3주차. 해시
3-7. LoadFactor메소드(적재율)
- 적재율(λ)
-테이블(해시)에 데이터가 얼만큼 있는가
즉,배열의 크기에 비해 데이터는 얼만큼 찼는가 보여준다
-적재율 = 항목(data) 수 / 자료구조의 크기
+)적재율 = number of entries / total size of array
-자료구조가 충돌을 해결하는 방법에 따라 적재율이 달라진다!!
-λ > 1도 가능(만약 이렇다면 테이블의 크기를 바꿔야 한다)
즉, 적재율의 크기에 따라 해시 충돌이 일어나지 않도록 해시의 크기를 조절해야 한다
ex)적재율 구하기

==> 답: λ= 4/12 = 1/3
- 적재율의 의미
-λ = 0: 자료구조가 비어 있다.
-λ = 0.5: 반이 차 있다.
-λ = 1: 꽉 찬 상태
+)만약 자료구조가 배열인 경우, λ >= 0.6이라면 테이블의 크기를 바꿀 필요가 있다!
생각해보기)λ가 0인 경우, λ가 1인 경우는 각각 어떤 상황을 의미하나요?
3-8. 충돌 해결
- 해시에 데이터 주입시,
// (1)
int h = x.hashCode(); // x.hashCode()가 정수 반환
h = h & 0x7FFFFFFF; // 양수 변환
h = H % tableSize // 테이블 크기만큼 연산
// (2)
int h = y.hashCode();
h = h & 0x7FFFFFFF;
h = H % tableSize(1)의 결과

