1.1 Transaction Concept
트랜잭션은 데이터베이스 작업의 논리적 단위이고, 이 단위가 안전하게 실행되기 위해 ACID 성질이 필요
PG4. Transaction Example
//Transaction Example
start transaction; // start a new transaction
select @orderNumber := max(orderNumber) from orders; //get largest order number
set @orderNumber = @orderNumber + 1; // set new order number
// insert a new order for customer 145
insert into orders(orderNumber, orderDate, requiredDate, shippedDate, status, customerNumber)
values(@orderNumber, now(), date_add(now(), INTERVAL 5 DAY), date_add(now(), INTERVAL 2 DAY), 'In Process', 145);
// insert 2 order line items
insert into orderdetails(orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
values(@orderNumber,'S18_1749', 30, '136', 1);
insert into orderdetails(orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber)
values(@orderNumber,'S18_2248', 50, '55.09', 2);
commit; // commit changes
// get the new inserted order
select * from orders a inner join orderdetails b on a.ordernumber = b.ordernumber
where a.ordernumber = @ordernumber;
위의 코드는 주문 번호를 새로 만들고, orders 테이블에 주문 1건을 넣은 뒤, orderdetails 테이블에 주문 상세 2건을 넣고, 마지막에 commit하는 구조.
코드 흐름 해석
-
start transaction;
- 새 트랜잭션 시작
-
select @orderNumber := max(orderNumber) from orders;
- 현재 가장 큰 주문번호 조회
-
set @orderNumber = @orderNumber + 1;
- 새 주문번호 생성
-
insert into orders ...
- 주문 기본 정보 저장
-
insert into orderdetails ... 두 번
- 주문 상품 2개 저장
-
commit;
- 지금까지의 변경을 최종 반영
-
마지막 select
- 방금 넣은 주문 결과 조회
즉, orders만 저장되고 orderdetails가 저장 안 되면 안 되고, 반대로 상세만 저장되고 본 주문이 없으면 더 안 됨. 그래서 이 전체가 하나의 트랜잭션으로 묶여야 함.
왜 트랜잭션인가?
트랜잭션은 하나의 논리적 작업을 수행하는 데이터베이스 연산의 순서(sequence)
위의 예에서 논리적 작업은 "주문 1건 생성"이고 SQL문은 여러 개지만, 사용자의 입장에서는 하나의 주문 등록이라는 하나의 일로 보이기 때문에 이 전체를 하나로 처리해야함.
포인트
- commit 전까지는 아직 "완전히 끝난 작업"이 아님
- 여러 테이블에 걸친 작업은 하나의 트랜잭션으로 묶는게 중요
- start transaction ~ commit 사이가 트랜잭션 범위
주의
- "SQL 한 줄 = 트랜잭션"이라고 생각하는 것 -> 아님. 여러 SQL이 묶여 하나의 트랜잭션이 될 수 있음
- commit을 단순 저장 버튼처럼 생각하는 것 -> commit은 트랜잭션의 성공적 종료를 확정하는 의미가 더 중요
PG5. Transaction Concept
트랜잭션은 데이터 항목들을 접근하고, 필요하면 갱신하는 데이터베이스 프로그램의 한 단위(unit)
설명 단순화를 위해 read/write 모델로 바꿔서 설명
계좌 A에서 B로 50달러를 보내는 트랜잭션:
read(A)
A := A - 50
write(A)
read(B)
B := B + 50
write(B)
위의 예시는 "A에서 돈을 빼고, B에 더한다"는 단순한 작업이지만 본질은 같음.
둘 중 하나만 반영되면 안 되고, 둘 다 반영되거나 둘 다 반영되지 않아야 함.
read와 write의 의미
- read(X): 데이터베이스에서 X 값을 읽어옴
- write(X): 계산한 X 값을 데이터베이스에 반영
중간의 A:= A - 50, B := B + 50는 데이터베이스 자체 연산보다는 프로그램 내부 계산임.
실제 데이터베이스 상태가 바뀌는 시점은 write.
포인트
- 트랜잭션은 프로그램의 일부
- 데이터베이스 연산은 단순화하면 read/write로 모델링 가능
- 내부 계산과 DB 반영은 구분해야 함
주의
- A := A - 50만으로 데이터베이스가 바뀌었다고 생각하는 것 -> 아님. write(A) 해야 DB가 바뀜
- read/write 모델을 실제 SQL과 다른 별개 개념으로 보는 것 -> 아님. 실제 SQL을 이론적으로 단순화한 표현
PG6. Transaction Management
트랜잭션 관리의 큰 문제는 두가지
- 실패(failures)
- 하드웨어, 소프트웨어, 트랜잭션 자체 오류
- 동시 실행(concurrent execution)
- 여러 트랜잭션이 동시에 수행될 때 생기는 문제
즉, DBMS는 장애가 나도 안전해야 하고, 동시에 여러 사용자가 함께 써도 꼬이면 안 된다는 두 가지를 해결해야함.
예시) 은행 시스템
- 서버가 중간에 죽을 수도 있음 -> 실패 문제
- 동시에 수천 명이 송금/조회함 -> 동시성 문제
그래서 트랜잭션 관리에는 보통 회복(recovery)과 동시성 제어(concurrency control)가 핵심으로 등장.
PG7. A transaction should have the ACID properties
트랜잭션은 반드시 ACID 성질을 가져야함.
- Atomicity
- Consistency
- Isolation
- Durability
1) Atomicity(원자성)
- 전부 수행되거나, 전혀 수행되지 않거나.
즉, all-or-nothing임. 송금 예제에서 A에서 돈만 빠지고 B에는 안 들어가면 안 되기 때문에, 중간 실패 시 전체를 취소해야함.
2) Consistency(일치성)
- 트랜잭션이 혼자 독립적으로 실행될 때, 데이터베이스의 무결성이 유지되어야함.
즉, 시작 전 DB가 올바른 상태라면 종료 후에도 올바른 상태여야함. 예를 들어 A+B 총합이 보존되어야 하는 규칙이 있으면, 트랜잭션 후에도 그 규칙이 유지돼야함.
3) Isolation(고립성)
여러 트랜잭션이 동시에 실행되어도, 각 트랜잭션은 혼자 실행되는 것처럼 보여야함.
다른 트랜잭션의 중간 결과(intermediate result)를 보면 안 돼.
4) Durability(지속성)
트랜잭션이 성공적으로 끝난 뒤에는, 그 결과는 시스템 장애가 나도 유지되어야함.
즉 commit된 결과는 나중에 날아가면 안 됨.
팁
- 원자성: 전부/전무
- 일치성: 무결성 유지
- 고립성: 중간 결과 숨김
- 지속성: commit 후 영속
주의
- Consistency를 "항상 데이터가 안 변함"으로 이해하는 것 -> 아님. 변해도 되는데 무결성 규칙을 지켜야 함
- Isolation을 "동시에 실행하면 안 된다"로 이해하는 것 -> 아님. 동시에 실행 가능하지만 혼자 실행한 것처럼 보여야 함
PG8. Example of Fund Transfer(1/3)
원자성과 지속성을 설명
계좌 A에서 B로 50달러를 보내는 트랜잭션:
1. read(A)
2. A := A - 50
3. write(A)
4. read(B)
5. B := B + 50
6. write(B)
Atomicity requirement
만약 3번 write(A)까지 하고 6번 write(B) 전에 실패하면,
- A에서는 50이 빠졌는데 B에는 50이 안들어감
즉 돈 50이 사라진 것처럼 된다.
그래서 부분 실행 결과는 DB에 남으면 안 된다는게 원자성.
DBMS는 이런 경우 rollback해서 A를 원래 값으로 돌려놔야 함.
Durability requirement
반대로 사용자가 "송금 완료" 안내를 받은 뒤에는, 나중에 하드웨어/소프트웨어 장애가 생겨도 그 결과가 남아 있어야함.
즉 완료 통보 후 결과가 사라지면 안 됨.
