Cold-Start Recommendation based on Knowledge Graph and Meta-Learning under Positive and Negative Sampling
Cold-Start Recommendation based on Knowledge Graph and Meta-Learning under Positive and Negative Sampling
DI HAN
광둥 금융대학교, 광저우, 중국
XIAOTIAN JING
시안 교통대학교, 시안, 중국
YIJUN CHEN
시안 항공대학교, 시안, 중국
JUNMIN LIU
시안 교통대학교, 시안, 중국
KAI LIAO
광둥 금융대학교, 광저우, 중국
WENTING LI
구이저우 상업대학교, 구이양, 중국
본 논문은 CRKM(Cold-start Recommendation based on Knowledge Graph and Meta-learning)이라는 새로운 추천 프레임워크를 소개합니다.
이 프레임워크는 사용자 상호작용 데이터가 부족한 문제를 해결하고,
긍정 및 부정 샘플을 융합하여 콜드스타트 추천 성능을 향상시키는 것을 목표로 합니다.
기존의 다른 콜드스타트 프레임워크와 달리, CRKM은 세 가지 주요 구성 요소로 나뉩니다:
-
부정 샘플러(Negative Sampler):
본 논문에서 설계된 부정 샘플러는 지식 그래프와 아이템의 인기도 정보를 활용하여,
사용자 상호작용이 없는 아이템에서 부정 레이블을 샘플링합니다.
이를 통해 콜드스타트 훈련 데이터의 희소성을 완화합니다. -
지식 그래프 기반 모델 아키텍처(Knowledge Graph-Based Model Architecture):
지식 그래프의 노드와 관계를 긍정 및 부정 샘플에 통합하며,
그래프 신경망(GNN)을 사용해 사용자와 아이템의 융합 표현을 더 효과적으로 학습하고,
예측 성능을 향상시킵니다. -
메타러너(Meta-Learner):
메타러너는 효율적인 모델 초기화 및 매개변수 업데이트를 수행합니다.
우리는 실제 데이터셋에서 사용자 및 아이템 추천을 위한 광범위한 실험을 수행했습니다.
CRKM은 리콜(Recall) 및 NDCG(Normalized Discounted Cumulative Gain) 측면에서
기존 최첨단 방법보다 뛰어난 성능을 보여, 제안된 접근법의 합리성과 효과성을 입증했습니다.
소스 코드는 https://gitee.com/kyle-liao/crkm에서 공개되어 있습니다.
CCS Concepts
- 정보 시스템(Information Systems) → 추천 시스템(Recommender Systems); 검색 모델 및 랭킹(Retrieval Models and Ranking); 검색 결과 평가(Evaluation of Retrieval Results).
추가 키워드(Keywords)
콜드스타트 추천(Cold-start Recommendation); 지식 그래프(Knowledge Graph); 메타러닝(Meta-Learning); 부정 레이블(Negative Label).
1. 서론 (Introduction)
인터넷과 스마트 기기의 발전으로 인해, 다양한 웹사이트, 애플리케이션, 소셜 네트워킹 플랫폼에서
데이터 양이 폭발적으로 증가했습니다.
이 방대한 데이터 속에서 추천 시스템이 등장하여,
사용자들에게 관심 있는 콘텐츠를 신속하고 정확하게 선택할 수 있도록 돕습니다.
추천 시스템의 핵심은 아이템에 대한 피드백과 과거 사용자 행동 데이터를 활용해
사용자 선호도를 파악하고, 추천 아이템을 정렬하는 것입니다.
추천 시스템은 방대한 데이터셋에서 정보를 필터링하여
사용자가 개인적인 관심사에 맞는 콘텐츠를 신속하게 찾을 수 있도록 지원하며,
정보 과부하 문제를 완화합니다.
비록 최근 다양한 추천 알고리즘이 등장했지만,
새로운 사용자나 상호작용이 적은 아이템과 같은 경우에는 여전히 콜드스타트 문제에 직면합니다.
콜드스타트 문제는 연구자들에게 중요한 관심사가 되었으며,
이는 두 가지 측면에서 주로 다뤄집니다.
1. 사용자 콜드스타트(User Cold Start):
과거 상호작용이 거의 없는 새로운 사용자에게 적합한 아이템을 추천하는 문제.
2. 아이템 콜드스타트(Item Cold Start):
시스템에 새롭게 추가된 아이템을 적합한 사용자에게 추천하는 문제.
콜드스타트 문제의 핵심 원인은 데이터의 제한된 가용성으로, 이는 추천 성능을 저하시킵니다.
성능 개선을 위해 더 많은 데이터를 확보해야 하며, 이를 해결하기 위해
연구자들은 다양한 방법을 제안했습니다.
이 방법들은 크게 데이터 수준 접근법(Data-Level Methods)과 모델 수준 접근법(Model-Level Methods)으로 나뉩니다.
데이터 수준 접근법 (Data-Level Methods)
콜드스타트 문제의 주요 원인은 활용 가능한 데이터의 부족입니다.
따라서 데이터 수준에서 문제를 해결하는 것이 중요합니다.
먼저, 기존 데이터를 효율적으로 활용하는 것이 필요합니다.
추천 시스템에서 관찰된 상호작용 데이터는 주로 암묵적 피드백(Implicit Feedback) 형태로 나타나며,
이는 사용자로부터 긍정적인 선호 정보만 제공합니다.
그러나 관찰되지 않은 샘플에서 부정적인 선호 정보는 종종 간과됩니다.
현재, 사용자와 상호작용하지 않은 아이템에 부정 레이블을 추가하여 데이터를 확장하는
다양한 방법이 존재하며, 이는 모델 최적화를 용이하게 합니다.
둘째로, 보조 정보를 효과적으로 활용하는 것도 중요합니다.
최근 지식 그래프(Knowledge Graph)는 추천 시스템에서 중요한 보조 정보의 출처로 주목받고 있습니다.
지식 그래프는 사용자와 아이템 간의 추가적인 정보를 발견하여,
역사적 상호작용 데이터의 희소성을 보완하고 추천 성능을 개선할 수 있습니다.
이러한 방법들은 좋은 결과를 보여줬지만, 데이터 수준에서만 문제를 완화하며,
데이터의 가용성과 품질에 크게 의존합니다.
본 논문에서는 [5]에서 영감을 받아, 지식 그래프를 활용하여 부정 레이블의 상호작용 정보를 개선하고,
주의 메커니즘(Attention Mechanism)을 통해 긍정 샘플의 잡음을 제거함으로써
콜드스타트 데이터를 더욱 풍부하게 만들고자 합니다.
모델 수준 접근법 (Model-Level Methods)
데이터 수준 확장 외에도, 최근 몇 년 동안 간단하고 효율적인 콜드스타트 모델과 메타러닝 접근법이
콜드스타트 문제를 해결하기 위한 새로운 아이디어를 제공했습니다.
메타러닝은 콜드스타트 추천에서 각 사용자의 선호 학습을 개별 태스크(Task)로 간주합니다.
메타러너(meta-learner)는 기존 사용자들의 태스크에서 강력한 일반화 능력을 가진 사전 지식을 학습하며,
이를 통해 희소한 상호작용 데이터를 가진 콜드스타트 태스크에
쉽고 빠르게 적응할 수 있도록 지원합니다.
하지만 기존 모델에는 여전히 한계가 있으며 [3],
지식 그래프의 다면적 의미 정보를 메타러너와 더 잘 통합하는 방법에 대한 추가 탐구가 필요합니다.
본 논문에서 설계된 콜드스타트 추천 프레임워크는 데이터 수준에서 샘플을 더 정확하게 구분할 수 있으며,
프레임워크 내 메타러너 [6]는 콜드스타트 태스크에 더 빠르게 적응할 수 있도록 설계되었습니다.
우리의 기여 (Our Contributions)
추천 시스템에서 콜드스타트 상황에서 고품질 데이터를 확보하고,
사용 가능한 데이터를 보완하기 위해, 우리는 지식 그래프와 메타러닝을 기반으로
보다 효과적인 콜드스타트 추천 모델 CRKM을 제안합니다.
-
데이터 수준:
지식 그래프를 보조 정보로 활용하여 사용자와 아이템 표현을 풍부하게 만듭니다. -
모델 수준:
메타러너를 지식 그래프 기반 추천 모델에 통합하여 콜드스타트 문제를 완화하고,
추천 성능을 개선합니다.
