
2.1 기본 특징
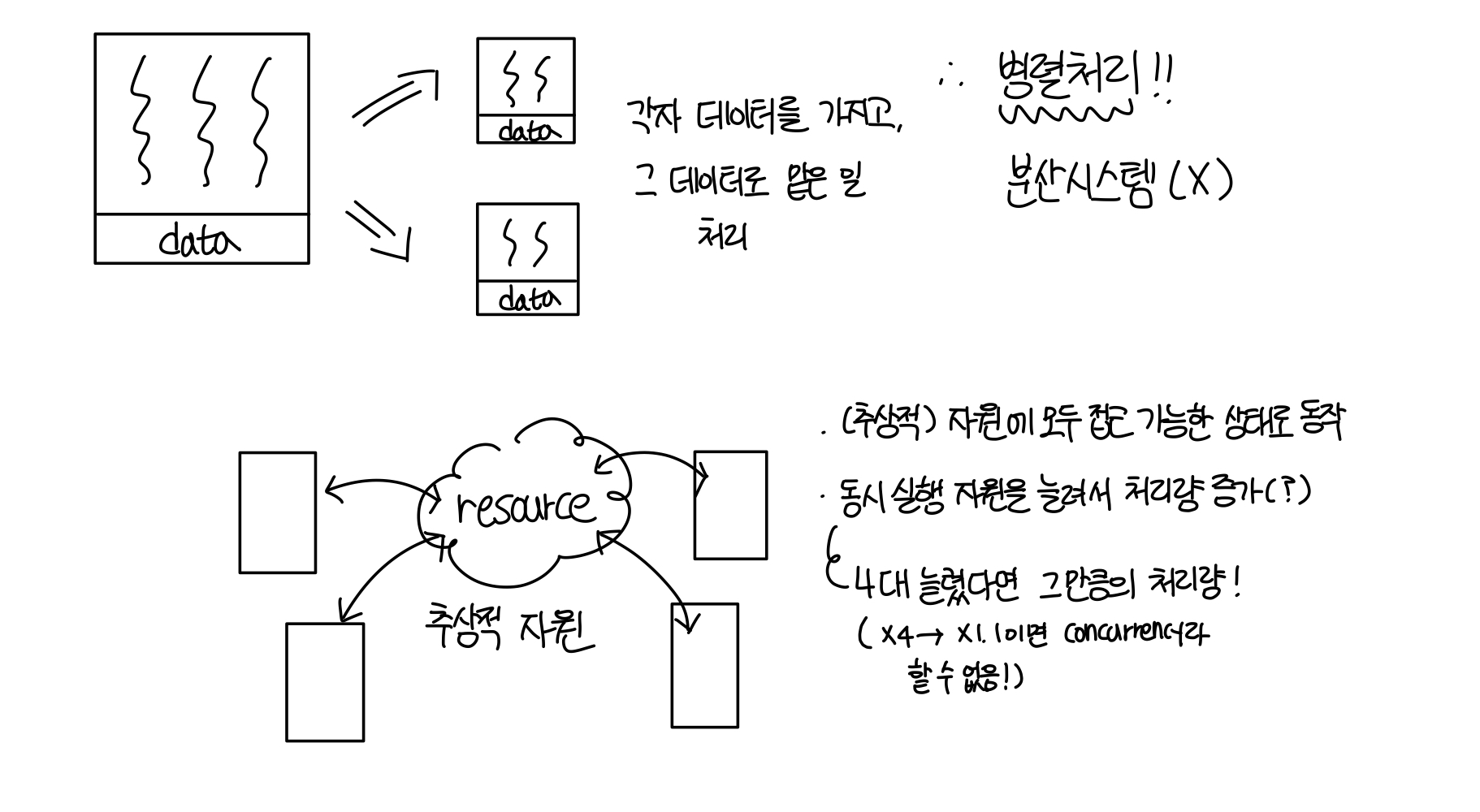
1️⃣ Concurrency
- 자원은 공유하면서, 리소스 내에서 동시에 여러가지 작업을 수행
- 동시 실행 자원을 늘려서 처리량을 늘릴 수 있다.
