부스트코드 '자바로 구현하고 배우는 자료구조'정리
1주차 - 자바 특성 및 알고리즘 기본
1.복잡성
(1) 자료구조란?
종류 - Array, Linked List, Stack&Queue, Hash Table, Tree
자료 형태
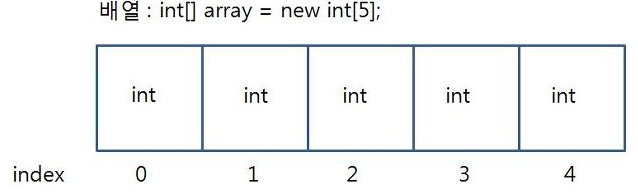
- Array
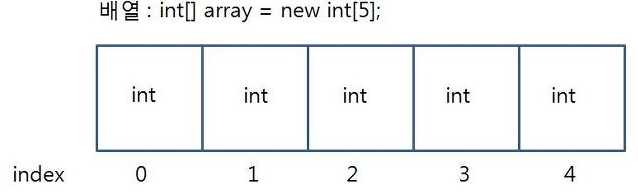
실제 코드)
int[] score = new int[4];
score[0] = 90;
score[1] = 80;
score[2] = 70;
score[3] = 60;출처 - https://kpopbloging.tistory.com/88
-
Linked List
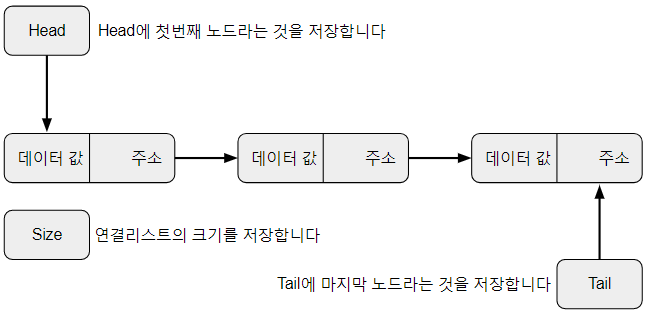
-코드가 긴 관계로 참고가 되는 사이트를 올립니다.
LinkedList 출처 - https://freestrokes.tistory.com/84 -
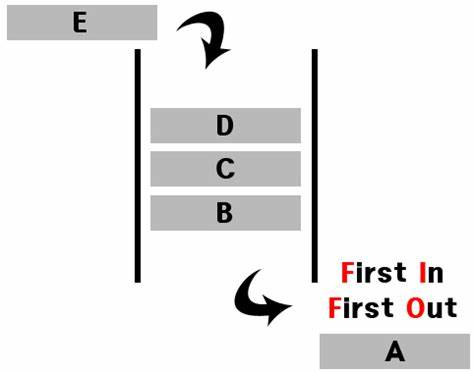
Stack&Queue
-Stack(Last Input First Output)
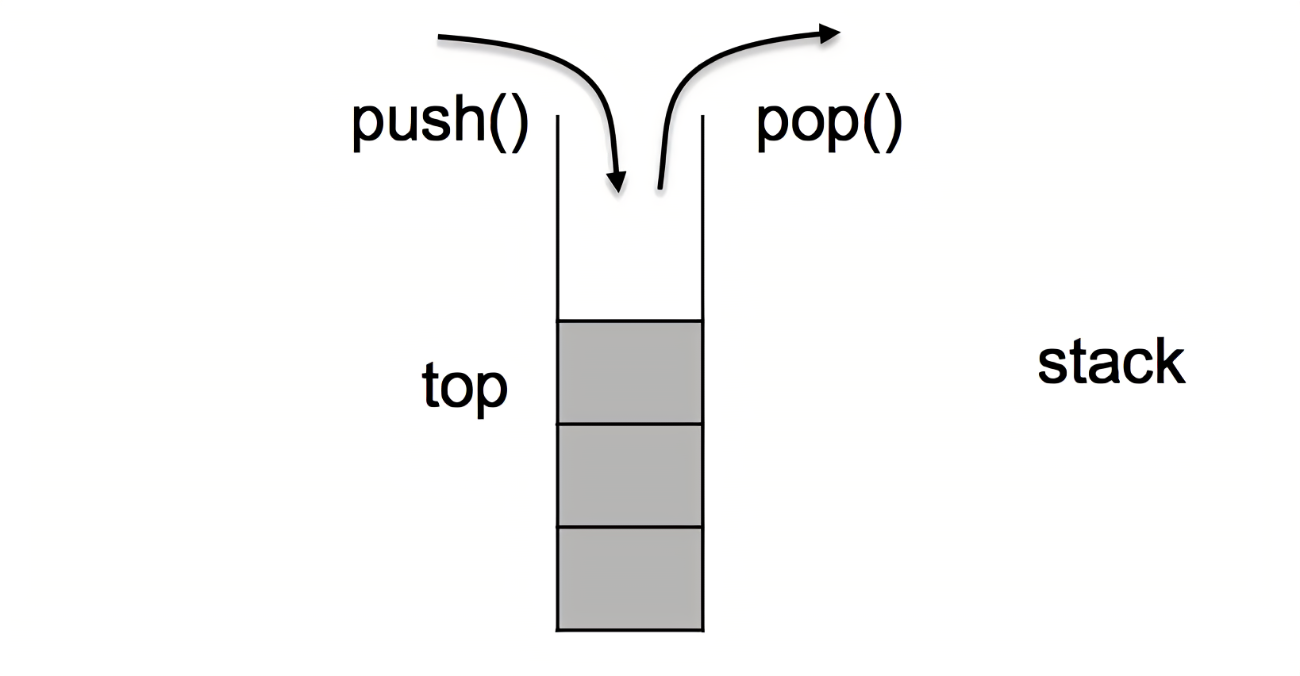
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class StackQueueTest {
public static void main(String[] args) {
Stack<String> stack = new Stack<String>(); //Generics을 이용하여 Collection이 저장할 데이터 타입 지정
for(int i=0;i<3;i++)
stack.push("Hi-"+i); //stack에 데이터를 삽입하는 문장
//stack = ["Hi-0", "Hi-1", "Hi-2"], top=2
System.out.println(stack.pop()); //스택의 꼭대기 값을 반환하고 삭제한다. Hi-2
System.out.println(stack.peek()); //스택의 꼭대기 값을 반환한다. Hi-1
System.out.println(stack.search("Hi-1")); //값이 존재하면 1, 아니면 -1을 출력한다. 1