본 연구의 주요 기여는 다음과 같이 요약됩니다:
-
지식 그래프 기반의 혁신적인 부정 샘플링 기법을 설계
이 기법은 고품질 부정 레이블을 아이템에서 추출함으로써 데이터셋 활용성을 높입니다.
이 전략은 사용자와 아이템 간의 상호작용 정보를 보완하여
추천의 정확성과 효율성을 개선합니다. -
지식 그래프 기반 모델 아키텍처를 구축
그래프 신경망(GNN)을 활용하여 사용자와 아이템 간 숨겨진 고차원 관계를 학습합니다.
특히, 게이트 주의 메커니즘(Gate Attention Layer)을 설계하여
의미적 관계를 구분하고 보다 정밀한 아이템 표현을 획득합니다.
또한, 부정 주의 메커니즘(Negative Attention Mechanism)을 설계하여
긍정 샘플의 잡음을 효과적으로 제거하며, 사용자 표현을 강화합니다.
마지막으로, 융합 레이어(Fusion Layer)를 도입하여 사용자와 아이템의
긍정 및 부정 표현 샘플에 가중치를 할당하여, 최종 표현을 예측 태스크에 활용합니다. -
메타러너를 모델에 도입
각 사용자의 선호 학습을 메타러닝 프레임워크 내의 태스크로 간주합니다.
기존 사용자의 태스크에서 높은 일반화 능력을 가진 사전 지식을 학습하여,
메타러너는 콜드스타트 태스크에 빠르게 적응하고 추천 성능을 향상시킵니다.
실험 및 성과 (Experiments and Results)
콜드스타트 문제를 다양한 상황에서 해결하기 위해,
음악, 도서, 쇼핑 도메인에 대한 세 가지 공개 벤치마크 데이터셋에서 실험을 수행했습니다.
이 실험에서는 제안된 모델과 여러 기준선(Baseline) 모델을 비교하여 효과성을 검증했습니다.
실험 결과, 제안된 모델이 다른 기준선 모델보다 뛰어난 성능을 보였습니다.
논문의 구조 (Structure of the Paper)
이 논문의 나머지 구성은 다음과 같습니다:
- 2장: 관련 연구 개요를 제공합니다.
- 3장: 제안된 방법을 자세히 설명합니다.
- 4장: 제안된 모델을 평가하기 위한 실험 결과를 제시합니다.
- 5장: 논문을 요약하고 잠재적인 향후 연구 방향을 논의합니다.
2. 관련 연구 (RELATED WORK)
콜드스타트 문제에 대한 연구는 두 가지 주요 측면에 중점을 둡니다:
사용자 콜드스타트(User Cold-Start)와 아이템 콜드스타트(Item Cold-Start)입니다.
사용자 콜드스타트는 제한적이거나 전혀 상호작용 데이터가 없는 "새로운" 사용자에게 아이템을 추천하는 문제를 다룹니다.
아이템 콜드스타트는 시스템에 새롭게 추가된 "새로운" 아이템을 적합한 사용자에게 추천하는 문제를 다룹니다.
콜드스타트 문제는 어느 측면에서든 추천 시스템의 효율성을 저하시킵니다.
따라서, 연구자들은 이 문제를 해결하기 위해 다양한 방법을 제시했습니다.
문제를 해결하려면 사용자 데이터와 아이템 정보를 효과적으로 활용해야 하며,
많은 제안된 솔루션은 부족한 정보를 보완하는 데 중점을 둡니다.
데이터 증강 활용
최근 몇 년 동안 많은 연구자들이 사용자나 아이템 특징을 활용하여
데이터 증강을 통해 콜드스타트 문제를 해결하려고 했습니다.
-
Anwaar 등 [1]은 암묵적 상호작용 데이터와 보조 아이템 정보를 결합하여
아이템 콜드스타트 문제를 해결했습니다.
이들은 Word2Vec [18]을 사용해 아이템 설명을 획득하고,
콘텐츠 임베딩을 협업 필터링에 통합하는 새로운 접근법을 제안했습니다. -
Zhang 등 [35]은 행렬 분해(Matrix Factorization)와 마르코프 체인(Markov Chain)을 결합한
JPMC(Joint Personalized Markov Chains) 프레임워크를 제안했습니다.
이들은 node2vec [8] 알고리즘을 사용해 사용자 특징 표현을 사전 학습했으며,
네트워크 이웃을 활용해 새로운 사용자를 나타내고,
동적 및 정적 선호도를 공동으로 모델링하여 사용자 콜드스타트 문제를 해결했습니다. -
또한, 일부 방법은 의사 레이블(Pseudo-Labeling)을 도입하여 사용자 및 아이템 임베딩 학습을 지원했습니다.
예를 들어, Togashi 등 [24]은 지식 그래프를 활용한 샘플링 방법을 제안하여,
관찰되지 않은 샘플에 의사 레이블을 부여하고 데이터 증강을 통해 사용자와 아이템의 콜드스타트 문제를 완화했습니다. -
Wu 등 [32]은 사용자 과거 상호작용 데이터를 모델링하기 위해
하이퍼그래프 표현을 도입했습니다.
이들은 하이퍼그래프를 긍정 하이퍼그래프와 부정 하이퍼그래프로 나누고,
부정 하이퍼그래프를 활용해 부정 임베딩을 학습함으로써
사용자와 아이템 표현 학습을 개선했습니다.
심층 신경망 모델 활용
최근에는 심층 신경망 모델을 활용해 다양한 보조 정보를 학습하고,
추천 시스템 성능을 향상시키는 연구가 활발히 이루어지고 있습니다.
-
Wei 등 [29]은 협업 필터링과 신경망을 결합한 추천 모델을 제안했습니다.
이들은 Stacked Denoising Autoencoder(SDAE) [25]를 사용하여
아이템의 콘텐츠 특징을 추출했으며,
timeSVD++ [14] 모델에 콘텐츠 특징을 통합하여
아이템 콜드스타트 문제에서 사용자 선호와 아이템의 시간적 동태를 모델링했습니다. -
Sun 등 [23]은 아이템 속성 정보를 활용한 새로운 콜드스타트 추천 모델을 제안했습니다.
이들은 생성적 적대 신경망(GAN)을 사용해,
특정 아이템에 관심이 있는 사용자의 표현을 직접 추출했습니다. -
Li 등 [16]은 제로샷 학습(Zero-Shot Learning) 방법을 활용하여
콜드스타트 문제를 해결했습니다.
이들은 저차원 선형 오토인코더(Low-Rank Linear Autoencoder)를 제안했으며,
인코더는 사용자 행동을 사용자 속성으로 매핑하고,
디코더는 사용자 속성을 기반으로 사용자 행동을 재구성하여
사용자 속성 정보를 더 효과적으로 활용했습니다.
이질 데이터 활용
아이템과 기타 엔터티 간의 풍부한 이질 데이터를 활용하는 연구도 주목받고 있습니다.
-
Shi 등 [22]은 메타 경로 기반 이질 네트워크 임베딩 방법을 제안했으며,
이는 의미적 및 구조적 정보를 추출하여,
확장된 행렬 분해 모델에 활용하여 추천 성능을 향상시켰습니다. -
Hu 등 [13]은 협업 주의 메커니즘(Collaborative Attention Mechanism)을 사용한
네트워크 모델을 도입했습니다.
이 모델은 사용자-아이템 상호작용 데이터를 기반으로,
메타 경로를 통해 컨텍스트 표현을 개선하고,
사용자와 아이템 표현을 더욱 향상시켰습니다. -
Cai 등 [2]은 새로운 사용자, 아이템, 관련 멀티모달 정보를
모달리티 인식 이질 그래프로 변환하는
새로운 이질 그래프 신경망(Heterogeneous Graph Neural Network)을 제안했습니다.
이를 통해 새로운 사용자의 희소한 속성 정보를 풍부하게 만들었습니다.
메타러닝 활용
보조 정보를 사용하여 누락된 데이터를 채우는 방법은 좋은 성능을 보여줬지만,
데이터 가용성, 품질, 사용자 프라이버시 우려로 인해 효과가 제한될 수 있습니다.
따라서 연구자들은 메타러닝을 활용해 콜드스타트 문제를 해결하는 방법을 탐구하기 시작했습니다.
-
MeLU (Meta-Learned User Preference Estimator) 모델 [15]은
MAML [6] 알고리즘을 기반으로 한 사용자 콜드스타트 추천 모델을 제안했습니다.
