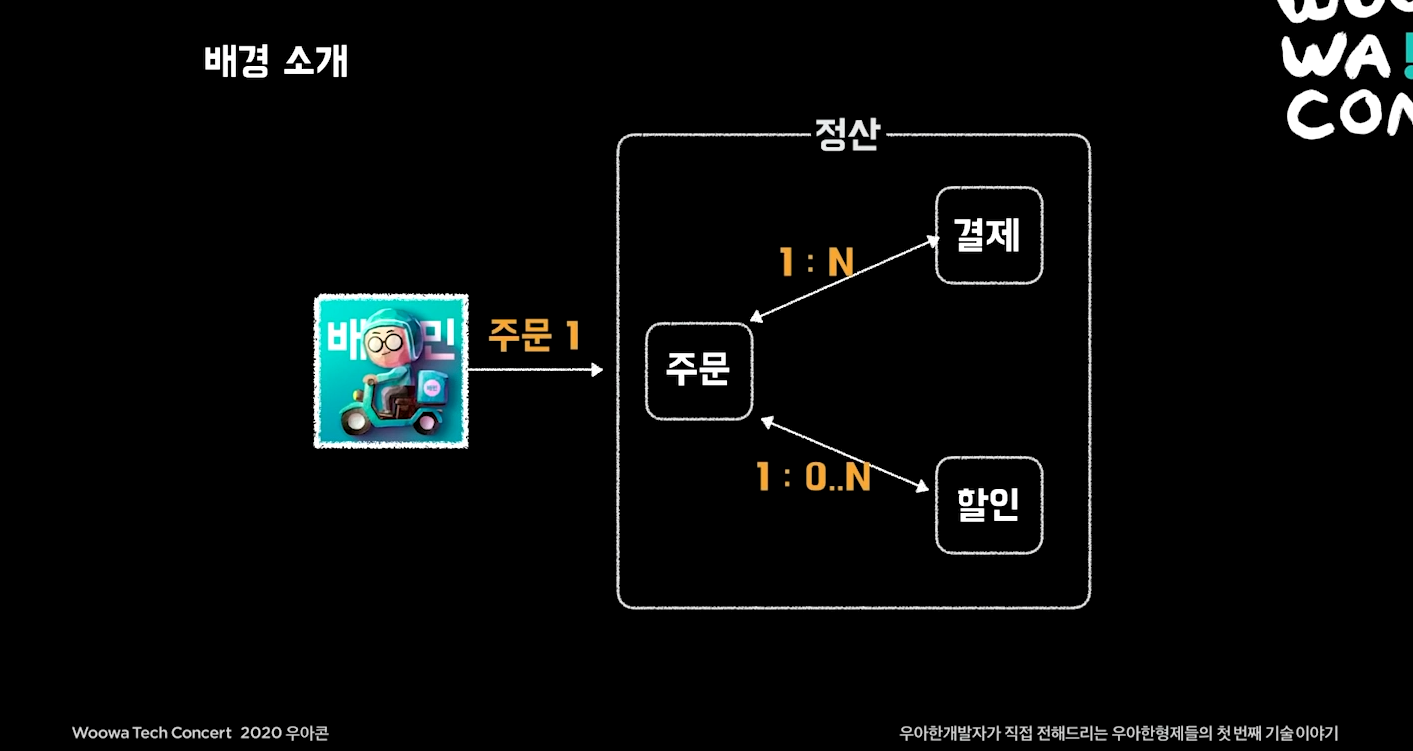

적재된 데이터가 1000만건에서 10억건까지 되는 과정에서 얻은 Querydsl-JPA 개선 TIP
발표대상 : 현업에서 JPA & Querydsl-JPA를 쓰고 계신분

1. 워밍업
extneds / implements (상속/구현) 사용하지 않기
