
개요
CPU는 매 순간 하나의 논리 주소를 참조하며, 페이지 테이블은 프로세스마다 하나씩 존재하여 시스템에 따라 유한하게 생성된다.
많은 페이지 항목들 중에서도 TLB에 캐시된 극히 일부만이 CPU 접근 시 빠르게 참조될 수 있다.
페이징이란?
가상 주소 공간을 일정 크기의 페이지로 나누고,
각 페이지를 물리 메모리의 프레임에 비연속적으로 적재함으로써
외부 단편화를 방지하고, 실제 메모리보다 큰 프로그램도 실행 가능하게 하는 메모리 관리 기법.
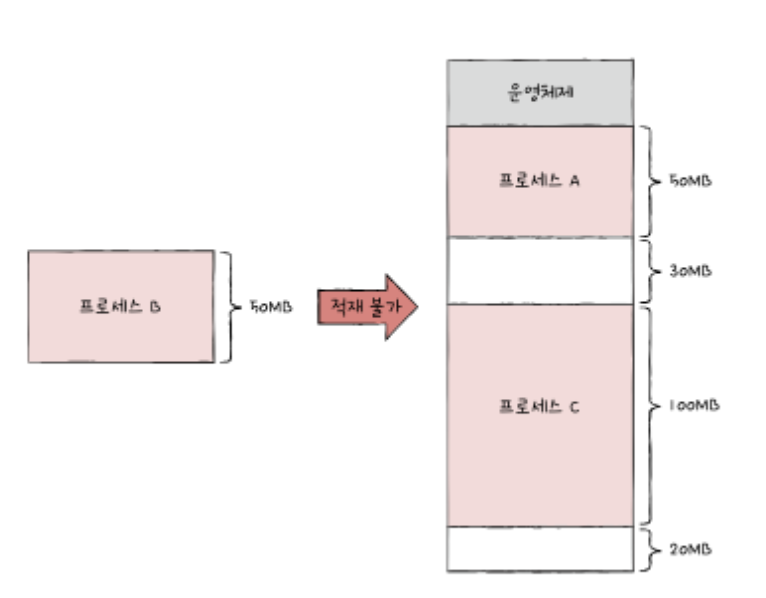
각기 다른 크기의 프로세스가 메모리에 연속적으로 할당되면 외부단편화 현상이 생겨 새로운 프로세스를 적재할 수 없다.
+) 외부단편화: 메모리에 충분한 공간이 있어도, 프로세스가 요구하는 연속적인 공간이 없으면 프로세스를 적재할 수 없음.
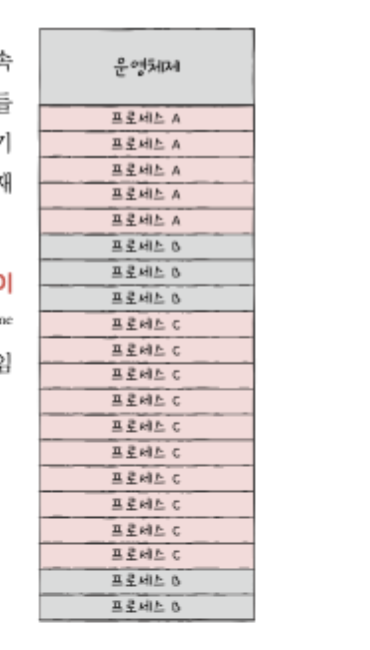
메모리와 프로세스를 일정한 단위로 나누어 불연속적으로 할당하면,
외부 단편화가 발생하지 않음
예: 프로세스와 메모리를 10MB 단위로 자르고, 자른 단위를 불연속적으로 배치해도 괜찮음
이는 페이징이라 불리며,
논리 주소 공간은 페이지(page)로,
물리 주소 공간은 프레임(frame)으로 나눔
페이지는 프레임에 일대일 대응되어 적재됨
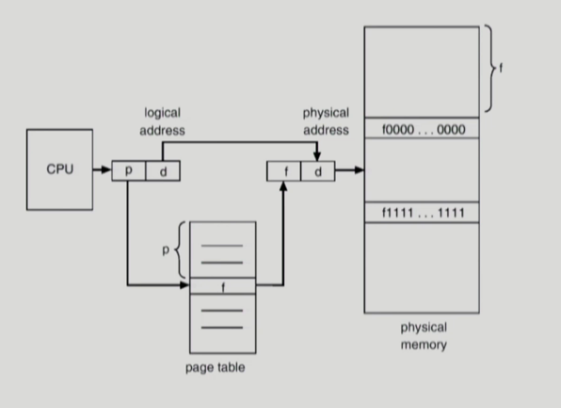
페이지 테이블
페이지 테이블(Page Table)은 가상 주소를 물리 주소로 변환하기 위한 매핑 정보를 저장하는 자료구조임.