이 모델은 우수한 초기화 매개변수를 학습하여
새로운 사용자의 관심사와 선호에 신속히 적응할 수 있도록 합니다. -
Wei 등 [30]은 MetaCF(Meta Collaborative Filtering)라는 새로운 학습 패러다임을 제안했습니다.
이는 사용자 보조 정보에 의존하지 않으며,
훈련 단계에서 사용자 중심의 서브그래프를 동적으로 샘플링하여
대표적인 훈련 태스크를 구성함으로써 모델 일반화를 촉진합니다.
이를 통해 상호작용 기록이 제한적인 새로운 사용자에 빠르게 적응할 수 있습니다. -
Du 등 [5]은 지식 그래프를 결합한 새로운 메타러닝 프레임워크를 제안했습니다.
이 프레임워크는 두 개의 메타러너를 교대로 학습하며,
하나는 지식 그래프에서 의미적 관계를 학습하고,
다른 하나는 개별 사용자의 선호 표현을 학습합니다.
결론
추천 시스템의 콜드스타트 문제를 해결하기 위해 다양한 방법이 제안되었습니다.
여기에는 보조 정보 활용과 메타러닝 기술 도입이 포함됩니다.
그러나 이러한 방법에도 여전히 한계가 있으며,
콜드스타트 문제는 추천 시스템에서 가장 어려운 도전 과제 중 하나로 남아 있습니다.
본 논문에서는 MetaKG [5]에서 영감을 받아,
상호작용 데이터를 풍부하게 만들기 위해 부정 레이블을 도입했습니다.
또한, 지식 그래프와 메타러닝을 보다 잘 결합하여
콜드스타트 문제를 해결하는 방법을 탐구하고,
콜드스타트 프레임워크의 전체 처리 과정을 최적화했습니다.
3. 공식화 및 방법론 (FORMULATION AND METHODOLOGY)
본 장에서는 먼저 연구 문제를 상세히 설명하고, 제안된 모델의 개요를 제공합니다.
다음으로, 전체 모델의 네 가지 주요 구성 요소인 부정 샘플러(Negative Sampler),
지식 그래프 기반 모델 아키텍처(Knowledge Graph-Based Model Architecture), 메타러너(Meta-Learner),
그리고 모델 학습(Model Training)을 소개합니다.
3.1 문제 정의 (Problem Description)
본 논문의 초점은 지식 그래프와 메타러닝 접근법을 활용하여
콜드스타트 추천 성능을 향상시키는 데 있습니다.
연구 문제를 명확히 설명하기 위해, 본 연구와 관련된 개념을 먼저 소개하고 정의한 후,
해당 문제를 최적화해야 하는 동기를 설명합니다.
협업 지식 그래프 (Collaborative Knowledge Graph)
제안된 CRKM 프레임워크는 사용자-아이템 상호작용 이분 그래프와 지식 그래프를
결합한 협업 지식 그래프(Collaborative Knowledge Graph)를 중심으로 설계되었습니다.
CRKM의 특징 엔지니어링 설계는 다음과 같이 설명됩니다:
-
사용자-아이템 상호작용 이분 그래프 (User-Item Interaction Bipartite Graph)
추천 시스템에서는 일반적으로 사용자 집합 ,
아이템 집합 ,
그리고 사용자-아이템 선호도를 나타내는 상호작용 행렬 이 주어집니다.사용자 와 아이템 간의 상호작용이 존재하면 ,
그렇지 않으면 입니다.
사용자가 아이템과 상호작용하는 관계는 삼중항(triplet)으로 표현할 수 있습니다.
따라서, 사용자-아이템 상호작용 이분 그래프는 다음과 같이 정의됩니다: -
지식 그래프 (Knowledge Graph)
사용자-아이템 상호작용 외에도, 아이템의 보조 정보를 보완하고
사용자와 아이템 간 고차원 관계를 포착하기 위해 지식 그래프를 도입합니다.
지식 그래프는 일반적으로 삼중항으로 표현되며, 현실 세계의 사실을 설명합니다.
정의는 다음과 같습니다:여기서 는 헤드 엔터티 와 테일 엔터티 간의 관계 을 나타냅니다.
는 엔터티 집합, 은 관계 집합입니다. -
아이템-엔터티 정렬 (Item-Entity Alignment)
사용자-아이템 상호작용 이분 그래프 과 지식 그래프 를 기반으로,
아이템과 엔터티의 정렬 집합 를 정의합니다.
여기서 는 아이템 와 엔터티 간의 정렬을 나타냅니다.
이는 모든 아이템이 지식 그래프의 엔터티에 포함됨을 의미합니다. -
협업 지식 그래프 정의 (Definition of Collaborative Knowledge Graph)
사용자-아이템 상호작용 이분 그래프 과 지식 그래프 를
아이템-엔터티 정렬 집합 를 기반으로 결합하여 협업 지식 그래프를 정의합니다.여기서 는 엔터티와 사용자를 포함하고,
는 관계와 사용자-아이템 상호작용을 포함합니다.긍정 협업 지식 그래프 ()는
긍정 사용자-아이템 상호작용 이분 그래프 를 사용하여 구축되며,
부정 협업 지식 그래프 ()는
부정 샘플링을 통해 얻어진 부정 사용자-아이템 상호작용 이분 그래프 를 사용하여 구축됩니다.
최적화 문제 정의 (Optimization Problem Definition)
앞서 설명한 협업 지식 그래프(CKG)를 기반으로,
추천 시스템에서 콜드스타트 문제를 해결하기 위한 최적화 문제는 다음과 같이 정의됩니다:
-
입력(Input):
- 긍정 및 부정 협업 지식 그래프 와
- 이는 긍정 및 부정 사용자-아이템 상호작용 이분 그래프 와 ,
그리고 지식 그래프 를 포함합니다.
-
출력(Output):
- 함수 는 사용자 가 상호작용하지 않은 아이템 에 대한 평점을 예측합니다.
콜드스타트 문제는 다음 세 가지로 나뉩니다:
1. 사용자 콜드스타트(UC): 새로운 사용자와 기존 아이템 간 상호작용 예측.
2. 아이템 콜드스타트(IC): 기존 사용자와 새로운 아이템 간 상호작용 예측.
3. 사용자-아이템 콜드스타트(UIC): 새로운 사용자와 새로운 아이템 간 상호작용 예측.
본 논문의 목표는 지식 그래프와 메타러닝을 기반으로 한 추천 모델을 구축하여,
위 세 가지 콜드스타트 문제(UC, IC, UIC)를 해결하는 것입니다.
3.2 CRKM 개요 (Overview of CRKM)
본 논문에서 제안한 CRKM 프레임워크의 전체 구조는 그림 1에 나와 있으며,
이 프레임워크는 부정 샘플러(Negative Sampler), 지식 그래프 기반 모델 아키텍처(Base Model),
메타러너(Meta-Learner)의 세 가지 구성 요소로 나뉩니다.
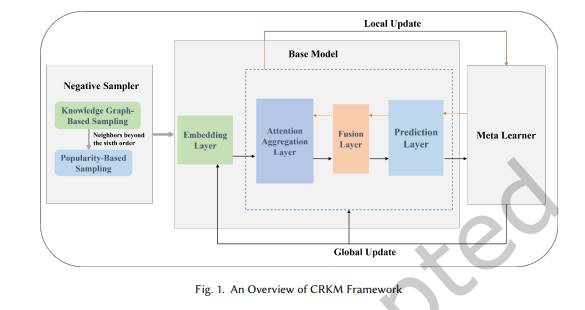
그림 1. CRKM 프레임워크 개요
-
부정 샘플러는 지식 그래프와 아이템의 인기도 정보를 활용하여
사용자가 상호작용하지 않은 아이템에서 부정 레이블을 샘플링하여
콜드스타트 훈련 데이터의 희소성을 보완합니다. -
지식 그래프 기반 모델 아키텍처(Base Model)는
그래프 신경망(GNN)을 사용하여 사용자와 아이템의 특징 표현을 생성하고,
선호도 점수를 예측합니다.
이 아키텍처는 임베딩 레이어(Embedding Layer), 주의 집계 레이어(Attention Aggregation Layer),
융합 레이어(Fusion Layer), 예측 레이어(Prediction Layer)로 구성됩니다. -
메타러너는 지역(Local) 업데이트와 글로벌(Global) 업데이트를 사용하여
모델의 초기 매개변수를 학습합니다.- 지역 업데이트(Local Update)는 그림 1의 주황색 선으로 표시되며,
각 태스크에서 사용자의 개인화된 선호도를 학습합니다. - 글로벌 업데이트(Global Update)는 그림 1의 검은색 선으로 표시되며,
다양한 태스크에 걸쳐 지식 그래프의 공통 의미 표현을 학습합니다.