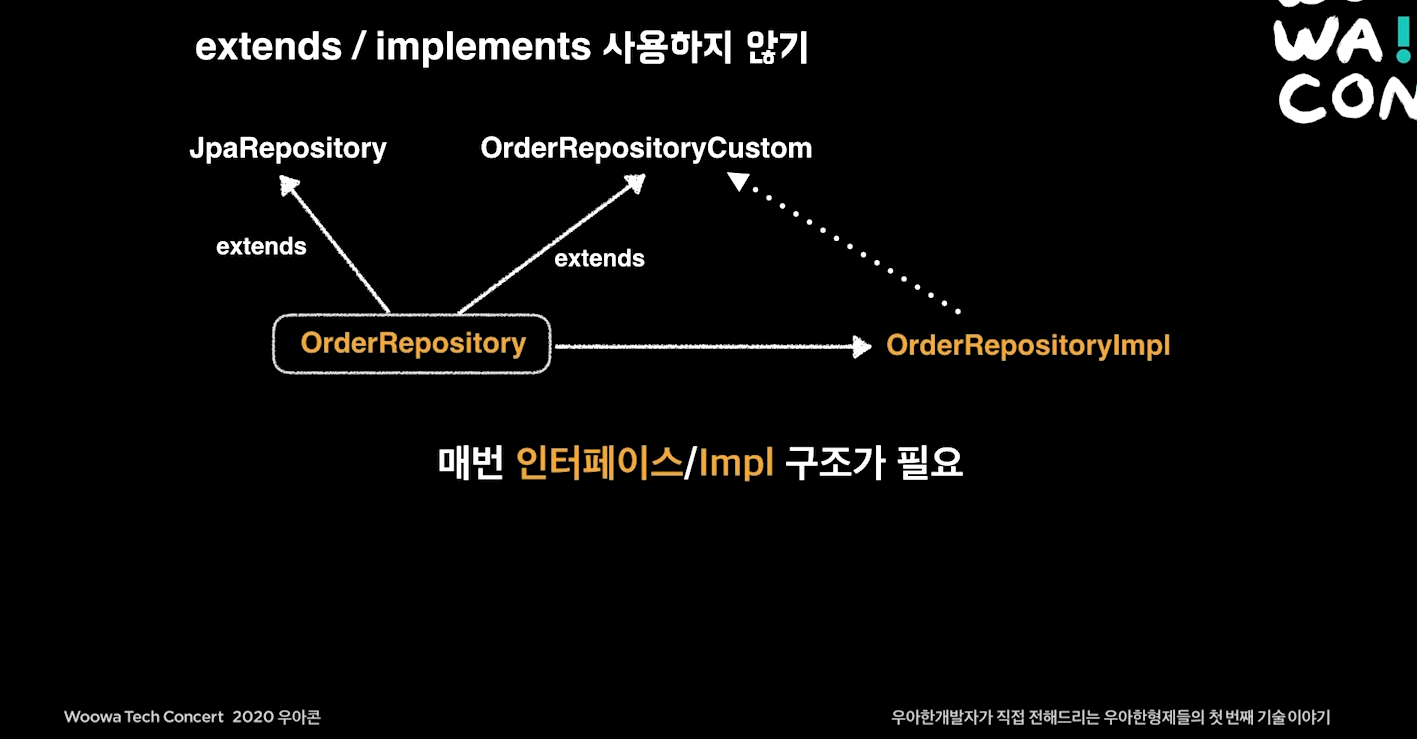

꼭 무언가를 상속/구현 받지 않더라도, 꼭 특정 Entitiy를 지정하지 않더라도 Querydsl을 사용할 수 있는 방법에 대한 고민. 아래는 그 해결책.

동적쿼리는 BooleanExpression