각 프로세스는 자신의 고유한 페이지 테이블을 가지며, 논리 주소의 페이지 번호(page number)를 물리 메모리의 프레임 번호(frame number)로 변환하는 데 사용됨.
페이지 테이블은 운영체제가 관리하며, 페이징 기법의 핵심 구성 요소
페이지 테이블 항목에는 다음과 같은 정보가 포함
- 해당 페이지가 메모리에 존재하는지 여부 (valid bit)
- 프레임 번호 (PFN: Physical Frame Number)
- 읽기/쓰기 권한, 캐싱 여부, 참조/변경 비트 등
※ 페이지 테이블 접근은 느리므로 이를 보완하는 캐시가 TLB
실제 시스템에서는 메모리 사용량을 줄이기 위해 다단계 페이지 테이블(multi-level page table)이 사용되며, x86-64에서는 4단계 구조가 기본임.
내부단편화
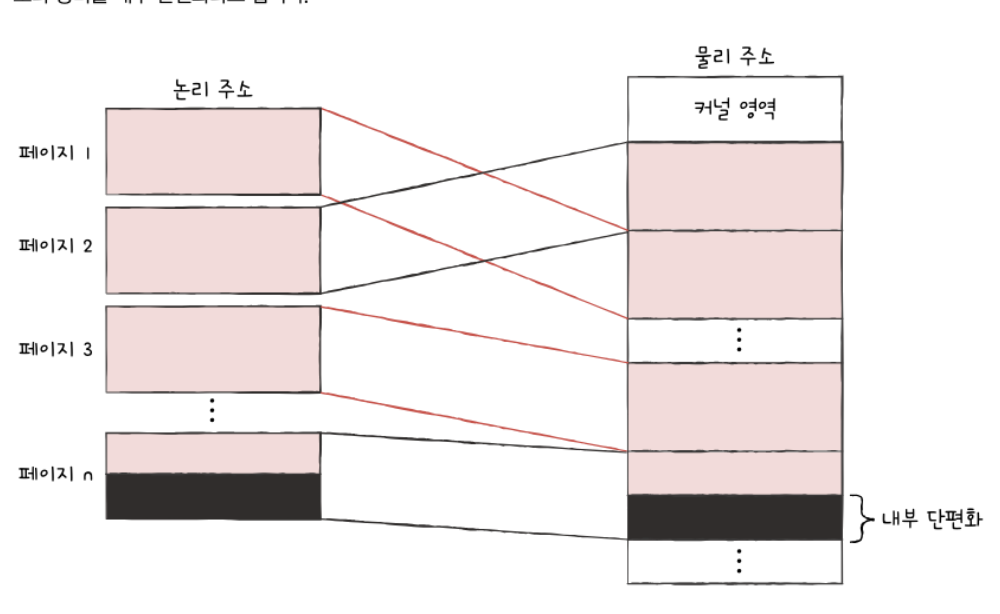
내부 단편화(Internal Fragmentation)란,
고정 크기의 메모리 블록을 할당했지만, 실제 데이터는 그보다 작아 일부 공간이 낭비되는 현상을 말함.
예를 들어, 페이지 크기가 4KB인데 프로세스가 3.6KB만 사용하는 경우,
남은 0.4KB는 다른 프로세스가 사용할 수 없고 낭비된다.
- 고정 크기 할당에서 주로 발생
- 페이징 시스템에서도 페이지 단위로 할당되기 때문에 내부 단편화가 발생할 수 있음
외부 단편화는 방지하지만, 내부 단편화는 페이징의 한계 중 하나임.