메타러너는 기존 사용자 태스크에서 강력한 일반화 능력을 가진 사전 지식을 학습함으로써
콜드스타트 태스크에 빠르게 적응하고 추천 성능을 향상시킵니다.
- 지역 업데이트(Local Update)는 그림 1의 주황색 선으로 표시되며,
3.3 부정 샘플러 (Negative Sampler)
추천 시스템의 회상(Recall) 과정에서 기존 데이터를 효율적으로 활용하는 것은
널리 사용되는 효과적인 접근 방식입니다.
따라서 본 논문에서는 사용자-아이템 상호작용 데이터를 활용하고,
부정적으로 샘플링된 데이터(상호작용 데이터의 보완 집합)를
전이하여 데이터 증강을 수행합니다 [32].
기존 부정 샘플링 기법
일반적으로 사용되는 휴리스틱 부정 레이블 샘플링 방법에는
랜덤 부정 샘플링(Random Negative Sampling)과
인기도 기반 부정 샘플링(Popularity-Based Negative Sampling)이 있습니다.
-
랜덤 부정 샘플링(Random Negative Sampling)
- 이 방법은 샘플링 풀에 있는 모든 아이템을 동일하게 취급하며,
동일한 확률로 샘플링합니다 [20]. - 이해하기 쉽고 구현이 간단하며 샘플링 효율이 높아,
현재까지 가장 널리 사용되는 샘플링 방법입니다.
- 이 방법은 샘플링 풀에 있는 모든 아이템을 동일하게 취급하며,
-
인기도 기반 부정 샘플링(Popularity-Based Negative Sampling)
- 이 방법은 훈련 효율을 높이기 위해,
인기가 높은 아이템을 부정 샘플로 선택하는 방식입니다 [4]. - 이는 롱테일(long-tail) 아이템(예: 콜드스타트 아이템)을 부정 샘플로 선택하는
빈도를 줄이며, 흥미로울 가능성이 있는 아이템이 부정 샘플로 오분류되는 것을 방지합니다.
- 이 방법은 훈련 효율을 높이기 위해,
인기도 기반 부정 샘플링은 랜덤 샘플링보다 더 많은 정보를 제공하며,
다양한 모델에서 부정 샘플링을 위해 널리 사용됩니다.
지식 그래프 기반 부정 샘플링 (Knowledge Graph-Based Sampling)
본 논문에서는 지식 그래프 경로를 활용한 부정 샘플링 기법을 도입하여,
부정 레이블 샘플링의 범위를 좁히고, 보다 정확한 부정 샘플을 얻습니다.
이 방법은 다음 두 단계로 구성됩니다.
1. 지식 그래프 기반 샘플링
지식 그래프에서는 인접 엔터티가 더 유사하며,
사용자는 상호작용한 아이템의 고차 이웃에 있는 아이템에
더 관심을 가질 가능성이 높습니다.
이에 따라 지식 그래프에서 너비 우선 탐색(Breadth-First Search, BFS) 알고리즘을 사용하여,
각 상호작용 아이템에서 비상호작용 아이템으로 이어지는 경로를 탐색합니다.
사용자를 루트 노드로 설정하고, 사용자가 상호작용한 모든 아이템을 탐색하며,
이 아이템들의 경로를 지식 그래프에서 순회합니다.
검색 경로 외부에 있는 아이템에서 부정 레이블을 추출합니다.
특히, 각 사용자-아이템 상호작용 쌍 에 대해
아이템 를 루트 노드로 설정한 후, 지식 그래프 에서 경로를 탐색합니다.
여기서 , , 이며,
는 탐색할 이웃 차수의 수를 나타내며, 입니다.
즉, 상호작용 아이템의 6차 이웃을 초과하는 아이템에서 부정 레이블을 추출합니다.
이러한 아이템은 사용자의 관심에서 더 멀리 떨어져 있는 것으로 간주됩니다.
2. 인기도 기반 샘플링
지식 그래프 탐색을 통해 아이템의 고차 이웃을 얻은 후,
해당 아이템의 6차 이웃을 제외하고 인기도 기반 샘플링을 수행합니다.
아이템 인기도는 다양한 방법으로 정의될 수 있지만,
본 논문에서는 아이템의 과거 상호작용 횟수로 정의합니다.
구체적으로, 아이템이 선택된 횟수가 많을수록 인기도가 높아집니다.
특정 아이템의 인기도는 다음 공식으로 계산됩니다:
여기서 는 아이템 가 사용자와 상호작용한 횟수를 나타내며,
는 모든 아이템의 총 상호작용 횟수입니다.
요약
본 논문에서 제안된 부정 샘플링의 최적화 동기는
지식 그래프를 기반으로 사용자 상호작용 아이템의 6차 이웃을 검색한 후,
인기도에 따라 확률적으로 샘플링하여 부정 협업 지식 그래프()를 구성하는 데 있습니다.
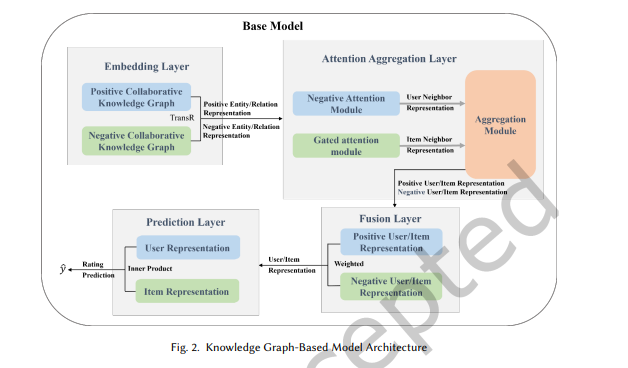
3.4 지식 그래프 기반 모델 아키텍처 (Knowledge Graph-Based Model Architecture)
본 논문에서 제안한 지식 그래프 기반 모델 아키텍처(Base Model)는
아이템 정보를 풍부하게 만들고, 지식 그래프 내 고차원 관계를
엔드투엔드 방식으로 학습하여, 추천 시스템에서 콜드스타트 문제를 해결합니다.
그림 2는 이 기본 모델의 구조를 보여주며, 네 가지 주요 구성 요소로 구성됩니다:
1. 임베딩 레이어(Embedding Layer):
TransR 알고리즘 [17]을 사용하여 긍정 및 부정 협업 지식 그래프의 노드와 관계에 대한 임베딩 표현을 학습합니다.
-
주의 집계 레이어(Attention Aggregation Layer):
게이트 주의 모듈(Gated Attention Module)과 부정 주의 모듈(Negative Attention Module)을 사용하여
아이템 및 사용자 노드 이웃의 임베딩 표현을 학습합니다.
이러한 표현은 집계 모듈에서 노드 자체의 임베딩과 통합됩니다. -
융합 레이어(Fusion Layer):
협업 지식 그래프에서 학습된 사용자 및 아이템의 긍정적, 부정적 노드 표현을 결합하여
노드의 최종 표현을 얻습니다. -
예측 레이어(Prediction Layer):
사용자의 아이템 선호도를 예측하기 위해 사용자와 아이템의 최종 표현을 사용합니다.
3.4.1 임베딩 레이어 (Embedding Layer)
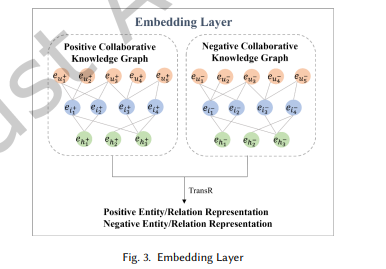
지식 그래프의 엔터티와 관계 임베딩은 그래프의 구조적 정보를 보존합니다.
본 논문에서는 긍정 및 부정 협업 지식 그래프에서 TransR 알고리즘을 사용하여
엔터티와 관계에 대한 임베딩을 학습합니다.
그림 3은 임베딩 레이어를 보여줍니다.
긍정 협업 지식 그래프 내 삼중항 에 대해,
해당 에너지 점수(energy score)는 다음과 같이 정의됩니다:
여기서:
- 는 초기 엔터티 임베딩,
- 는 초기 관계 임베딩,
- 는 엔터티 공간에서 관계 공간으로의 투영 행렬입니다.