포인트
- step 3 후 step 6 전 장애가 나면 어떤 ACID 성질이 문제되는가? -> Atomicity
- 사용자가 완료 메시지를 받은 뒤 장애가 나도 결과가 유지되어야 하는 성질은? -> Durability
PG9. Example of Fund Transfer(2/3)
일치성을 설명
무결성 제약의 두 종류
-
명시적 제약
- PK, FK 같은 DB가 선언해 둔 제약
-
묵시적 제약
- 업무 규칙, 의미적 제약
- 여기서는 A+B 총합이 변하지 않아야 한다는 규칙
트랜잭션은 시작 전에 DB가 일관된 상태라면, 종료 후에도 그 상태를 유지해야함.
다만 실행 중간에는 잠깐 일관성이 깨져 보일 수 있다는 점이 중요.
왜 중간에는 깨질 수 있나?
송금 중간을 보면:
- A에서 50 차감 완료
- B에는 아직 50 추가 안 됨
위 순간만 보면 총합이 줄어든 것처럼 보임. 하지만 트랜잭션이 끝나면 다시 정상이 되므로 괜찮음.
즉 일치성은 "트랜잭션 완료 시점"기준으로 보는 개념
포인트
- Consistency는 "아무 값도 안 바뀜"이 아님
- 중간 과정은 잠시 불일치 가능
- 성공 종료 후 무결성 제약 만족해야 함
주의
- 트랜잭션 수행 중간에도 항상 무결해야 한다 -> 아님. 중간에는 temporarily inconsistent 할 수 있음
PG10. Example of Fund Transfer(3/3)
고립성을 설명
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | A:=A-50 | |
| 3 | write(A) | |
| 4 | read(A), read(B), print(A+B) | |
| 5 | read(B) | |
| 6 | B:=B+50 | |
| 7 | write(B) |
상황 해석
이
- read(A)
- A := A - 50
- write(A)
까지 했는데 아직 B는 안 더한 상태.
그 사이에 가 read(A), read(B), print(A+B)를 하면, 는 중간 결과를 보게 됨.
그래서 A+B가 원래보다 작게 보일 수 있는데 이는 잘못된 값.
왜 문제인가?
는 원래 완성된 DB 상태를 기준으로 계산해야 하는데, 이 아직 끝나지 않은 중간 상태를 읽음.
그러면 가 기반으로 삼는 데이터 자체가 틀려져서 이후 연산도 다 잘못될 수 있음.
교안에서 이런 접근을 허용하면 고립성을 위배한다고 설명.
직렬 실행(serial execution)
고립성을 가장 쉽게 보장하는 방법은 트랜잭션을 하나씩 끝까지 실행하는 것.
즉 <, > 또는 <, >
그런데 실제 시스템에서는 성능상 매우 비효율적.
현실에서는 interleaved execution(교차 실행)을 하되 결과가 직렬 실행과 같도록 제어해야 함.
나중에 배우는 serializability와 연관.
포인트
- Isolation 핵심 문장: 다른 트랜잭션이 중간 결과를 보면 안 됨
- 직렬 실행은 고립성 보장에 가장 단순한 방법
- 하지만 실제 DBMS는 성능 때문에 동시 실행 + 제어 방식을 택함
PG11. Transaction State(1/2)
트랜잭션은 실행되면서 상태가 바뀜.
- Active
- Partially committed
- Aborted
- Committed
특히 partially committed와 committed를 구분하는 문제를 조심
1) Active
트랜잭션이 실행 중인 초기 상태.
read/write 등 실제 문장들을 수행하는 단계.
2) Partially committed
마지막 문장까지 실행된 직후 상태.
이 시점은 아직 완전한 commit이 아님.
즉 "SQL문은 다 돌았지만, 최종 완료를 확정하는 안전 조치가 끝난 건 아닐 수 있음"이라는 뜻.
교안의 예로 로그를 안전한 곳에 기록하는 등의 완료 조치
3) Committed
성공적으로 모든 완료 절차가 끝난 상태.
이제 결과는 최종적으로 인정.
4) Aborted
실행 중 오류, 시스템 장애, 명시적 철회 요청 등으로 인해 트랜잭션이 실패하고 rollback된 상태.
이때 DB는 트랜잭션 시작 전 상태로 복구되어야 함.
교안에서는 철회된 트랜잭션이 DBMS에 의해 다시 시작될 수 있다고 적혀있음.
포인트
- final statement executed = partially committed
- successful completion = committed
- aborted는 단순 실패가 아니라 원상복구까지 반영된 상태
주의
- partially committed를 완전히 commit 완료로 생각하는 것 -> 아님. 아직 최종 안정 상태 전
- aborted를 "그냥 실패"로만 이해하는 것 -> rollback을 거쳐 원상복귀된 상태까지 포함
PG12. Transaction State(2/2)
방금 본 상태들을 상태 전이도로 보여줌
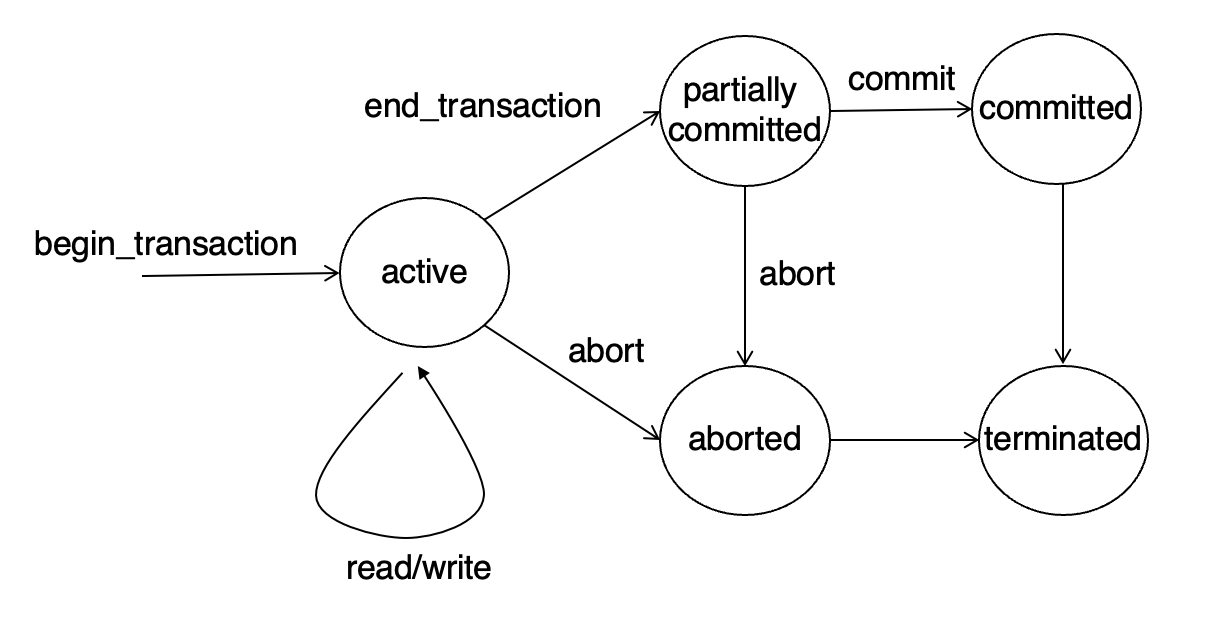
포인트
- Active에서 read/write는 여러 번 반복 가능
- Active 상태여도 abort 가능
- Partially committed 상태여도 abort 가능 -> 즉, 마지막 문장까지 실행되었더라도 아직 완전히 안전하지 않을 수 있음
- Committed나 Aborted 이후에는 종료(terminated)
그림 보고 "어느 상태에서 abort 가능한가?" 같은 문제 가능성
- active에서 가능
- partially committed에서도 가능
PG13. Concurrent Executions
DBMS는 여러 트랜잭션을 동시에(concurrently) 실행할 수 있음
그 이유는 성능 때문이고 장점은 크게 두 가지
- 프로세서와 디스크 활용률 증가
- CPU나 디스크가 놀지 않고 계속 일할 수 있음
- 결과적으로 throughput(처리량) 증가
- 평균 응답시간 감소
- 짧은 트랜잭션이 긴 트랜잭션 뒤에서 계속 기다리지 않아도 됨
위의 장점들은 OS의 프로세스 동시 수행과 비슷한 장점임.