System.out.println(stack.isEmpty()); //스택이 비어있으면 true을 출력한다. false
System.out.println(stack); //[Hi-0, Hi-1]-Queue(First Input First Output)
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class StackQueueTest {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<String>();
for(int i=0;i<3;i++)
queue.add("데이터-"+i); //큐에 데이터를 삽입한다.
//queue = ["데이터-0", "데이터-1", "데이터-2"], front=0, rear=2
System.out.println(queue.peek()); //큐의 front가 가리키는 값을 반환한다. 데이터-0
System.out.println(queue.poll()); //큐의 front가 가리키는 값을 반환하고 삭제한다. 데이터-0
System.out.println(queue.isEmpty()); // false
System.out.println(queue); //[데이터-1, 데이터-2]
}
}출처 - https://blog.naver.com/PostView.nhn?blogId=pjok1122&logNo=221504688603
- Hash Table
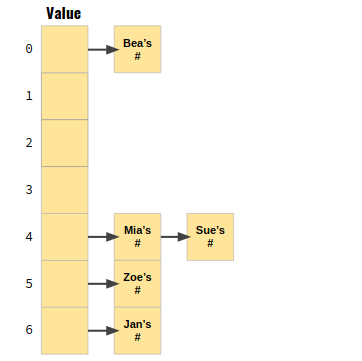
-코드가 긴 관계로 참고 사이트를 올립니다
출처 - https://dev2som.tistory.com/56
- Tree
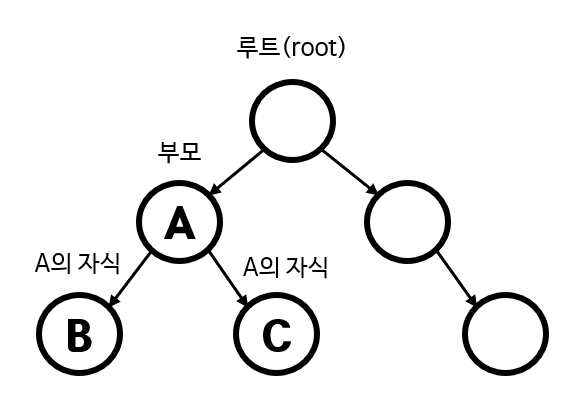
-코드가 긴 관계로 참고 사이트를 올립니다
출처 - https://dev-whoan.xyz/40
(2) 복잡성
*시간복잡도 - 서로 다른 알고리즘을 비교시 사용.
규칙)
- n >= 0, n:입력값의 크기
n < 0은 시간복잡도를 고려하지 않는 범위. - 함수에서 입력값과 작업량은 비례
모든 알고리즘에서 입력값이 많으면 어떤 작업을 하는 필요한 계산 or 처리 시간을 길게 만든다.
