[추천 시스템] Collaborative-Filtering-for-Implicit-Feedback-Datasets 논문 리뷰
[추천시스템] Collaborative-Filtering-for-Implicit-Feedback-Datasets
추천시스템의 논문중 하나인 Collaborative-Filtering-for-Implicit-Feedback-Datasets를 리뷰 하겠다.
데이터 및 기타 설명
1. Explicit Feedback(명시적 피드백)
명시적 피드백은 직접적 피드백이라고도 한다.
이는 유저가 자신의 선호도(Preference)를 직접적으로 표현한 데이터이다.
예시)
- 리뷰 데이터
- 평점 데이터
- 기타
2. Implicit Feedback(간접적 피드백)
간접적 피드백은 EF(Explicit Feedback)과 달리 간접적으로 선호도(Preference)를 표현한 데이터이다.
예시)
- 페이지 방문 기록
- 페이지 방문 시간
- 기타 움직임
해당 IF는 EF와 다른 점이 몇가지 있다.
- 부정적인 피드백이 없다.
- 데이터가 부정확할 수 있다.
- 수치는 신뢰도를 의미한다.
- 해당 데이터는 EF와 다른 평가 방법을 제시해야한다.
3.
는 관측값(Observation)이라고 한다.
이것은 가 에대한 표현이다.
EF에서는 사용자(u)가 아이템(i)에 갖는 선호도를 의미 하며,
IF에서는 사용자(u)가 아이템(i)를 구매하거나, 아이템(i)에서 소비한 시간, 혹은 아이템(i)를 구매한 횟수 등을 의미한다.
IF에서는 관측된 것이 없을 경우 으로 설정된다.
4.
는 를 확인할때 신뢰도를 측정하는 변수다.
위의 식으로 표현되며, 신뢰도의 증가는 상수()로 조절된다.
해당 논문에서는 일때 좋은 결과를 내었다.
5.
는 선호도(Prefrence)에 대한 이진 변수다.
이것은 로 부터 파생되며 식은 아래와 같다.
가 항목 에 대해 소비한 적 혹은 이용한 적이 있다면, 는 이 되며, 없을 경우 는 이 된다.
본론
1. Neighborhood Model
이웃 기반 모델은 협업 필터링에서 가장 흔한 접근 방식으로, 크게 두 가지 방법이 있습니다:
사용자 중심 접근법(User-oriented Approach)
이 방법은 사용자 간의 유사성을 기반으로 한다.
어떤 사용자가 좋아하는 항목의 평가를 바탕으로 비슷한 취향을 가진 다른 사용자들의 평가를 사용하여 예측을 한다.
초기 CF 시스템들은 대부분 이 사용자 중심 접근법을 사용했다.
항목 중심 접근법(Item-oriented Approach)
이 방법은 항목 간의 유사성을 기반으로 한다. 사용자가 평가한 항목 중에서 유사한 항목들을 찾아 해당 항목들의 평가를 바탕으로 예측을 한다.
흔히 Pearson 상관 계수를 사용.
장점
- 항목 중심 접근법은 확장성과 정확도가 더 우수함
- 예측의 근거 설명에 용이
단점
- IF에서는 이러한 방법이 사용자 선호와 그 신뢰도 간의 구별을 잘 해내지 못함
2. SVD Model
특이값 분해(Singular Value Decomposition, SVD)모델 이라고 한다.
해당 모델은 사용자 요인와 아이템 요인 로 표현한다.
예측은 이 두 요인의 내적(inner product)을 통해 수행된다
파라미터 추정은 주로 정규화된 모델을 사용하여 수행된다.
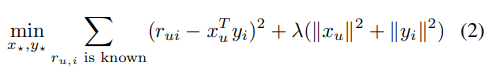
λ는 정규화 파라미터
이미지 출처 : 논문
3. Our Model
결론