2. 성능개선 - Select
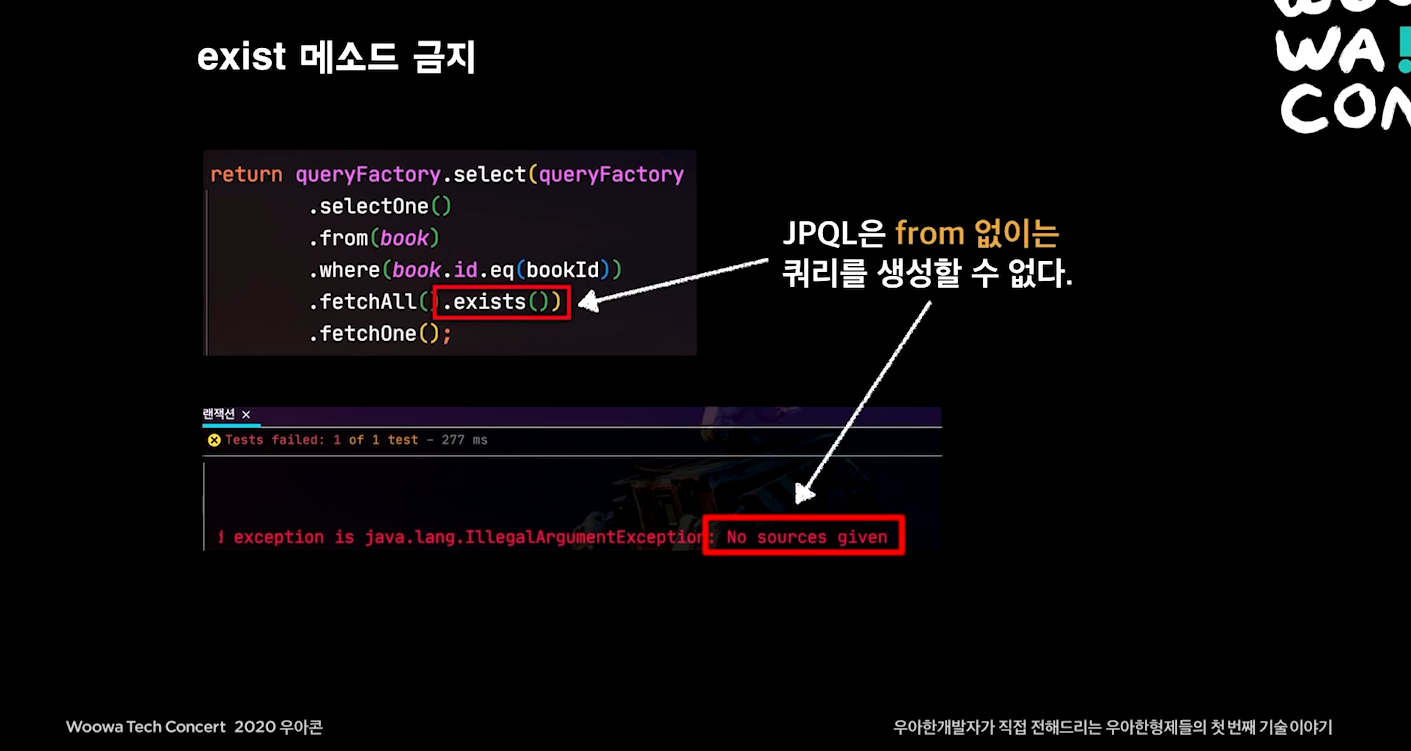
Querydsl에서 exist 금지
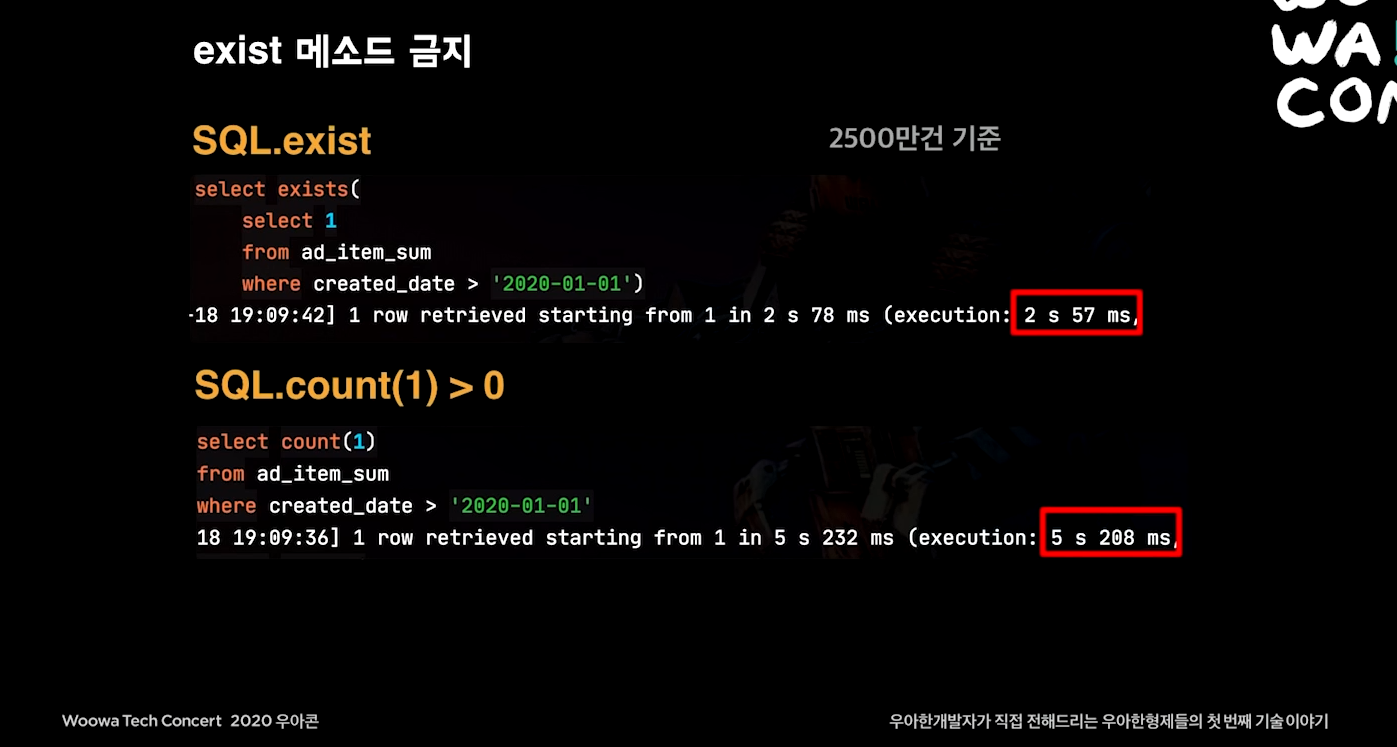
exist는 데이터를 찾으면 검색이 끝나지만, count는 중간에 데이터를 찾아도 끝까지 검색함.