입력값과 처리시간이 반비례 => 이는 컴퓨터 과학으로도 설명이 안된다 - 시간복잡도를 고려할 때 상수는 배제
ex) 3n => n, 5n => n - 낮은 차수의 항은 무시
만약 n(n>=2)차식으로 구성되어 다양한 차수 항을 통해 표현하게 된다면 가장 큰 n차를 따라 선형적으로 증가되게 표현한다.
ex) n^2 + n => n^2, n^3 + n^2 + n +5 => n^3 - log함수(ln, log)로 표기하는 경우, log로만 취급
복잡도가 log인 알고리즘은 n배로 나누거나 곱한 경우에 자주 발생한다. 이 때, n은 무시하고 log로만 복잡도 비교 - 2n = O(n)
여기서 '='는 '속한다(∈)'라는 의미로 사용
생각해보기) 시간복잡도가 1이거나 n인 경우 어떤 상황을 의미할까?
=>
(3) 빅오 표기법
*빅오 표기법 - 알고리즘의 효율성을 표기하는 표기법, 알고리즘끼리 비교하는 용도로 자주 사용

(x축 - 시간복잡도(n에 따라 증가하는 메모리의 양), y축 - 처리 시간)
- x가 같을 경우, y가 낮을수록 => 같은 일을 하는데 더 적은 시간이 든다(faster)
y가 같을 경우, x가 낮을수록 => 같은 시간 내 처리량이 적다(slower)
[기준:n] - fast 알고리즘 is better than slow 알고리즘
*빅오 표기법 속 관계
- O(빅 오 복잡도): 비교대상과 일치 혹은 아래에 위치 => same or faster
- θ(세타 복잡도): 비교대상과 일치 => same
- Ω(오메가 복잡도): 비교대상과 일치 혹은 위에 위치 => same or slower
- o(리틀 오 복잡도): 비교대상 아래에 위치 => faster
- ω(리틀 오메가 복잡도): 비교대상 위에 위치 => slower
생각해보기) 빅오 표기법 속 관계는 무엇의 약자일까?
=>
[빅 오 표기법 문제] 맞게 표기됐는지 확인하시오.
문제1. n^(4/3) = O(nlogn)
=> 그래프로 그리면 무한대로 식이 그래프에 그려지는 경우 어떻게 나오는지 확인하는 게 포인트!
풀이)
(1)1000을 대입하면,1000^(4/3)과 1000log(1000)을 그래프로 그리면서 비교하면, 10000과 1000이 된다
-> 이를 가지고 그래프를 그려서 (0,0)과 같은 x축에 따른 결과에
지나는 그래프의 모양을 선형적으로 그려 파악한다.
(2)n^(4/3)과 nlogn을 그래프로 비교하면 n^(4/3)은 nlogn 위에 위치
-> 이를 통해 n^(4/3)과 nlogn을 비교하여 n^(4/3)이 위치하는 곳을 본다.
여기서 nlogn은 비교대상으로 빅 오 복잡도를 통해 보면
n^(4/3)은 nlogn보다 위에 존재하여 O(nlogn)이라고 말할 수 없다.
정답: No, n^(4/3)은 O(nlogn)이 될 수 없다.
문제2. 3n^3+4n^2+5n+6 = θ(n^3)
=> 상수항, 최대차수항을 제외한 모든 (n-1)차항은 제거된다.
풀이)
남는 건 n^3으로 비교대상인 n^3과 일치.
정답: Yes.문제3. n(n-1)/2 = O(n^2)
=> 문제 2번과 같은 접근 방식
풀이)
남는 건 n^2으로 비교대상은 n^2
정답: Yes.문제4. 2^n = w(n)
=> 1번 접근 방식과 유사.
풀이)
(1)1000을 대입하면,
-> 2^(1000)과 1000인 점과 (0,0)인 점을 그래프에 선형적으로 그린다.
(2)그래프 내 비교하면,
-> 2^n이 n 위에 존재한다. 비교대상인 n 위가 바로 w()영역으로 이는 정답.
정답: Yes.문제5. n^3 = O(n^2)
=> 1번 접근 방식으로 그래프 내 비교.
풀이)
n^3과 n^2를 비교하면, n^3 > n^2가 된다. 이를 가지고 그래프 내 비교 하면, n^3은 n^2위에 배치.
정답: No, n^3은 O(n^2)이 될 수 없다.문제6. n^2 = O(n^3)
=> 1번 접근 방식으로 그래프 내 비교.
풀이)
그래프 내 서로 비교하면, n^2은 n^3보다 무조건 아래에 위치.
정답: Yes.생각해보기) 문제 1이에서 n=1을 대입하면 어떻게 되나요? 적당히 큰 수를 대입하는 이유는?
+)왜 문제 1과 문제 3은 로피탈 정리로 문제를 풀 수 있을까?
*참고
-빅오 표기법: https://noahlogs.tistory.com/27 (복잡도 관련)

-로피탈 정리

