
금융권 3-Tier 아키택처에서 Redis를 활용한 고트래픽 대응 방안
🗓️ 2025.07.18 ~ 2025.08.05 1차 기술 세미나
금융권 3-Tier 아키택처
대부분의 금융권은 3-Tier 구조를 따른다.
현재 금융권이 MSA로 완전히 변환하려는건지, 아니면 여전히 일부 서비스는 3-Tier로 남아있는지를 현업자에게 물어본 결과 다음과 같이 말하셨다.
MSA로 도입하려는 방향이 맞지만, 관리 포인트와 모니터링을 해야 하는 구간이 많아져서 서비스가 커집니다. 그래서 내부 시스템, 사용자가 많지 않은 서비스, 간단 서비스는 여전히 3-Tier 구조입니다. 서비스의 성격과 규모에 따라 MSA와 3-Tier를 병행해서 사용하는 것이 효율적입니다.
3-Tier 구조
3-Tier 구조는 3개의 계층으로 이뤄져있다.
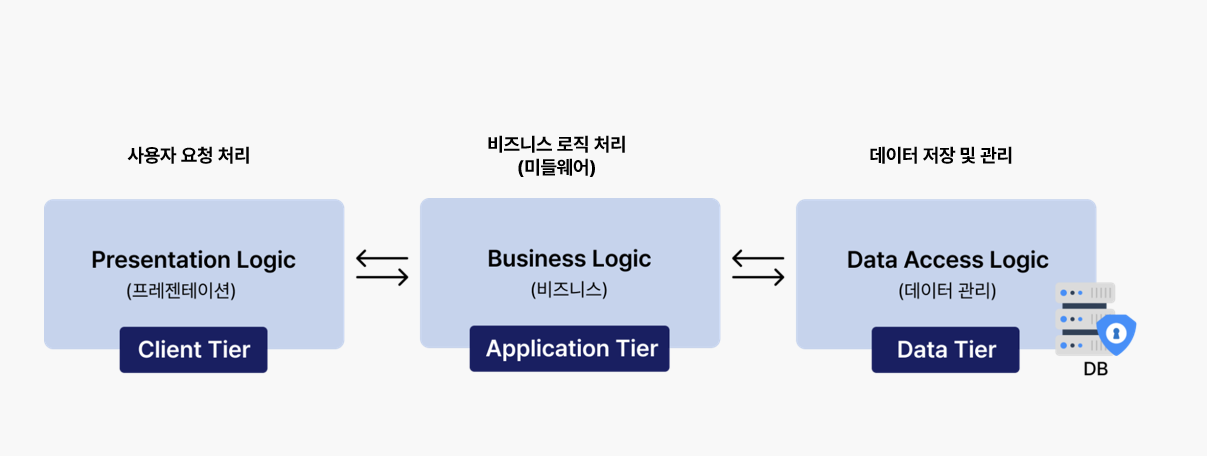
- Presentation 계층 = 사용자의 요청처리가 이뤄지는 화면 역할
- Applicaiton 계층 = 비지니스 로직 처리를 하는 미들웨어 역할
- Database 계층 = 데이터를 저장하고 관리하는 역할
‼️Layer와 Tier 차이
Layer = 논리적인 구분
➡️ 하나의 애플리케이션 내부에서 레이어는 코드 단위로 나뉨
Tier = 물리적인 구분
➡️ 티어는 각각 다른 컴퓨터(서버)에서 실행됨
다른 조의 발표를 듣고 이런 고민을 했다니...! 하고 감명받았다 ㅎㅎ
3-Tier 구조는 역할이 분리되어 있어 보안성, 유지보수성, 확장성 측면에서 많은 장점이 있다. 하지만 각 계층에서 병목 현상이 발생할 경우, 전체 서비스의 지연이나 장애로 이어질 수 있다.
3-Tier 구조의 매일 이자 받기 기능 구현
3-Tier에서의 병목 현상과 이를 완화하는 방안을 분석하고자 "매일 이자 받기" 기능을 구현했다.
