Event Sourcing Pattern
상황 설정
[1] 주문 요청
↓
[2] 재고 체크
↓
[3] 결제
↓
[4] 배송 준비 / 알림 발송
위와 같은 서비스를 구성한다고 하자.
기본 시스템 설계
테이블 뚝딱
Table
[orders 테이블]
- 주문 정보 저장
- status 컬럼으로 주문 상태 관리 (ex. ORDERED, PAYMENT_COMPLETED, PAYMENT_FAILED)
[order_items 테이블]
- 주문에 포함된 상품 정보 저장
- order_id 기준으로 여러 상품 연결
[stocks 테이블]
- 상품별 재고 수량 관리
- 재고 차감, 재고 복구 처리
[payments 테이블]
- 결제 시도 & 결과 저장
- PG사 거래 번호, 결제 수단, 결제 금액 등 기록
[deliveries 테이블]
- 배송 상태 저장1. 주문 생성 → orders insert
2. 재고 확인 → stocks select
3. 재고 차감 → stocks update
4. 결제 시도 → payments api 호출
5. 결제 성공 → orders update (status=PAYMENT_COMPLETED)
6. 결제 실패 → orders update (status=PAYMENT_FAILED)
6. 배송 생성 → deliveries insert문제점
- 결제는 외부 API잖아?
PG사 API 호출이 실패하거나 느리거나 응답 안 오거나…
근데 이미 DB에 주문 insert 해버림.
→ 주문은 생겼는데 결제 안 됨.
→ 유저는 주문 했다고 착각.
→ VoC 폭발
- 반대로 이런 경우도 있다.
PG 결제는 성공했는데
DB insert/update 실패…
??? 돈은 나갔는데 주문이 없다 ???
결제 취소 요청 넣어야 하고,
PG사 연락해야 하고,
서비스 로그 파면서 눈물의 야근.
- 상태 추적 지옥
그나마 status 컬럼 하나로 상태는 관리하는데…
나중에 이런 요구사항이 들어온다.
- 언제 결제 시도했는지?
- 언제 실패했는지?
- 몇 번 시도했는지?
- 결제 실패 이유는 뭐였는지?
…
“로그 보세요…”
- 동기적 처리로 인한 응답시간 증가
- 동시에 많은 insert, update가 수행되면 그 만큼 트랙잭션 길어짐
- 하루 종일 db lock wating
이러다가 나는 깨달았다.
“아 CRUD 만으로는 못 버틴다.”
Outbox Pattern
한 마디로 요약하면 이거다.
“DB Insert 할 때 이벤트 로그도 같이 Insert 해버리자”
DB Insert → Commit 성공 → Outbox 테이블 읽어서 Kafka 발행
이렇게 설계하면 DB와 Kafka 사이 정합성이 거의 완벽해진다.
[outbox 테이블]
- id
- aggregate_id (ex. 주문번호)
- event_type (ex. ORDER_CREATED)
- payload (json 데이터)
- status (READY / SENT / FAIL)Command (ex. 주문 생성 요청)
↓
Event Emit (OrderCreated)
↓
Kafka Publish
↓
각 서비스가 Subscribe
- StockService → 재고 차감
- PaymentService → 결제 시도
- NotificationService → 알림 발송
↓
각 서비스는 처리 결과 Event Emit
- StockHeld
- PaymentCompleted
- PaymentFailed
↓
OrderService 는 Event 기반으로 상태 전이만 관리Outbox 패턴은 좋은데, 한계가 분명하다
처음 서비스를 설계할 때, 상태 변화가 일어나면 그걸 이벤트로 발행하는 건 이제 거의 기본처럼 여겨진다. 문제는 여기서 발생하는 “DB와 Kafka 간 데이터 정합성”이다.
예를 들어, 주문 데이터를 DB에 저장하고 Kafka로 이벤트를 발행한다고 해보자. DB 저장은 성공했는데 Kafka 발행이 실패하면? 또는 Kafka 발행은 성공했는데 DB 저장이 실패하면? 서비스가 커지면 이런 문제가 현실에서 반드시 발생한다.
그래서 등장한 게 Outbox 패턴이다.
Outbox 패턴은 뭘 해결해주는가?
Outbox 패턴은 단순하다.
DB Insert 또는 Update와 Kafka Publish를 하나의 트랜잭션처럼 묶어주는 패턴이다.
구조는 이렇다.
1. 비즈니스 데이터(DB)에 Insert
2. Outbox 테이블에 이벤트 Insert (같은 트랜잭션)
3. 트랜잭션 Commit
4. 별도의 Worker가 Outbox 테이블을 주기적으로 읽어서 Kafka Publish
5. 발행 성공 → Outbox 테이블 상태 변경 (SENT)
이 방식의 최대 장점은 데이터 정합성이다.
DB 저장과 Kafka 발행을 완전히 분리하면서도 싱크는 확실하게 맞출 수 있다.