이런 동시 수행을 안전하게 제어하는 기술이 바로 동시성 제어(concurrency control).
왜 중요한가?
동시 실행 자체는 좋은데, 서로 섞여서 실행되면 이상한 결과가 나올 수 있음.
성능은 살리되, 결과는 올바르게 유지해야함.
포인트
- 동시 실행의 장점 2가지
- 동시성 제어의 목적: 고립성 달성 + 일관성 파괴 방지
1.2 Serializability
동시에 실행된 트랜잭션이 올바른지 어떻게 판단할 것인가?
"동시 실행 결과가 어떤 직렬 실행(serial execution) 결과와 같으면 올바르다" 라고 판단하는 기준을 배울 것임. 이게 바로 직렬가능성(serializability)이다.
PG14. Correct Execution
동시에 실행된 트랜잭션이 올바르게 실행되었다는 기준은 무엇인가?
- Conflict serializable
- View serializable
직렬 실행(serial execution)은 항상 올바르다.
왜 직렬 실행은 항상 올바른가?
직렬 실행은
- 전체 끝
- 그다음 전체 끝
- 그다음 전체 끝
처럼 트랜잭션이 서로 전혀 섞이지 않는 방식
가정: 각 트랜잭션이 일치성(consistency)을 유지한다고 가장하기 때문이라고 설명
즉, DB가 일관된 상태에서 시작하면
- 혼자 실행 -> 일관성 유지
- 그다음 혼자 실행 -> 일관성 유지
- 그다음 혼자 실행 -> 일관성 유지
그래서 항상 안전.
그런데 왜 직렬 실행만 안 쓰나?
안전하지만 너무 느림.
현실에서는 사용자가 많기 때문에 그렇게 못 하고, 대신 직렬 실행과 같은 효과를 내는 동시 실행을 찾는 것.
그 기준이 serializability.
포인트
- 직렬 실행이 왜 항상 correct인가? -> 각 트랜잭션이 consistency를 보존한다고 가정하기 때문
PG15,16. Nonserializable Execution
직렬가능하지 않은(nonserializable) 실행은 concurrency anomalies(동시성 이상 현상)를 일으킬 수 있음.
교안은 3가지를 제시
- dirty read
- lost update
- unrepeatbale read
바르지 못한 실행으로 생길 수 있는 대표 현상은 이 세 가지라고 정리하고 있음.
1) Dirty Read (오손 읽기)
아직 commit되지 않은 값(uncommitted value)을 다른 트랜잭션이 읽는 것.
| index | ||
|---|---|---|
| 1 | write(A) | |
| 2 | read(A) | |
| 3 | A=A+50 | |
| 4 | write(B) | |
| 5 | rollback |
상황
- 이 write(A) 수행
- 아직 commit 안 함
- 가 그 값을 read(A)해서 사용
- 그런데 나중에 이 rollback
그러면 는 결국 존재하지 않게 된 값을 읽고 계산한 것.
왜 문제?
가 의존한 값 자체가 취소되었기 때문.
강의 교안대로라면 이 경우 도 같이 철회해야 할 수 있음.
예시) 은행
은행 계좌 잔액이 원래 100인데
- 이 임시로 150으로 써 놓음
- 가 150으로 읽고 이자 계산
- 그런데 이 rollback되면 실제 잔액은 100
그럼 계산은 잘못된 것.
2) Lost Update(갱신 손실)
한 트랜잭션이 쓴 값을 다른 트랜잭션이 덮어써서 먼저 한 갱신 효과가 사라지는 것
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | A=A+50 | |
| 3 | read(A) | |
| 4 | A=A+50 | |
| 5 | write(A) | |
| 6 | write(A) |
상황
- 과 가 둘 다 A를 읽음
- 각각 A를 수정
- 나중에 한쪽 write가 다른 쪽 write를 덮음
가 쓴 값이 에 의해 덮어써져서 효과가 데이터베이스에서 사라짐
예시
A=100인데
- : +50 해서 150 저장
- : +50 해서 150 저장
원래 둘 다 반영되면 200이어야 하는데, 둘 다 100을 기준으로 계산하면 마지막 write만 남아서 150이 됨.
3) Unrepeatable Read(반복 불가 읽기)
같은 트랜잭션이 같은 데이터를 두 번 읽었는데 사이에 다른 트랜잭션이 수정해서 서로 다른 값이 읽히는 것.
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | read(A) | |
| 3 | A=A+50 | |
| 4 | write(A) | |
| 5 | read(A) |
상황
- 이 read(A)
- 그 사이 가 A를 읽고 수정 후 write(A)
- 이 다시 read(A)
그러면 입장에서는 같은 A를 읽었는데 값이 다름.
왜 문제?
하나의 트랜잭션 안에서는 데이터가 안정적으로 보여야 하는데, 중간에 값이 바뀌어 버리니 로직이 흔들림.
포인트
이 3개는 거의 무조건 구분할 수 있어야함.
- dirty read: commit 안 된 값 읽음
- lost update: 한쪽 update가 덮어져서 사라짐
- unrepeatable read: 같은 데이터 두 번 읽었는데 값이 다름
PG17. Schedules(Histories)
스케줄(schedule) = 여러 트랜잭션 연산이 실제로 실행된 시간 순서
history라고도 부름
- 동시에 실행되는 여러 트랜잭션의 연산 전체를 포함해야 함
- 각 트랜잭션 내부의 연산 순서는 깨지면 안 됨
- 성공 종료면 마지막에 commit
- 실패 종료면 마지막에 abort
아주 중요
스케줄은 트랜잭션 내부 순서를 마음대로 바꾸는 게 아님.
예를 들어 이 원래
read(A) -> write(A) -> read(B) -> write(B)
이면, 스케줄에서도 이 순서는 반드시 유지됨.
다만 연산이 그 사이에 끼어들 수는 있음.
PG18. Schedule 1
문제 설정
- : A에서 B로 50달러 송금
- : A 잔액의 10%를 B로 송금
초기값:
- A = 100
- B = 200
| index | state | A+B | ||
|---|---|---|---|---|
| 1 | read(A) | 300 | ||
| 2 | A:=A-50 | |||
| 3 | write(A) | A=50, B=200 | 250 | |
| 4 | read(B) | |||
| 5 | B:=B+50 | |||
| 6 | write(B) | A=50, B=250 | 300 | |
| 7 | read(A) | |||
| 8 | Temp:=A*0.1 | |||
| 9 | A:=A-Temp | |||
| 10 | write(A) | A=45, B=250 | 295 | |
| 11 | read(B) | |||
| 12 | B:=B+Temp | |||
| 13 | write(B) | A=45, B=255 | 300 |
Schedule 1의 의미
위의 표는 직렬 스케줄이고, 을 먼저 전부 실행한 뒤 를 실행하는 방식.
PG19. Schedule 2
이것도 직렬 스케줄.