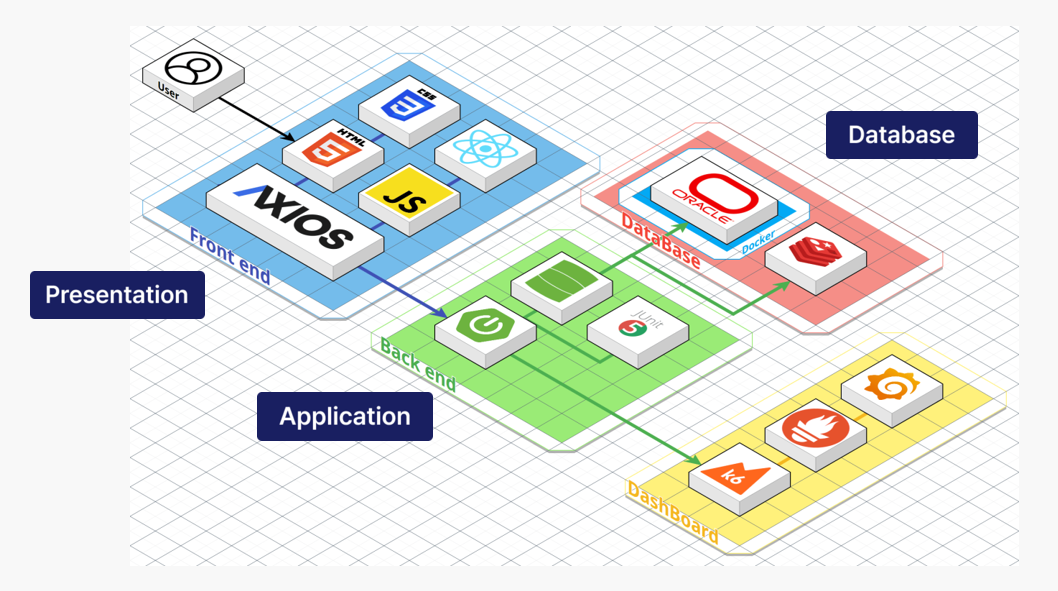
3-Tier 구조로 구현했다.
- Presentation 계층 ➡️ React
- Application 계층 ➡️Spring Boot (Axios를 이용해 API 통신을 수행)
- Database 계층 ➡️ Oracle DB (선택 이유 : 실제 금융 환경과 유사하도록)