이 에너지 점수를 사용하여 훈련하며,
낮은 에너지 점수는 해당 삼중항이 참일 가능성이 높음을 나타냅니다.
3.4.2 주의 집계 레이어 (Attention Aggregation Layer)
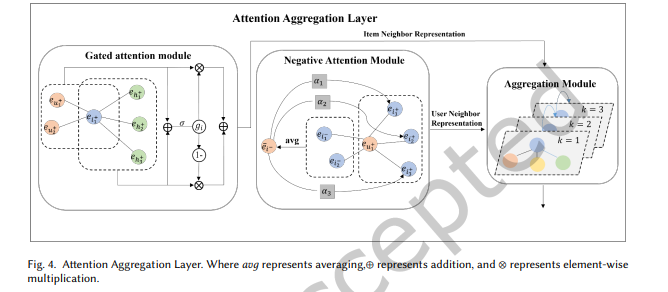
이 레이어는 긍정 및 부정 협업 지식 그래프 모두에 대해 동일한 정보 전달 및 집계 연산을 수행합니다.
긍정 협업 지식 그래프를 예로 들어 설명하겠습니다.
그림 4는 이 레이어가 게이트 주의 모듈(Gated Attention Module),
부정 주의 모듈(Negative Attention Module), 그리고 집계 모듈(Aggregation Module)로 구성됨을 보여줍니다.
게이트 주의 모듈 (Gated Attention Module)
협업 지식 그래프에서, 아이템 엔터티는 두 가지 유형의 이웃을 가집니다:
- 사용자 이웃(User Neighbors): 아이템의 잠재적 요구사항을 제공합니다.
- 엔터티 이웃(Entity Neighbors): 보조 정보를 제공합니다.
아이템 엔터티의 표현을 더 정확히 학습하기 위해,
이웃 표현 집계 과정에서 게이트 메커니즘을 도입하여
두 이웃 유형 간의 차이를 반영합니다.
사용자-아이템 삼중항은 다음과 같이 정의됩니다:
엔터티-아이템 삼중항은 다음과 같이 정의됩니다:
사용자-아이템 삼중항을 예로 들면, 정보 전달을 위한 이웃 가중치 집계 과정은 다음과 같이 표현됩니다:
여기서:
- 는 사용자 노드의 특징 표현,
- 는 아이템 노드의 사용자 이웃 집계 표현,
- 는 주의 가중치로, 관계 아래에서 사용자 가 아이템 에 미치는 중요도를 나타냅니다.
주의 가중치는 다음과 같이 계산됩니다:
유사한 방식으로, 엔터티-아이템 삼중항에 대한 이웃 표현 집계는 로 표현됩니다.
이 두 유형의 이웃 표현은 게이트 신호 를 사용하여 결합됩니다:
3.4.3 융합 레이어 (Fusion Layer)
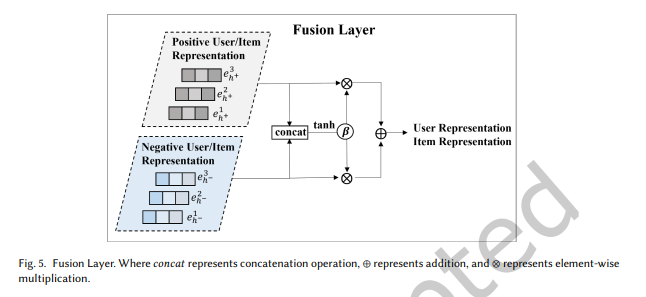
긍정적 및 부정적 노드 표현을 얻은 후,
이 레이어는 각 노드의 최종 표현을 계산하기 위해 서로 다른 가중치를 학습합니다:
여기서 는 각각 긍정적 및 부정적 노드 표현,
는 학습 가능한 가중치입니다.
3.4.4 예측 레이어 (Prediction Layer)
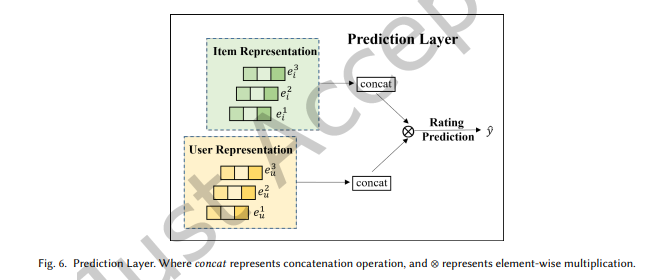
모든 레이어의 표현을 결합하여 사용자와 아이템의 최종 표현을 얻습니다:
최종적으로, 사용자와 아이템 표현 간 내적을 통해 선호 점수를 예측합니다:
3.4.4 예측 레이어 (Prediction Layer)
개의 전파 및 집계 레이어를 거친 후,
사용자와 아이템에 대한 다층 표현을 각각 다음과 같이 얻습니다:
각 레이어의 표현은 하나의 벡터로 연결됩니다:
이 연결된 표현을 통해 사용자와 아이템의 특징 표현을 풍부하게 하고,
의 값을 조정하여 전파 범위를 제어할 수 있습니다.
마지막으로, 그림 6에 표시된 대로,
사용자와 아이템 표현 간의 내적을 수행하여 선호 점수를 예측합니다:
3.5 메타러너 (Meta Learner)
콜드스타트 시나리오에서 평점 예측을 위한 모델 초기화를 보다 잘 수행하기 위해,
CRKM 프레임워크는 MAML [6] 메타러닝 알고리즘을 도입하여
모델 매개변수 학습 과정을 최적화합니다.
특히, 각 사용자의 선호 학습을 메타러닝 태스크로 간주하며,
이를 로 표시합니다.
여기서 는 지원 집합(Support Set), 는 쿼리 집합(Query Set)을 나타냅니다.
학습 과정에서, 사용자 의 상호작용 아이템 집합에서
지원 집합과 쿼리 집합을 샘플링하며, 이 두 집합은 상호 배타적입니다.
훈련 태스크 집합 내에서,
공유 초기 매개변수를 학습한 후 이를 새로운 태스크(테스트 태스크 )에 적용하여
아이템 평점을 예측합니다.
메타러너의 손실 함수
CRKM의 메타러너 손실 함수는 두 부분으로 구성됩니다:
1. 사용자 평점 예측을 위한 BPR 손실 (Bayesian Personalized Ranking, ):
각 사용자의 선호도를 학습하기 위해 사용됩니다.
- 지식 그래프 임베딩을 위한 쌍별 순위 손실 (Pairwise Ranking Loss, ):
지식 그래프의 의미적 지식을 학습하기 위해 사용됩니다.
손실 함수는 다음과 같이 정의됩니다:
BPR 손실 ()
사용자 평점 예측을 위한 BPR 손실은 다음과 같이 표현됩니다:
여기서:
- 는
사용자 가 상호작용한 긍정 아이템()과
상호작용하지 않은 부정 아이템()의 쌍입니다. - 는 시그모이드 함수입니다.
쌍별 순위 손실 ()
지식 그래프 임베딩을 위한 쌍별 순위 손실은 다음과 같이 표현됩니다:
여기서:
- 는
지식 그래프의 삼중항 과 잘못된 삼중항 의 쌍입니다. - 는 삼중항의 점수를 계산하는 함수입니다.
- 는 시그모이드 함수입니다.
메타 학습 과정
모델의 매개변수 집합은 로 정의되며:
- 는 임베딩 레이어의 매개변수,
- 는 주의 집계 레이어와 융합 레이어의 매개변수를 나타냅니다.
지역 업데이트 (Local Update)
주의 집계 레이어와 융합 레이어의 매개변수 는
지원 집합에서 BPR 손실을 기반으로 다음과 같이 업데이트됩니다:
여기서 는 학습률(learning rate)입니다.
글로벌 업데이트 (Global Update)
쿼리 집합에서 를 최적화하여 업데이트를 수행합니다:
또한, 임베딩 레이어의 매개변수 는
지식 그래프 임베딩 손실 를 사용하여 다음과 같이 업데이트됩니다:
여기서 는 글로벌 업데이트를 위한 학습률입니다.
메타 학습 알고리즘 (Algorithm 1)
알고리즘 1: 메타 학습 과정
-
입력:
- 긍정 및 부정 협업 지식 그래프 와
- 메타 학습 태스크 집합
- 초기 모델 매개변수
- 학습률 ,
-
출력:
- 새로운 태스크에 대한 모델 매개변수
-
초기화:
- 모델 매개변수
-
반복:
- 에서 지원 및 쿼리 집합 샘플링
- 지역 업데이트:
- 글로벌 업데이트:
메타 학습 후 테스트
훈련 후, 모델은 초기 매개변수 를 얻습니다.
