5주차 Tree
4-11. 트리: 재귀 함수
트리에 데이터 추가하는 방법: 재귀함수!
- 트리에 새 데이터 추가하는 방법
1.root에서 시작하여 추가할 위치 찾기
2.추가할 위치로 null인 부분을 찾았다면 그 곳에 새 노드 추가
-> 이 과정에서 재귀함수를 이용해 트리를 내려간다
<데이터 추가 코드>
public void add (E obj, Node<E> node){ // add를 반복하는 재귀로 실행
// E - 추가할 객체, Node - 추가할 노드
if (((Comparable<E>) obj).compareTo(node.data) > 0){
// go to the right
if(node.right == null) { // right에 비어있다면
node.right = new Node<E>(obj); // 방금 만든 노드로 가리킨다
return;
}
return add (obj, node.right); // right가 차 있어 다시 한 번 발동
}
// go to the left
if(node.left == null) { // left에 비어있다면
node.left = new Node<E>(obj); // left에 추가
return;
}
return add (obj, node.left); // left가 차 있어 다시 한 번 발동
}- 만약 중복된 요소를 추가한다면?
:크기에 따라 중복된 값의 left or right child로 추가된다(추가되는 부분의 parent보다 작거나 같으면 left child, 크면 right child)
ex)
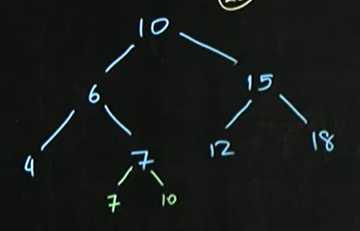
cf)루트 - 전역변수, 데이터 Type은 Node, 트리에 있어서 필수 요소
<트리가 비어있는 경우의 add 메소드>
// 트리가 비어있을 경우 (오버로딩)
오버로딩: 함수와 이름이 같지만 다루고 있는 기능이 다른 메소드가 두 개 이상인 것
public void add (E obj){
if (root==null)
root = newNode<E>(obj);
else
add(obj, root);
currentSize++;
}생각해보기)-재귀 함수를 활용하였을 때의 장점은 무엇인가요?
답: 반복문을 사용하지 않아 코드에 가독성 증가, 변수 사용 감소
참고)https://hazel-developer.tistory.com/173
4-12. 트리: Contains
: 데이터가 트리에 존재하는지 확인하는 함수(여기서도 재귀함수 활용)
- 구현 과정
- root에서 시작하여 데이터 찾기
- 찾는 데이터를 발견하면 True 반환,
마지막에 null인 노드에 도달하면 False 반환
<Contains 함수 코드>
public boolean contains (E obj, Node<E> node){
// 1. 찾고자하는 노드가 없는 경우