📱구현된 매일 이자받기 화면이다.
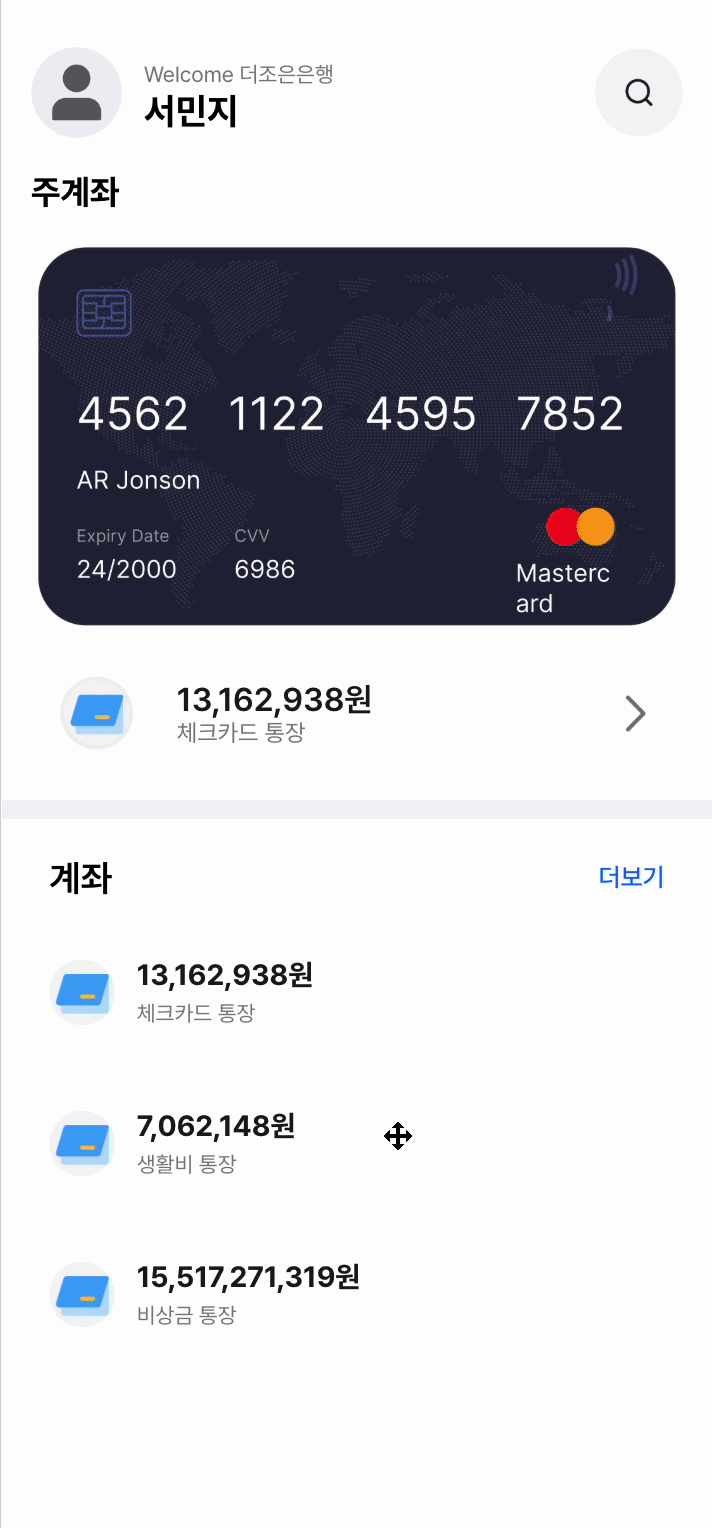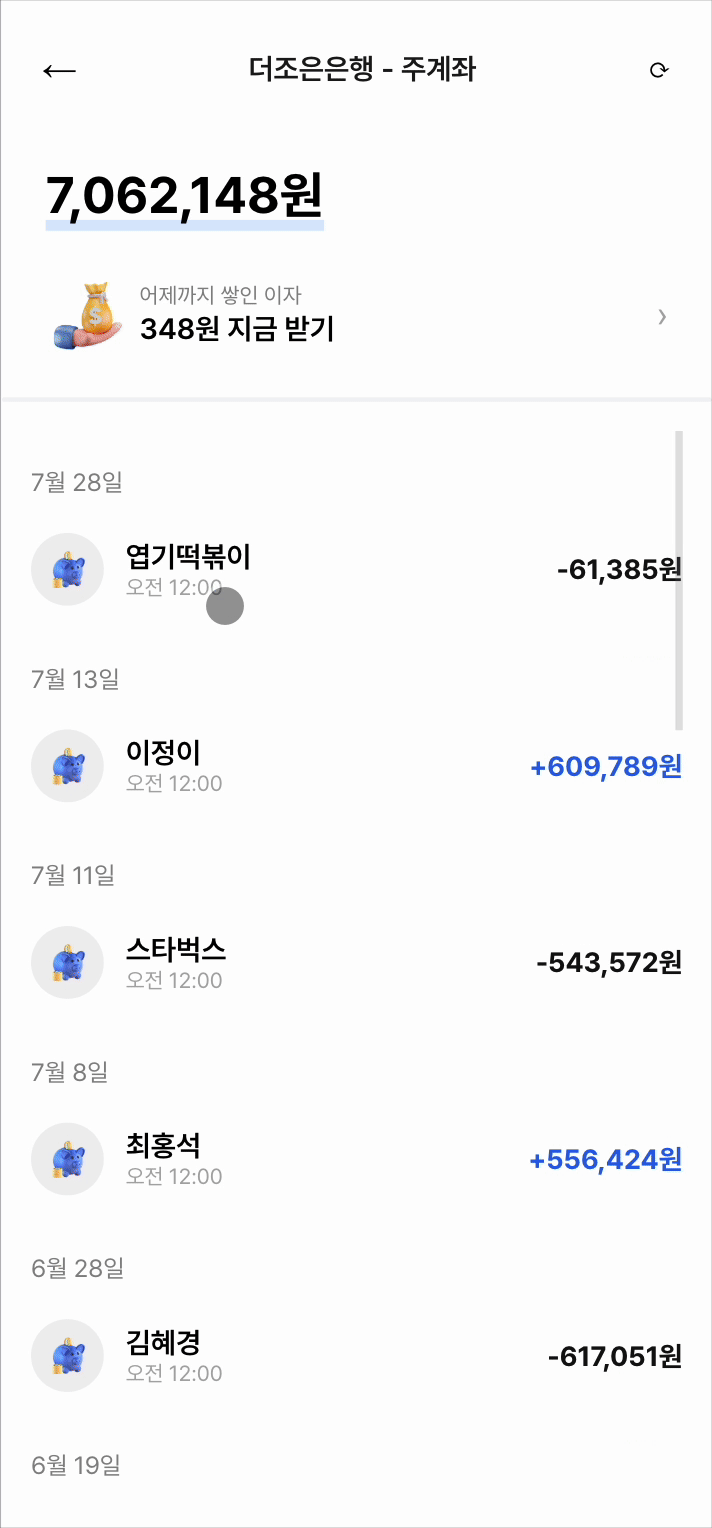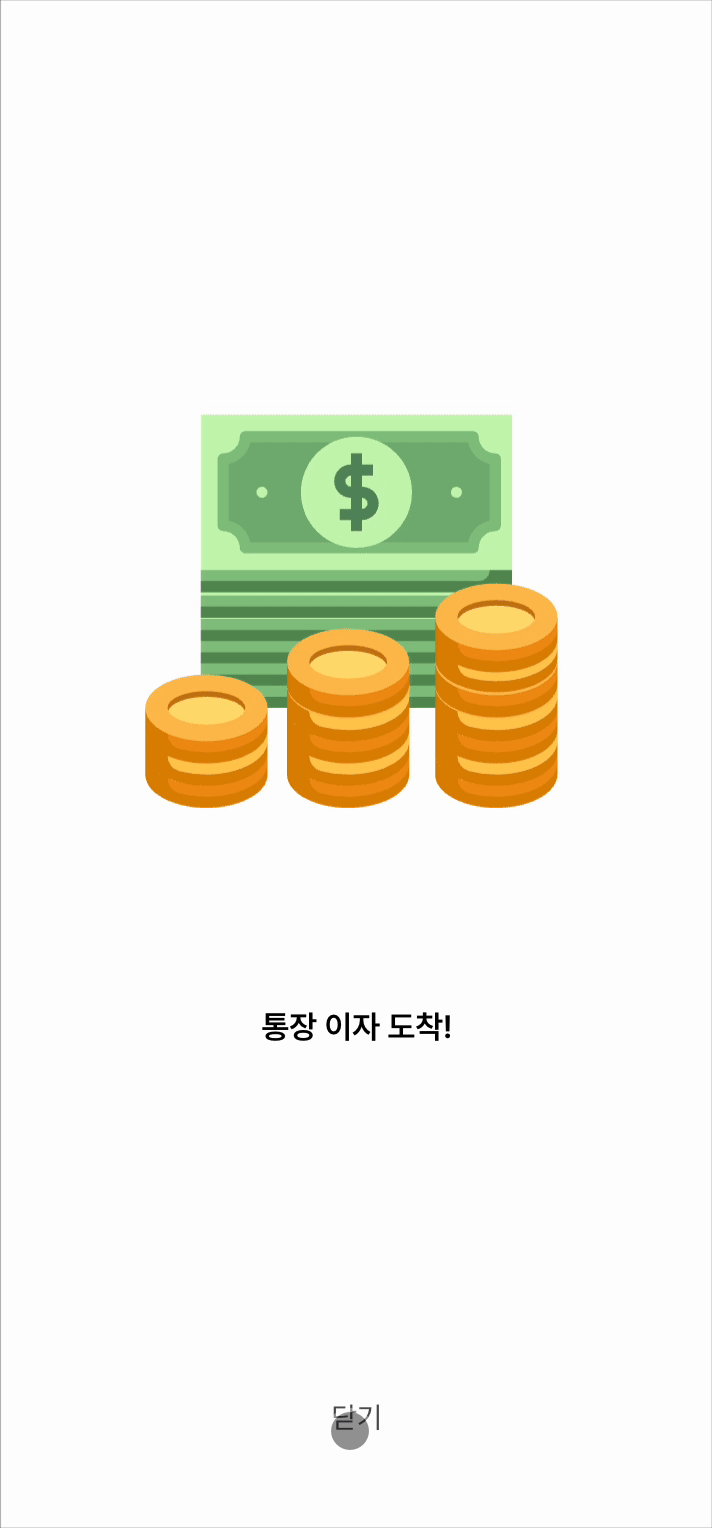