테스트 태스크 의 지원 집합에서 를 미세 조정하여
다양한 콜드스타트 시나리오에 적응합니다:
4. 실험 (EXPERIMENTS)
이 장에서는 먼저 실험 환경을 설명한 후, 제안된 CRKM의 실험 결과를 제시하고, 결과의 합리성을 분석합니다.
실험은 다음 세 부분으로 구성됩니다:
1. 비교 실험(Comparative Experiments)
2. 제거 실험(Ablation Experiments)
3. 매개변수 설정 실험(Parameter Setting Experiments)
주요 목표는 다음의 연구 질문(Research Questions, RQs)을 해결하는 것입니다:
- RQ1: 본 논문에서 제안한 CRKM 프레임워크는 다양한 데이터셋 및 콜드스타트 시나리오에서
다른 기준선 모델보다 우수한가요? - RQ2: CRKM 프레임워크의 부정 샘플러, 부정 주의 모듈, 융합 레이어, 메타러너와 같은
다양한 구성 요소가 모델 성능에 어떻게 영향을 미치나요? - RQ3: CRKM 프레임워크에 대한 하이퍼파라미터 설정은 모델 성능에 어떻게 영향을 미치나요?
4.1 실험 환경 (Experimental Setup)
4.1.1 데이터셋 (Datasets)
CRKM 프레임워크의 효과를 평가하기 위해, 다음 세 개의 벤치마크 데이터셋을 사용했습니다:
1. Amazon-book:
Amazon Reviews 데이터셋은 널리 사용되는 추천 데이터셋입니다.
본 논문에서는 Amazon Books Reviews 데이터셋을 선택했으며,
이는 사용자 ID, 도서 ID, 사용자 평점, 타임스탬프를 포함합니다.
데이터 품질을 보장하기 위해, 사용자와 아이템 모두 최소 10회 이상의 상호작용이 있는 데이터를 사용했습니다.
-
Last-FM:
Last-FM 음악 플랫폼에서 제공된 데이터셋으로,
트랙에 대한 사용자 평점 없이 사용자 청취 기록을 포함합니다.
이 데이터셋은 암묵적 피드백을 다루는 추천 시스템에서 대표적인 데이터셋입니다.
데이터는 사용자 ID, 트랙 ID, 아티스트 및 앨범 정보, 트랙 청취 타임스탬프를 포함하며,
최소 10회 이상의 상호작용 데이터만 사용되었습니다. -
Yelp2018:
Yelp 데이터셋은 다양한 비즈니스에 대한 사용자 평점을 포함합니다.
본 논문에서는 2018년 Yelp Challenge 데이터셋을 사용했으며,
사용자 ID, 비즈니스 ID, 비즈니스 평점, 평점 타임스탬프를 포함합니다.
사용자와 아이템 모두 최소 10회 이상의 상호작용이 있는 데이터를 사용했습니다.
각 데이터셋에 대해 아이템 지식 그래프도 구축했습니다:
- Amazon-Book과 Last-FM 데이터셋의 지식 그래프는 Freebase를 기반으로 구축했으며,
KB4Rec [36]에서 설명된 전처리 방법을 사용해 아이템을 엔터티에 매핑했습니다. - Yelp2018 데이터셋의 경우, 지역 비즈니스 정보 네트워크에서 아이템 정보를 추출해
비즈니스 위치와 카테고리와 같은 세부 정보를 포함하는 지식 그래프를 생성했습니다.
표 1은 세 데이터셋의 통계 정보를 요약합니다.
| Dataset | Users | Items | Interactions | Entities | Relations | Triplets |
|---|---|---|---|---|---|---|
| Yelp2018 | 45919 | 45538 | 1185068 | 90961 | 42 | 1853704 |
| Amazon-book | 70679 | 24915 | 847733 | 88572 | 39 | 2557746 |
| Last-FM | 23566 | 48123 | 3034796 | 58266 | 9 | 464567 |
4.1.2 비교 방법 (Compared Methods)
CRKM 프레임워크는 세 가지 범주의 방법과 비교되었습니다:
1. 전통적인 추천 알고리즘:
- FM (Factorization Machines) [19]:
이 알고리즘은 2차원 특징 상호작용을 모델링하고, 데이터 희소성 문제를 해결하기 위해 특징 관계를 학습합니다. - NFM (Neural Factorization Machines) [12]:
FM의 확장 버전으로, 2차원 특징 상호작용을 다층 퍼셉트론(MLP)으로 대체하여
고차원 특징 상호작용을 학습하고 모델 표현력을 향상시킵니다.
-
지식 그래프 기반 추천 알고리즘:
- CKE (Collaborative Knowledge Embedding) [34]:
TransR 알고리즘을 사용하여 지식 그래프에서 아이템의 구조적 표현을 학습하고,
텍스트 및 시각적 지식에서 의미적 표현을 추출하여 최종 아이템 표현에 통합합니다. - RippleNet [26]:
경로 기반 및 임베딩 기반 접근법을 결합하여 사용자 표현을 향상시키고,
아이템 지식 그래프 경로를 따라 사용자 선호 분포를 학습합니다. - KGAT (Knowledge Graph Attention Network) [27]:
지식 그래프 컨볼루션에서 주의 메커니즘을 사용하여 다단계 이웃을 통해
엔터티 임베딩을 반복적으로 학습하며, 사용자와 아이템 간 고차원 관계를 캡처합니다.
- CKE (Collaborative Knowledge Embedding) [34]:
-
메타러닝 기반 추천 알고리즘:
- MetaKG [5]:
메타러닝과 추천 시스템을 결합하여 콜드스타트 문제를 해결합니다.
두 개의 메타러너를 설계해 지식 그래프의 의미적 관계와 사용자의 선호를 교대로 학습합니다.
- MetaKG [5]:
4.1.3 매개변수 설정 (Parameter Settings)
- 최적화 방법: Adam 옵티마이저와 Xavier 초기화를 사용했습니다.
- 임베딩 크기: 사용자, 엔터티, 관계의 임베딩 크기는 에서 선택되며, 최종 크기는 64입니다.
- 규제 계수: 규제 계수는 범위에서 설정하며, 최종 값은 입니다.
- 학습률: 범위에서 설정하며, 글로벌 학습률은 0.0005, 로컬 학습률은 0.01로 설정되었습니다.
- 그래프 신경망 깊이: 고차 이웃 정보를 학습하기 위해 3 레이어로 설정했습니다.
- 평가 메트릭: Recall@K와 NDCG@K를 사용했으며, 으로 설정했습니다.
4.2 비교 실험 (Comparative Experiment, RQ1)
CRKM 프레임워크를 세 가지 공개 데이터셋에서 다양한 콜드스타트 시나리오와
비콜드스타트 시나리오에서 기존 기준선 모델과 비교하였습니다.
실험 결과는 아래 표에 나와 있으며, %Imp는 제안된 방법이 가장 강력한 기준선과
비교했을 때의 상대적 향상을 나타냅니다.
최고 성능은 굵게 표시하였으며, 두 번째로 높은 성능은 밑줄로 표시하였습니다.
실험 결과는 CRKM 프레임워크가 세 데이터셋에서 대부분의 기준선 모델보다
더 나은 성능을 보임을 나타냅니다. 이는 CRKM의 합리성과 효과성을 증명합니다.
이러한 개선은 주로 다음 요인에 기인합니다:
1. 지식 그래프 기반 샘플링과 인기도 기반 샘플링으로 구성된
2단계 부정 샘플링 방식을 통해 더 나은 부정 샘플을 얻었습니다.
이러한 샘플은 네트워크 구조에 통합되어 제한된 상호작용 데이터를 확장하고
정보를 풍부하게 만듭니다. 반면, 기준선 모델은 단순히
랜덤 부정 샘플링만 수행하여 더 많은 노이즈가 발생합니다.
2. 네트워크 구조에서 주의 집계 레이어(Attention Aggregation Layer)와
융합 레이어(Fusion Layer)를 사용하여 지식 그래프에서 고차원 정보를 효과적으로 학습하고,
부정 샘플을 활용해 긍정 샘플에서 노이즈를 제거하며 사용자와 아이템 표현을 향상시켰습니다.
