JPA 이점
- Spring Data Jpa를 사용하면 개발자가
JpaRepository를 상속하기만 하더라도 기본적인 CRUD 쿼리를 제공해주므로 편하게 사용할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {}
- Spring Data Jpa를 사용하면 메소드 이름을 이용해서 쿼리를 생성할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
List<User> findByUserName(String userName);
// "SELECT u FROM User u WHERE u.userName = ?" 쿼리와 동일한 기능
}@Query 어노테이션으로 직접 쿼리를 정의하는 JPQL을 사용할수도 있다.
@Query("select u from User u where u.username = :username")
Optional<User> findByUsername(@Param("username") String username);
// 동일한 기능
Optional<User> findByUsername(String username);
- Jpa를 사용하면 페이징과 정렬메소드를 제공하므로 개발자가 직접 구현할 필요가 없다.
public List<User> findAll(int page){
return em.createQuery("select u from User u", User.class)
.setFirstResult(page * 5)
.setMaxResults(5)
.getResultList();
}"pageable": {
"sort": {
"sorted": false,
"unsorted": true,
"empty": true
},
"pageNumber": 0,
"pageSize": 2,
"offset": 0,
"paged": true,
"unpaged": false
},
"totalPages": 3,
"totalElements": 6,
"last": false,
"sort": {
"sorted": false,
"unsorted": true,
"empty": true
},
"numberOfElements": 2,
"size": 2,
"number": 0,
"first": true,
"empty": false- Jpa가 제공하는
@DataJpaTest어노테이션을 이용하여 데이터 관련 빈들만 로드하여 테스트를 빠르게 진행할 수 있다. Hibernate의 기능을 사용하여 트랜잭션, 캐싱, 지연 로딩 기능을 이용할 수 있다.
JPA 메소드명 규칙
이러한 규칙들에는 다음과 같은것들이 있다.
findBy<PropertyName>
readBy<PropertyName>
getBy<PropertyName>
queryBy<PropertyName>
countBy<PropertyName>끝에 IgnoreCase를 붙이면 대소문자에 상관하지 않는 쿼리를 보낸다.
findByFirstNameIgnoreCase(String firstName)And, Or을 이용해서 두 가지 이상의 조건으로 쿼리를 보낸다.
findByFirstNameAndLastName(String firstName, String lastName)정렬을 사용할 경우 ( 첫번째 조건 - 검색, 두번째 조건 - 정렬 )
findByLastNameOrderByFirstNameAsc(String lastName)입력한 파라미터과 같은값, 다른값을 검색하는 쿼리를 보낸다.
findByFirstNameEquals(String firstName)
findByFirstNameNot(String firstName)특정한 조건을 만족하는 쿼리를 보낸다.
IsTrue, IsFalse, IsNull, IsNotNull, IsEmpty, IsNotEmpty
findByActiveIsTrue()LessThan, LessThanEqual, GreaterThan, GreaterThanEqual, Between, Before, After 등으로 범위의 쿼리를 보낸다.
Like, NotLike, StartingWith, EndingWith, Containing 으로 특정 패턴을 만족하는 쿼리를 보낸다.
JPA optional 처리 방법
JPA는 ORM을 통해 데이터를 반환하는데 이때 반환하는 데이터는 존재할수도 없을수도 있기때문에 Optional을 통해서 처리한다.
@Query("select ac from Account ac where ac.number = :number")
Optional<Account> findByNumber(@Param("number") Integer number);메소드를 호출하는 서비스에서는 Optional을 처리하기 위한 방법으로 isEmpty()나isPresent()를 이용하기도 하지만 아래와 같은 방법도 사용한다.
반환되는 타입을 Optional로 처리하지 않는다면 orElseThrow를 사용할 수 있다.
// 서비스
Account accountPS = accountRepository.findByNumber(number)
.orElseThrow(
() -> new Exception404("계좌를 찾을 수 없습니다"));
@Query / createQuery 차이
두가지 방법 모두 JPQL 을 이용해서 직접 쿼리를 작성해 JPA가 쿼리를 만들어 DB에 접근한다.
@Query어노테이션은 JPA 에서 제공해는 기능으로 메소드가 호출될때 JPA가 JPQL을 생성하여 사용한다.