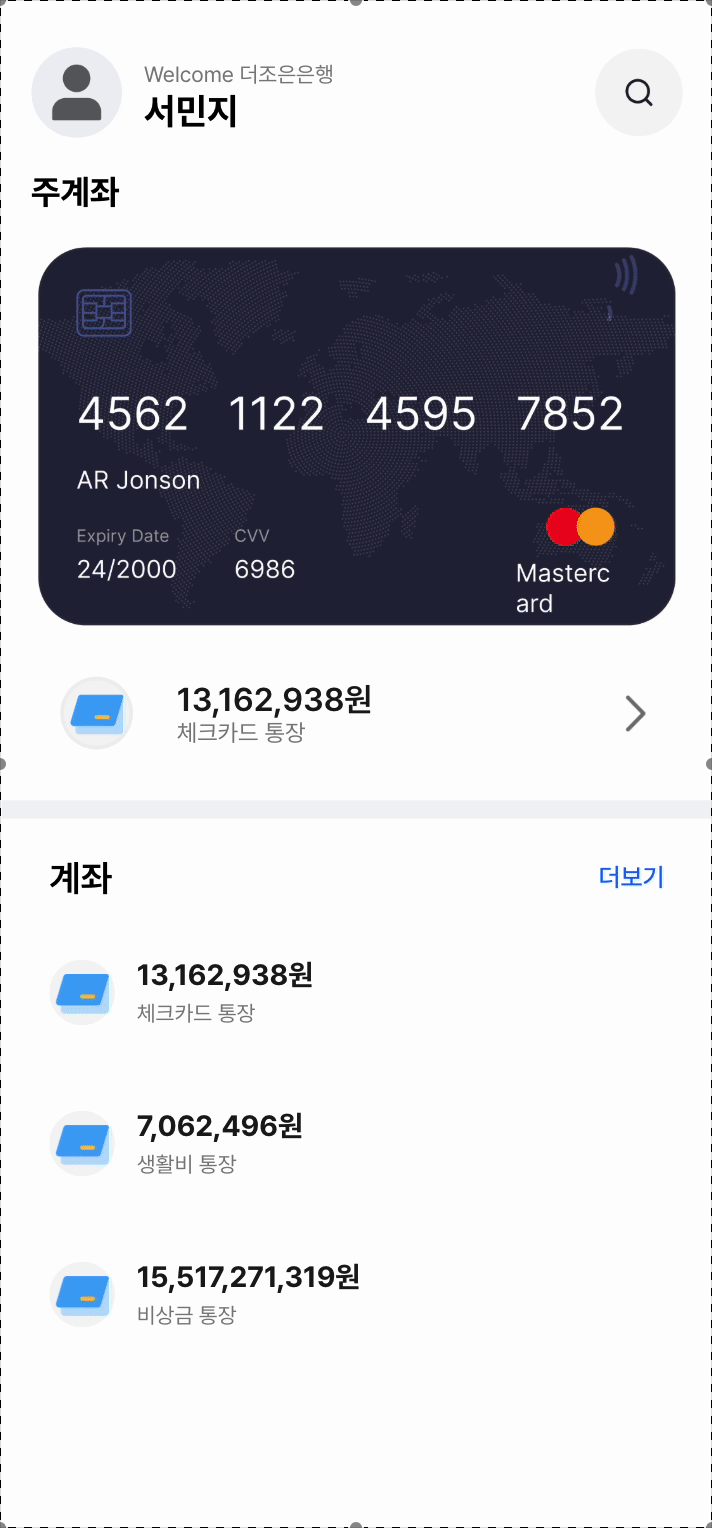
매일 이자 받기 기능에서의 병목 현상
💣 문제점 :
- 1️⃣ 하나의 이자 지급 요청에 대해 "이자 조회 → 이자 지급 → 변경 내용 조회"까지 총 3개의 API 호출이 발생
- 2️⃣ 이자 조회 기능은 계좌 상세 페이지에 진입할 때마다 호출되며, DB를 반복 조회하는 구조
➕ 많은 조회와 업데이트 요청이 집중되며, 실제 서비스에서는 세금 계산 등 복잡한 비즈니스 로직까지 추가
💥 애플리케이션 계층과 데이터베이스 계층에서 높은 부하가 발생하여 서비스 지연과 장애 발생 가능
👉 해결하기 위해 Redis 활용
Redis
이제 Redis에 대한 개념을 간단히 다뤄보겠다.
