3주차. 해시
3-1. 해시 소개
*메소드(&시간복잡도)
- add, remove, lookup/find, change, set = 데이터에 따라 달라짐
- all entries, all keys, all values = O(n)
- size, isEmpty, isFull, loadFactor = O(1)
*연결리스트 단점
-'리스트 내 요소 찾기'시, 모든 요소를 살펴봐야 한다 => 시간복잡도 상승
So, 데이터 처리하기에 좋은 자료구조가 필요하여 Hash가 탄생!
- Hash
-Associative Arrays에서 탄생되었으며, key-value로 연관된 정보끼리 묶은 구조
-key를 통해 value를 찾는다

cf)HashCode
HashCode(String id)
remove id
convert to int
int - 10-만약 데이터를 삭제하고 싶다면, 데이터를 key로 찾아 삭제 후 -1을 넣는다
생각해보기)원하는 요소를 찾을 때, 연결 리스트와 해시의 시간 복잡도는 각각 무엇인가요?
3-2. 해시 함수
- 해시 함수 작성시, 고려할 점
-데이터의 속성이 무엇인가(key or value? 무슨 객체인가?)
이유: Hash는 해시 함수에 대해서 아무것도 모른다
-연산 is Fast
해시 함수는 정수를 반환하며, 주어진 것에 빠르게 처리(계산속도 is fast)
-두 요소(key나 value)가 같다면 같은 값 반환
여기서 객체인가 문자열인가 key비교인가에 따라 비교 상황이 다르다
객체: heap의 위치에 따라 같음
문자열: 글자 하나씩 비교
key: key를 부르는 배열이 무엇인지 비교
-같은 실행 환경인 경우, 같은 객체일 때 같은 값이 나와야 함
if)'학생'이라는 객체에 데이터를 넣는다면
===> 데이터를 찾을 때 똑같은 값이 나와야 한다
- 새로 코드를 실행하면 객체가 같아도 다른 값 도출 가능
이유: 만약 두 값의 비교가 메모리 위치 기반으로 설정되어 있는 경우, 그 객체에서 실행할 때마다 다른 곳에 배치될 수 있어서 어떤 객체에 넣어 만들건지 중요하다
하지만! 언제나 실행하면 같은 값이 나오게 자료구조를 짜야 함!
즉, 코드 내 충돌 최소화가 가장 중요!
생각해보기)코드를 새로 실행한다는 것이 어떤 의미일까요? 왜 다른 값이 나올 수 있을까요?
3-3. 해시 충돌
- 해시 충돌
->서로 다른 value를 가진 key가 일치하는 경우 발생
=>해시 함수로 나온 결과값을 key로 잡을 때, key가 일치할 수 있다.
하지만 이런 경우에는 배열 안에 같은 위치를 가리키는 상황은 없어야 한다(충돌 발생X)
이유: 배열에 두 key가 같은 공간에 들어갈 수 없어서
우리는 해시 함수를 만들 때, 안의 값이 무작위로 배열되지 않기에 어떻게 분포하여 더 펼칠 수 있을지(충돌이 발생하지 않도록) 생각해야 한다!
key를 무작위로 만들면 안되는 이유
:나중에 다시 코드로 돌아오면 key가 무엇인지 기억X
생각해보기)
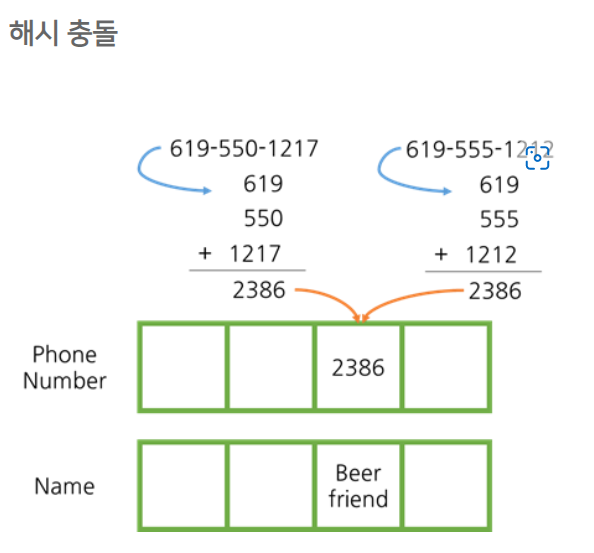
위 예시에서 해시 충돌이 일어나지 않게 하려면 전화번호를 어떻게 folding하는 것이 좋을까요?

완벽보다는 완성을 목표로!