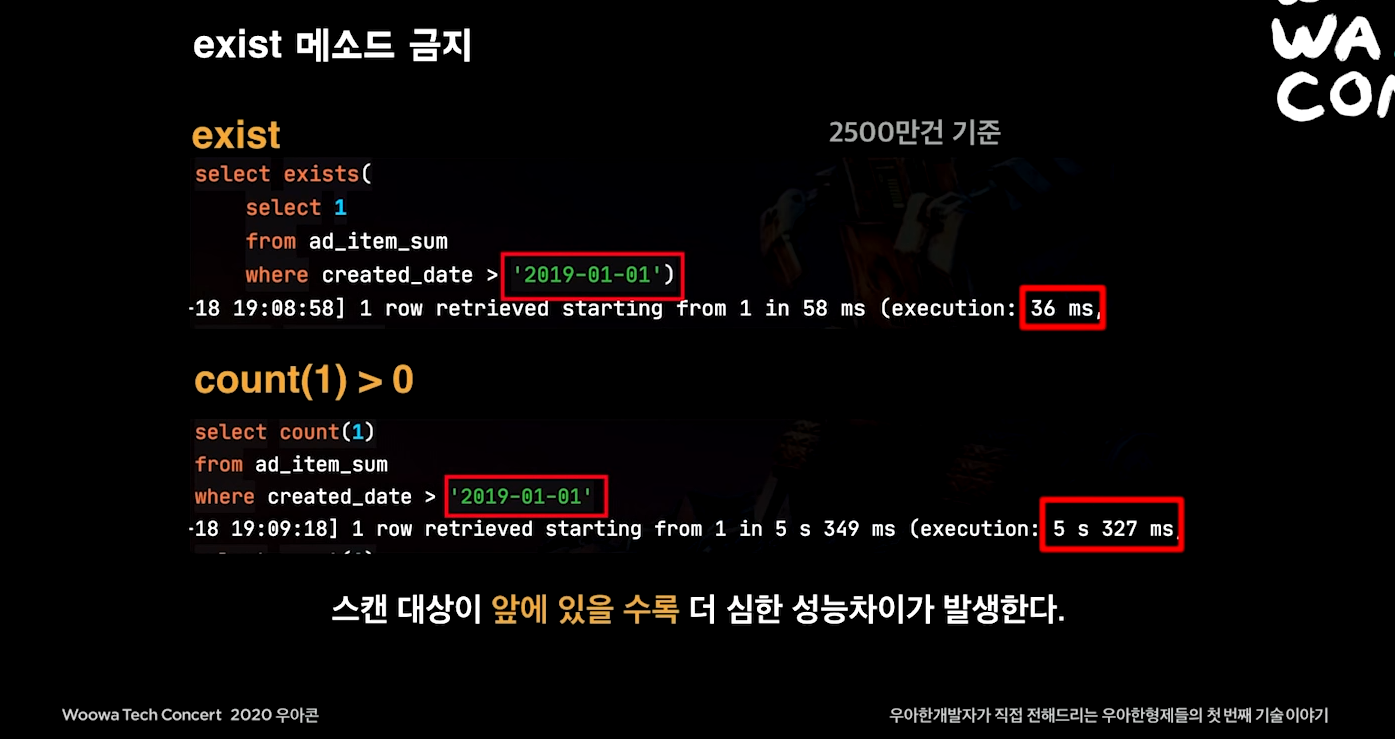
스캔 대상이 앞에 있을수록 더 심한 성능차이가 발생한다.
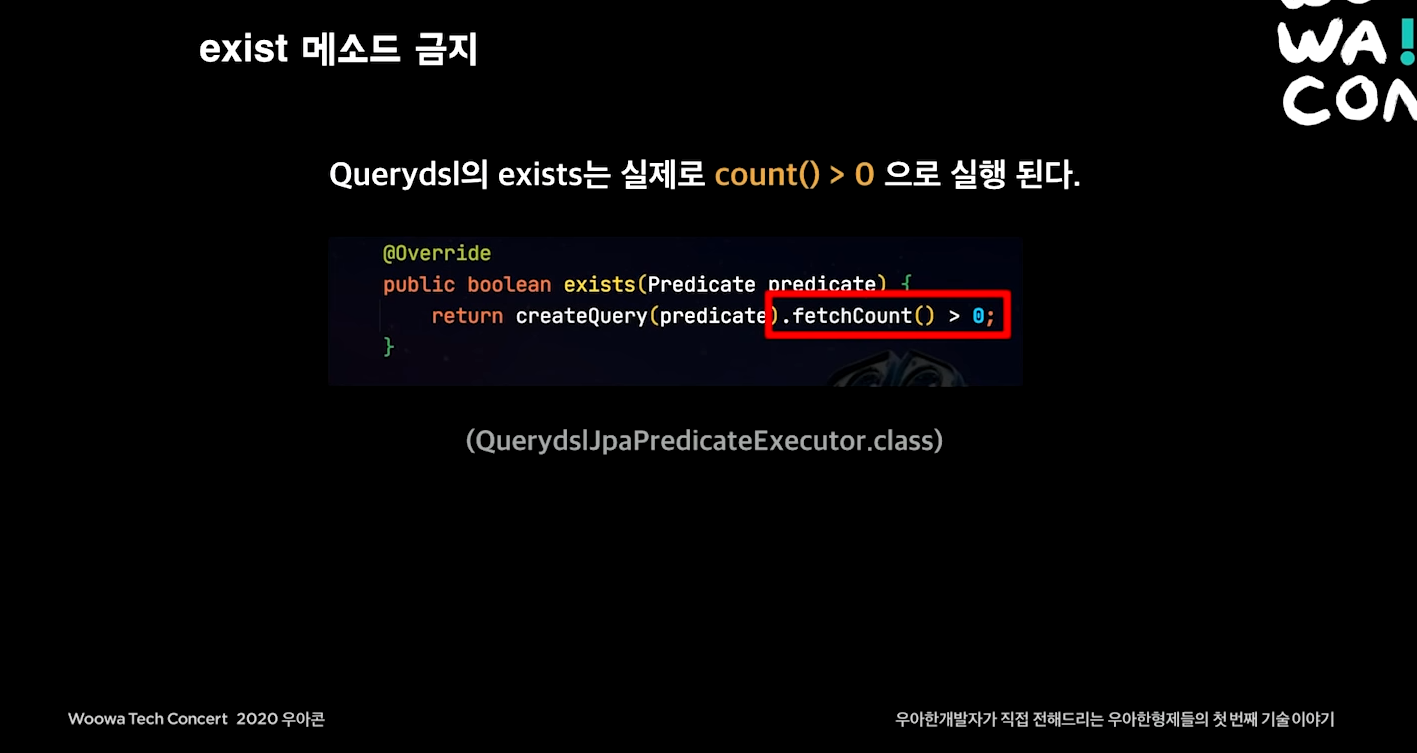