이번에는 <, >
초기값:
- A = 100
- B = 200
| index | state | A+B | ||
|---|---|---|---|---|
| 1 | read(A) | 300 | ||
| 2 | Temp:=A*0.1 | |||
| 3 | A:=A-Temp | |||
| 4 | write(A) | A=90, B=200 | 290 | |
| 5 | read(B) | |||
| 6 | B:=B+Temp | |||
| 7 | write(B) | A=90, B=210 | 300 | |
| 8 | read(A) | |||
| 9 | A:=A-50 | |||
| 10 | write(A) | A=40, B=210 | 250 | |
| 11 | read(B) | |||
| 12 | B:=B+50 | |||
| 13 | write(B) | A=40, B=260 | 300 |
중요한 점
Schedule 1과 2는 둘 다 올바르지만 결과는 다르다
- Schedule 1 결과: (45, 255)
- Schedule 2 결과: (40, 260)
즉, 직렬 스케줄이 여러 개일 수 있고, 서로 결과가 다를 수도 있다는 것을 보여준다
PG20. Schedule 3
이건 직렬 스케줄은 아니지만(non-serial), 그 효과가 Schedule 1과 동일
초기값:
- A = 100
- B = 200
| index | state | A+B | ||
|---|---|---|---|---|
| 1 | read(A) | 300 | ||
| 2 | A:=A-50 | |||
| 3 | write(A) | A=50, B=200 | 250 | |
| 4 | read(A) | |||
| 5 | Temp:=A*0.1 | |||
| 6 | A:=A-Temp | |||
| 7 | write(A) | A=45, B=200 | 245 | |
| 8 | read(B) | |||
| 9 | B:=B+50 | |||
| 10 | write(B) | A=45, B=250 | 295 | |
| 11 | read(B) | |||
| 12 | B:=B+Temp | |||
| 13 | write(B) | A=45, B=255 | 300 |
즉,
- 실행은 섞여 있음
- 하지만 결과는 <, > 직렬 실행과 같음
그래서 올바른 스케줄이다.
왜 Schedule 1과 같은가?
결국 A에 대한 작업이 먼저 반영된 후 가 그 결과를 바탕으로 움직이고,
B에 대해서도 결과적으로 후 순서 효과가 유지되기 때문
포인트
- 직렬은 아니어도 어떤 직렬 스케줄과 같은 효과면 올바른 스케줄이다.
PG21. Schedule 4
올바르지 않은 concurrent schedule 예시, A+B 값을 보존하지 못한다.
초기값:
- A = 100
- B = 200
| index | state | A+B | ||
|---|---|---|---|---|
| 1 | read(A) | 300 | ||
| 2 | A:=A-50 | |||
| 3 | read(A) | |||
| 4 | Temp:=A*0.1 | |||
| 5 | A:=A-Temp | |||
| 6 | write(A) | A=90, B=200 | 290 | |
| 7 | read(B) | |||
| 8 | write(A) | A=50, B=200 | 250 | |
| 9 | read(B) | |||
| 10 | B:=B+50 | |||
| 11 | write(B) | A=50, B=250 | 300 | |
| 12 | B:=B+Temp | |||
| 13 | write(B) | A=50, B=210 | 260 |
왜 이런 일이 생기나?
가 A를 기준으로 Temp를 계산한 뒤, 중간에 이 A와 B를 바꿔버려서(index 8~11) 의 B 갱신이 오래된 값/엉킨 값을 기준으로 수행되버림.
- A쪽 반영 순서와 B쪽 반영 순서가 서로 다른 직렬 순서를 따르면서 꼬여버린 상태
포인트
- 왜 Schedule 4가 틀렸는가? -> Schedule 1과도 다르고 Schedule 2와도 다르며, A+B 보존도 깨짐
PG22. Schedules
- Schedule 1, 2, 3은 correct
- Schedule 4는 not correct
- Schedule 3은 Schedule 1과 equivalent라서 correct
즉, "올바름"의 기준은 직렬이냐 아니냐 자체가 아니라, 직렬 스케줄과 동등하냐이다.
결론
- 직렬 스케줄 = 항상 correct
- 비직렬 스케줄 = 경우에 따라 correct / incorrect
- 그 판정 기준 = 직렬가능성(serializability)
PG23. Serializability
스케줄이 어떤 직렬 스케줄과 동등하면 serializable이다
교안에 따르면:
- 관련 트랜잭션이 n개면 가능한 직렬 스케줄은 n!개
- 이들 중 적어도 하나와 결과가 같으면 serializable
기본 가정
Each transaction preserves database consistency
즉, 각 트랜잭션 자체는 혼자 실행되면 올바르다고 가정.
그래서 동시 실행도 결국 어떤 직렬 실행과 같기만 하면 안전하다고 보는 것.
두 가지 notion
- Conflict serializability
- View serializability
Simplified view
이론 설명을 단순화하기 위해
- read/write 이외 연산은 무시
- 중간 계산은 자유롭게 있을 수 있다고 가정
- 따라서 스케줄은 read와 write만으로 본다
PG24. Conflicting Instructions
충돌(conflict)이 정확히 무엇인지 정의
두 연산 , 가 서로 다른 트랜잭션 , 에 속해 있을 때, 같은 데이터 항목 Q를 접근하고, 그 중 적어도 하나가 write(Q)면 충돌한다고 본다.
즉 핵심 조건은 두 가지
- 같은 데이터를 만져야 하고
- 최소 하나는 write여야 함
경우의 수 정리
- = read(Q) vs = read(Q) -> 충돌 안 함
- = read(Q) vs = write(Q) -> 충돌함
- = write(Q) vs = read(Q) -> 충돌함
- = write(Q) vs = write(Q) -> 충돌함
왜 read-read는 충돌이 아닐까?
둘 다 읽기만 하면 데이터베이스 값을 바꾸지 않음.
순서를 바꿔도 결과가 달라지지 않으니까 충돌이 아님. 반대로 write가 끼면 순서에 따라 결과가 달라질 수 있으므로 충돌이라고 보는 것.
교안에서도 충돌 연산은 트랜잭션의 논리적 시간 순서를 강제한다고 설명.
매우 중요한 직관
서로 인접한 두 연산이 비충돌이면, 그 둘의 위치를 바꿔도 결과가 같다
위의 문장이 뒤의 conflict equivalence의 출발점. 즉, 직렬가능성 판단은 결국 "어떤 연산끼리는 바꿔도 되고, 어떤 연산끼리는 절대 바꾸면 안 되는가?"를 따지는 문제.
포인트
- 다른 데이터 항목이면 애초에 충돌 아님
- 같은 데이터여도 read-read는 충돌 아님
- 같은 데이터 + write 포함 = 충돌
주의
read(A)와 write(B)를 충돌이라고 생각하면 안됨.
데이터 항목이 다르기 때문에 충돌이 아님. 충돌 정의는 반드시 동일 데이터 항목 기준.
PG25. Conflict Serializable Schedule
충돌 동등(conflict equivalent)과 충돌 직렬가능(conflict serializable)을 정의
어떤 스케줄 를 비충돌 연산들만 서로 swap 해서 스케줄 로 바꿀 수 있으면, 와 는 conflict equivalent라고 함.
그리고 가 어떤 직렬 스케줄(serial schedule)과 conflict equivalent 하면, 는 conflict serializable 이라고 한다.
쉽게 설명하면..
- 결과에 영향을 안 주는 연산들만 자리 바꾸기 가능
- 그렇게 자리 바꾸기를 계속 했더니
- 완전히 직렬 스케줄이 되면
- 원래 스케줄은 충돌 직렬가능
즉, 비충돌 연산만 바꾸는 건 안전한 재배열이라고 보는 것.
왜 중요하나?
앞에서 "동시 실행이 올바르려면 직렬 실행과 같은 효과여야 한다"를 배움.
그걸 실제로 검사하는 가장 현실적인 기준이 충돌 직렬가능성이다.
포인트
- conflict equivalent 정의
- conflict serializable 정의
PG26. Conflict Serializability Example 1
충돌 직렬가능한 스케줄의 대표 예시
Schedule 5
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | wrtie(A) | |
| 3 | read(A) | |
| 4 | write(A) | |
| 5 | read(B) | |
| 6 | write(B) | |
| 7 | read(B) | |
| 8 | write(B) |
Schedule 6
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | wrtie(A) | |
| 3 | read(B) | |
| 4 | write(B) | |
| 5 | read(A) | |
| 6 | write(A) | |
| 7 | read(B) | |
| 8 | write(B) |
교안에 따르면 Schedule 5는 비충돌 연산들을 swap해서 Schedule 6이라는 직렬 스케줄로 바꿀 수 있으므로 conflict serializable이다.
