.join([str(l) for l in lls]) for lls in labels]
predictions = pd.DataFrame(data={'session_type': test_session_AIDs.index, 'labels': labels_as_strings})
prediction_dfs = []
for st in session_types:
modified_predictions = predictions.copy()
modified_predictions.session_type = modified_predictions.session_type.astype('str') + f'_{st}'
prediction_dfs.append(modified_predictions)
submission = pd.concat(prediction_dfs).reset_index(drop=True)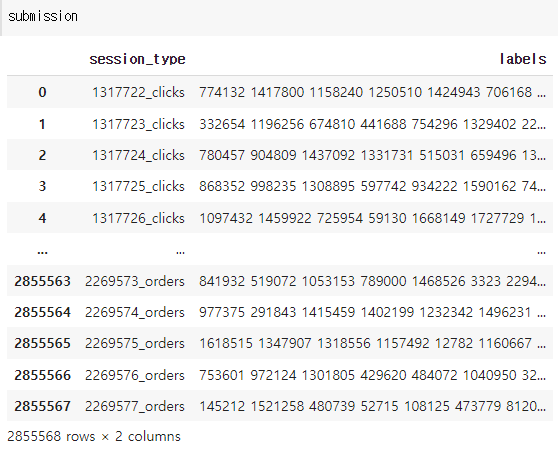
참고자료
https://data-analysis-expertise.tistory.com/92
https://www.geeksforgeeks.org/python-range-function/
https://appia.tistory.com/154
