일반적인 스프링의 처리흐름
클라이언트의 요청은 필터를 거쳐 디스패처 서블릿(DS)으로 간다.
DS에는 인터셉터 / 핸들러 / 뷰리졸버 / 메세지컨버터등이 관계 되어 있다.
컨트롤러가 던진 throw는 컨트롤러를 호출한 DS로 전달되어 핸들러가 처리하게 된다.
필터를 통과하지 못한 요청은 스프링에 접근하지 못했으므로 핸들러 처리를 할 수 없다.
DS이후 컨트롤러, 모델, 뷰의 모든 처리가 가능하기 때문에 mvc패턴의 핸들러는 mvc핸들러라고 한다.
인터셉터의 작동 시점은 컨트롤러가 호출된 전후로 볼 수 있다. ( 생성 시점은 DS )
필터가 사전에 다양한 공격을 막으면 뒤가 편하다 -> 조금더 구체적인 처리는 인터셉터나 핸들러가 처리한다.
스프링에서 빈을 등록해서 등록한 빈을 필터에서 사용할 수도 있다.
개발자는 DS를 제어할 수 없다. 스프링이 제어권을 가진다.
컨트롤러의 단위테스트는 필터부터 컨트롤러단까지를 메모리에 띄워서 테스트하는것을 말한다.
단위테스트를 분리시키는 이유는 A가 에러인데 B를 보고 있지 말라는 의도도 있다.
JPA를 이용했을때 스프링의 처리흐름
( 그림 못그려서 죄송.. )
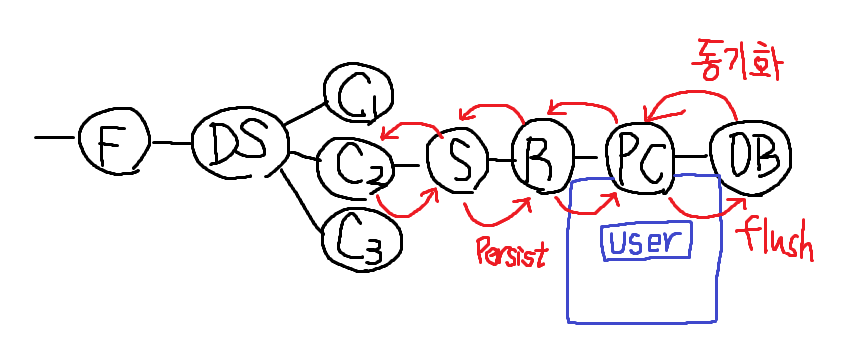
Hibernate를 이용하면
컨트롤러 - 서비스 - 레파지토리 - DB의 레이어가
컨트롤러 - 서비스 - 레파지토리 - Persistence Context( PC ) - DB의 레이어가 된다.
Persistence Context( PC )는 ORM을 이용해서 자바 오브젝트와 DB 사이에서 데이터를 변환해준다.
DB에 접근하기 위해서는 DB커넥션을 만들어야 하는데 가능한 풀링을 이용해서 오버헤드를 줄여야 한다.
필터를 이용해서도 커넥션을 만들어줄 수 있다. DB세션이 생기기 때문에 필터가 조회를 할 수도 있지만 권장하지는 않는다.
JPA는 EntityManager를 이용하고 EntityManager는 DataSource에서 커넥션을 가져온다.
컨트롤러에서 JPA 레파지토리를 호출하면 EntityManager가 커넥션과 트랜잭션을 가져온다.
트랜잭션 처리를 위해서 JPA 레파지토리에서 @Tranjactional 어노테이션을 이용한다.
JPA의 영속화, 더티체킹
persist 요청을 하면
처음 요청이 되었을때 데이터를 파싱한 user오브젝트는 Persistence Context( PC )에 존재하지 않는 비영속 객체이다.
@Transactional
public User save(User user){
em.persist(user);
return user;
}JPA레파지토리가 persist를 요청하면 레파지토리에서 PC로 레퍼런스( call by reference )가 전달되는데 이때 user 오브젝트는 영속화가 된다.
여기서 영속화라는 말은 persistence를 하고 싶다는 것이고 데이터를 영원히 저장한다는 것 -> DB에 저장
즉, 영속화가 된다는 말은 자동적으로 DB에 데이터가 들어간다는 것이다.
DB에 들어갈때는 flush가 되면서 commit이 된다. 물론 트랜잭션도 발동한다.
영속화가 진행되면서 DB와 PC의 오브젝트는 동기화가 된다.
동기화가 되므로 PC레이어로 가기만 하면 user오브젝트는 자동적으로 id와 createdAt의 데이터를 부여 받는다. ( id 와 createdAt는 데이터를 받지 않아도 생성 )
위처럼 save()메소드에서 User를 리턴하면 영속화된 user오브젝트를 DS까지 전달해서 뷰로 보내게 된다.
JPA가 만들어진 이유는 객체 지향적으로 데이터를 저장하기 위함이다. 영속화라는 표현을 사용하는것도 자바오브젝트를 영원히 저장하고 싶다는 맥락인것 같다.
merge 요청을 한다면
// JpaRepository를 의존했을때 -> save()
User userPS = userRepository.findById(id).get();
if(ObjectUtils.isEmpty(userPS)){
return new ResponseEntity<>("해당 유저가 없습니다.", HttpStatus.BAD_REQUEST);
}
userPS.update(user.getPassword(), user.getEmail());
User updateUserPS = userRepository.save(userPS); // EntityManager를 의존해서 직접적으로 메소드를 사용할때 -> merge()
@Transactional
public User update(User user){
return em.merge(user);
} findById를 수행할때 id를 Persistence Context( PC )에 전달하게 되는데 이때 PC는 DB에서 user 오브젝트를 복사해서 만든다 ( 스냅샷 )
update를 통해 userPS의 데이터를 변경하고 나서 save() 메소드를 호출하게 되면 트랜잭션이 시작된다.
트랜잭션이 수행되면 고립성이 시작되고 이때 PC에서는 트랜잭션 범위 안에서 더티체킹을 수행하게 된다.
더티체킹은 영속성 컨텍스트(PC)가 관리하는 엔티티에서만 이루어지고 트랜잭션이 수행되면서 PC레이어로 들어온 오브젝트와 스냅샷의 오브젝트를 상태를 비교하게 된다.
트랜잭션이 종료되는 시점에 변경이 감지되면 자동적으로 flush가 수행되고 변경된 오브젝트는 영속화가 진행되어 DB에 저장된다.
여기서 merge를 하기 전에 findbyid를 해서 update를 했기 때문에 영속화된 오브젝트를 DB에 저장하게 되었는데 findbyid하지 않아 PC에 엔티티가 복사되지 않으면 스냅샷이 존재하지 않아 변경감지가 안되므로 flush만 하면 안되고 반드시 merge를 해야한다.
변경된 오브젝트중에서 변경된 필드만 업데이트 하고 싶다면 @DynamicUpdate 어노테이션을 엔티티에 추가하면 된다.