반면, 기준선 모델은 부정 샘플을 단순히 모델 학습 과정에만 활용할 뿐,
네트워크 구조에 통합하지 않았습니다.
3. 모델 학습 중 메타러너를 사용하여 초기 매개변수를 학습하고,
새로운 태스크에 대해 모델을 훈련합니다.
메타러닝 접근법은 소량의 학습 데이터로도 효과적이며,
추천 시스템의 콜드스타트 문제 해결에 크게 기여합니다.
그러나 MetaKG를 제외한 다른 기준선 모델은 모델 학습 중 메타러너를 활용하지 않습니다.
사용자 콜드스타트 시나리오 실험 결과
| Model | Amazon-book Recall | Amazon-book NDCG | Last-FM Recall | Last-FM NDCG | Yelp2018 Recall | Yelp2018 NDCG |
|---|---|---|---|---|---|---|
| FM | 0.0869 | 0.0749 | 0.1756 | 0.1635 | 0.0626 | 0.0693 |
| NFM | 0.1093 | 0.0924 | 0.2053 | 0.1921 | 0.0747 | 0.0702 |
| CKE | 0.1387 | 0.1333 | 0.2068 | 0.2027 | 0.0692 | 0.0793 |
| RippleNet | 0.1592 | 0.1778 | 0.1925 | 0.2032 | 0.0796 | 0.0731 |
| KGAT | 0.1919 | 0.2008 | 0.2321 | 0.2294 | 0.0854 | 0.0817 |
| KGCL | 0.2056 | 0.2120 | 0.2412 | 0.2378 | 0.0939 | 0.0955 |
| KGIN | 0.2068 | 0.2118 | 0.2428 | 0.2335 | 0.0894 | 0.0817 |
| MetaKG | 0.2073 | 0.2124 | 0.2451 | 0.2492 | 0.1044 | 0.0978 |
| CRKM | 0.2164 | 0.2273 | 0.2652 | 0.2714 | 0.1125 | 0.1039 |
| %Imp | 7.5% | 7.0% | 8.2% | 8.9% | 7.7% | 6.2% |
아이템 콜드스타트 시나리오 실험 결과
| Model | Amazon-book Recall | Amazon-book NDCG | Last-FM Recall | Last-FM NDCG | Yelp2018 Recall | Yelp2018 NDCG |
|---|---|---|---|---|---|---|
| FM | 0.1621 | 0.1502 | 0.3386 | 0.3218 | 0.0738 | 0.0771 |
| NFM | 0.1655 | 0.1610 | 0.3442 | 0.3363 | 0.0856 | 0.0813 |
| CKE | 0.1707 | 0.1721 | 0.3564 | 0.3418 | 0.0897 | 0.0828 |
| RippleNet | 0.1674 | 0.1740 | 0.3701 | 0.3402 | 0.0915 | 0.0903 |
| KGAT | 0.1798 | 0.1782 | 0.3698 | 0.3567 | 0.0970 | 0.0932 |
| MetaKG | 0.1875 | 0.1823 | 0.3891 | 0.3996 | 0.1112 | 0.1184 |
| CRKM | 0.1960 | 0.1954 | 0.4127 | 0.4244 | 0.1169 | 0.1235 |
| %Imp | 4.5% | 7.2% | 6.0% | 6.2% | 5.1% | 4.3% |
사용자-아이템 콜드스타트 시나리오 실험 결과
| Model | Amazon-book Recall | Amazon-book NDCG | Last-FM Recall | Last-FM NDCG | Yelp2018 Recall | Yelp2018 NDCG |
|---|---|---|---|---|---|---|
| FM | 0.2091 | 0.1742 | 0.3056 | 0.3078 | 0.0811 | 0.0760 |
| NFM | 0.2312 | 0.1985 | 0.3143 | 0.3191 | 0.0824 | 0.0796 |
| MetaKG | 0.2574 | 0.2357 | 0.3407 | 0.3436 | 0.1308 | 0.1214 |
| CRKM | 0.2657 | 0.2471 | 0.3589 | 0.3697 | 0.1367 | 0.1170 |
| %Imp | 3.2% | 4.8% | 5.3% | 7.5% | 4.5% | -3.8% |
CRKM 프레임워크 성능 요약
제안된 모델은 콜드스타트 및 비콜드스타트 시나리오 모두에서 일관되게 우수한 성능을 보였으며,
그 강건성을 다시 한번 확인할 수 있었습니다.
비콜드스타트 시나리오에서는 데이터셋이 매우 희소하더라도,
지식 그래프에서 풍부한 의미 정보를 결합하고 부정 샘플로 데이터를 증강하여
데이터 희소성 문제를 완화할 수 있음을 보여줍니다.
또한, 모델 학습에 메타러너를 포함하면 희소한 데이터 문제를 더 효과적으로 처리할 수 있습니다.
콜드스타트 시나리오 중에서, 사용자 콜드스타트 시나리오에서 가장 큰 성능 향상이 나타났습니다.
이는 부정 주의 모듈(Negative Attention Module)에서 부정 샘플 정보를 활용하여
사용자 표현을 최적화한 결과일 가능성이 큽니다.
세 데이터셋을 비교했을 때, Last-FM 데이터셋에서의 성능 향상이 더 두드러졌습니다.
이는 Last-FM 데이터셋이 다른 두 데이터셋에 비해 상호작용 정보가 더 조밀하기 때문일 수 있습니다.
기준선 모델 성능 분석
-
전통적인 방법 (FM, NFM)
- FM과 NFM과 같은 전통적인 방법은 상대적으로 낮은 성능을 보였습니다.
- 이는 지식 그래프를 활용하지 않아 추가 정보를 제공하지 못하기 때문입니다.
-
지식 그래프 기반 모델
- CKE는 상대적으로 약한 성능을 보였습니다.
이는 CKE가 지식 그래프의 경로 정보와 고차원 연결성을 완전히 활용하지 못했기 때문입니다. - RippleNet과 KGAT은 지식 그래프에서 다단계 연결성을 엔드투엔드 방식으로 학습하며,
다중 의미 지식을 캡처하여 더 나은 성능을 보였습니다.
- CKE는 상대적으로 약한 성능을 보였습니다.
-
MetaKG
- MetaKG는 메타러닝을 활용하여 콜드스타트 문제를 해결하는 데 있어 가장 강력한 기준선 모델이었습니다.
- 그러나 MetaKG는 부정 샘플 정보를 활용하지 않았습니다.
반면, CRKM은 고품질 부정 샘플링을 수행하고 이를 활용하여 노이즈를 제거하며 추천 품질을 향상시켰습니다.
CRKM 프레임워크의 계산 비용 분석
CRKM과 기타 모델에서 FLOPs (Floating Point Operations Per Second)와 같은 계산 복잡도 지표를 기록한 결과,
프레임워크의 성능 향상이 계산 비용 증가를 상회한다는 것을 발견했습니다.
따라서, CRKM 프레임워크는 높은 효용성을 가지고 있습니다.
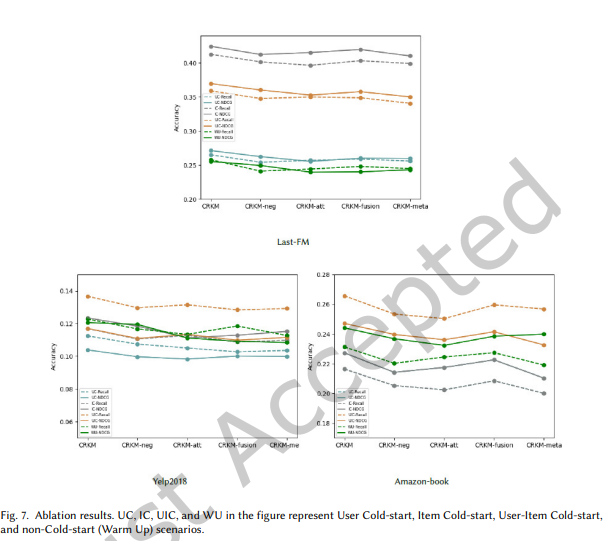
4.3 제거 실험 (Ablation Experiment, RQ2)
CRKM 프레임워크의 핵심 구성 요소인 부정 샘플러(Negative Sampler),
부정 주의 모듈(Negative Attention Module),
긍정-부정 샘플 융합 레이어(Fusion Layer), 메타러너(Meta-Learner)가
추천 결과에 미치는 영향을 조사했습니다.