@Query("SELECT a FROM Account a WHERE a.number = :number")
List<Account> findByNumber(@Param("number") Integer number);
createQuery메소드는EntityManager에서 제공하는 메소드로 위와 마찬가지로 쿼리를 작성하여 DB에 접근한다.createQuery를 사용하면 쿼리의 결과가 리스트일 경우getResultList를 이용해서 List로 반환해야 하고 하나일 경우getSingleResult를 이용해서 객체로 반환해야 한다.
TypedQuery<Account> query = entityManager.createQuery(
"SELECT a FROM Account a WHERE a.number = :number", Account.class);
query.setParameter("number", number);
List<Account> accounts = query.getResultList();
QLRM( Query Language Result Mapper )
jpa는 엔티티를 리턴하기 때문에 DTO를 반환해야 할 경우 여러번 조회해서 DTO에 넣은뒤 반환하는 방법이 있고,
QLRM 라이브러리를 이용해서 Native Query를 작성해 DTO를 반환하는 방법이 있다.
QLRM 라이브러리를 이용하기 위해서든 다음의 의존성을 추가한뒤에
implementation group: 'org.qlrm', name: 'qlrm', version: '2.1.1'다음과 같은 코드로 DTO에 맞는 쿼리를 직접 날린다.
반환받을 데이터가 단일 객체라면 uniqueResult()를 이용하고 List라면 list()를 이용한다.
// java 11에서 따옴표 3개로 이어 쓰기 가능 ( Text Blocks )
String sql = """
SELECT *
FROM my_table
WHERE condition = true
ORDER BY id ASC
""";
// Open Jdk 15 미만이라면
String sql = "SELECT * "
+ "FROM my_table "
+ "WHERE condition = true "
+ "ORDER BY id ASC";
Query query = em.createNativeQuery(sql);
JpaResultMapper result = new JpaResultMapper();
AllOutDTO dto = result.uniqueResult(query, AllOutDTO.class);참고로 MySQL의 BIGINT타입을 DTO에서 받기 위해서 Id의 타입을 BigInteger로 만든다.
Hibernate 전략
성능을 높이려면 ?
서비스로직은 들어온 데이터를 검증하는 과정을 먼저 해야한다.
서비스로직을 유지한 채로 조회를 줄이는게 성능에 좋다.
성능상 이점을 가지려면 @ManyToOne 일때는 모두 Lazy전략을 이용하고 필요할때만 fetch join으로 조회한다.
Lazy전략 +In () 쿼리를 사용하면 보다 빠른 성능을 구현할 수 있다. ( 중복되는 레코드 -> distinct -> in )
조회가 많을 경우 각자 조회한 후에 Dto 에 데이터를 넣는다.
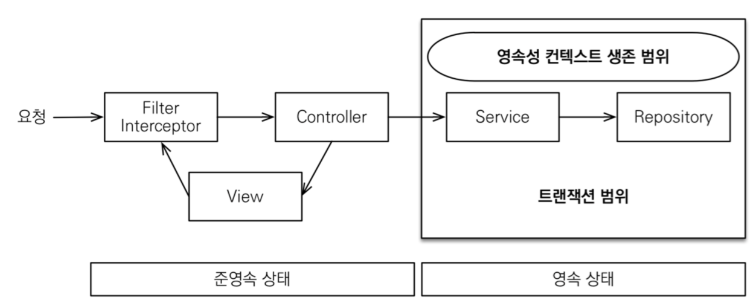
OSIV = true
true일때는 JPA의 트랜잭션 범위를 벗어나더라도 DB커넥션이 유지된다.
화면에 렌더링 될때까지도 커넥션이 유지되는데 이로 인해서 Lazy-Loding이 발생하더라도 데이터를 가져올 수 있게 된다.
오랬동안 커넥션을 유지하기 때문에 성능 최적화가 되지 않는다.
LazyInitializationException발생을 피할 수 있다.
OSIV = false
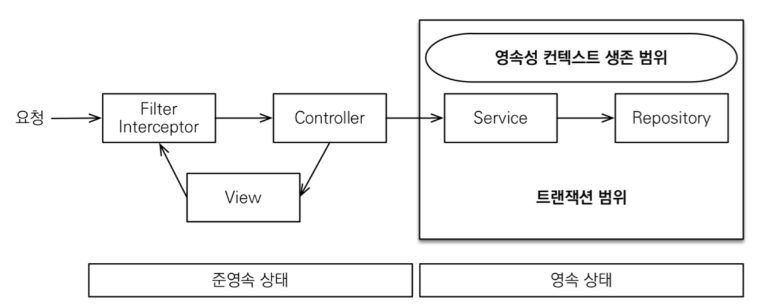
트랜잭션이 종료되면 DB커넥션을 반환한다.