근데 웃기게도 Querydsl의 exists는 실제로 count() > 0으로 실행된다.

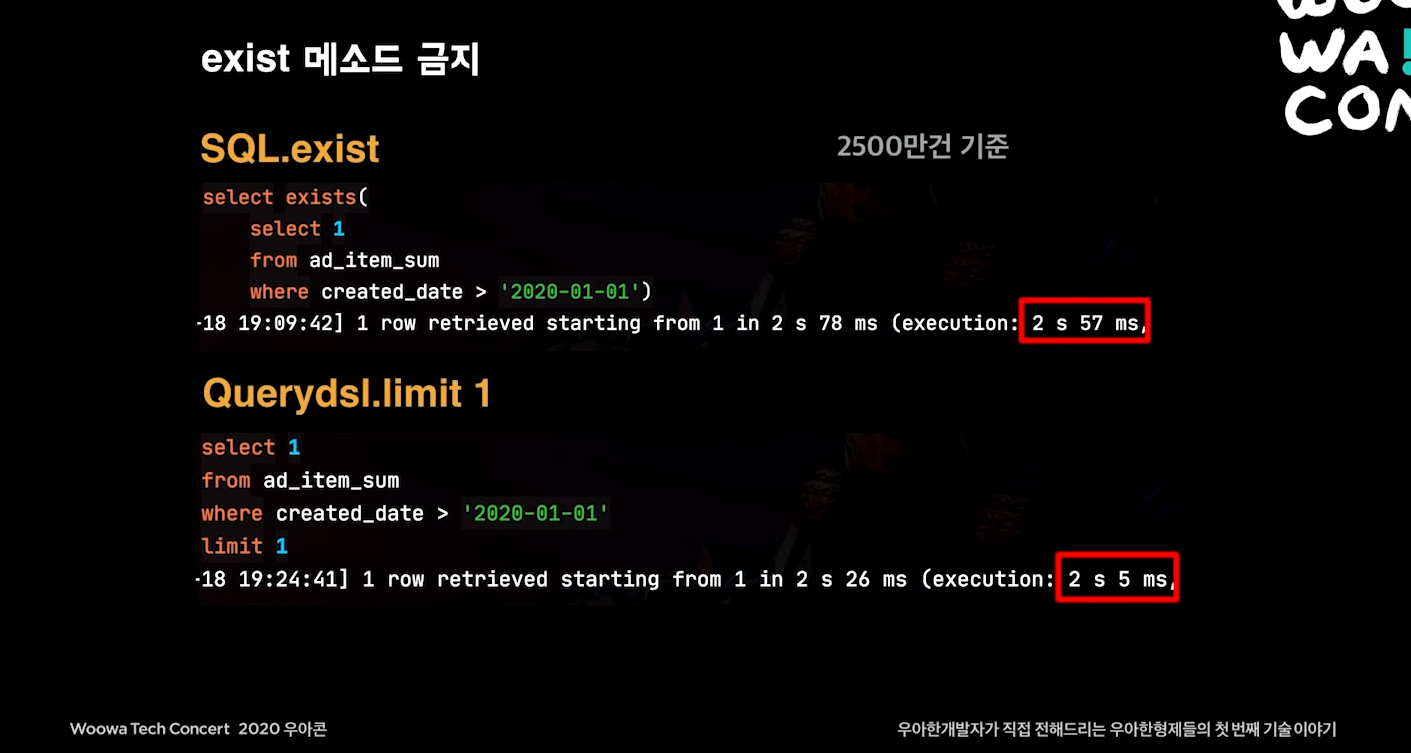
limit 1로 조회 제한

조회결과는 0과 1이 아닌 null로서 체크해야함.
