6주차 정렬(Sort)
- 현재 숫자들을 순서대로 정렬하는 경우만 다룬다. 물론 문자열이나 객체 모두 정렬 가능
6-1. 정렬 소개(정렬 알고리즘)
-
정렬: 만약 숫자 리스트가 있을 때, 어떻게 숫자를 배치할 것인가
-
정렬 분류
-정렬할 때, 데이터 처리방식:out-of-place 정렬 / in-place 정렬
out-of-place 정렬: 데이터를 정렬할 때, 모든 데이터를 똑같은 크기의 다른 저장공간(자료구조의 복사본)에 옮긴 후 순서대로 배열하여 정렬
in-place 정렬: 데이터를 정렬할 때, 모든 데이터를 현재 존재하는 자료구조 안에서 위치만 바꾸어 정렬
-리스트에 중복된 것이 있는가:안정 정렬 / 불안정 정렬
안정 정렬: 중복된 순서가 정렬 전의 순서와 같은(중복된 숫자 기준 하에) 정렬
ex)
정렬 전:8[1] 1[1] 10 1[2] 7 8[2] 9
정렬 후:1[1] 1[2] 7 8[1] 8[2] 9 10
=>중복된 숫자인 1와 8을 보면 정렬한 순서대로 배치된 것을 알 수 있다
불안정 정렬:'정렬 전 중복된 숫자의 순서 =/= 정렬 후 중복된 숫자의 순서'인 정렬
- 시간복잡도
-정렬 알고리즘에서 따져야 할 조건 중 하나
-모든 정렬 알고리즘은 worst/avg/best case에 따른 복잡도를 가진다
-각 case에 따라 복잡도는 달라질 수 있다
ex)
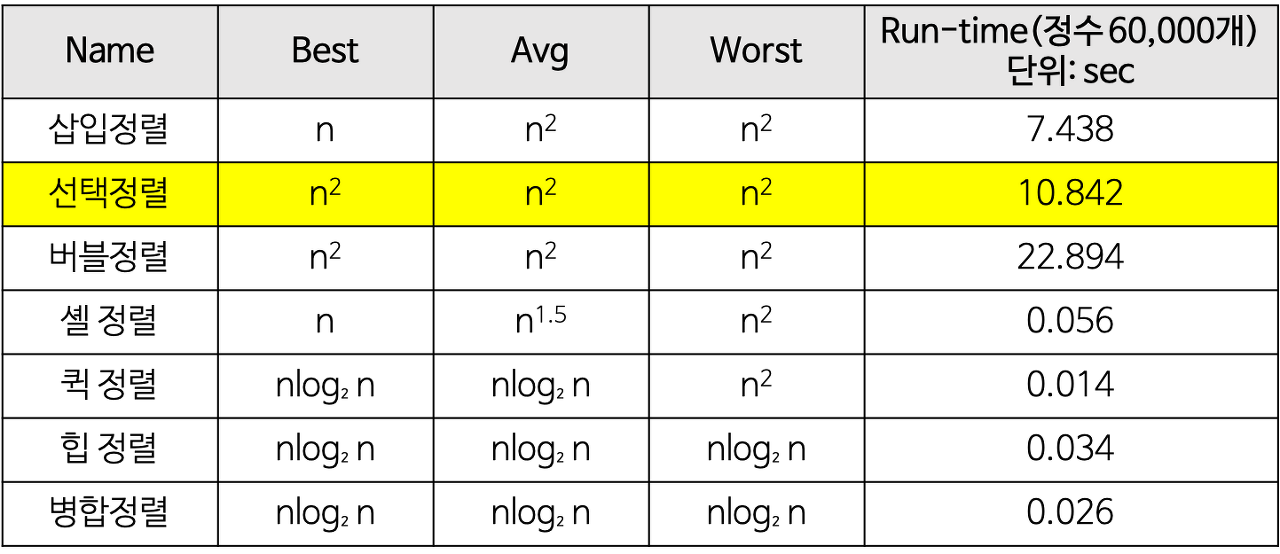
보통 각 case에 해당하는 경우는 아래와 같다.
worst: 정렬 전 큰 수에서 작은 수로 있는 경우
avg: 임의의 순서로 리스트를 정렬하는 경우
best: 이미 정렬된 경우
6-2. 선택 정렬[Select Sort]
:순서대로 리스트의 가장 작은 수를 찾아 정렬
->정렬에 따라 순서만 바뀌기 때문에 in-place 정렬
ex)
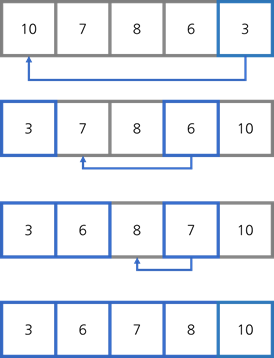
:정렬 전 무엇이 가장 작은지 모른다
:정렬할 때마다 대소 비교를 통해 이미 정해진 곳을 제외 모든 곳과 비교하여 교체한다. 이를 바탕으로 비교 횟수는 처음에 (n-1)회에서 (n-2),(n-3),...으로 줄어든다
- 시간 복잡도 : O(n^2)
=(n-1) + (n-2) + (n-3) + .... = n(n-1)/2
->best, avg, worst case 모든 경우에서 리스트가 이미 정렬되어 있어도 대소 비교를 하며 시간복잡도는 동일
6-3. 삽입 정렬[Insertion Sort]
:요소를 하나씩 꺼내어 앞에 있는 것과 비교하며 정렬하는 방식. 이 때, 순서만 바꾸기 때문에 in-place,안정 정렬
ex)
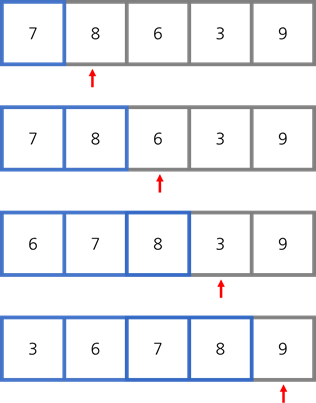
:앞에 있는 것과 비교하면서 앞에 있는 것보다 작으면 앞으로 이동하는 방식으로 정렬된다(즉, 모든 값과 대소비교)
- 시간복잡도
worst,avg: O(n^2)
best: O(n) -> 이미 순서대로 정렬되어 있다면, 맨 앞만 비교하기 때문에
+) 왜 이미 정렬된 경우 또 정렬하는가?
:이 정렬에 데이터를 추가하는 경우, 추가할 위치를 찾기 위해서(그래서 모든 데이터와 크기 비교만 한다)
6-4. 코드 with 삽입 정렬
-자료 구조: array
<삽입 정렬 with 반복문 코드>
// 요소를 선택하여 v에 저장
for (int i=1; i < array.length; i++) {
int j; // 추가할 데이터
v = array[i]; // 현재 존재하는 데이터
for (int j=i-1; j >= 0; i--) {
// v가 바로 전의 요소보다 크거나 같으면 break
if (array[j] <= v)
break;
// v가 바로 전의 요소보다 작으면 change
array[ j+1 ] = array[ j ];
}
array[ j+1 ] = v; // 적절한 위치 발견 후, 교체
}:이미 정렬되어 있다면 break를 통해 다시 반복문이 가동되도록 한다(반복문 내 break 역할 참고)
:비교는 2번째부터 시작한다