여기서 Schedule 6는 <, >이다.
왜 swap이 가능할까?
Schedule 5에서 의 write(A)는 의 read(B), write(B)와 비충돌이다. 왜냐하면 A와 B는 다른 데이터 항목이기 때문에 위치를 바꿀 수 있다.
마찬가지로 의 read(A)도 의 read(B), write(B)와 비충돌이라서 위치를 바꿀 수 있다.
이렇게 계속 바꾸면 결국 의 A, B 작업이 먼저 다 오고, 의 A, B 작업이 뒤로 가서 직렬 스케줄이 된다.
핵심 직관
위 예제는 "스케줄이 섞여 있어 보여도, 실제로는 서로 건드리는 데이터가 다르면 분리해서 생각할 수 있다"는 것을 보여준다.
즉 A 관련 연산과 B 관련 연산이 서로 방해하지 않으면 자리를 밀어내서 직렬 형태로 정리할 수 있다
포인트
- 어떤 연산끼리가 비충돌인지 표시
- swap 가능한지 쓰기
- 최종적으로 어떤 직렬 순서가 되는지 적기
주의
"원래 동시에 섞여 있으면 무조건 nonserializable이다"라고 생각하면 안됨.
섞여 있어도 swap해서 직렬로 만들 수 있으면 conflict serializable이다.
PG27. Conflict Serializability Example 2
이번에는 반대로 충돌 직렬가능하지 않은 예시
Schedule 7
| index | ||
|---|---|---|
| 1 | read(Q) | |
| 2 | wrtie(Q) | |
| 3 | wrtie(Q) |
Schedule 7은 비충돌 연산 상호 교환만으로는 <, > 또는 <, > 어떤 직렬 스케줄도 만들 수 없기 때문에 not conflict serializable 이다.
왜 안되나?
는 read(Q) 후 write(Q)를 하고, 도 write(Q)를 함.
여기서는 같은 데이터 Q에 대해 write가 끼어 있으므로 연산들 대부분이 충돌함.
그래서 "안전하게 바꿀 수 있는" 비충돌 swap이 거의 없고, 결과적으로 직렬 형태로 밀어 넣을 수 없음.
포인트
- 직렬로 만들려면 swap이 필요
- 그런데 필요한 swap이 충돌 연산 사이에서 일어나야 함
- 충돌 연산은 swap하면 안 됨
- 그래서 직렬로 못 만듦 -> not conflict serializable
PG28. View Serializability Definition
뷰 동등(view equivalent)과 뷰 직렬가능(view serializable)의 정의
두 스케줄 와 가 같은 트랜잭션 집합을 가질 때, 각 데이터 항목 Q에 대해 다음 세 조건을 만족하면 view equivalent라고 함.
-
초기값 읽기 보존
- 에서 어떤 트랜잭션 가 Q의 초기값을 읽었다면, 에서도 는 Q의 초기값을 읽어야함.
-
read-from 관계 보존
- 에서 의 read(Q)가 의 어떤 write(Q) 결과로 읽었다면, 에서도 똑같이 는 같은 의 같은 write 결과를 읽어야 함.
즉 누구에게서 읽었는지가 같아야함.
- 에서 의 read(Q)가 의 어떤 write(Q) 결과로 읽었다면, 에서도 똑같이 는 같은 의 같은 write 결과를 읽어야 함.
-
최종 쓰기(final write) 보존
- 에서 Q에 대해 마지막으로 write한 트랜잭션이 에서도 마지막 write를 해야함.
쉽게 풀면..
뷰 동등은 단순히 "최종 결과만 같음"보다 더 엄격함.
다음 세 가지를 모두 유지해야함.
- 누가 초기값을 읽었는가
- 누가 누구의 값을 읽었는가
- 마지막으로 누가 썼는가
즉 읽기 관점까지 포함한 결과 보존이라고 보면됨.
포인트
위의 세 조건은 서술형으로 나올 수 있음
주의
"최종 write만 같으면 view equivalent다"라고 하면 틀림.
초기값 읽기와 누구 값 읽었는지까지 같아야 함.
PG29. View Serializability Example
view serializable이지만 conflict serializable은 아닌 예시
Schedule 8
| index | |||
|---|---|---|---|
| 1 | read(Q) | ||
| 2 | wrtie(Q) | ||
| 3 | wrtie(Q) | ||
| 4 | wrtie(Q) |
Schedule 8은 직렬 스케줄 <, , >와 view equivalent 이므로 view serializable이지만, 비충돌 swap으로 직렬화할 수는 없어서 conflict serializable은 아니다.
왜 view serializable인가?
- 의 read(Q)가 보는 값은 <, , > 직렬 스케줄에서 가 보는 값과 같다.
- Q에 대한 최종 write는 둘 다 이 한다.
그래서 view equivalence 조건을 만족한다.
왜 conflict serializable은 아닌가?
위 스케줄은 사실상 충돌 연산만으로 구성되어 있어서, 비충돌 swap을 이용해 직렬 스케줄로 변환할 수 없다.
따라서 conflict serializable은 아니다.
blind write
conflict serializable이 아닌데 view serializable인 모든 스케줄은 blind write를 가진다.
blind write는 미리 read하지 않고 곧바로 write하는 것이다.
포인트
- blind write 정의
- "view serializable but not conflict serializable" 예시에서 blind write 찾기
질문
view serializable한게 뭔지 이해가 안됨.
, 은 read(Q)를 하지 않았는데 어떤 Q값으로 write한다는거지?
PG30. Conflict Serializability vs. View Serializability
포함관계 정리
모든 conflict serializable 스케줄은 view serializable이다.
하지만 그 반대는 성립하지 않음. 즉 conflict serializable ⊂ view serializable 이다.
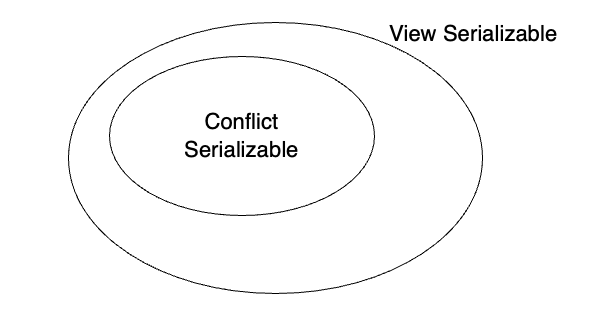
conflict는 더 강한 조건, view는 더 넓은 개념
왜 DBMS는 conflict를 더 많이 보나?
현실적으로 DBMS가 지원하는 것은 충돌 직렬가능성과 뷰 직렬가능성의 일부라고 설명하지만,
view serializable 판정이 어렵기 때문에 conflict serializable이 더 실용적이라는 점.
뒤 1.3에서 precedence graph로 더 분명해짐.
PG31. Other Notions of Serializability
충돌 직렬가능도 아니고, 뷰 직렬가능도 아니지만, 특정 직렬 스케줄과 같은 결과를 내는 스케줄ㅇ리 존재할 수 있다라고 교안에 써있음.
즉 serializability의 개념이 conflict/view로 완전히 끝나는건 아니다라는 뜻.
예시
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | A:=A-50 | |
| 3 | write(A) | |
| 4 | read(B) | |
| 5 | B:=B-10 | |
| 6 | write(B) | |
| 7 | read(B) | |
| 8 | B:=B+50 | |
| 9 | write(B) | |
| 10 | read(A) | |
| 11 | A:=A+10 | |
| 12 | write(A) |
왜 이런 일이 생기나?
연산 자체의 의미 때문.
위 예제의 트랜잭션 연산은 모두 더하기/빼기인데, 이런 연산은 어떤 경우 서로 교환 가능(commutable)해서 결과가 같게 나올 수 있음.