특징 및 장점
-
Redis는 인메모리 기반 고성능 데이터 저장소로, 메모리는 디스크 대비 CPU와 가까운 계층에 위치하여 월등한 I/O 성능을 제공
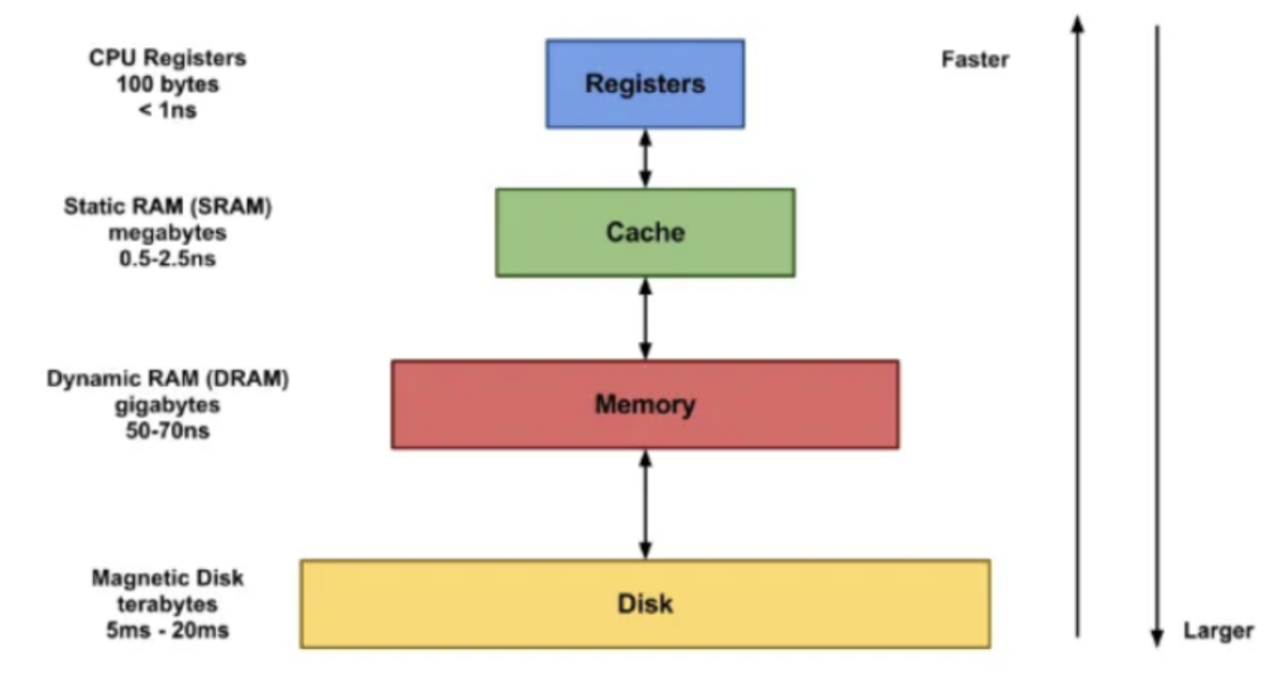
GET, SET과 같은 기본 연산을 초당 10만 건 이상 수행 가능 -
Key-Value 구조를 기반으로 하며, Value는 String, Hash, List, Set, Sorted Set 등 다양한 자료형을 지원하여 개발 편의성도 높음

-
single thread 방식으로 동작하여 동시성 문제 최소화
-
휘발성 캐시처럼 보이지만, RDB와 AOF를 통한 영속성 지원도 가능
-
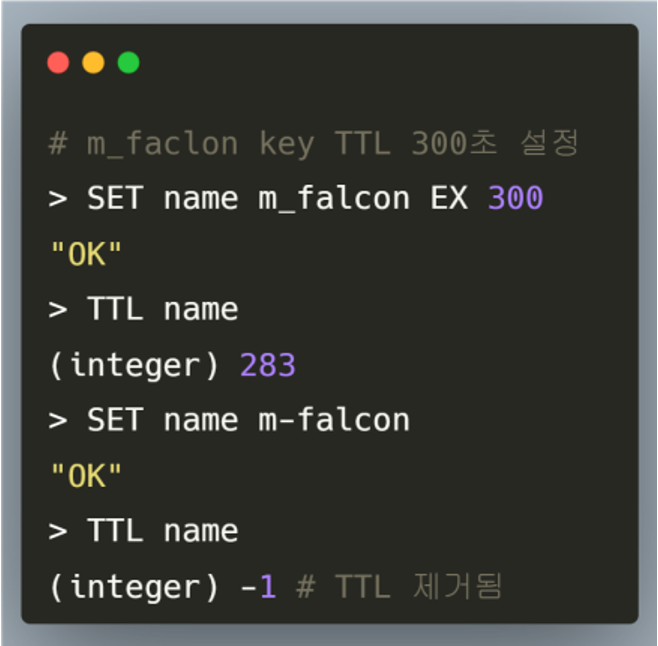
TTL을 통해 캐시 데이터에 유효 시간을 설정해 자동 만료시킴으로써 데이터 최신성 유지에 효과적
캐싱 전략
Redis 캐싱 전력은 읽기 전략과 크기 전략으로 나눠 생각할 수 있다
[ 읽기 전략 ]