커넥션을 즉시 반환하므로 리소스의 낭비가 없다.
Lazy-Loding의 범위가 축소되었으므로 커넥션 범위 안에서 데이터를 가져와야 한다.
커넥션 종료후 데이터를 가져오려고 하면 LazyInitializationException이 발생한다.
트랜잭션이 끝나기 전에 Lazy-Loding을 강제로 종료하거나 fetch join을 사용한다.
준영속 상태( 영속성 컨텍스트의 관리를 벗어난 )의 엔티티 변화는 DB에 반영되지 않는다.
따라서 트래픽이 많은 서비스에서는 OSIV를 끄는것을 추천한다. ( 개발할때는 켜놓기도 함 )
참고로 스프링 부트 2.0의 기본 상태는spring.jpa.open-in-view=false이다.
Lazy-Loding 사용
ORM 프레임워크에서 객체를 한번에 조회하는것은 메모리 측면에서 비효율적일수가 있는데 Lazy-Loding을 사용하면 필요할때만 조회하므로 효율적이다.
예를들어 1000명의 계좌를 조회하는데 이 계좌들이 10명의 계좌일 경우 1000번을 조회하지 않아도 되므로 Lazy-Loding을 이용한다.
사용방법은 아래와 같이 Lazy를 필드에 명시한다.
@Entity
@Getter
@NoArgsConstructor
@Table(name = "account_tb")
public class Account {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Comment("계좌 아이디")
private Long id;
@Comment("계좌 유저아이디")
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
@OnDelete(action = OnDeleteAction.CASCADE)
private User user;
//생략
}Account를 로드할때 User는 로드되지 않고 User의 내부 필드에 접근할때 User가 지연로딩 된다.
앞서 말했듯 지연로딩 시점은 트랜잭션 범위내에 있어야 하므로 서비스 레이어에서 최대한 데이터 로드를 마무리 해야한다.
Lazy Loading으로 인해서 N+1문제가 발생할 수 있다.
유저마다 orders를 조회할 경우 중복 조회되는 문제가 발생하므로 fetch join으로 해결한다.
그리고 왠만하면 @ManyToOne 단반향만 사용한다.
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@OneToMany(fetch = FetchType.LAZY)
private List<Order> orders;
//생략
}벌크 패치(Bulk Fetch)
대량의 데이터를 한 번의 쿼리로 효율적으로 가져오는 벌크 패치를 통해서 위 문제( N+1 )를 해결한다.
지연로딩이 여러번 되면 성능의 저하가 발생하는데 벌크 패치로 한번에 조회를 해서 성능을 향상시킨다.
yml에 다음과 같이 정의하면 100개의 엔티티를 한 번에 로딩할 수 있다. ( 일반적으로 10 ~ 100 )
spring:
jpa:
properties:
javax.persistence.default_batch_fetch_size: 100
fetch join 사용
JPQL을 사용해서 아래와 같은 방법으로 벌크 패치를 수행하면 N+1 문제를 해결할 수 있다.
List<User> users = em.createQuery(
"SELECT u FROM User u JOIN FETCH u.orders", User.class)
.getResultList(); 이 방법은 쿼리의 결과 레코드가 많아질 수가 있다.
하지만 통신을 한번만 하므로 성능을 향상시킨다.
가장 쉬운 방법은 연관된 데이터를 따로 select 해서 DTO에 넣어 반환하면 된다.
테스트시에는 BeforeEach등으로 영속화가 되었다면 em.clear()를 사용해 영속성 컨텍스트를 비우고 테스트하면 된다.
ORM 최적화 기법
@BatchSize
특정 엔티티에 배치크기를 지정한다.
5개의 엔티티를 한번에 로딩한다.
@Entity
@BatchSize(size = 5)
public class Order {
// ...
}
@EntityGraph
쿼리 실행시 연관된 엔티티를 로딩한다.
fetch join과 동일한 기능을 수행한다.
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@OneToMany
private List<Order> orders;
// ...
}
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@EntityGraph(attributePaths = { "orders" })
List<User> findAll();
}
