
들어가며
이 글은 이전 글에서 언급되었던 DeepLabCut을 실제로 실습해보고 그 과정에서 발생한 여러 문제점과 이에 대한 저의 대처를 기록한 글입니다. DeepLabCut에 대한 맥락이 궁금하시다면 관련 글 [Research Note] Decoding Animal Actions: How Machines Learn Behaviour를 읽어주시면 감사하겠습니다.
0. 실습 개요

이번 실습은 DeepLabCut을 고안해낸 mackenziemathislab 팀에서 제공하는 COLAB_DEMO_SuperAnimal을 기반으로 하여 실습 목적과 방향성에 따라 수정하여 진행하였습니다.
1. 환경 선택 (Google Colab vs. Local)
초기에는 실제로 라이브러리를 다운로드하여 실행해보고자 하는 의도로 로컬 환경(Windows + venv)에서 실습을 진행했지만, 아래와 같은 경로 오류로 실행이 중단되었습니다.

이는 Windows 경로 길이 제한 및 Hugging Face 모델 캐시 구조 문제로 판단되었고, 특히 경로 길이 제안을 해결하기 위해 경로를 사전에 저장해보는 등 여러 방법을 시도했지만 진척이 없었기에,
이후 Google Colab 환경으로 옮겨 진행하게 되었습니다. 문제 해결의 지연이라는 이유 외에도 지금 활동의 목적인 DeepLabCut의 실습을 빠르게 진행하기 위해서 모델의 문제 외에 초기 설정 단계에서 시간을 소비할 이유가 없다고 생각했기 때문입니다.
하지만 로컬의 컴퓨팅 자원을 활용하는 방법도 충분히 괜찮다고 생각했기에 Google Colab 환경도 문제가 생긴다면 다시 로컬을 시도해보기로 결정했습니다.
"역시 실습과정에서 제일 어려운 부분은 초기 셋업이다"
2. 실습 중 발생한 문제
1. Adapting과정에서 발생하는 GPU 폭발
펑!
(GPU 15GB가 터지는 소리)
OutOfMemoryError: CUDA out of memory.
Tried to allocate 2.00 MiB. GPU 0 has a total capacity of 14.74 GiB of which 2.12 MiB is free.
Process 18853 has 14.74 GiB memory in use.
Of the allocated memory 14.55 GiB is allocated by PyTorch, and 58.91 MiB is reserved by PyTorch but unallocated.
If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation.
See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
- Fine-tuning 단계(
video_adapt=True)에서 GPU 메모리 부족 오류가 발생했었습니다.
이는 Colab의 기본 T4 GPU가 DeepLabCut의 adaptation 과정에서 사용하는 HRNet/FasterRCNN 모델을 감당하지 못했기 때문입니다. 하지만 Google Colab에서 GPU 추가 결제는 아직 계획에 없었기에 저는 video adaptation 과정은 과감히 생략하고, 기본 pretrained 모델로 inference만 수행을 해봄으로써 전반적인 흐름을 배우고자 하였습니다. (하지만 뒤에서 언급된 문제점으로 인해 결국 작은 단위의 adaption을 진행하게 되었습니다.)
2. 모델 성능 문제
테스트 영상은 다람쥐 동영상이었습니다. DeepLabCut에서 사용가능한 모델 중 사족보행 동물에 대한 모델이 있기도 했고, 저작권 문제가 없는 무료 동물 동영상을 찾던 중
1. 해당 동물의 전신이 나오며, 2. 귀여워서 실습의 동기를 부여한다 라는 두가지 기준을 가지고 판단한 결과였습니다.

모델 설정:
superanimal_name = "superanimal_quadruped"
model_name = "hrnet_w32"
detector_name = "fasterrcnn_mobilenet_v3_large_fpn"
pcutoff = 0.15 #@param {type:"slider", min:0, max:1, step:0.05}
사족동물이기에 quadruped 모델을 선택해 pose estimation을 진행하였고 나머지는 기본 설정 그대로 진행하였습니다. 하지만 결과는 대부분의 keypoint가 -1.0으로 기록되어 매우 낮은 신뢰도를 보였습니다.