1️⃣ Look-Aside 방식
: 애플리케이션이 먼저 캐시를 조회하고, 없으면 DB에서 가져와 캐시에 저장한 후 응답
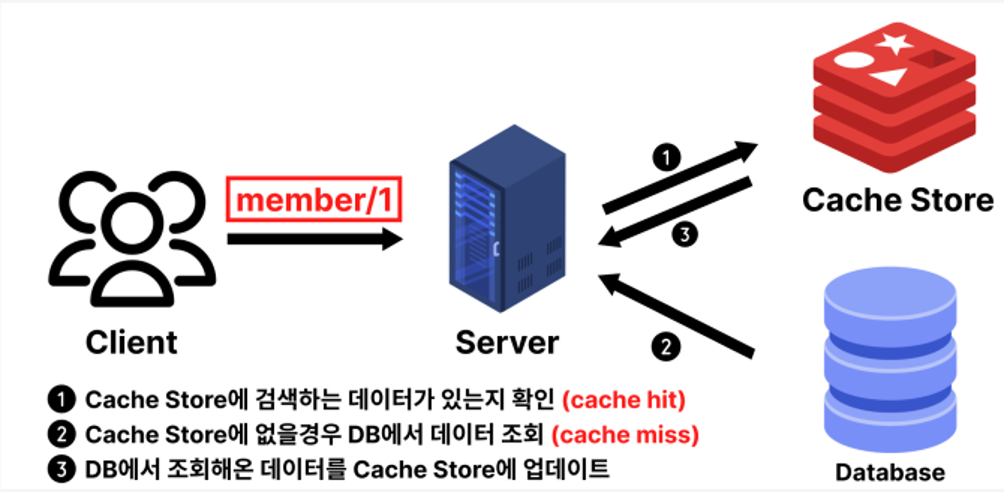
➕ 캐시 장애 시에도 DB 조회가 가능
➖ 첫 요청 시 DB 부하, 정합성 문제
참고)
- 애플리케이션 = Client + Server
- 정합성 = 데이터나 정보가 서로 모순되지 않고 일관되게 일치하는 상태
2️⃣ Read-Through 방식
: 요청이 캐시로 전달되고, 캐시에 없을 경우 캐시가 직접 DB에서 조회해 저장 후 응답
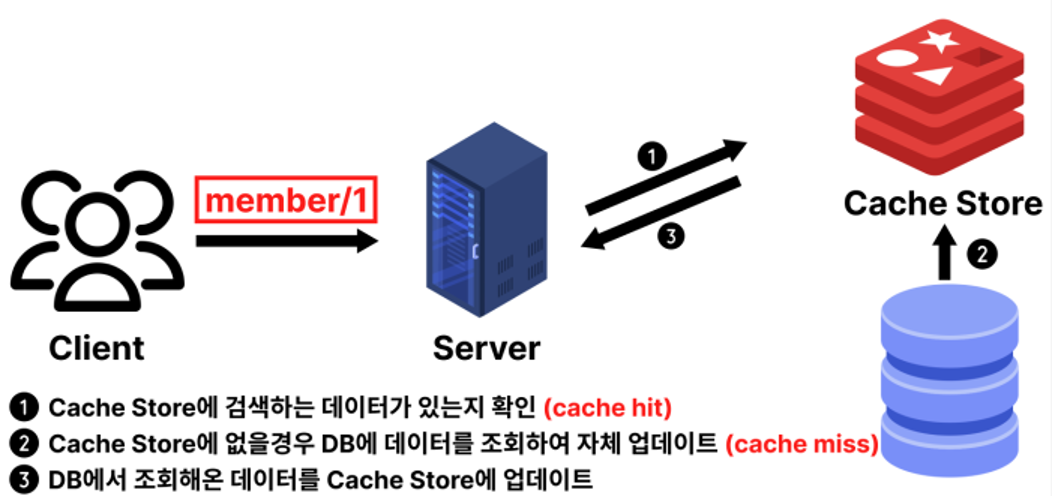
➕ 캐시가 항상 최신 데이터를 유지하므로 정합성에 유리
➖ 캐시 장애 시 전체 서비스에 영향
[ 쓰기 전략 ]
1️⃣ Write-Around 방식
: 데이터를 캐시에 저장하지 않고, DB에만 기록,
해당 데이터가 조회될 때 (= 처음 캐시 미스가 발생) 캐시에 적재