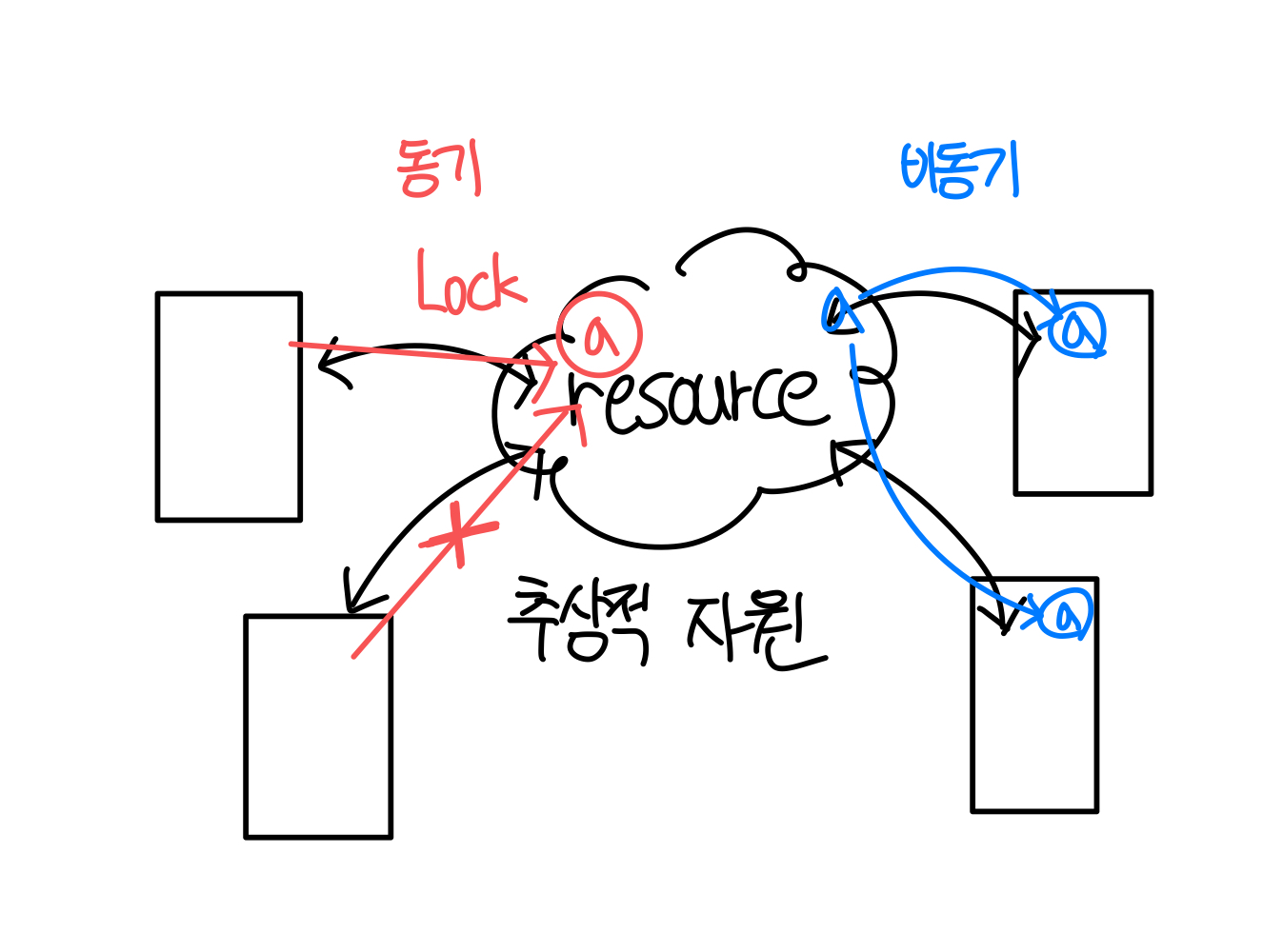
2️⃣ No Global Block
- 시스템의 각 부분이 비동기적으로 동작
( 기계가 다르면 시간도 각각 다름 ) - 어떤 한 부분의 상태 때문에 다른 곳에 Lock, Bottleneck이 걸리면 안된다.
(영향은 받을 수 있음)
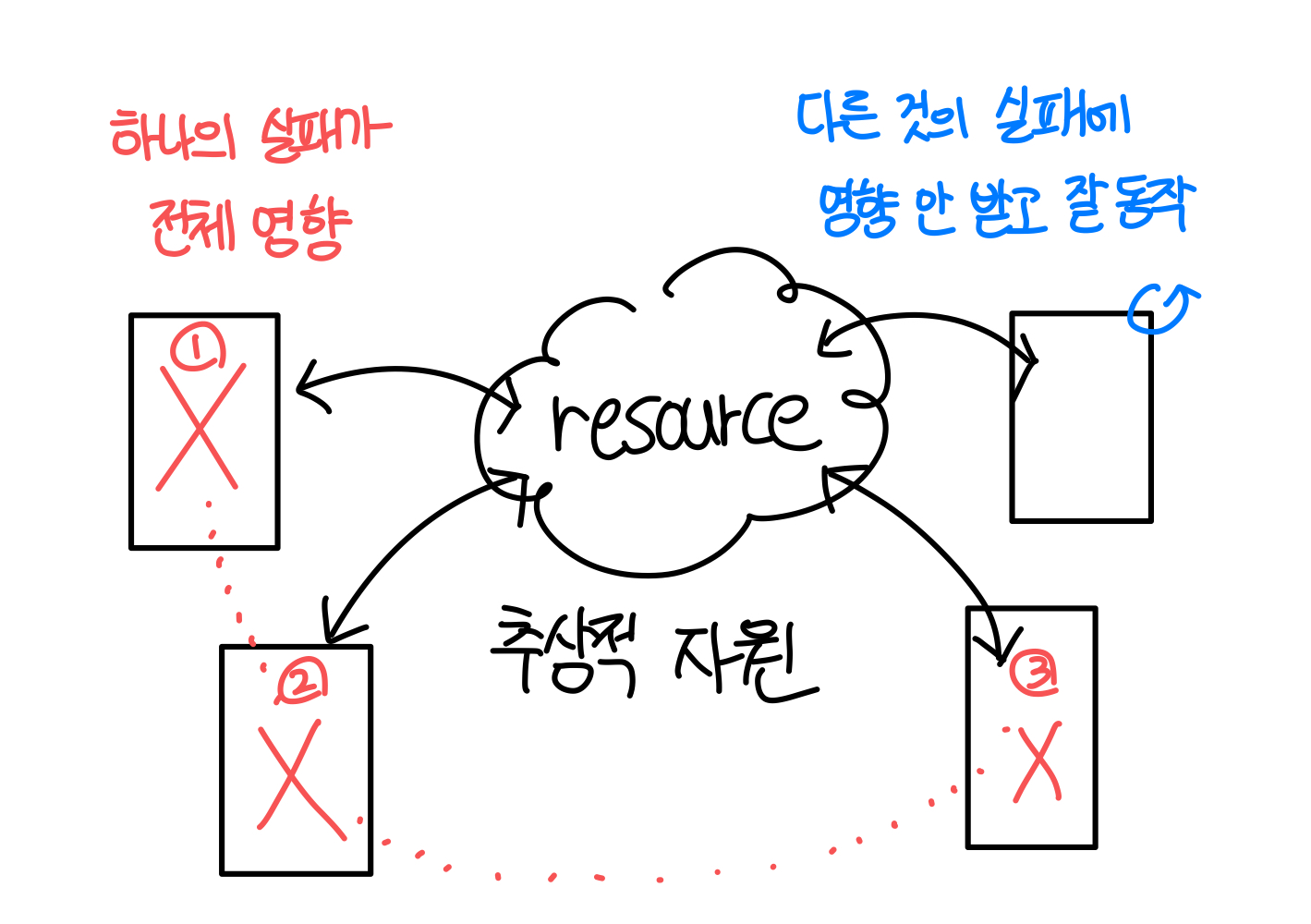
3️⃣ Independent Failure
- (설계 차원에서, 이론적으로) 시스템의 한 부분의 실패가 전체 시스템에 영향(장애)를 주면 안 된다.