하지만 conflict serializability와 view serializability는 read/write 정보만 보고 판단하므로, 이런 연산 의미까지는 반영하지 못함.
시험에서 어떻게 이해해야 하는지?
- conflict / view는 실용적이고 이론적인 기준
- 하지만 완전한 결과 동등성 전체를 다 포착하는 건 아님
- DBMS가 트랜잭션 내부 연산 의미를 미리 다 아는 건 현실적으로 불가능
- 그래서 실제 시스템은 보통 read/write 기반 기준을 사용
주의
"직렬가능성이란 곧 conflict serializable 또는 view serializable 둘 중 하나다"라고 딱 잘라 외우면 안됨.
교안에서는 그 외 notion도 존재할 수 있다고 말하고 있음.
다만 시험에서는 실용적으로는 conflict와 view를 중심으로 보면 됨.
1.3 How to Test Serializability
"그럼 실제로 충돌 직렬가능인지 어떻게 검사하냐?"를 배우는 파트
PG33. Testing for Conflict Serializability
주어진 스케줄이 conflict serializable인지 판별하기 위해 precedence graph(선행 그래프)를 사용한다.
그래프의 정점(vertex)은 트랜잭션이고, 간선(edge)은 충돌로 인해 생기는 선후관계를 나타낸다.
즉 어떤 데이터 항목에서 충돌이 생겼을 때, 먼저 접근한 트랜잭션에서 나중에 접근한 트랜잭션으로 화살표를 그린다. 간선에는 그 데이터 항목 이름을 라벨처럼 붙일 수도 있다.
그래프를 만드는 절차
- 등장하는 트랜잭션들을 노드로 그림
- 같은 데이터 항목에 대한 충돌 연산 쌍을 찾음
- 시간상 먼저 나온 연산의 트랜잭션에서, 나중 연산의 트랜잭션으로 화살표 그림
- 모든 충돌에 대해 반복
제일 중요한 판정 기준
선형 그래프에 사이클이 없으면 conflict serializable,
사이클이 있으면 not conflict serializable 이다.
왜 사이클이 문제일까?
사이클이 있다는 건
- 이 보다 먼저여야 하고
- 동시에 도 보다 먼저여야 하는
식의 모순된 선후관계가 생긴다는 뜻.
즉 어떤 하나의 직렬 순서로도 만족시킬 수 없다.
PG34. Precedence Graph Example 1
선행 그래프를 그린 예제
Schedule 10
| index | ||
|---|---|---|
| 1 | read(X) | |
| 2 | write(X) | |
| 3 | read(X) | |
| 4 | write(X) | |
| 5 | read(Y) | |
| 6 | write(Y) | |
| 7 | read(Y) | |
| 8 | write(Y) |
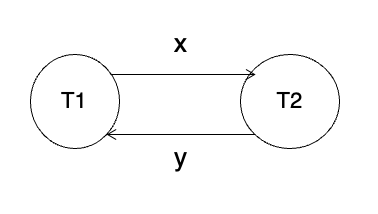
Schedule 10에 대해 그래프를 그렸더니 -> 와 -> 이 모두 생겨 사이클이 존재한다. 그래서 Schedule 10은 conflict serializable이 아니다.
그림 해석
스케줄을 보면
- X 데이터에서는 이 먼저 읽고/쓰고, 그다음 가 X를 읽고/씀 -> X 때문에 -> 간선이 생김
- Y 데이터에서는 반대로 가 Y를 먼저 읽고/쓰고, 그다음 이 Y를 읽고/씀 -> Y 때문에 -> 간선이 생김
왜 직렬화가 불가능한가?
X 기준으로는 이 먼저여야 하고, Y 기준으로는 가 먼저여야 함.
즉 둘을 동시에 만족하는 하나의 직렬 순서를 만들 수 없으니, 충돌 직렬가능하지 않은 것.
포인트
이런 문제에서는 전체를 한 번에 보지 말고, 데이터 항목별로 간선을 따로 잡아.
- X 관련 충돌 -> 누구에서 누구로?
- Y 관련 충돌 -> 누구에서 누구로?
PG35. Precedence Graph Example 2
Schedule 11의 선행 그래프(precedence graph) 예제
핵심 메시지
- 선행 그래프에서 중복 간선은 굳이 여러 번 그릴 필요가 없다
- 사이클이 없으면 conflict serializable
- Schedule 11은 사이클이 없으므로 충돌 직렬가능 스케줄이다
Schedule 11
| index | |||||
|---|---|---|---|---|---|
| 1 | read(X) | ||||
| 2 | read(Y) | ||||
| 3 | read(Z) | ||||
| 4 | read(V) | ||||
| 5 | read(W) | ||||
| 6 | read(W) | ||||
| 7 | read(Y) | ||||
| 8 | write(Y) | ||||
| 9 | write(Z) | ||||
| 10 | read(U) | ||||
| 11 | read(Y) | ||||
| 12 | write(Y) | ||||
| 13 | read(Z) | ||||
| 14 | write(Z) | ||||
| 15 | read(U) | ||||
| 16 | write(U) |
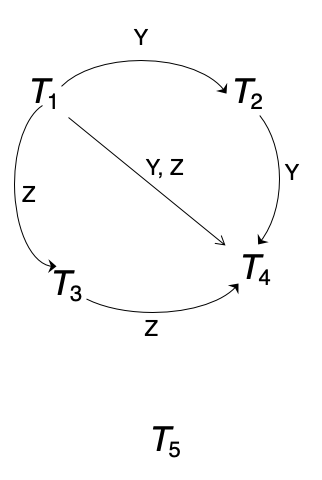
왜 그렇게 되는가?
선행 그래프는 충돌 때문에 생기는 선후관계만 표현
예를 들어 어떤 데이터 항목 Y에 대해 의 충돌 연산이 먼저 나오고 의 충돌 연산이 나중에 나오면, -> 간선을 그림. 같은 이유로 다른 데이터 항목에서도 같은 방향의 간선이 또 생길 수 있는데, 이건 이미 "이 보다 먼저여야 한다"는 정보가 들어 있으니 중복해서 또 그릴 필요는 없음.
교안에서도 우리 관심은 사이클 존재 여부이므로 중복 에지는 생략 가능하다고 말함.
위 예제에서 중요한 점
단순히 "그래프를 그린다"가 아니라, 그래프를 그린 뒤 무엇을 보느냐를 보여줌.
정답은 사이클이 있냐 없냐
- 있으면 not conflict serializable
- 없으면 conflict serializable
Schedule 11은 사이클이 없으니 올바른 스케줄로 판정되는 것.
포인트
- 중복 간선은 그리지 않아도 됨
- 사이클 유무가 본질
- Schedule 11은 충돌 직렬가능
PG36. Cycle detection in precedence graphs is cheap
1.3의 결론
- 스케줄이 conflict serializable일 필요충분조건은 선행 그래프가 acyclic(비순환) 인 것.
- 선행 그래프에서 사이클 판별은 계산 비용이 크지 않다.
- 그래프에 사이클이 없으면 위상 정렬(topological sort) 로 해당 스케줄과 동등한 직렬 순서를 구할 수 있다.
"if and only if"가 중요
- conflict serializable이면 선행 그래프는 acyclic
- 선행 그래프가 acyclic이면 conflict serializable
둘 다 성립한다는 뜻.
위상 정렬이 뭔가?
부분 순서(partial order)를 만족하면서 전체 노드를 일렬로 세우는 방법.
선행 그래프에서 간선 -> 가 있으면, 위상 정렬 결과에서도 반드시 가 보다 앞에 와야함.
교안은 Schedule 11의 한 예로
-> -> -> ->
를 제시하고 있음.
즉 이 순서대로 직렬 실행해도 원래 Schedule 11과 충돌 관점에서 동등하다는 뜻.
왜 10개의 serialization order가 나오나?