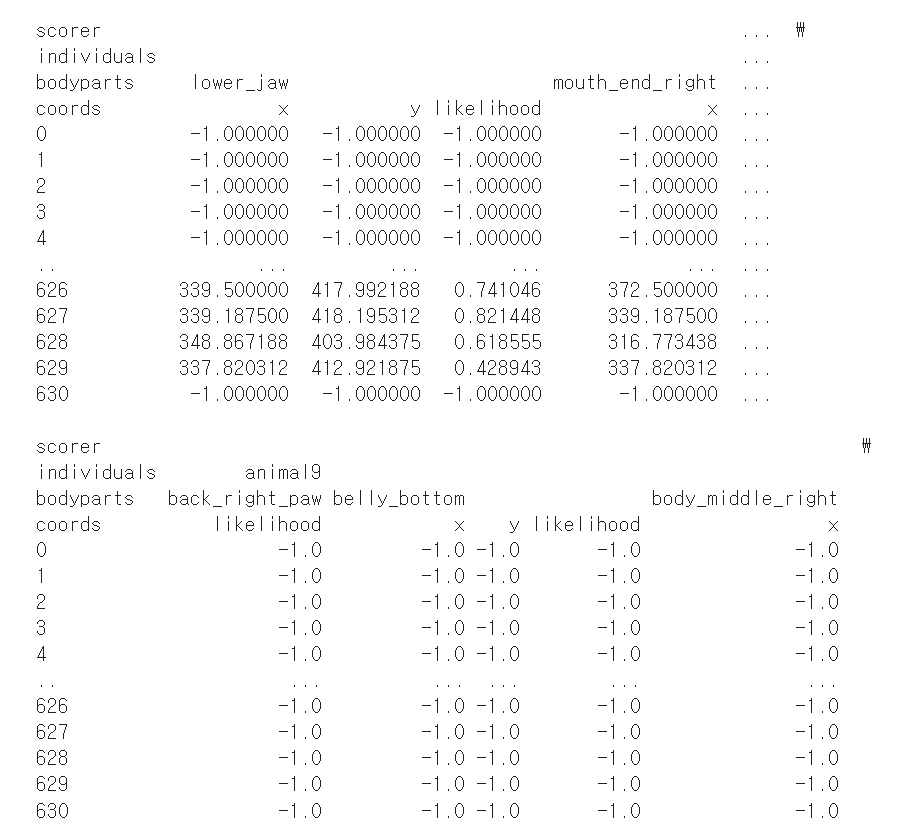
위 사진은 실제 학습 결과 중 일부인데 물론 모든 값들이 객체탐지가 실패한건 아니지만 출력된 결과만 보기에는 -1.000000 (탐지 실패)가 많이 보였기에 모델 문제인가 싶어 rtmpose_s 모델 (RTMPose 기반 모델(superanimal_quadruped_rtmpose_s))을 선택하였는데, 이유는 다음과 같았습니다.
RTMPose 모델은 MMPose (MMDetection 기반) 계열 중 실시간 추론(Real-Time Inference) 과 고정밀 추정(Accurate Pose Estimation) 사이의 균형을 잡기 위해 설계된 모델이고, 그 중 _s 버전은 “small”의 약자입니다. 그렇기에
경량 구조로 Colab이나 일반 GPU 환경에서도 메모리 부담이 적음
고속 추론이 가능하므로 frame 단위 분석에 적합
HRNet, ResNet 기반 모델에 비해 적은 연산량으로 근사한 정확도
라는 세가지 근거로 성능을 향상시키면서 Colab 환경에서 앞서 맞닥뜨린
OutOfMemoryError를 피하기 위해서는 이 모델이 상대적으로 안정적인 선택이라고 생각했습니다.
superanimal_name = "superanimal_quadruped" #@param ["superanimal_bird","superanimal_topviewmouse", "superanimal_quadruped"]
model_name = "rtmpose_s" #@param ["hrnet_w32", "resnet_50", "rtmpose_s"]
detector_name = "fasterrcnn_mobilenet_v3_large_fpn" #@param ["fasterrcnn_resnet50_fpn_v2", "fasterrcnn_mobilenet_v3_large_fpn"]
pcutoff = 0.15 #@param {type:"slider", min:0, max:1, step:0.05}
실행 결과 점수(likelihood)는 여전히 낮았지만, 두 모델의 실제 출력된 동영상을 확인해보면 결과에서는 다람쥐의 형체를 어느 정도 인식한다는 것을 확인할 수 있었습니다.


점수표와는 다르게 실제로는 다람쥐라는 객체를 어느정도 인식하고 대략적인 동물의 구조적 특징에 대해 학습하는 것 "처럼" 보인다.