2.2 고려 요소
1️⃣ Heterogeneity
- 서로 다른 시스템에 설치하더라도 동일하게 동작해야 한다.
- 서로 다른 시스템 사이에 정보와 자원을 공유하며 동작
- 운영체제 ,HW에 대한 영향이 크기 때문에 일관된 개발을 하기 위한 언어(Java, Scala, Golang)를 선택
2️⃣ Openess
- 서로 다른 요소 사이의 연결과 확장, 상호 운용이 가능해야한다.
- 주요 인터페이스를 노출하고 (프로토콜(=약속)) 기반의 일관된 커뮤니케이션 방식을 사용해야한다.
ex ) 다음과 같은 상황 가정
- 2개의 coordinator node와, 3개의 data node가 있다
- linux 기반의 data node는 coordinator node랑은 통신하는데, data node와는 통신하지 않음
- mac 기반의 data node는 coordinator node랑도 통신하고, data node와도 통신함
- windows 기반의 data node는 coordinator node랑은 통신하지 않는데, data node와는 통신함
➡️ 서로 다른 커뮤니케이션 방식, 약속
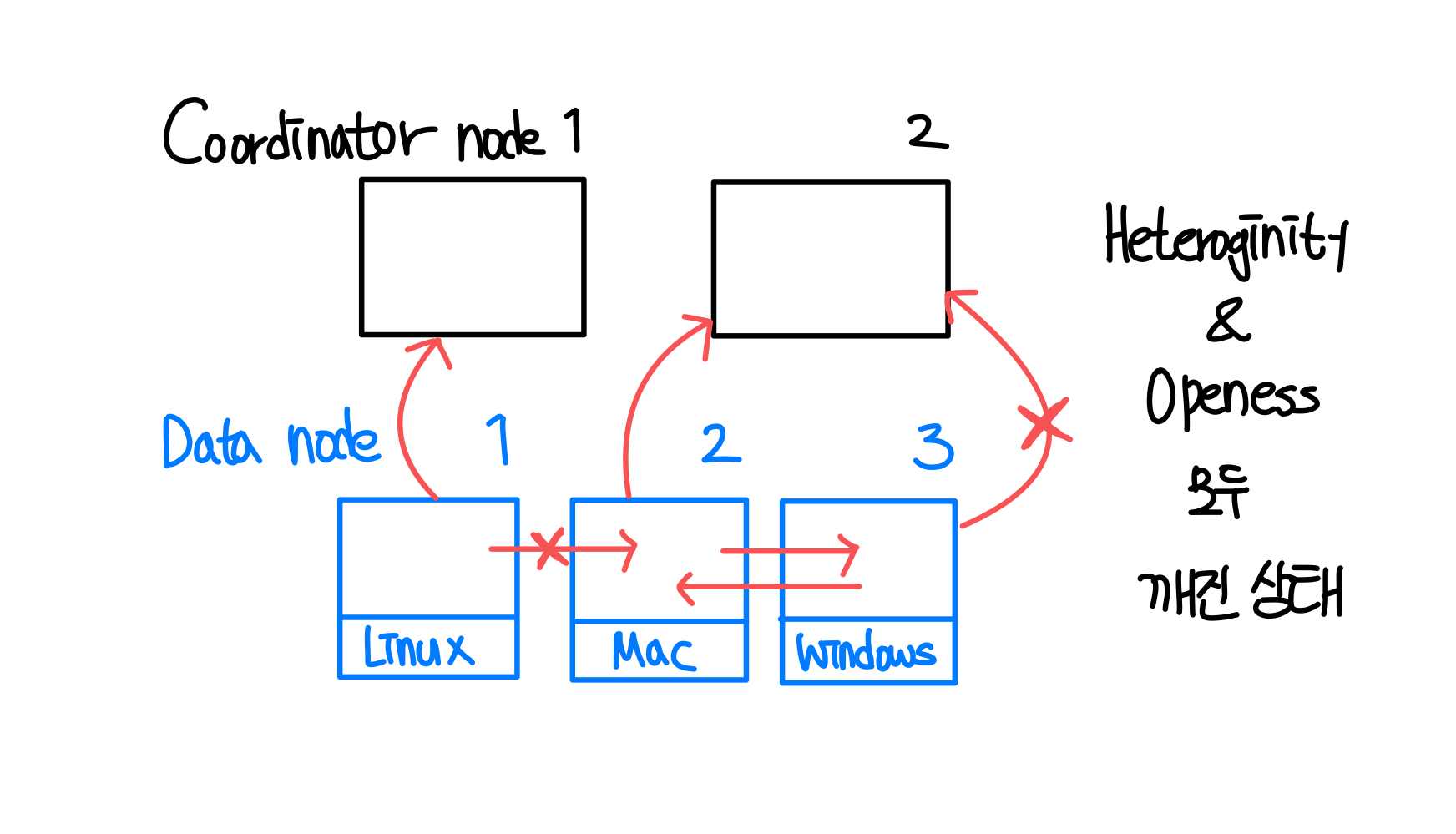
프로토콜(약속) 기반의 상호 통신 기능, 동작이 동일해야 한다!!