각 구성 요소의 효과를 평가하기 위해 다음과 같은 CRKM 프레임워크의 네 가지 변형을 생성했습니다:
1. CRKM: 완전한 모델
2. CRKM-neg: 부정 샘플러를 제거한 CRKM
3. CRKM-att: 부정 주의 모듈을 제거한 CRKM
4. CRKM-fusion: 융합 레이어를 제거한 CRKM
5. CRKM-meta: 메타러너를 제거한 CRKM
실험 결과는 그림 7에 나와 있습니다.
CRKM 구성 요소별 분석
-
CRKM-neg
부정 샘플러를 설계된 방식 대신 랜덤 부정 샘플링으로 대체하여 효과를 검증했습니다.
실험 결과, Recall과 NDCG 지표 모두 감소했으며,
이는 지식 그래프와 인기도를 기반으로 한 2단계 부정 샘플링이
랜덤 부정 샘플링보다 높은 품질의 부정 샘플을 추출하고,
일부 노이즈 샘플을 필터링할 수 있음을 나타냅니다. -
CRKM-att
사용자 표현 학습 시 부정 주의 모듈을 제거하고,
부정 샘플과 긍정 샘플 간의 유사도를 기반으로 가중치를 부여하는 대신
사용자-아이템 상호작용 행렬을 직접 사용했습니다.
그러나 부정 주의 모듈이 없는 경우 모델 성능이 하락했으며,
이는 부정 주의 모듈이 부정 샘플 정보를 활용해 노이즈를 제거하고
사용자 표현을 개선하는 데 중요한 역할을 한다는 것을 시사합니다. -
CRKM-fusion
네트워크 구조에서 융합 레이어를 제거하여 성능을 비교했습니다.
융합 레이어가 없는 모델의 성능이 원래 모델보다 낮았으며,
이는 융합 레이어가 긍정 및 부정 샘플의 가중치 표현을 학습하여
사용자 및 아이템 표현을 향상시킴으로써 추천 성능을 개선한다는 것을 확인시켜줍니다. -
CRKM-meta
메타러너를 제거한 CRKM의 성능을 검증했으며,
이 경우 글로벌 모델 학습이 로컬 업데이트 없이 수행되었습니다.
메타러닝이 없는 모델은 원래 모델보다 낮은 성능을 보였으며,
이는 메타러너를 도입함으로써 제한된 데이터(예: 새로운 사용자 및 아이템) 시나리오에
모델이 빠르게 적응할 수 있음을 나타냅니다.
결론
실험 결과는 제안된 모델의 핵심 구성 요소(부정 샘플러, 부정 주의 메커니즘, 융합 레이어, 메타러너)의
효과성을 확인시켜줍니다. 각 구성 요소를 개별적으로 제거한 경우,
모델 성능은 완전한 CRKM 프레임워크보다 일관되게 낮은 결과를 보였습니다.
4.4 매개변수 설정 실험 (Parameter Setting Experiment, RQ3)
마지막으로, 모델 매개변수(임베딩 차원 및 네트워크 레이어 수)가 추천 성능에 미치는 영향을 조사했습니다.
다른 시나리오에서도 유사한 결과를 얻을 수 있으므로,
이 실험은 사용자-아이템 콜드스타트(UIC) 시나리오에 초점을 맞췄습니다.
임베딩 차원 (Embedding Dimension)
임베딩 차원이 모델 성능에 미치는 영향을 조사했으며,
{16, 32, 64, 128, 256} 차원을 탐구했습니다.
결과는 표 6에 제시되어 있으며,
CRKM 프레임워크는 임베딩 차원을 64로 설정했을 때 최고의 성능을 보였습니다.
또한, 임베딩 차원이 증가함에 따라 모델 성능이 안정화되었으며,
이는 모델이 임베딩 차원에 대해 높은 강건성을 가지고 있음을 보여줍니다.
| 임베딩 차원 | Amazon-book Recall | Amazon-book NDCG | Last-FM Recall | Last-FM NDCG | Yelp2018 Recall | Yelp2018 NDCG |
|---|---|---|---|---|---|---|
| 16 | 0.2621 | 0.2389 | 0.3536 | 0.3635 | 0.1327 | 0.1156 |
| 32 | 0.2665 | 0.2428 | 0.3542 | 0.3613 | 0.1341 | 0.1148 |
| 64 | 0.2657 | 0.2471 | 0.3589 | 0.3697 | 0.1367 | 0.1170 |
| 128 | 0.2648 | 0.2456 | 0.3585 | 0.3694 | 0.1364 | 0.1161 |
| 256 | 0.2652 | 0.2462 | 0.3574 | 0.3681 | 0.1355 | 0.1165 |
네트워크 레이어 (Network Layers)
네트워크 레이어 수가 모델 성능에 미치는 영향을 조사했으며,
CRKM-{1, 2, 3, 4}로 설정된 네트워크를 비교했습니다.
결과는 표 7에 제시되어 있으며, 레이어 수가 증가함에 따라
모델 성능이 점진적으로 향상되는 것을 보여줍니다.
CRKM-2와 CRKM-3은 각 데이터셋에서 CRKM-1보다 더 나은 성능을 보였으며,
이는 사용자, 아이템, 엔터티 간의 고차원 관계를 모델링함으로써
지식 그래프에서 더 풍부한 구조적 정보를 캡처할 수 있음을 나타냅니다.
그러나 CRKM-3에 추가 레이어를 쌓아 CRKM-4로 확장해도 성능이 유의미하게 개선되지 않았습니다.
이는 엔터티 간 3-hop 관계를 고려하는 것이 그래프 내 다양한 의미 정보를 캡처하는 데 충분함을 시사합니다.
| 네트워크 레이어 | Amazon-book Recall | Amazon-book NDCG | Last-FM Recall | Last-FM NDCG | Yelp2018 Recall | Yelp2018 NDCG |
|---|---|---|---|---|---|---|
| CRKM-1 | 0.2594 | 0.2419 | 0.3524 | 0.3652 | 0.1294 | 0.1125 |
| CRKM-2 | 0.2612 | 0.2436 | 0.3568 | 0.3685 | 0.1326 | 0.1181 |
| CRKM-3 | 0.2657 | 0.2471 | 0.3589 | 0.3697 | 0.1367 | 0.1170 |
| CRKM-4 | 0.2649 | 0.2467 | 0.3587 | 0.3712 | 0.1354 | 0.1164 |
5. 결론 및 미래 연구 (CONCLUSIONS AND FUTURE WORK)
본 논문은 추천 시스템에서의 콜드스타트 고품질 데이터 획득 문제를 해결하기 위해
새로운 CRKM 프레임워크를 제안하였습니다.
우리는 이 문제를 데이터와 모델 관점에서 접근했습니다.
- 데이터 관점:
지식 그래프를 보조 정보로 활용하여 그래프 신경망 모델을 구축하였습니다. - 모델 관점:
메타러너를 활용하여 모델을 훈련하고,
사용자와 아이템의 더 풍부한 표현을 학습함으로써 추천 성능을 향상시켰습니다.
우리는 음악, 도서, 쇼핑 관련 세 가지 공개 데이터셋에서 비교 실험을 수행했습니다.
실험 결과, 제안된 CRKM 프레임워크는 콜드스타트 및 비콜드스타트 시나리오 모두에서
다른 기준선 모델보다 뛰어난 성능을 보였습니다.
연구 성과와 한계
본 연구는 추천 시스템의 콜드스타트 문제 해결에 있어 진전을 이루었으나,
시간과 연구 제약으로 인해 여전히 몇 가지 도전 과제와 한계가 존재합니다.
-
동적 부정 샘플링 탐색:
사용자-아이템 관계의 실시간 변화를 포착하여
의미 있는 부정 샘플을 식별하고 변화하는 동적 환경에 적응할 수 있는
동적 부정 샘플링 방법을 탐구할 수 있습니다. -
소셜 네트워크 통합:
사용자 간의 관계를 소셜 네트워크에 포함시켜
사용자 정보를 더욱 풍부하게 하고 추천 정확도를 향상시킬 수 있습니다.
감사의 말씀 (ACKNOWLEDGEMENTS)
본 연구는 아래의 지원을 받아 수행되었습니다:
- 중국 교육부 인문사회과학재단 (23YJAZH046)
- 국가 자연과학 재단 (12326607, 62276208, 11991023)
- 산시성 자연과학 기초 연구 프로그램 (2024JC-JCQN-02)