TLB
페이지 테이블 탭에서 잠시 언급되었던
TLB(Translation Lookaside Buffer)는
최근 또는 자주 사용된 페이지 테이블 항목을 캐시해 두는 고속 메모리
주소 변환 시 먼저 TLB를 참조하여, 페이지 테이블에 접근하는 비용을 줄임.
- 하드웨어 기반 캐시 (CPU 내부 또는 MMU 내 존재)
- 보통 수십~수백 개의 항목만 저장 가능
- 주소 변환 성능 향상에 결정적인 역할을 함
TLB는 CPU가 가상 주소 → 물리 주소를 빠르게 변환하도록 도와주는 핵심 가속 장치
TLB 히트 & TLB 미스
-
TLB Hit:
→ CPU가 찾는 가상 주소의 매핑 정보가 TLB에 존재하는 경우
→ 페이지 테이블 접근 없이 바로 물리 주소로 변환 가능
→ 빠른 메모리 접근이 가능함 -
TLB Miss:
→ TLB에 매핑 정보가 없어 페이지 테이블을 다시 찾아야 함
→ 주소 변환 지연 발생
→ TLB 미스 후에는 해당 정보를 TLB에 캐싱(업데이트)함
TLB miss에는 단순한 miss 외에도 page fault로 이어지는 경우도 있으므로 성능 저하가 연쇄적으로 발생할 수 있다.
TLB 히트율이 높을수록 시스템 전체의 성능이 좋아짐.
서버 개발 & 유지 & 보수 측면에서의 TLB
TLB는 페이지 테이블 접근을 줄이기 위한 고속 주소 변환 캐시로서,
가상 주소를 물리 주소로 빠르게 변환하는 데 필수적인 역할을 함.
페이징 시스템에서는 주소 변환이 빈번하게 발생하며,
이 과정에서 CPU가 주소 변환 시 참조하는 TLB의 캐시 히트율은 전체 시스템 성능에 직접적인 영향을 미친다.
히트율이 높으면 빠르게 변환이 이뤄지지만, TLB miss가 발생하면 페이지 테이블을 다시 참조해야 하므로 지연이 발생
따라서 실무에서는 다음과 같은 최적화가 중요.
- 지역성(locality)을 고려한 메모리 접근 설계
- Huge Page(대용량 페이지)를 활용하여 TLB 엔트리 수를 절약
- 문맥 교환 시 TLB flush 최소화를 위한 커널 최적화
- 가상화 환경에서는 Nested TLB나 EPT 등을 통해 성능 손실 최소화
효율적인 TLB 활용은
- 서버 애플리케이션의 메모리 접근 비용을 줄이고,
- 요청 처리 지연(latency)을 최소화하며
- 전체 시스템의 반응성과 처리량(QPS, TPS)을 개선시킴.
즉, TLB를 효율적으로 활용하면 메모리 접근 속도와 전체 시스템 반응성을 동시에 개선 가능.
서버 개발자에게 있어 TLB란
앞서 살펴본 바와 같이, TLB의 효율은 서버 애플리케이션의 메모리 접근 속도, 요청 처리 지연(latency), **시스템 처리량(QPS, TPS)**에 직결됨.
이러한 영향력 때문에, TLB는 단순한 하드웨어 캐시가 아니라 서버 성능을 유지하고 병목을 예방하기 위한 실질적인 관리 대상이 됨.
서버 개발자는 다음과 같은 실전 상황에서 TLB를 의식한 설계를 고민해야함.
(1) GC(가비지 컬렉션) 중 대규모 메모리 스캔 시 발생할 수 있는 TLB miss 최소화
(2) 문맥 전환 시 발생하는 TLB flush를 줄이기 위한 스레드 구조 최적화
(3) DBMS, Redis, AI 모델 서버에서의 반복적 메모리 접근 경로를 고려한 Huge Page 활용
(4) NUMA 환경에서 TLB locality를 고려한 CPU-메모리 바인딩 전략
특히 고성능 시스템에서는 단순히 기능을 구현하는 것을 넘어,
TLB miss가 시스템 레이턴시에 미치는 영향을 예측하고, 이를 설계 초기부터 제어하는 것 자체가 개발자의 중요한 역할임.

일단 좋아요 누르고 나중에 읽겠읍니다