이로부터, “score가 낮더라도 예측된 포즈는 시각적으로 타당할 수 있다”는 관찰을 얻었습니다. 이는 모델 confidence와 실제 spatial accuracy 간의 괴리 가능성을 시사하는 듯 했습니다.
그렇기에 저는 왜 이런 괴리가 발생할까 의문을 가졌고, likelihood score가 낮더라도 결과값의 정확도는 높을 수 있다라는 직관을 얻을 수 있는건지 아니면 그냥 우연히 잘 맞는 것처럼 보일 뿐인건 이를 확인하기 위해 먼저 실제 score의 흐름을 시각화해보았습니다.
import pandas as pd
import matplotlib.pyplot as plt
import json
# JSON 파일 로드
with open("/content/squirrel_superanimal_quadruped_rtmpose_s_fasterrcnn_mobilenet_v3_large_fpn__before_adapt.json", "r") as f:
data = json.load(f)
df = pd.DataFrame(data)
# bbox_scores 처리: 리스트일 경우 평균값으로 변환
def extract_mean_score(x):
if isinstance(x, list):
return np.mean(x) if len(x) > 0 else np.nan
elif isinstance(x, (int, float)):
return x
else:
return np.nan
if "bbox_scores" in df.columns:
df["bbox_score_mean"] = df["bbox_scores"].apply(extract_mean_score)
else:
raise ValueError("bbox_scores 컬럼을 찾을 수 없습니다. JSON 구조를 확인하세요.")
# 시각화
plt.figure(figsize=(12, 5))
plt.plot(df["bbox_score_mean"], color="blue", linewidth=1)
plt.xlabel("Frame in timeline")
plt.ylabel("Mean Bounding Box Confidence")
plt.title("The change of the likelihood in object detection in timeline (average bbox_scores)")
plt.grid(True)
plt.show()
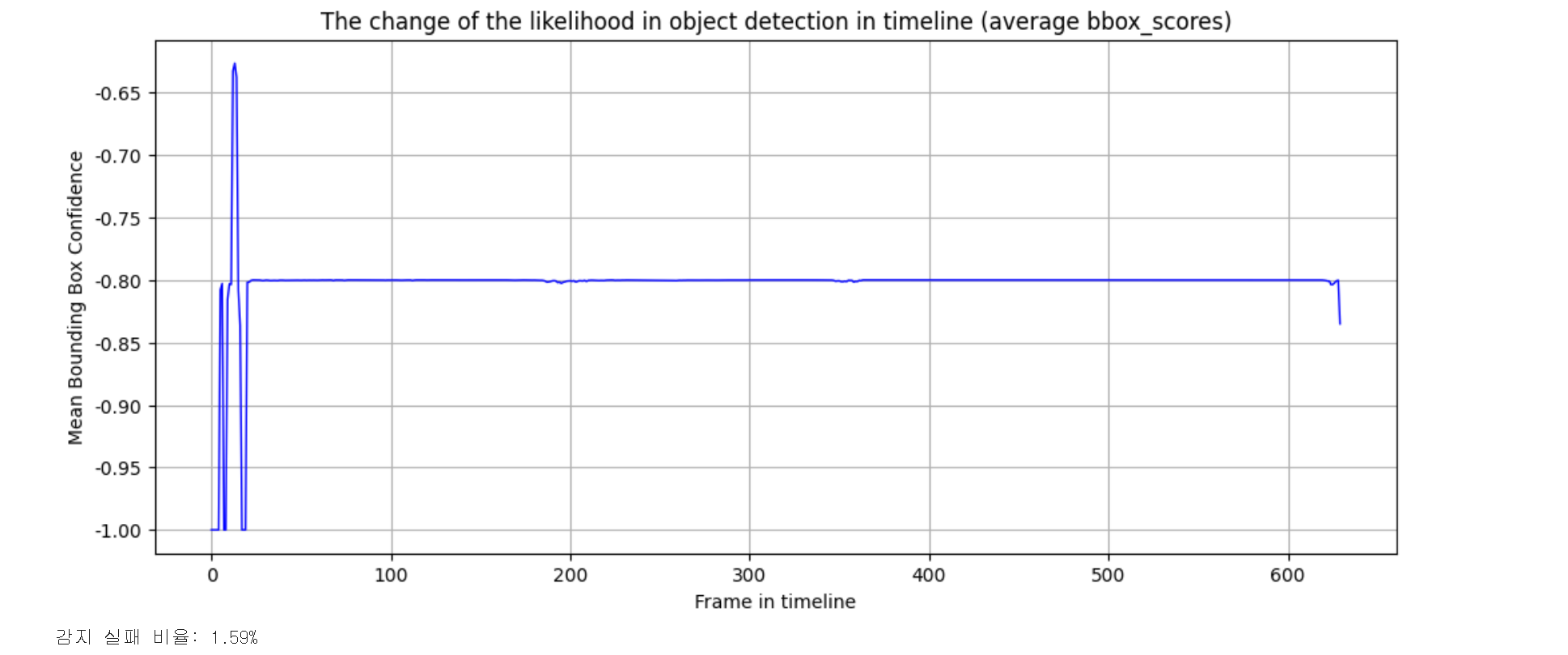
이런 방식으로 사용한 두 모델에 대해 모두 나타내 보았는데, 실제로는 해골물로 유의미한 차이가 존재하지않고 거의 동일하게 성능이 저조하다는 것을 알게 되었습니다.

