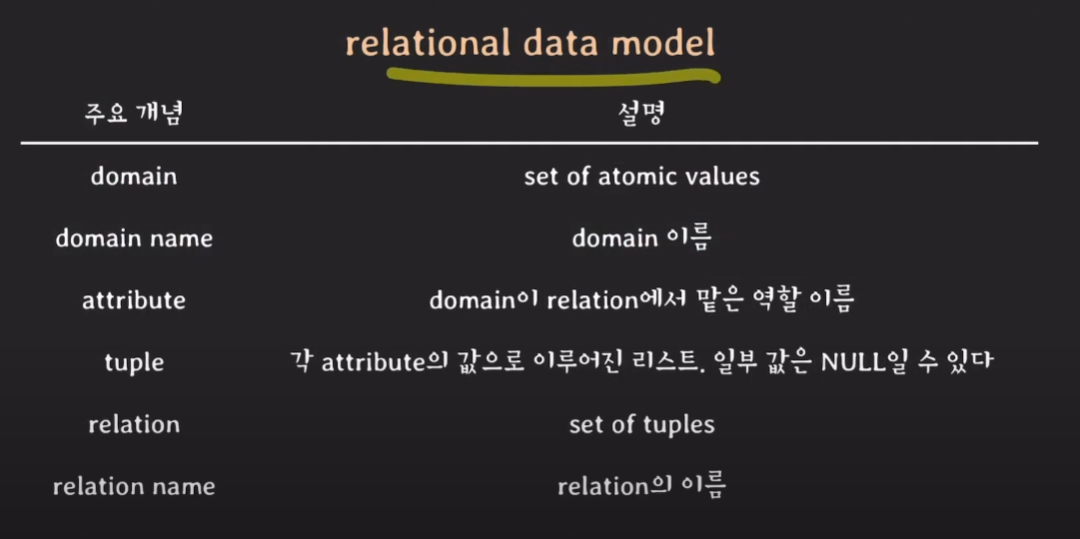
relational data model
relational : 수학적 개념 (A X B 카르테시안 곱과 연관이 있음)
set : 서로 다른 element를 가지는 collection, 하나의 set에서 element의 순서는 중요하지 않다.
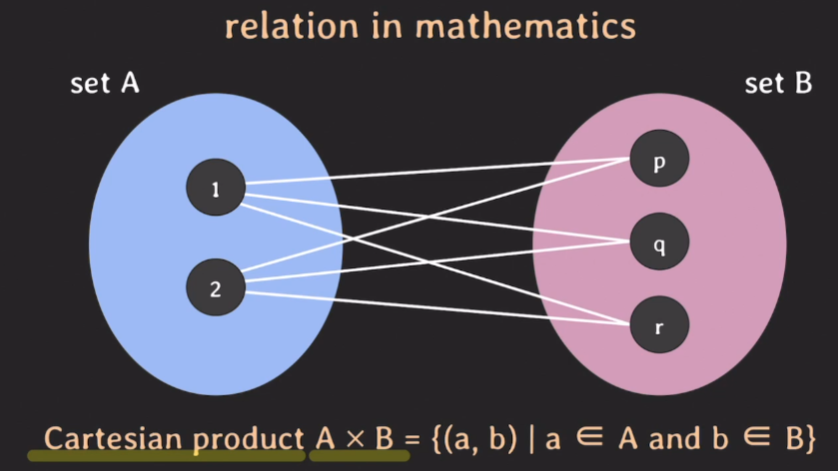
카르테시안 프로덕트는 두 집합의 모든 쌍의 경우의 수를 의미함
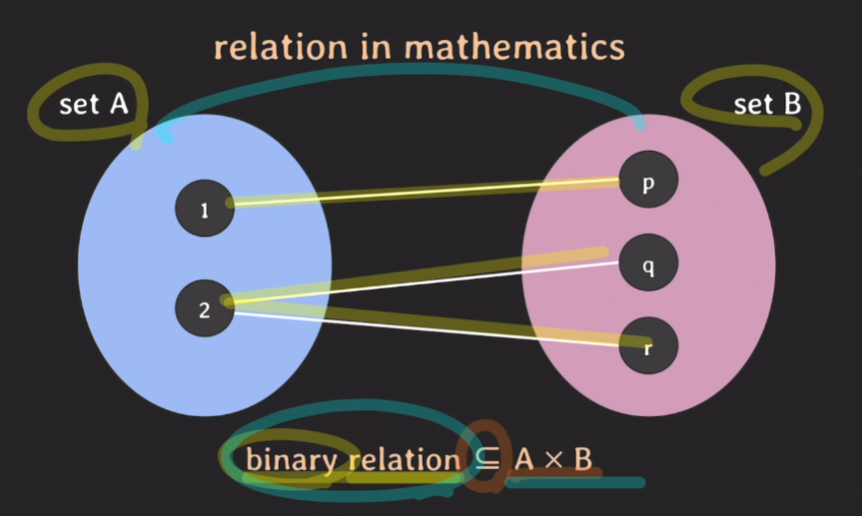
binary relation은 A와 B의 카르테시안 프로덕트의의 부분집합
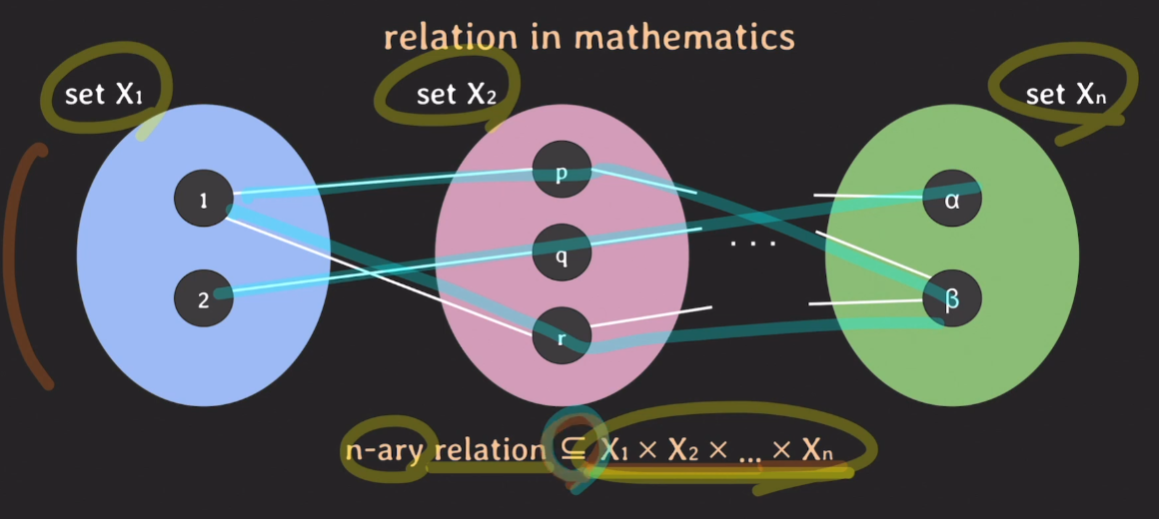
n-ary relation은 n개의 집합에 대한 카르테시안 프로덕트의 부분집합
튜플(Tuple) : n개의 element들로 이루어진 리스트 (n-tuple)
