문제 설명
방향그래프가 주어진다. 시작점이 주어진다. 여기서 모든 다른 그래프로의 최단경로 거리를 찾아서 출력해라.
단, 정점 간 여러개의 간선이 존재할 수 있다.
접근
다익스트라다. 처음에는 정점 간 여러개 간선이 존재할 수 있다는 것 때문에, ArrayList<Node>[]로 그래프를 표현하지 않고, HashMap<Interger, Integer>로 표현해서 간선을 입력받을때, 항상 더 작은값만 저장시켰다.
그렇게 해서 풀리긴했으나 java11로 푼 다른 사람들의 풀이 중 빠른 편인 700ms와 500ms 정도가 차이가 나도록 느렸다.
다른 사람의 풀이를 보고 다시 생각해보았다, 다익스트라 알고리즘의 특성상 노드를 방문할 때, 어차피 그 노드와 연결된 간선에 대한 모든 정보를 토대로 그냥 다익스트라 테이블 업데이트 하고, 갱신 가능할 때마다 우선순위큐에 다 넣는다.
어차피 우선순위 큐라서 동일한 노드에 대한 정보들이 들어가도 상관없다. 어차피 늦게 뽑힐거고, 나중에 뽑힌다해도 그 값으로는 다익스트라 테이블을 갱신시킬 수 없다(이 특징 때문에 사실 isVisited 여부도 없어도 된다. 근데 난 왜 있는게 더 익숙한지 그동안 계속 넣고 있었다... ).
아래코드에서 방문여부 배열 지워도 됩니다.
import java.util.*;
import java.io.*;
public class Main {
static int V, E, K;
static ArrayList<Node>[] graph;
static boolean[] isVisited;
static int[] dijkstraTable;
static class Node {
int n;
int cost;
Node(int n, int cost) {
this.n = n;
this.cost = cost;
}
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
V = Integer.parseInt(st.nextToken());
E = Integer.parseInt(st.nextToken());
K = Integer.parseInt(br.readLine());
graph = new ArrayList[V + 1];
for (int i = 1; i < V + 1; i++) graph[i] = new ArrayList<>();
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
int w = Integer.parseInt(st.nextToken());
graph[u].add(new Node(v, w)); // 최단 거리로 갱신
}
dijkstra(K);
StringBuilder sb = new StringBuilder();
for (int i = 1; i < V + 1; i++) {
if (i == K) {
sb.append(0).append("\n");
} else if (dijkstraTable[i] == Integer.MAX_VALUE) {
sb.append("INF").append("\n");
} else {
sb.append(dijkstraTable[i]).append("\n");
}
}
System.out.print(sb);
}
static void dijkstra(int s) {
isVisited = new boolean[V + 1];
dijkstraTable = new int[V + 1];
PriorityQueue<Node> pq = new PriorityQueue<>((o1, o2) -> {
return o1.cost - o2.cost;
});
Arrays.fill(dijkstraTable, Integer.MAX_VALUE);
dijkstraTable[s] = 0;
pq.add(new Node(s, 0));
while (!pq.isEmpty()) {
Node curnode = pq.poll();
if (isVisited[curnode.n]) continue;
isVisited[curnode.n] = true;
for (Node node : graph[curnode.n]) {
if (isVisited[node.n]) continue;
int newW = curnode.cost + node.cost;
int originW = dijkstraTable[node.n];
if (originW > newW) {
dijkstraTable[node.n] = newW;
pq.add(new Node(node.n, newW));
}
}
}
}
}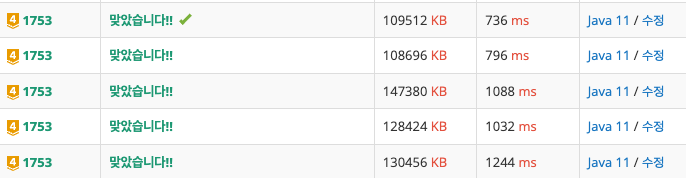
맨 처음으로 푼 1244ms가 방문여부 배열과 해시맵을 사용한것
1000ms두개가 방문여부 배열을 제거한것
796ms가 해시맵을 리스트로 변경한것, 방문여부배열은 넣음
736ms가 리스트로 바꾸고 방무여부 배열도 제거한것.
느낀점
다익스트라 알고리즘에 대해 잘 알고 있다고 생각했는데, 방문여부 배열을 굳이 넣을 필요가 없었다니... 다른 기존 것들도 수정해봤는데 시간이 빨라졌다!