3️⃣ Security
- 권한 제어, 접근 제어 등이 가능해야 한다. 프로토콜 정의/이용해서 구현.
- Security 평가 구성 요소
- Confidentially : 권한이 없다면 공개 불가
- Integrity : 허가되지 않은 방법으로 변경할 수 없다
- Availability : 권한이 있다면 접근 가능
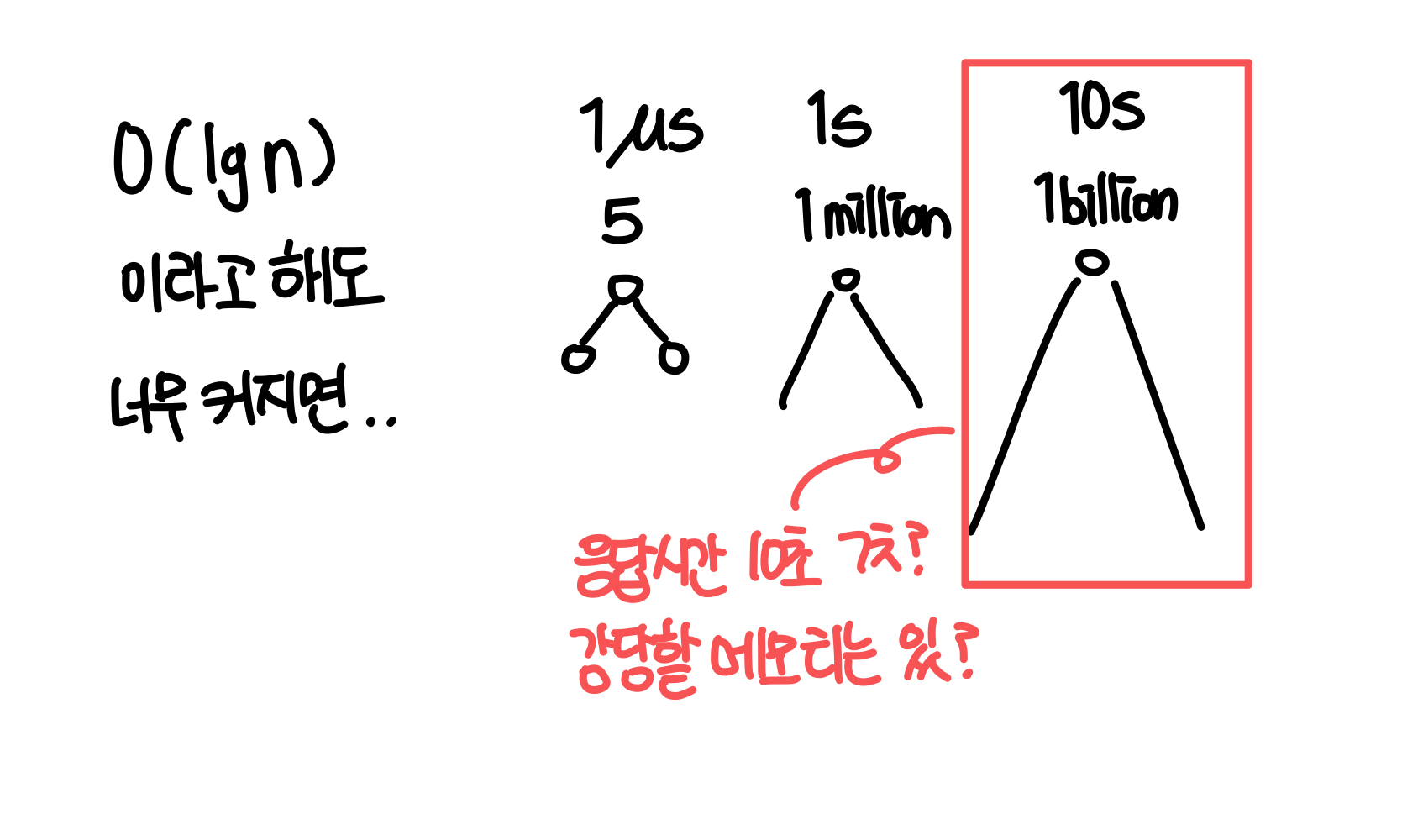
4️⃣ Scalability ⭐️
- 시스템 자원이나 사용자 수에 따라서 확장 가능
- scale up 불가능 ➡️ 수평적 확장 방법
- 확장을 통해서
- 성능이 좋아지거나
- 처리량이 많아지거나
- 가용(capacity)이 높아져야 한다 (ex. 용량, 서빙 유저 수)
- Scalability 달성을 위한 문제(Challenges)
1️⃣ 물리적인 리소스에 대한 비용 (Controlling the cost of physical resources)
: n명의 사용자 > 실제로 O(n)만큼 자원 필요
2️⃣ 성능 손실(Controlling the performance loss)
: 데이터 양이 너무 커졌을 때 성능 손실, 자원
 3️⃣ 자원 한계로 인한 제약 (Prevent software resources running out)
3️⃣ 자원 한계로 인한 제약 (Prevent software resources running out)
: 자원 때문에 할 수 있는 것에 제약이 생길 수 있다
( ex : IP 주소 32비트 사용 -> 128비트 사용 불가)
4️⃣ 성능에 의한 Bottleneck (Avoiding performance bottleneck)
: 여러 역할 상호작용 -> 하나가 성능 지연, 손실 -> 전체에 영향
5️⃣ Failures Handling
- 장애/실패에 대한 대응을 (자동화된 방식으로) 할 수 있어야 한다.