Schedule 11의 그래프에서는
- 어떤 트랜잭션들 사이에는 반드시 지켜야 할 순서가 있고
- 어떤 트랜잭션들 사이에는 순서 제약이 없다
그래서 위상 정렬 결과가 하나만 나오는게 아니라 여러 개 나올 수 있다.
교안에서는 총 10개의 위상 정렬이 가능하다고 설명. 즉 직렬가능 스케줄은 동등한 직렬 순서가 여러개일 수 있다는 의미.
포인트
- acyclic <-> conflict serializable
- 위상 정렬 결과가 곧 equivalent serial schedule
- 직렬 순서는 여러 개일 수 있음
주의
- "사이클이 없으면 직렬 순서가 하나만 나온다" -> 틀림
- "위상 정렬은 아무 순서나 나열하는 것" -> 틀림. 반드시 간선 방향 제약을 만족해야 함.
참고) 위상정렬 10가지
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
- -> -> -> ->
PG37. Test for View Serializability
뷰 직렬가능성 판별은 어렵다는 걸 강조
- precedence graph 검사는 conflict serializability용이지, view serializability에 바로 쓸 수는 없다
- view serializability 판정 문제는 NP-complete
- 그래서 현실에서는 충분조건만 검사하는 실용적 방법을 쓴다.
왜 어려운가?
conflict serializability는 "충돌 순서"만 보면 되니까 선행 그래프로 빠르게 검사할 수 있음.
그런데 view serializability는
- 누가 초기값을 읽었는지
- 누가 누구의 write를 읽었는지
- 최종 write가 누구인지
이런 관계를 전부 맞춰야해서 훨씬 복잡해짐. 그래서 다항시간 알고리즘을 기대하기 어렵다고 말함.
노트에 나온 실용적 관점
노트는 현실적인 뷰 직렬가능 시험에서 blind write 존재 여부를 활용한다고 설명.
즉 뷰 직렬가능성은 이론적으로 더 넓은 개념이지만, 실제 시스템에서는 보통 충돌 직렬가능성 중심으로 접근하는 이유가 여기 있음.
포인트
- precedence graph는 view serializability 직접 검사 불가
- view serializability 판정은 NP-complete
- 실무/시험에서는 보통 conflict serializability를 더 중심적으로 다룸
1.4 Recoverability
PG39. Recoverable Schedules
여기서부터 관점이 조금 바뀜.
지금까지는 고립성/직렬가능성 중심이었고, 이제는 실패가 났을 때 복구 가능한가를 본다.
교안에서는 회복가능 스케줄(recoverable schedule)을 다음처럼 정의
어떤 트랜잭션 가 가 쓴 값을 읽었다면, 의 commit이 의 commit보다 먼저 나와야 한다.
예제
| index | ||
|---|---|---|
| 1 | read(A) | |
| 2 | write(A) | |
| 3 | read(A) | |
| 4 | read(B) | |
| 5 | write(A) | |
| 6 | commit | |
| 7 | rollback |
왜 이런 조건이 필요한가?
위의 예제를 보면
- 이 A를 write
- 가 그 A를 read
- 그런데 가 먼저 commit
- 이후 이 rollback
이러면 큰 문제가 생김.
왜냐하면 는 결국 취소될 값을 읽고 commit해버렸기 때문.
그런데 이미 commit한 트랜잭션을 취소해야 한다면, 이는 의 지속성(durability)을 깨드리는 심각한 상황이 돼. 교안에서도 이걸 복구 불가능한 상황이라 설명함.
직렬가능성과는 별개다
아무리 직렬가능한 스케줄이어도, 회복 관점에서 문제가 있으면 사용할 수 없다
즉,
- serializable 여부
- recoverable 여부
는 서로 다른 기준이다. 둘 다 봐야함.
포인트
- recoverable 정의 정확히 외우기
- "누가 읽었으면, 그 값을 쓴 트랜잭션이 먼저 commit해야 한다"
- 직렬가능성과 회복 가능성은 별도 판단 기준
주의
- "읽기 전에 commit해야 recoverable"이라고 쓰면 틀림 -> 그건 cascadeless 쪽 정의에 가까움, recoverable은 commit 순서를 묻는 것.
질문
rollback하면 어디로 돌아가는거냐?
PG40. Cascading Rollbacks
연쇄 철회(cascading rollback)를 설명
의미는 단순하다.
한 트랜잭션의 실패가 다른 여러 트랜잭션의 rollback까지 연달아 유발하는 현상
교안에서는 이게 많은 작업을 한꺼번에 되돌리게 만들 수 있다고 설명.
예제
| index | |||
|---|---|---|---|
| 1 | read(A) | ||
| 2 | read(B) | ||
| 3 | write(A) | ||
| 4 | read(A) | ||
| 5 | write(A) | ||
| 6 | read(A) | ||
| 7 | rollback |
예제 해석
위의 예제에서는 아직 아무도 commit하지 않았기 때문에, 형식적으로는 recoverable임.
그런데 문제는:
- 이 쓴 값을 이 읽고
- 또 그 영향을 가 읽는 식으로 이어지면
- 이 rollback할 때 , 도 줄줄이 rollback해야 함.
즉 recoverable이긴 한데, 복구 비용이 너무 크고 비효율적
dirty read와 연결
교안에서는 이 상황의 읽기를 dirty read라고 설명.
왜냐하면 , 가 읽은 값은 아직 commit되지 않은 값이기 때문.
결국 commit되지 않은 값을 읽게 허용하면 이런 연쇄 철회가 생긴다는 것.
포인트
- cascading rollback 정의
- recoverable과 cascadeless의 차이
- recoverable이라고 해서 좋은 스케줄은 아님
PG41. Cascadeless Schedules
연쇄 철회를 막는 더 강한 조건인 cascadeless schedule (ACA)를 설명함
정의는 다음과 같음
어떤 가 가 쓴 값을 읽는다면, 가 read하기 전에 가 먼저 commit해야 함
recoverable과의 차이
recoverable은 commit 순서만 제약함.
- 읽은 뒤에 commit은 나중에 해도 됨
하지만 cascadeless는 더 강함.
- 아예 읽기 전에 commit된 값만 읽어야 함
그래서 dirty read 자체가 불가능해지고, 결과적으로 cascading rollback도 생기지 않음.
교안에서도 모든 cascadeless schedule은 recoverable이라고 설명.
쉽게 비교
- Recoverable: "읽는 건 허용, 단 commit은 나중에 해"
- Cascadeless: "읽기 자체를 commit된 값만 하게 해"
그래서 cascadeless가 더 안전한 조건.
포인트
- ACA = avoids cascading aborts
- committed read만 허용
- every cascadeless schedule is also recoverable
PG42. Relationship Between Histories
지금까지 배운 여러 스케줄 집합의 관계를 그림으로 정리.
새로 나오는 개념이 strict(ST) 인데 정의는:
어떤 트랜잭션이 데이터 X를 write한 뒤라면, 그 트랜잭션이 abort 또는 commit으로 종료되기 전까지 다른 트랜잭션은 그 X를 읽지도 못하고, 덮어쓰지도 못한다.
strict가 왜 더 강한가?
ACA는 읽기에 대해서만 제한을 건다.
- commit 안 된 값은 읽지 마
그런데 strict는 더 강함.
- commit 안 된 값 읽지도 말고
- commit 안 된 값을 덮어쓰지도 마
그래서 strict는 recoverability / rollback을 훨씬 단순하게 만듬.
교안에서도 이전 write를 한 트랜잭션이 종료될 때까지 아무도 read/write 못 한다고 설명함.