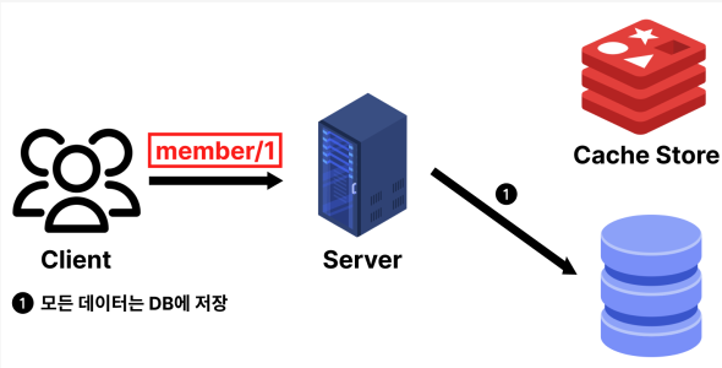
➕ 불필요한 캐시 업데이트 감소
➖ 쓰기 직후 바로 데이터를 조회하면 캐시 미스가 발생해 읽기 성능 저하 우려
2️⃣ Write Back 방식
: 캐시에 먼저 저장하고 일정 주기 후 DB에 반영
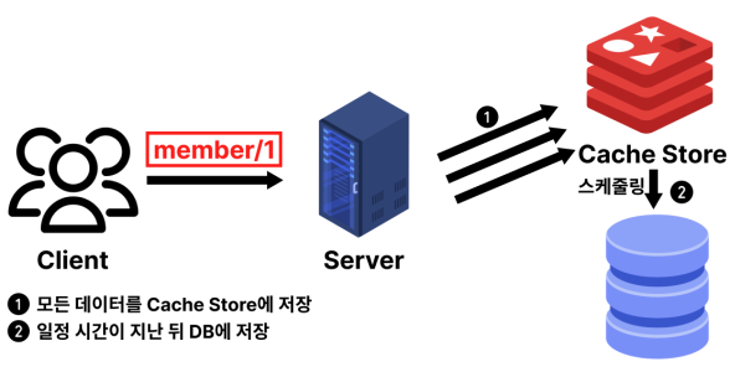
➕ 쓰기 횟수를 줄여 성능은 높음
➖ 캐시 장애 시 데이터 유실 위험
3️⃣ Write Through 방식
: 항상 캐시에 먼저 쓰고 DB에도 함께 저장
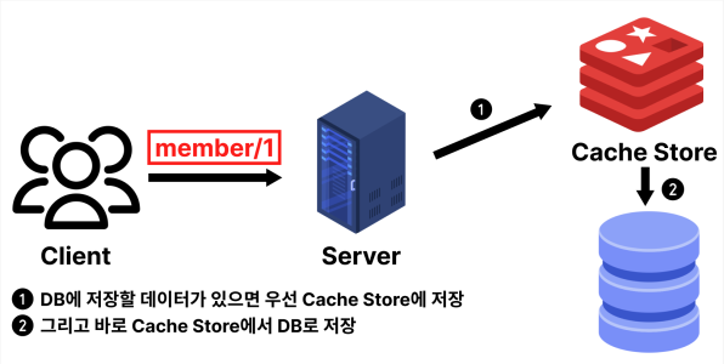
➕ 데이터 정합성 보장
➖ 쓰기 작업이 두 번 일어나기 때문에 성능 저하 우려
👀 앞서 발견한 병목 현상을 완화하기 위해, 이자 조회 결과를 Redis에 캐싱해보았다.
캐싱 과정과 효과를 검증하기 위해 성능 테스트(k6)와 시각화(grafana)를 하였고, 그 자세한 과정은 다음 편에서 이어 작성하겠다.