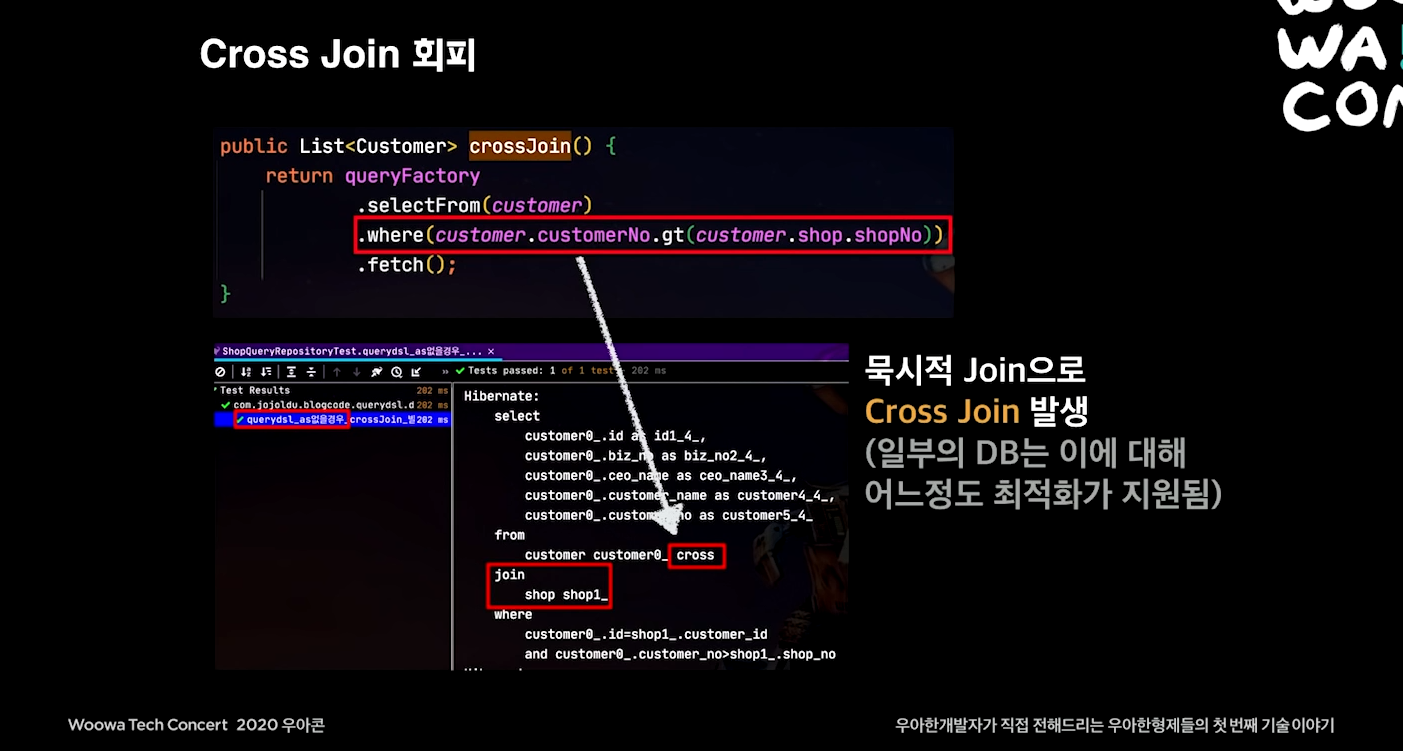
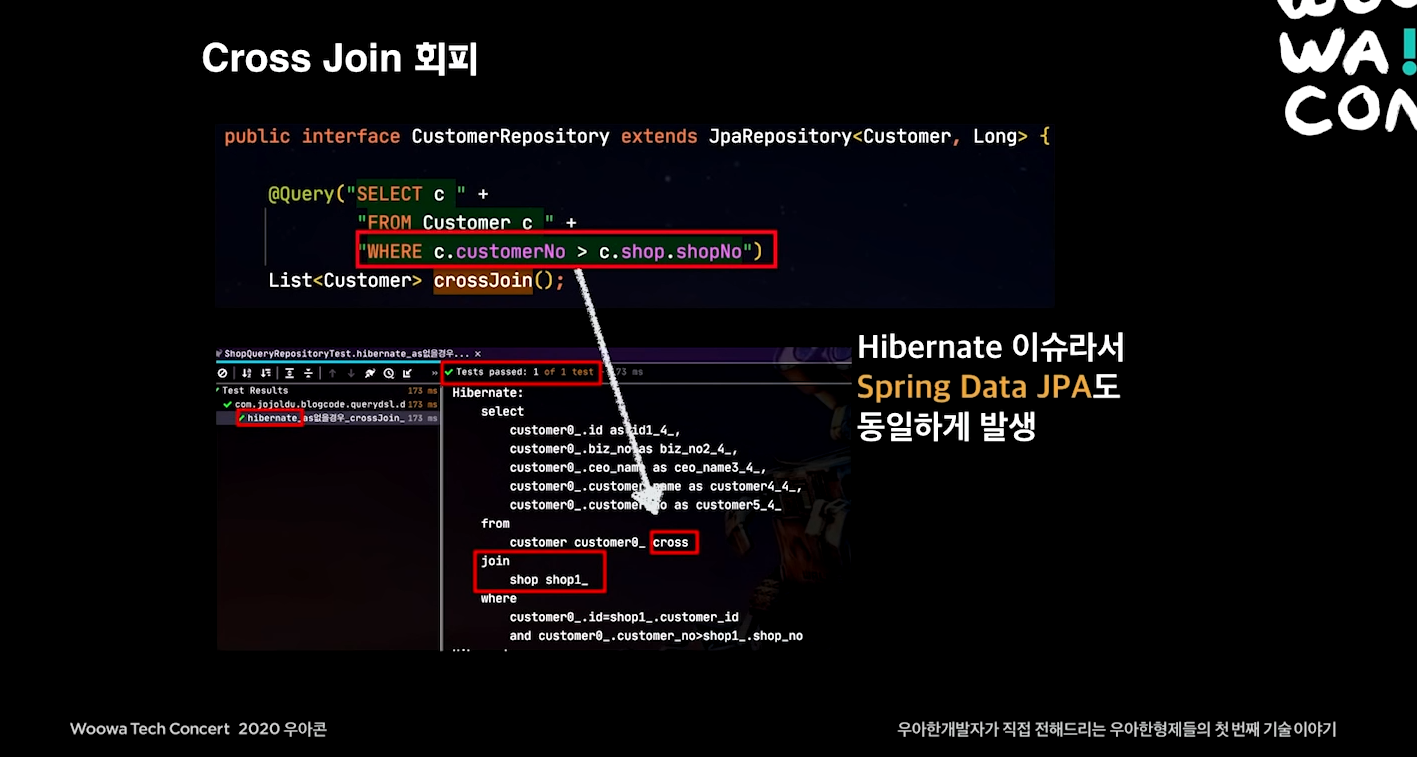
