7주차-정렬(2)
6-8. 퀵 정렬
- 퀵 정렬(Quicksort)
-중심점(Pivot Point)를 임의로 선정 후, 이를 가지고
왼쪽: Pivot Point보다 작은 수
오른쪽: Pivot Point보다 큰 수
로 분류하여 정렬하는 방법
-왼쪽과 오른쪽은 서로 비교할 필요X(이유:리스트가 분리되어 있어 리스트 내에서 퀵정렬이 이루어진다)
-in-place 정렬, 크기를 비교하여 수를 넣기 때문에 불안정 정렬
ex) 중심점: 6
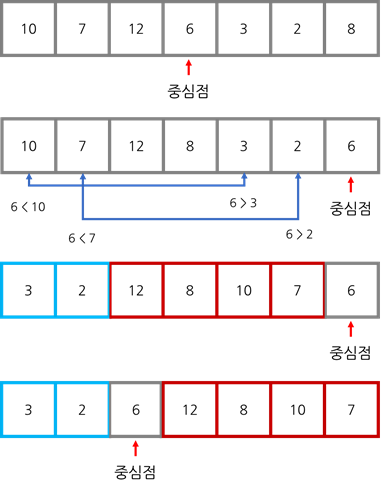
진행과정)
(1)왼쪽과 오른쪽으로 Pivot Point에 의해 나눠진다.
(2)왼쪽, 오른쪽 각각 Pivot Point를 설정한 뒤 왼쪽과 오른쪽으로 퀵정렬
(3)위 과정을 반복
-
Pivot Point 선정 방법
-리스트 내 중간에 위치한 숫자를 뽑는다
만약 중간에 위치하는 숫자가 중간값을 가지고 있지 않는다면?
-보통 중심점의 값과 배열의 맨 끝(보통 오른쪽 끝)에 위치한 값과 SWAP한 뒤에 비교한다 -
시간복잡도(Avg case): O(nlogn)
이유: 데이터를 반으로 쪼개면서 비교(logn)하기 때문에
참고 블로그) 퀵정렬
https://choewy.tistory.com/143
6-9. 퀵 정렬의 worst case
-퀵 정렬도 전체 데이터를 반으로 쪼개기 때문에 Pivot Point에 따라 시간복잡도는 차이가 발생한다
if) 계속해서 최소/최대인 지점을 Pivot Point로 잡는다면?
시간복잡도: O(n^2)
이유: 위치에 의해 n,n-1,n-2,....식으로 데이터를 비교해 나눠지므로 총 n개의 요소가 생긴다
ex) 중심점: 배열 내 최소의 수
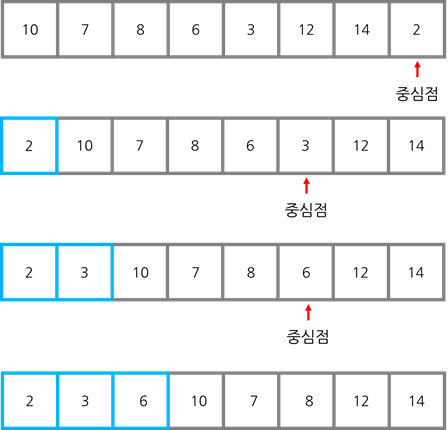
6-10. 코드(with 퀵 정렬)
<코드>
모든 종류의 변수에서 사용 가능한 퀵 정렬 코드 구현
public class QuickSort <E> {
E[] array;
public E[] sort(E[] array) {// 제너릭 생성자
this.array = array;
quicksort(0, array.length - 1);
return array;
}
public void swap(int from, int to) {
E tmp = array[from]; // 임시 변수
array[from] = array[to];
array[to] = tmp;
}
// 퀵 정렬 메소드
// 변수 - 정렬할 배열의 범위
public void quicksort(int from, int to) {
if (from >= to)
return;// 정렬 종료
E value = array[to]; // 중심점으로 마지막 숫자를 가리킴
int counter = from; // 배열 가장 앞에 카운터를 지정하여 Pivot Point보다 큰 첫번째 값을 가리킴
// 중심점보다 작은 값을 발견하면 중심점보다 큰 값과 Swap.
for (int i=from; i < to; i++) {
if (((Comparable<E>) array[i].compareTo(value) <= 0) { 현재 값 < 중심점
swap(i, counter);
counter++;
}
}
swap(counter, to); // to에 있는 값이 Pivot로 counter와 swap함 -> 중심점은 중간으로 이동
// 배열의 왼쪽과 오른쪽을 정렬합니다.