또한 예상은 했지만 -1.0값이 너무 많다보니 평균으로 계산하다보니 세로축에 표시된 실제 값의 의미는 거의 없고 실제 점수의 변화 양상을 파악하는데 의미가 그쳤습니다. 하지만 눈에 띄는 부분은 object detection 감지 자체는 잘 이루어지는 것 같이 보인다라는 점입니다. (감지 실패 비율: 1.59%)
3. 개선사항
그러면 이제 시선은 역시 초반에 터진 GPU를 지키면서 Adaption을 하는 방법으로 돌리게 됩니다. GPU를 지키면서 최대한 성능을 끌어올리는 방법이 없을까 parameter들을 뒤적여보면서 아래와 같이 최적화를 시도해보았습니다.
모델은 다람쥐에 대해 특화된 모델과 같이 성능 향상에 영향을 줄 만큼 특화된 모델이 없었기 때문에 그대로 유지했습니다.
superanimal_name = "superanimal_quadruped"
model_name = "hrnet_w32"
detector_name = "fasterrcnn_mobilenet_v3_large_fpn"
pcutoff = 0.15
videotype = video_path.suffix
scale_list = []
os.environ["TORCH_BACKEND_FUSE_BN_RELU"] = "0" # 배치 정규화 관련 fused 연산 비활성화 (안정성↑)
deeplabcut.video_inference_superanimal(
[video_path],
# 사용할 SuperAnimal 모델 이름 -> 유지
superanimal_name,
# 포즈 추정용 백본 모델 -> 유지
model_name=model_name,
# 객체 탐지용 모델 -> 유지
detector_name=detector_name,
# keypoint 최소 신뢰도 (잡음 제거) -> 유지
pcutoff=pcutoff,
# 비디오 적응 학습 활성화 (fine-tuning)
video_adapt=True,
# 적응 학습 반복 횟수 (속도-정확도 절충을 위해 기존 150에서 100으로 절감)
adapt_iterations=100,
# 객체 탐지기 학습 epoch (최소 수준의 fine-tuning)
detector_epochs=2,
# 포즈 추정기 학습 epoch (최소 수준의 fine-tuning)
pose_epochs=2,
# 적응 학습 배치 크기 (VRAM 절약)
video_adapt_batch_size=1,
# 추론 시 배치 크기 (VRAM 절약)
batch_size=1,
# 탐지 단계 배치 크기 (VRAM 절약)
detector_batch_size=1,
# 단일 개체만 추적설정 (불필요한 검출과 자원 소모 방지)
max_individuals=1,
# 탐지 신뢰도 임계값 구체화 (정확도↑, 오검출↓)
bbox_threshold=0.9,
# 탐지 박스 시각화 비활성화 (VRAM 절약)
plot_bboxes=False,
)
결과는 아래와 같이 비디오에서는 시각적으로 차이를 짐작하기 어렵지만 그래프를 통해 바라보았더니 likelihood는 상당히 향상되고 감지 실패 비율은 감소한 것을 확인할 수 있었습니다.