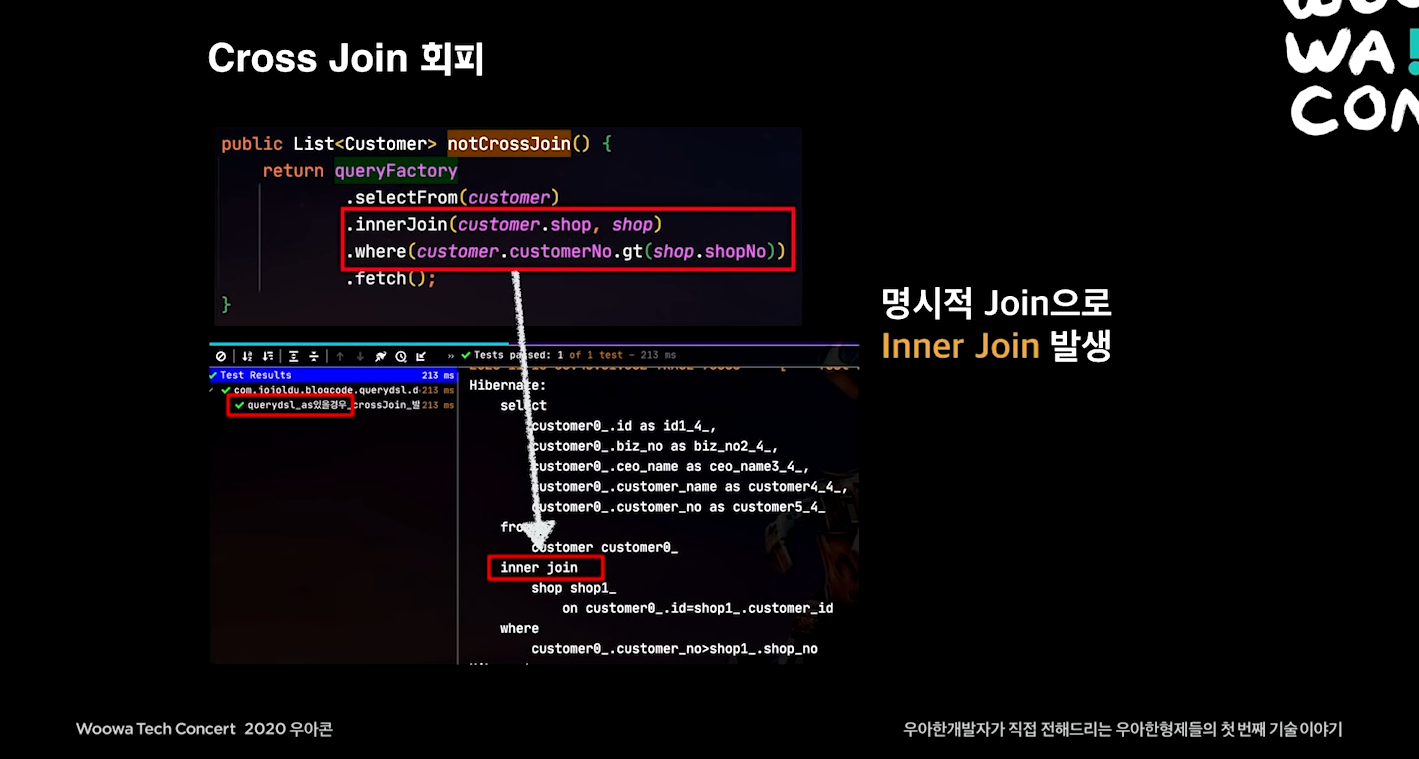
cross join 회피