quicksort(from, counter - 1); // 왼쪽
quicksort(counter + 1, to); // 오른쪽
}:카운터의 위치는 맞는 자리이므로 더 이상 옮길 필요가 없다
:Quicksort 메소드에서 'from = to'는 '리스트에 요소가 하나밖에 없다'를 의미한다
(요소가 하나인 리스트: 퀵 정렬이 이미 된 상태)
:Pivot에 있는 값은 비교X(Pivot 앞까지)
:두 번의 Quicksort 실행할 때, 카운터는 포함하면 안된다. 왜냐하면 카운터는 맞는 값이므로 옮길 필요가 없음
6-11. 기수 정렬
- 기수 정렬(Radixsort)
-우편번호, 자릿수 등 기준에 따라 숫자를 분류하여 정렬하는 방법
-모든 숫자를 계속해서 복사해 다시 리스트에 넣기 때문에 out-of-place 정렬
-안정 정렬
ex)기준:일의 자리 숫자

결과)
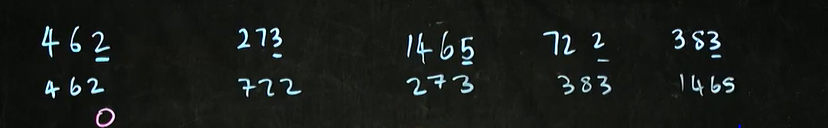
:이렇게 한 뒤에 다음 기준으로 숫자를 기준에 따라 다시 정렬할 때 원래 리스트를 삭제하고 다시 숫자를 채운다
ex2)기준:백의 자리 숫자

ex3)기준:천의 자리 숫자
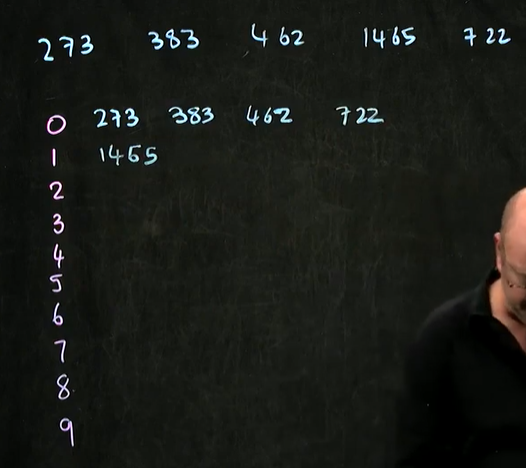
- 시간복잡도: 숫자의 갯수에 비례하나 일반적으로 n
ex) 4자리 숫자를 일/십/백/천의 자리 숫자에 따라 비교하여 시간복잡도는 4n이 된다.
-> 시간복잡도만 본다면 n이기 때문에 빠르다.하지만 컴퓨터 내에서 숫자를 비교할 때, 숫자는 매 번 복사하여 리스트에 넣고 시작하기 때문에 수행 속도는 느리다고 볼 수 있다!
6-12. 정렬 요약(전체적으로)
- 정렬 특징 요약
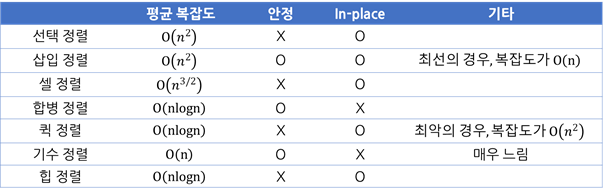
- 선택 정렬 - 작은 수를 왼쪽에 넣어가면서 정렬
- 삽입 정렬 - 인접한 요소끼리 비교하면서 정렬
- 셀 정렬 - 간격으로 나눠 간격끼리 삽입 정렬
- 합병 정렬 - 리스트를 반으로 나눠 합칠 때 정렬
- 퀵 정렬 - Pivot Point를 설정하여 크기를 비교해 정렬
- 기수 정렬 - 기준에 맞춰 숫자를 계속 정렬
- 힙 정렬 - 최대 힙이나 최소 힙으로 만들면서 정렬
+)힙 정렬
- 트리로 만들면서 전체 힙의 절반만큼 대소 비교하여 시간복잡도는 O(nlogn)
- 최대힙/최소힙으로 만드는 과정에서 순서가 깨지기 때문에 불안정 정렬이지만, in-place 정렬