if (node==null)
return false;
// 2. 찾고자하는 노드 발견
if (((Comparable<E>) obj).compareTo(node.data) == 0)
return true;
// go to the right
if (((Comparable<E>) obj).compareTo(node.data) > 0)
return contains(obj, node.right);
// go to the left
// 여기서는 모든 가능성을 다 파악했기 때문에 if문 작성 필요X
return contains(obj, node.left);
}생각해보기)-트리가 비어있을 경우에도 contains 함수는 잘 동작하나요?
답: 루트가 비어있기 때문에 'root는 null인 상태'다. 그래서 'node==null'이라는 조건에 해당하여 False 반환
4-13. 트리: 제거
- 트리 내 노드는 객체를 가리키는 포인터가 존재한다
- 트리 내 데이터 제거시, 제거하는 노드의 child의 갯수에 따라 달라진다
ex)
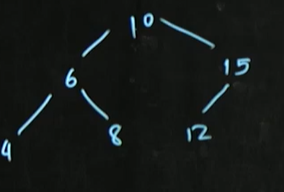
(1) child이 0개
-해당 노드의 parent의 포인터를 null로 설정
ex1) 12 제거
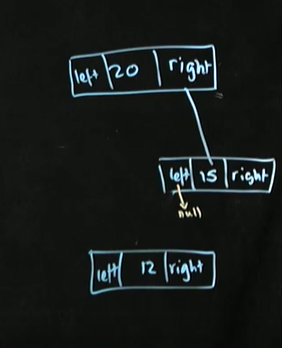
(2) child이 1개
-해당 노드의 parent의 포인터를 child으로 향하게 한다
-연결한 child에서 연결한 child의 존재여부는 신경X
ex2) 15 제거
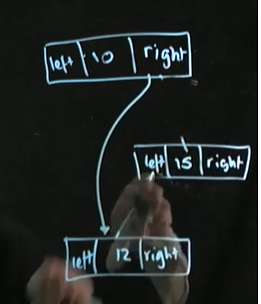
---->여기까지는 삭제된 해당 노드는 가비지 컬렉션이 되어 사라진다
(3) child이 2개
-제거 후, 중위 후속자 or 중위 선임자 중 하나가 들어간다(제거 후 나올 수 있는 트리의 가능성은 2개)
-
중위 후속자,In Order Successor
-제거하고자 하는 노드보다 작는 노드(중위 순회) 중 가장 큰 노드로, 보통 제거하고자 하는 노드의 왼쪽 서브 트리에서 가장 큰 값
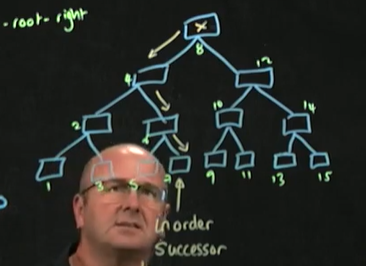
-
중위 선임자,In Order Predessor
-제거하고자 하는 노드보다 큰 노드(중위 순회) 중 가장 작은 노드로, 보통 제거하고자 하는 노드의 오른쪽 서브 트리에서 가장 작은 값
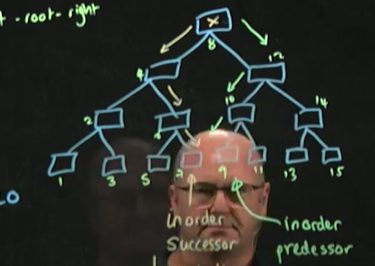
ex)
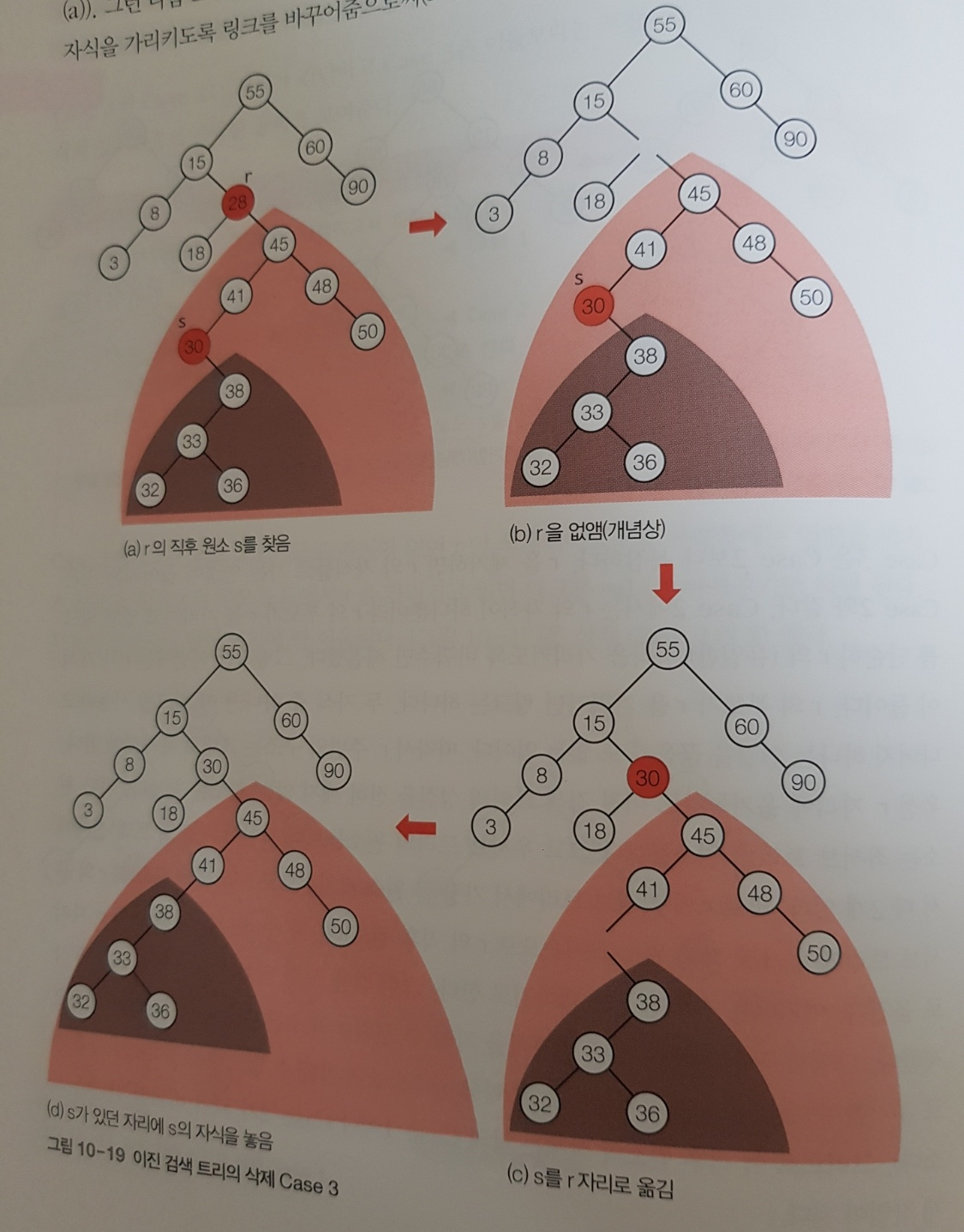
생각해보기)- 자식 노드가 2개인 노드를 제거할 때, 중위 후속자 혹은 중위 선임자와 자리를 바꾸는 이유는 무엇인가요?
답: 만약 중위 선임자, 중위 후속자가 아닌 다른 노드를 제거하는 경우, 우리가 지울 수 있는 더 큰 노드가 있기 때문에