관계형 데이터베이스에서 "튜플" (Tuple)은 데이터베이스 테이블의 각 행(row)을 나타내는 용어입니다. 튜플은 레코드 또는 로우라고도 합니다. 각 튜플은 테이블의 열(column)에 해당하는 필드(field) 값을 포함하고 있으며, 각 필드는 해당 속성(attribute)의 값을 나타냅니다.
예를 들어, 고객 정보를 저장하는 데이터베이스 테이블이 있다면 각 행(튜플)은 특정 고객의 정보를 포함하고 있을 것입니다. 이러한 튜플은 데이터베이스 쿼리를 통해 검색, 수정, 삭제 및 삽입 등의 작업을 수행하는 데 사용됩니다.
튜플은 관계형 데이터베이스의 핵심 구성 요소 중 하나이며, 데이터를 구조화하고 관리하는 데 사용됩니다. 튜플은 테이블의 레코드를 나타내며, 각 필드는 해당 레코드의 속성 값을 저장합니다.
정리하면 수학에서의 relation은 다음과 같이 말할 수 있다.
(1) 카르테시안 프로덕트(Cartesian product)의 부분집합(subset)이다
(2) 튜플의 집합이다 (set of tubles)
카르테시안 곱은 조인 연산 중 하나인 CROSS JOIN을 통해 구현할 수 있다(?)
relation DB 모델에서 데이터들의 집합을 도메인이라고 부르기도 한다.