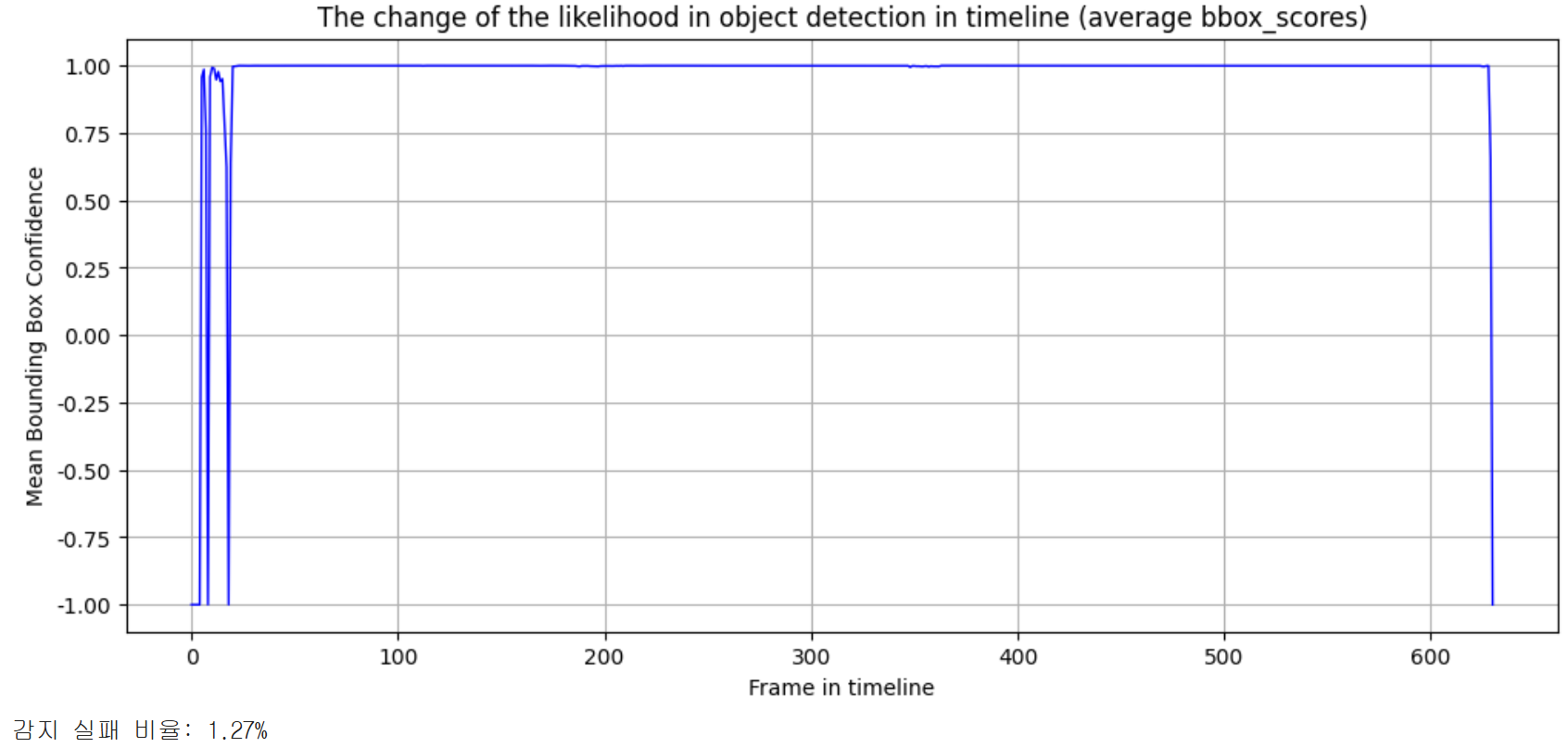

기존에 빨간 테두리 박스로 표시되던 객체 검출은 VRAM의 사용을 줄이기 위해 제외하였습니다.
결론
아쉽게도 GPU용량의 한계와 이 이상 튜닝할 방법에 대해 떠오르지 않아 이 이상의 개선은 이어나가지 못했습니다. 하지만 아래와 같이 더 탐구할 수 있는 질문들이 남았다고 생각합니다.
- 만약 사전에 미리 몸의 구조를 알고 이를 configuration file에 넣어 사전 학습 데이터를 풍부하게 했다면?
- GPU의 사용량이 최종적으로 1.5GB를 사용했는데, 그렇다면 adaption_iteration을 더 효과적인 크기로 돌릴 수 있지 않았을까?
이 질문들은 조금 더 공부후에 다시 한번 답해보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다.