- 대응 방식 절차
- Detecting failure
- Masking failure
- Tolerating failure (ex : 복제본 생성)
- Recovery failure (ex : 제 3노드에 복제된 내용 띄우고 친구 노드)
- Redundancy
6️⃣ Concurrency
- 여러 클라이언트가 하나의 공유 자원에 접근하는 등의 동시성에 대한 문제
- 여러 처리에 대해서 (상태의 간섭 없이) 병렬 처리
- 분산환경에 있는 shared resource를 표현하는 대상은 자신의 상태에 대해서 확실히 표현
(ex. 이 데이터는 이용할 수 없는 상태이다, 복제가 안 돼서 불안정하다 ...) - 동시성 환경에 안전하려면 하나의 리소스는 consistent한(확정적인) 상태로 동기화되어야 한다.
( ex. inconsistent한 상태에서 동기화되어서 active한 자원을 참조하게 되면 문제가 생긴다. )
7️⃣ Transparency ⭐️⭐️
- 사용자로부터 내부에 있는 정보를 보이지 않게 하고 다음과 같은 투명성 달성
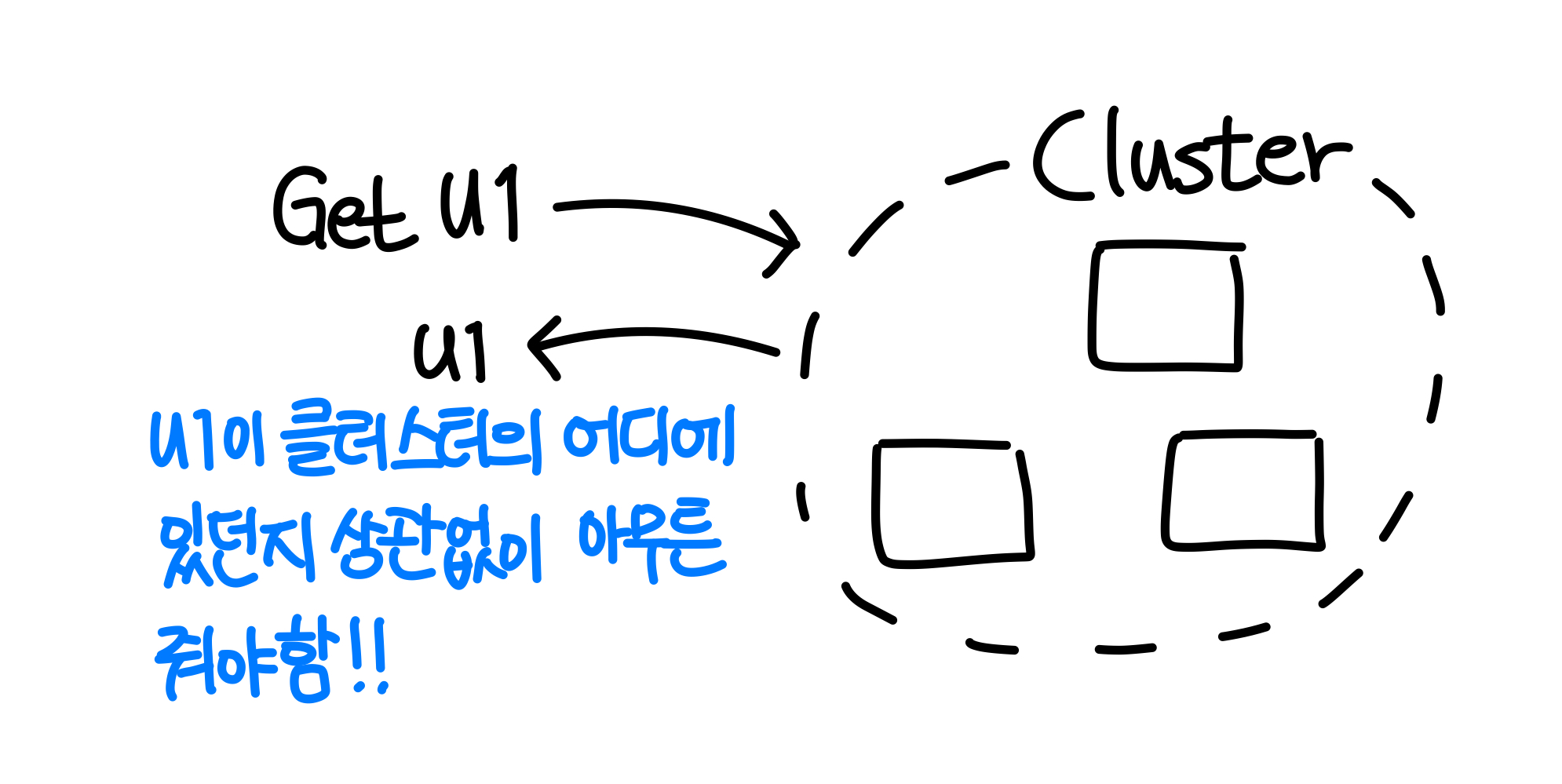
- 1️⃣ Access transparency
: 로컬이든 리모트이던 동일한 오퍼레이션
- 2️⃣ Location transparency
: 내부, 외부 위치에 상관 없이 오퍼레이션 수행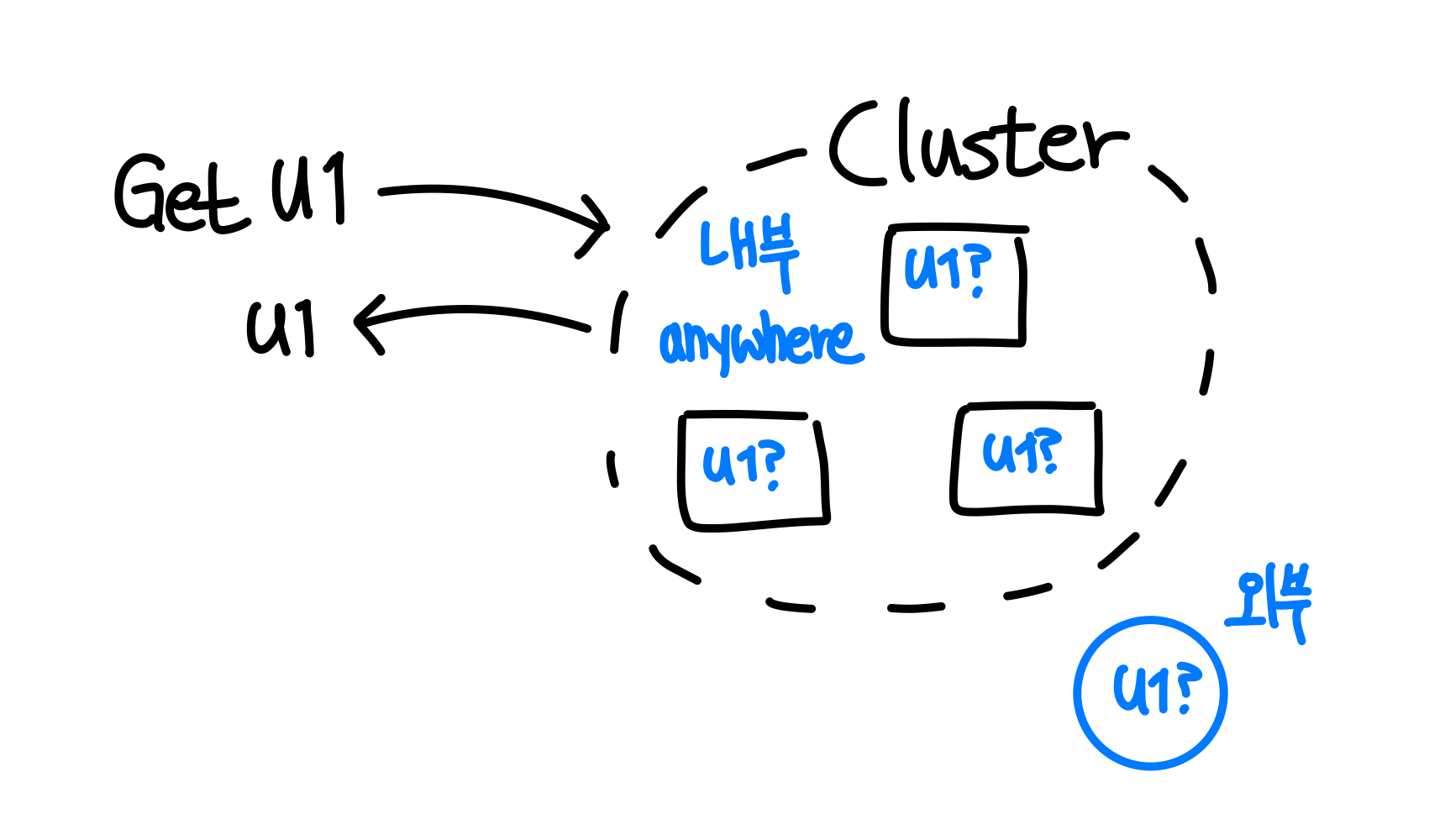