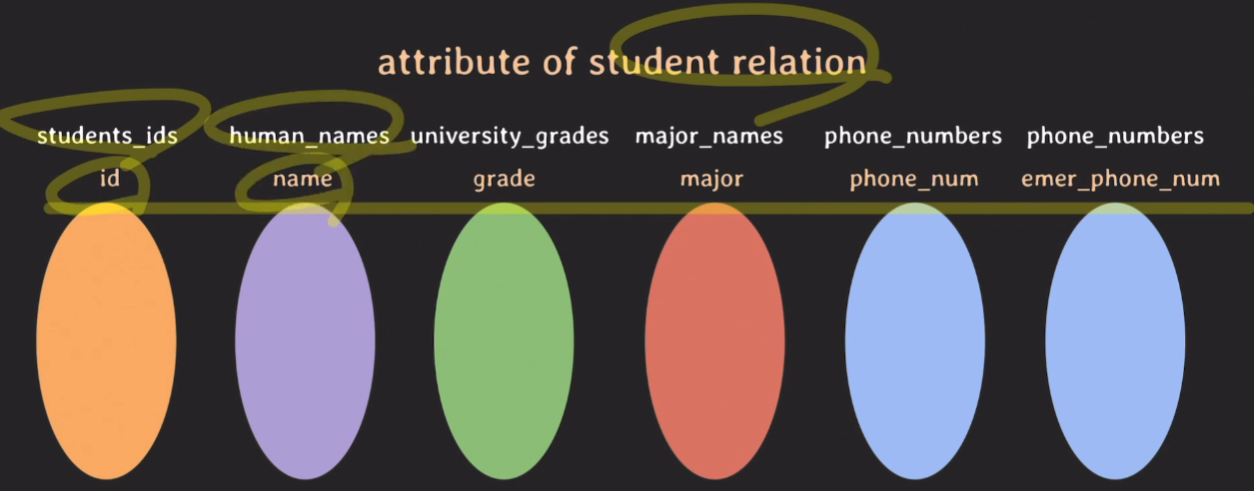
전화번호(phone_numbers)는 본인의 전화번호와 비상연락망 등 두가지 역활(attribute, 역활 이름)이 있다고 가정함.
relation data model에서 tuple의 관계도를 나타내기 위해 가장 좋은 것이 table이다.

relational schema
- relation의 구조를 나타낸다.
- relation 이름과 attributes 리스트로 표기된다.
- e.g. STUDENT(id, name, grade, major, phone_num, emer_phone_num)
- attributes와 관련된 constraints도 포함된다.
- relation schemas set + integrity constraints set (무결성 제약 조건 세트)
degree of relation (관계의 차수)
- relation schema에서 attributes의 수
- e.g. STUDENT(id, name, grade, major, phone_num, emer_phone_num) -> degree 6
relation을 추상적인 개념으로 이야기할 때도 있고, set of tuple(튜플들의 집합)의 개념으로 이야기 할 때도 있으니 문맥에 따라 잘 파악하라.
간단히 정리하면 relational database는 relational data model에 기반하여 구조화된 database이며 여러 개의 relations으로 구성된다.
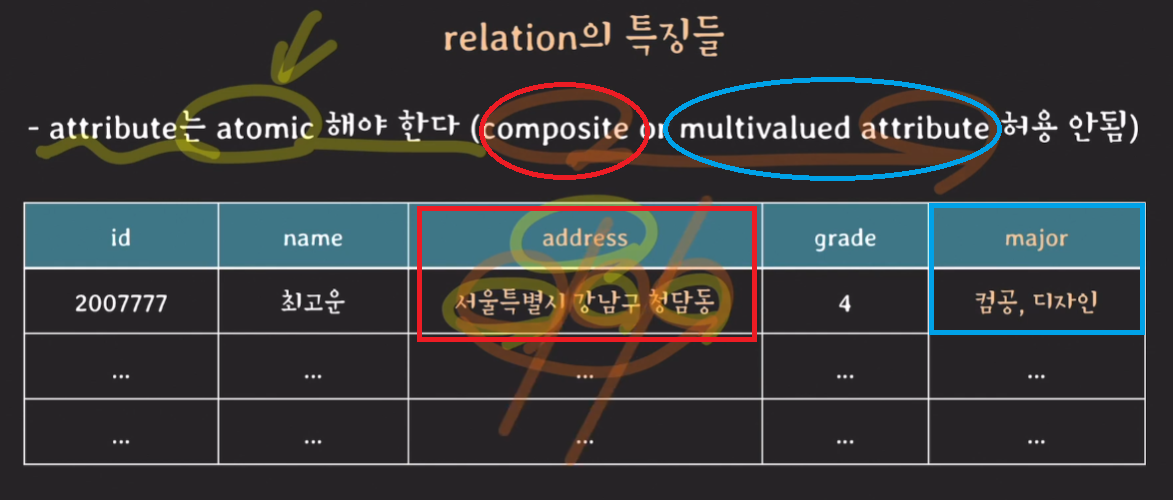
relation의 특징들
- relation은 중복된 tuple을 가질 수 없다. (relation is set of tuples)
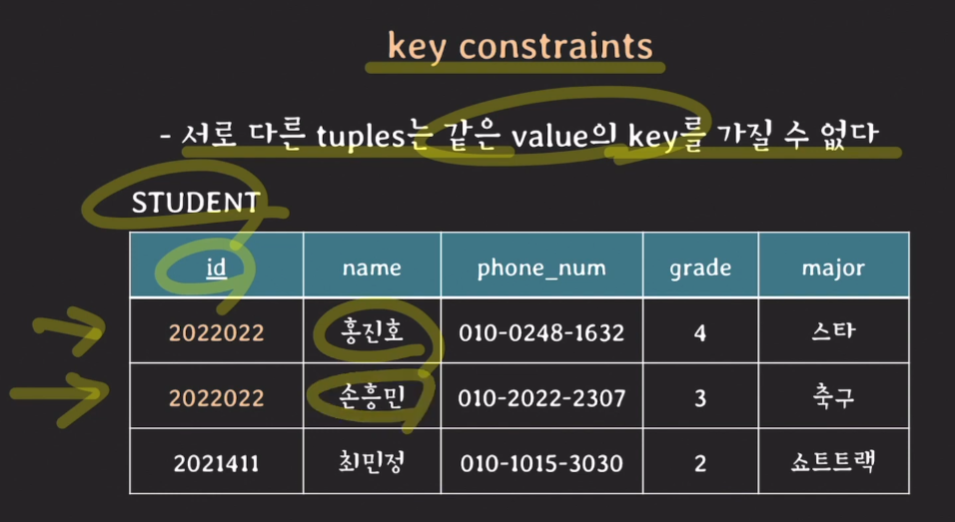
- relation의 tuple을 식별하기 위해 attribute의 부분 집합을 key로 설정한다.