Outbox 패턴의 장점은 분명하다
- DB와 Kafka 데이터 불일치 문제 해결
- 기존 CRUD 기반 시스템에도 쉽게 적용 가능
- 상태 변화가 단순한 서비스에서는 비용 대비 효과가 좋다
- 장애 상황에서도 Outbox 테이블만 조회하면 재처리가 쉽다
- 설계가 어렵지 않고, 기존 시스템 구조를 크게 바꾸지 않아도 된다
이런 이유로 대부분의 서비스 초반, 혹은 단순한 데이터 처리에서는 Outbox 패턴만으로 충분하다.
그런데 Outbox 패턴으로 해결 못하는 영역이 있다
Outbox 패턴을 쓰다 보면 점점 이런 상황이 온다.
1. 상태 변화가 복잡해지면서 Outbox 이벤트가 너무 많아진다
2. 장애 상황 처리 로직이 점점 if else 지옥이 된다
3. 보상 트랜잭션이 많아지고 관리가 어려워진다
4. 과거 상태를 복원하거나, 히스토리를 추적할 수 없다
Outbox는 어디까지나 DB Insert → Kafka Publish 싱크 문제만 해결해줄 뿐이다.
그런데 복잡한 주문/결제/정산/물류 같은 도메인은 상태 변화 자체가 엄청 많고, 그 상태 변화의 히스토리가 진짜 중요한 경우가 많다.
이때 Outbox로 계속 때우기 시작하면 이런 느낌이 된다.
"Kafka는 쓰는데 설계는 여전히 모놀리식처럼 동작한다…"
Event Sourcing Pattern이란?
Event Sourcing ensures that all changes to application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
데이터 저장에 대한 방법론인다.
일반적인 데이터 저장 방식은 최종 상태만을 관리하며 중간 과정을 알 수가 없다.
Event Sourcing Pattern은 모든 데이터가 변경되는 일련의 과정을 기록하면 그 기록을 통해 서비스를 구성하는 방법이다.
데이터 저장에 있어서 update, delete 없이 오직 insert를 사용해 데이터를 관리한다.
서비스 설계라는 게 참 그렇다.
처음엔 CRUD로도 충분하다.
조금 더 가면 Outbox Pattern으로 데이터 정합성도 지킨다.
근데 서비스가 커지면 진짜 본질적인 문제가 남는다.
"데이터를 어떻게 믿을 건데?"
"상태 꼬이면 어떻게 복구할 건데?"
"상태 변화의 히스토리는 어디있는데?"
이 지점에 오면 기존 방식으로는 답이 안 나온다.
그리고 바로 여기서 등장하는게 Event Sourcing이다.
Event Sourcing Flow
Command : "주문 생성"
↓
Event : "OrderCreatedEvent" 저장
↓
Event Store (Append Only)
↓
Projection : 현재 상태 테이블 구성
↓
Kafka Publish : 이벤트 발행그래서 뭐가 좋아지는 건데?
- 과거 상태 그대로 보존
- 어떤 이벤트가 있었는지 전부 저장됨
- 데이터 복구 → Event Replay 하면 끝
- 장애 복구 난이도 ↓
- 서비스 간 의존성 최소화
- 직접 호출 없이 Event 기반 처리
- 각 서비스는 Subscribe 만 하면 됨
- 히스토리가 데이터
- 상태 변화 타임라인 자동 제공
- VoC 대응, 감사 로그, BI 분석 최강
- 이벤트 기반 시스템 설계 최적화
- CQRS 패턴과 찰떡
- Kafka / EventStore 기반 구조 자연스럽게 정착
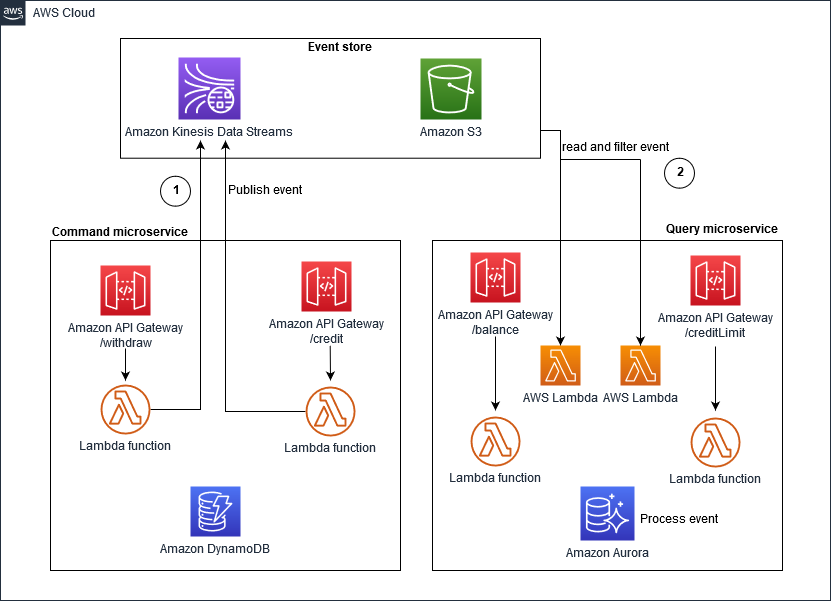
AWS가 제시하는 기본 모델
보통 CQRS가 기본 패턴이다.