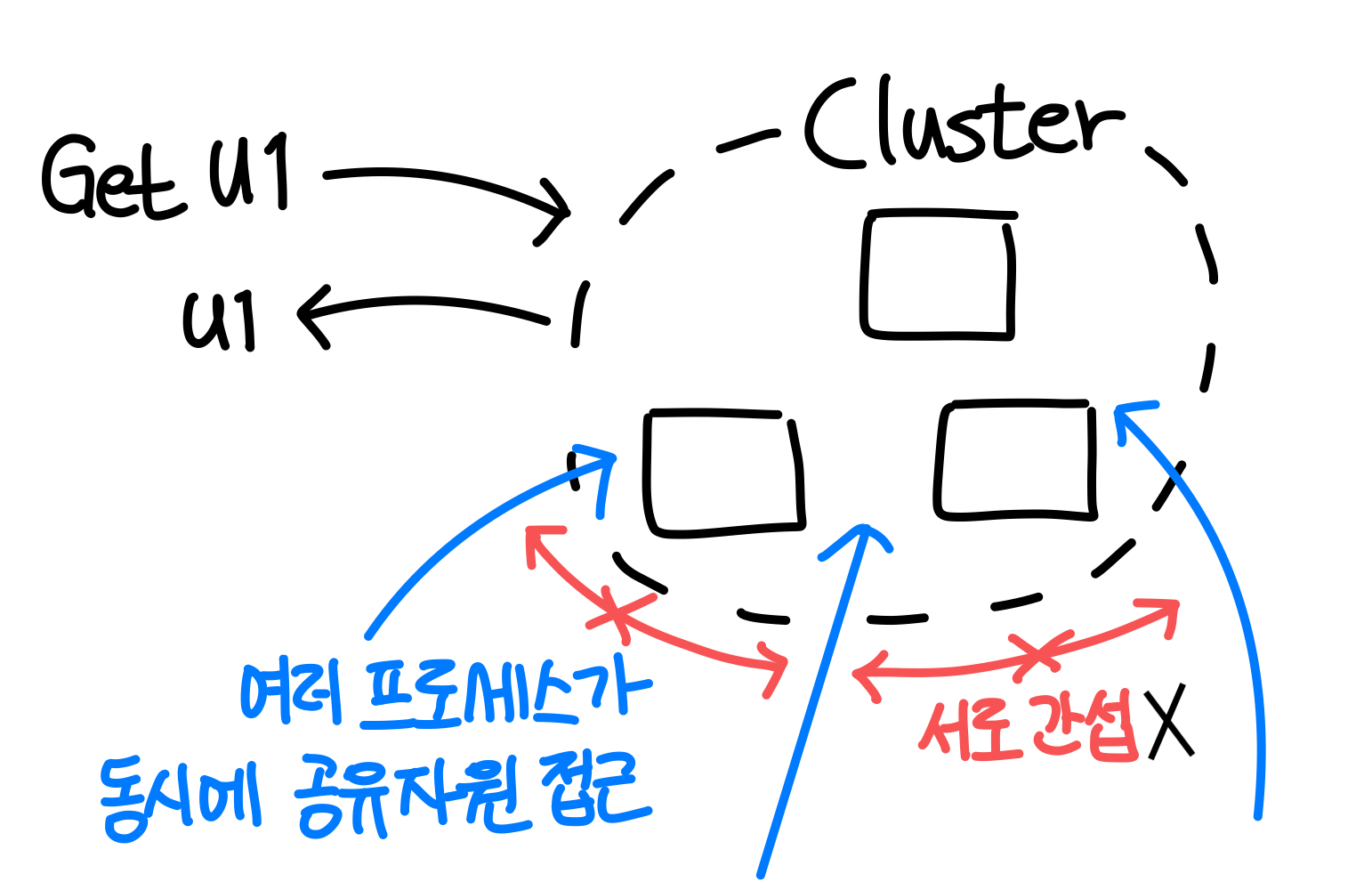
- 3️⃣ Concurrency transparency
: 여러 프로세스가 공유 자원에 접근할 때 다른 접근들의 상태, 응답 여부 등에 간섭받지 않고 이뤄져야 한다.
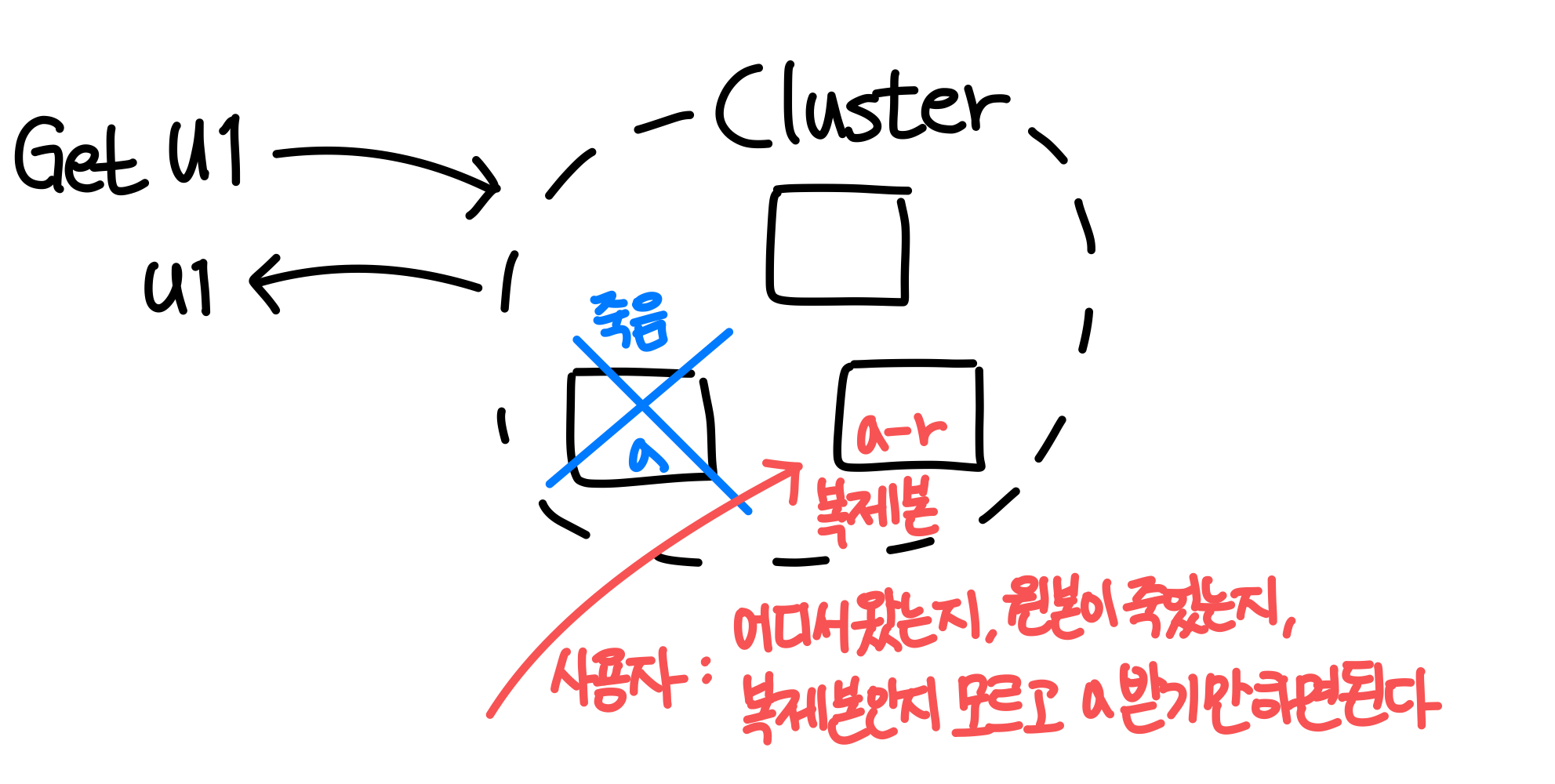
- Replication transparency
: reliability를 높이기 위해서 어떤 리소스의 복제본을 다른 곳에 저장해서, 하나가 죽어도 복제본을 저장해둔 다룬 곳에 저장할 수 있게 해둔다. 사용자 입장에서는 어떤 것이 죽었는지, 살았는지, 복제본인지, 어디서 왔는지 등은 모르고 원하는 리소스만 얻으면 된다.