- relation에서 tuple의 순서는 중요하지 않다. (순서, 정렬기준가 바뀐다고 relation의 의미가 바뀌지 않는다)
- 하나의 relation에서 attribute의 중복되면 안된다.
- 하나의 tuple에서 attribute의 순서는 중요하지 않다.
- attribute는 atomic해야 한다. (composite or multivalued attribute 허용 안됨)
NULL의 의미
- 값이 존재하지 않는다.
- 값이 존재하나 아직 그 값이 무엇인지 알지 못한다.
- 해당 사항과 관련이 없다.
key 설명 (기본키, 외래키 등등)
(1) superkey
relation에서 tuples를 unique하게 식별할 수 있는 attributes set
(superkey의 attributes set의 조합에 따라 여러 경우의 수로 나뉠 수 있다)
(2) candidate key
어느 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 super key
key 또는 minimal superkey라고 부르기도 한다.
(3) primary key
relation에서 tuples를 unique하게 식별하기 위해 선택된 candidate key
(4) unique key
primary key가 아닌 candidate keys
alternate key라고 부르기도 한다
(5) foreign key
다른 relation의 PK를 참조하는 attributes set
constraints 설명
relational database에서 relation들이 언제나 지켜줘야 하는 제약사항
(1) implicit constraints (암시적 제약)
relational data model 자체가 가진 constraints
relation은 중복되는 tuple을 가질 수 없다.
relation 내에는 같은 이름의 attribute를 가질 수 없다.