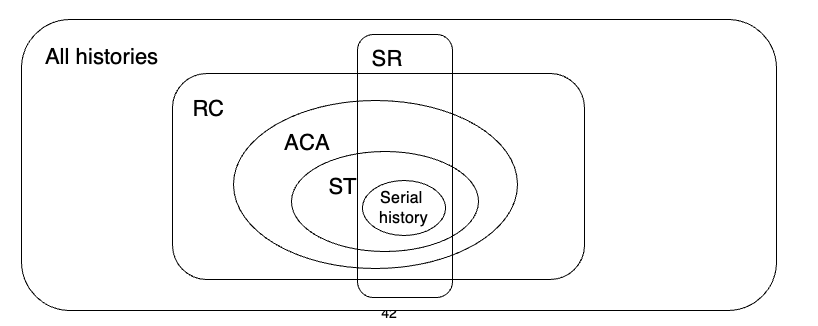
그림 해석
- 전체 가능한 스케줄 중 일부가 RC(recoverable)
- 그 안의 일부가 ACA(cascadeless)
- 그 안의 일부가 ST(strict)
즉 회복 관점에서는 ST ⊂ ACA ⊂ RC 관계로 이해하면 된다.
한편 SR(conflict serializable)은 이 회복성 집합들과 완전히 포함관계로 딱 들어맞는것이 아님.
즉 직렬가능성과 회복가능성은 서로 다른 축이다.
교안에서도 DBMS가 실제로 지원해야 하는 것은 직렬가능 스케줄과 ACA(또는 recoverable) 스케줄의 교집합 부분이라고 설명함.
포인트
- strict 정의
- ST ⊂ ACA ⊂ RC
- SR은 회복성 집합과 별개의 관점
주의
- strict를 "읽기만 막는 것"으로 외우면 틀림 -> strict는 읽기 + overwrite 둘 다 금지
PG43. An ACA schedule that is not in ST
ACA이지만 strict는 아닌 스케줄 예시
즉 ACA와 ST가 다르다는 걸 실제 예로 보여줌
예제
| index | ||
|---|---|---|
| 1 | write(X) | |
| 2 | write(Y) | |
| 3 | read(U) | |
| 4 | write(X) | |
| 5 | write(Z) | |
| 6 | commit | |
| 7 | read(Y) | |
| 8 | write(Y) | |
| 9 | commit |
왜 ACA는 만족하나?
ACA는 읽기 연산에 대한 조건만 요구.
즉 가 다른 트랜잭션이 쓴 값을 읽으려면, 그 write를 한 트랜잭션이 먼저 commit해야 한다는 것만 보면 됨.
위의 예제에서는 그 조건은 깨지지 않아서 ACA는 만족.
왜 strict는 아니냐?
strict는 읽기뿐 아니라 overwrite도 금지함.
그런데 위 예제에서 는 이 쓴 X를, 이 종료되기 전에 write(X)로 덮어써버림.
교안에서도 4번째 줄의 write(X)가 strict 요구사항을 위반한다고 설명함.
아주 중요한 차이
- ACA: 읽기만 조심
- ST: 읽기 + 쓰기(덮어쓰기)까지 조심
PG44. Concurrency Control(1/2)
지금까지 배운 모든 내용을 "DBMS는 실제로 무엇을 해야 하느냐"로 연결해줌.
교안에서는 데이터베이스가 결국 보장해야 할 스케줄 조건을 다음과 같이 말함.
- conflict 또는 view serializable
- recoverable, 그리고 가급적 cascadeless
왜 그냥 한 번에 하나씩 실행하지 않나?
교안에서는 한 번에 하나의 트랜잭션만 실행하면 직렬 스케줄이 만들어지므로 안전하긴 하지만, 동시성 정도가 너무 낮아서 성능이 나쁘다고 말함.
즉 안전성만 생각하면 serial execution이 쉽지만, 실제 시스템 성능 때문에 그건 현실적이지 않음.
"실행 후 검사"는 늦다
스케줄이 끝난 뒤에 serializable인지 검사하는 건 너무 늦다
왜냐하면 이미 문제가 있는 스케줄이 실행되면 그 사이에 데이터가 깨졌을 수도 있기 때문이다.
교안에서도 트랜잭션이 다 수행된 뒤 판별하는 것은 의미가 없다고 설명함.
그래서 필요한 것
DBMS는 "실행하고 나서 검사"가 아니라,
애초에 나쁜 스케줄이 만들어지지 않도록 규율(discipline)을 강제하는 프로토콜이 필요.
그게 바로 동시성 제어 규약(concurrency control protocol).
포인트
- 원하는 스케줄 조건 2축
- serializable
- recoverable / preferably cascadeless
- 사후 판정은 늦음
- 그래서 protocol이 필요
PG45. Concurrency Control(2/2)
동시성 제어의 목적을 다시 정리하고, 앞으로 배울 주제들 예고
교안에서는 동시성 제어 프로토콜이
- 동시 실행은 허용하되
- 스케줄이 conflict/view serializable이게 하고
- recoverable이며 cascadeless하게 만들도록 해야 한다고 설명
tradeoff
동시성 제어 프로토콜마다
- 얼마나 많은 동시성을 허용하느냐
- 그 대신 얼마나 많은 관리 비용(overhead)을 치르느냐
가 다름.
즉, 빠르기만 하면 좋은 것도 아니고, 안전하기만 하면 좋은 것도 아니고, 안전성과 성능 사이 균형이 필요.
왜 serializability test를 배우나?
우리가 precedence graph나 serializability test를 배우는 이유는 단순 계산문제를 풀기 위해서가 아니라, 왜 어떤 동시성 제어 프로토콜이 옳은지 이해하기 위해서 배우는 것.
앞으로 나올 프로토콜
- locking
- timestamp ordering
- multiversion
- optimistic / validation protocol
PG46. Recap
1. 스케줄의 올바름(correctness criteria)은 두 관점으로 본다
스케줄이 올바른지 판단할 때 기준이 한 종류가 아니라 두 종류
(1) Isolation 관점
동시에 실행된 트랜잭션이 서로 간섭하지 않고, 마치 직렬 실행한 것처럼 올바른 결과를 내는지를 보는 기준.
여기서 나오는 개념이:
- conflict serializable
- view serializable
즉, "이 스케줄이 동시 실행됐지만 직렬 실행과 동등한가?"를 보는 축.
(2) Durability / Atomicity 관점
장애나 rollback이 생겼을 때도 안전한가를 보는 기준.
여기서 나오는 개념이:
- recoverable
- cascadeless
- strict
즉, "이 스케줄이 commit/abort 관점에서도 안전한가?"를 보는 축.
2. conflict serializability는 precedence graph로 판별한다
핵심 절차
- precedence graph(선행 그래프)를 만든다.
- 그래프에 cycle(사이클)이 있는지 본다.
- 사이클이 없으면 conflict serializable
- 사이클이 있으면 not conflict serializable
즉, conflict serializable 판별 = precedence graph + cycle 검사라고 외우면 됨.
3. 위상 정렬(topological sort)로 equivalent serial schedule을 구한다
precedence graph에 사이클이 없으면, 그 그래프는 acyclic이니까 topological sort가 가능.
그 topological sort 결과가 바로 원래 스케줄과 동등한 직렬 스케줄(equivalent serial schedule) 임.
즉:
- cycle 없음 -> conflict serializable
- topological sort 가능 -> 직렬 순서 구할 수 있음
4. view serializability 판정은 어렵다
어떤 스케줄이 view serializable인지 판별하는 것은 어렵고, NP-complete이다.
시험에서는 보통 두 가지만 기억하면 됨.
- conflict serializable은 그래프로 비교적 쉽게 판별 가능
- view serializable은 직접 판별이 어려움
즉, 둘을 비교해서 쓰라는 문제가 나오면
conflict는 practical하고 판단 쉬움, view는 더 넓지만 판정 어려움
이렇게 연결해서 쓰면 된다.
5. schedule들 사이의 관계 그림을 기억해야 한다
이 장에서 배운 개념들이 서로 어떤 포함관계인지를 구분해야 하기 때문에 중요하다.
대표적으로 기억할 관계는:
- Conflict Serializable ⊂ View Serializable
- **Strict ⊂ Cascadeless ⊂ Recoverable
즉,
- 격리성 쪽 관계
- 회복성 쪽 관계
두 줄을 알아야 한다.