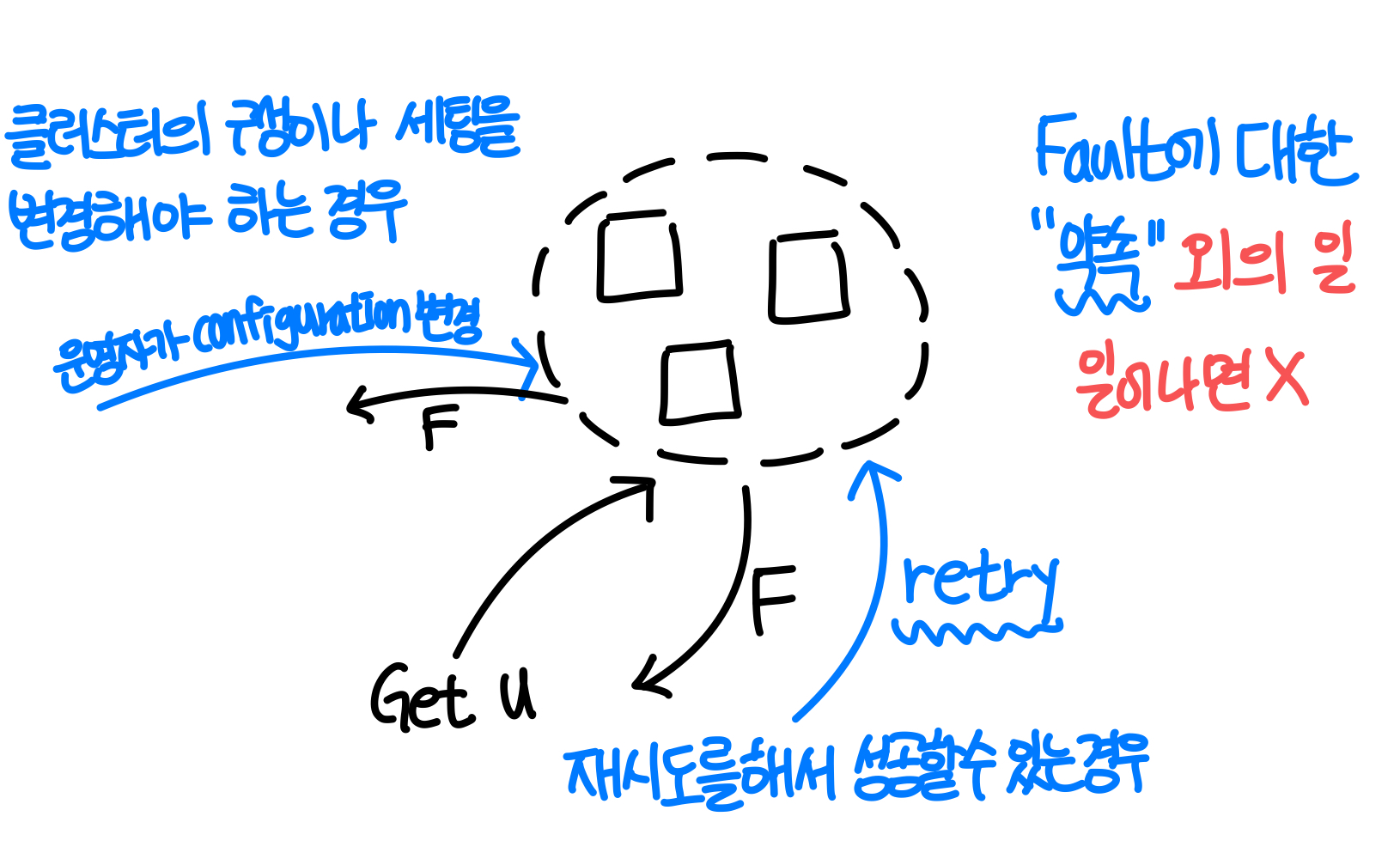
- Failure transparency
: 실패에 대해서 사용자가 일관되게 사용할 수 있도록, 신뢰할 수 있는 프로그램 만들어야 한다. Fault에 대한 약속이 있고, 유저는 어떤 실패인지에 따라서 다음 프로그램을 짤 것이기 때문이다.
ex) 약속된 것과 달리 특정 동작 필요- 리트라이가 아니라 실제 하드웨어 내용을 알고 (약속과 달리) 특정 하드웨어 설정을 바꿔야 하는 경우
- Rebalnce 실패 문제에서, 실제로는 HW fault 때문에 Rebalance가 일어나지 않았던 경우
- Mobility transparency
: 실제로 리소스가 이동해야하는 경우, 사용자는 이에 영향(DNS 주소, 접근 API을 받지 않고 이용한다.
(부분적으로 알도록 프로그래밍해야하는 경우가 있긴 해도 라이브러리 영역까지, API 영역에서는 일관되도록) - Performance transparency
: 로드가 일어났을 때, 내가 성능을 개선하기 위해 설정할 수 있어야 한다. 그리고 그 설정이 live하게(= 재기동,혹은 일부 기능 제한 없이) 적용되는 게 좋다. - Scaling transparency
: 클라이언트가 이용하려는 대수가 몇 대로 늘어나던지에 상관 없이, 시스템의 기본적인 피처, 구조, 할당 방식은 동일해야 하며 사용자가 이를 일관되게 이용할 수 있어야 한다.

가볍게 재밌던 거 기록해요