hashCode의 값에 따라 x가 들어가는 위치는 달라진다
(2) - (1)을 반복
-(1)과 같은 정수를 hashCode로부터 받을 수 있다
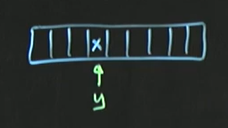
==> 이 경우, 해시 충돌이 발생하여 문제 발생!
- 해시 충돌 해결법
1.Linear probing
-해시가 같은 값을 발견하면 NULL에 도착할 때까지 자료구조를 하나씩 추가하면서 데이터를 추가 or 삭제하는 방법
- 자료구조가 차면서 추가된 객체를 찾기 위해 더 많은 칸을 살펴야 함
- 요소 제거 시, 제거하는 곳에 NULL 주입하지 않고, '비었다'라고 표시(이유: 나중에 찾을 때 찾을 수 없음)
단점: 데이터가 뭉쳐 배열이 순차적으로 정렬 ==> 순차적 추가로 인해 적용하기에는 비효율적
-> 이로 인해 탄생한 해결방안: Quadratic probing
2.Quadratic probing
-Linear probing처럼 추가를 하지만, 이번에는 넣는 hashCode 값의 제곱만큼 추가하면서 데이터를 추가 or 삭제하는 방법
-
제곱을 더하는 이유: 저장하는 곳에서 멀리 추가시키기 위해
-
Linear probing, Quadratic probing 모두 해시 값을 증가시킨다!
하지만 값을 더하면서 테이블의 크기보다 커질 수 있어 데이터가 테이블의 끝을 넘을 수 있다!
=>해결방안: 반환된 정수에 %연산을 해서 다시 테이블 범위 내로 들어오게 만든다
3.Double Hashing
<핵심!>
1) hashCode 함수가 2개
2) 두번재 함수는 첫 함수와 같지 않으며, 0을 반환하지 안된다!
-
0을 반환하면 안되는 이유: 두 함수의 값을 더하여 구한 값을 받기 때문(여기서 구한 합 == 데이터가 들어가야 할 테이블의 위치)
-
작동방식
int h = d.hashCode(); // x.hashCode()가 정수 반환
h = h & 0x7FFFFFFF; // 양수 변환
h = h % tableSize // 테이블 크기만큼 연산
int h = e.hashCode();
h = h & 0x7FFFFFFF;
h = h % tableSize여기까지는 평소대로 진행
// 두번째 hashCode 함수인 hashTwo를 사용
int g = e.hashTwo();
g = g & 0x7FFFFFFF;
g = g % tableSize
int result = g + h; // result는 양수인 g와 h의 합으로 0 반환X! g+h는 넣은 데이터가 들어갈 테이블의 위치(key)가 된다
결과) 녹색이 추가된 데이터
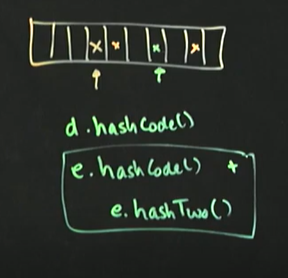
장점 - 함수를 2개 사용하여 다른 방법보다 데이터를 골고루 넣을 수 있다.
단점 - 자료 구조에 들어가는 데이터가 두 개의 해시 함수를 요구하도록 만들어야 한다(자바 내에서는 두 개의 해시 함수가 있다고 보장X)
+) 모든 객체는 hashCode 함수가 구현되어 있어 hashCode 함수 자체는 보장되어 있다!
==>이로 인해 Double Hashing은 Linear probing와 Quadratic probing의 대안으로 사용
+) 모든 방법이 데이터가 빠르게 차는 문제가 발생하지만 Linear probing와 Quadratic probing은 테이블의 크기를 바꿔야 하는 문제도 발생!
생각해보기)이중 해싱이 선형 조사법, 2차식 조사법보다 데이터를 더 골고루 넣을 수 있는 이유는 무엇인가요?
3-9. Chaining
- Chaining
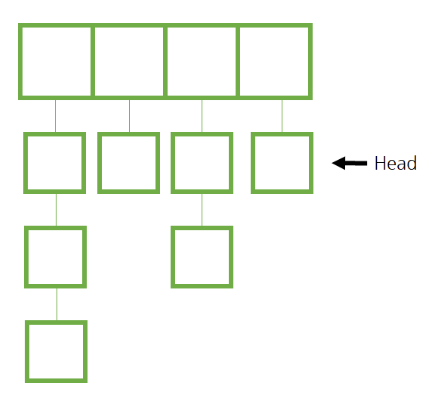
-요소마다 연결리스트를 만들어(위치마다 head 존재) 수많은 데이터를 수용하게 만드는 방법
-Chaining Hash는 가장 안정적이며, 보편적으로 사용하는 자료 구조
ex)
h = a.hashCode();
h = h & 0x7FFFFFFF;
H = H % tableSize;
h = b.hashCode();
h = h & 0x7FFFFFFF;
H = H % tableSize;- 위 코드를 실행하면 나오는 결과
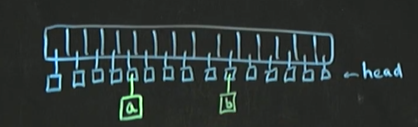
참고) a나 b를 넣을 때, 연결리스트의 add메소드나 addFirst메소드를 사용하여 추가한다
- 지속된 추가시 모양

장점
(1) 상수 시간으로 어떤 요소든 추가 or 제거 or 찾기 가능
(2) 수용 가능한 요소 갯수에 제한X, only 메모리 용량만 제한만 존재
(3) 크기 조정 필요X -> '자료 구조의 크기 > 테이블의 크기'도 가능
-
Chaining Hash의 적재율
=> 체인의 배열에 들어있는 요소 갯수 / 체인의 배열 크기
-자료 구조가 커져 2~3을 넘어 10도 가능하여, 넣을 요소가 없어도 요소를 위한 자리는 남아있으며, 체인에 문제X -
Chaining Hash의 시간 복잡도
Worst case)

:O(n)
Best Case)

:O(1)
+)메소드에 따라 시간 복잡도는 달라진다
생각해보기)체인 해시를 효율적으로 사용하려면 hashCode 함수를 어떻게 설계해야 할까요?
답: hashCode에서 반환되는 값이 다양하도록 설계
*참고
Hash Table 관련 블로그
-https://hsp1116.tistory.com/35
-https://m.blog.naver.com/jysaa5/221852333340