(2) schema-based constraints
주로 DDL(Data Definition Language)을 통해 schema에 직접 명시할 수 있는 constraints
explicit constraints (명시적 제약)
(2.1) domain constraints

(2.2) key constraints
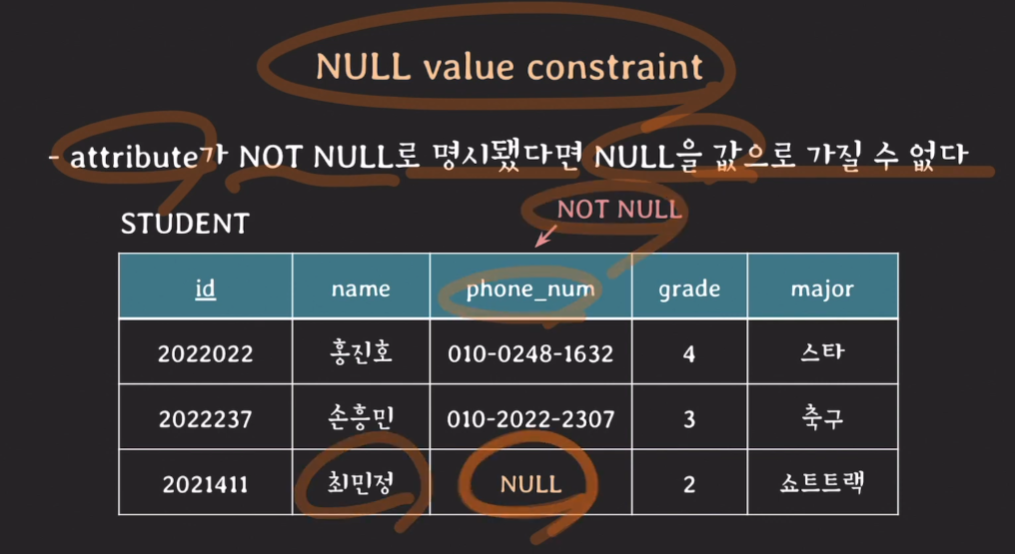
(2.3) NULL value constraint
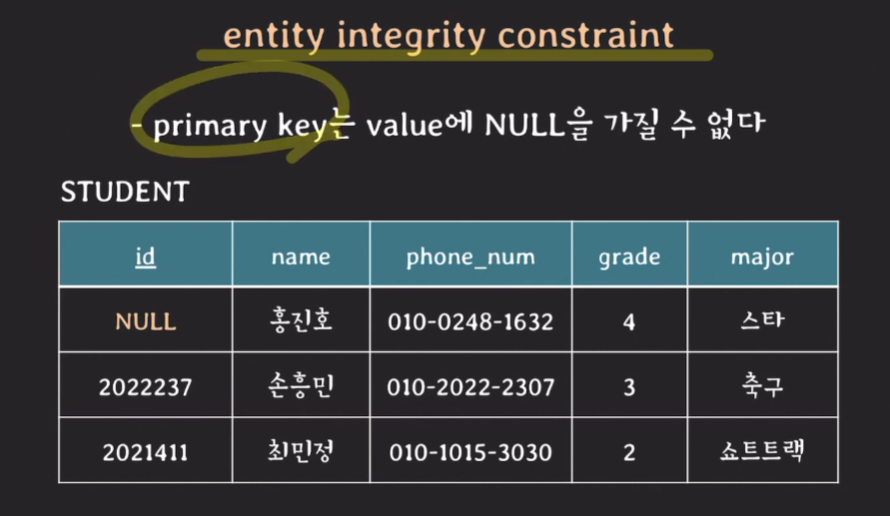
(2.4) entity integrity constraint
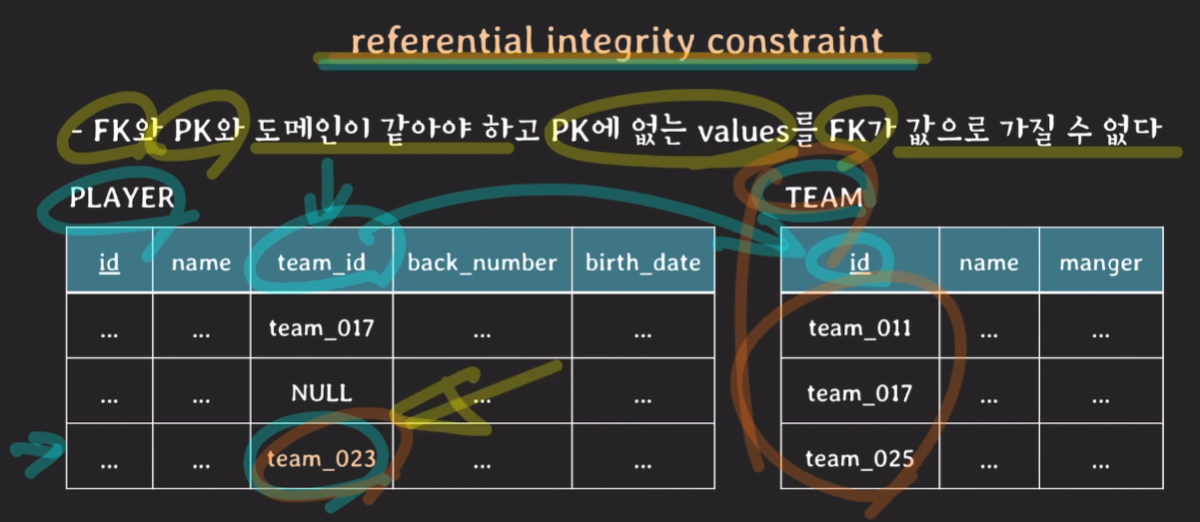
(2.5) referential integrity constraint
제약조건의 존재의의!
Database가 일치된 형태로 데이터의 일관성을 보장하기 위한 것.