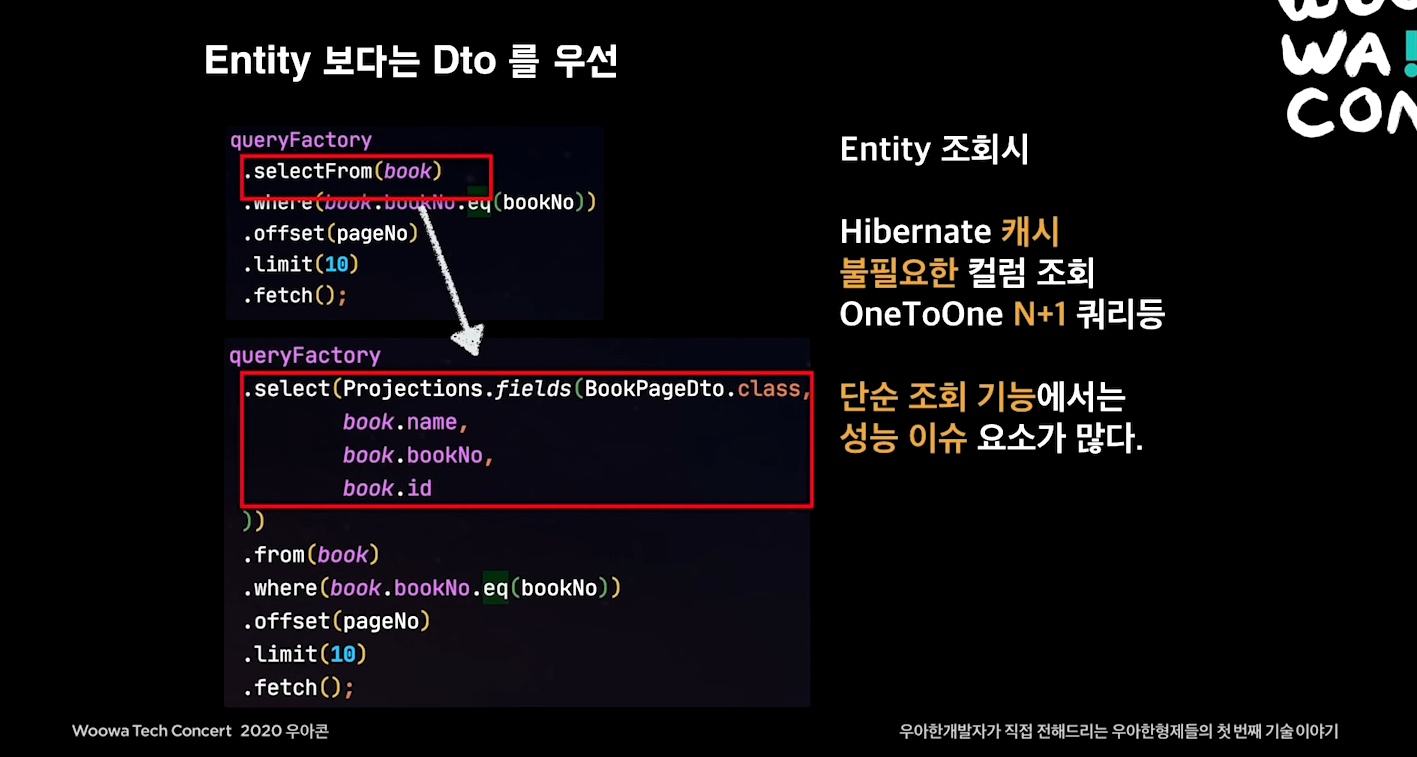
Entity 보다는 Dto를 우선

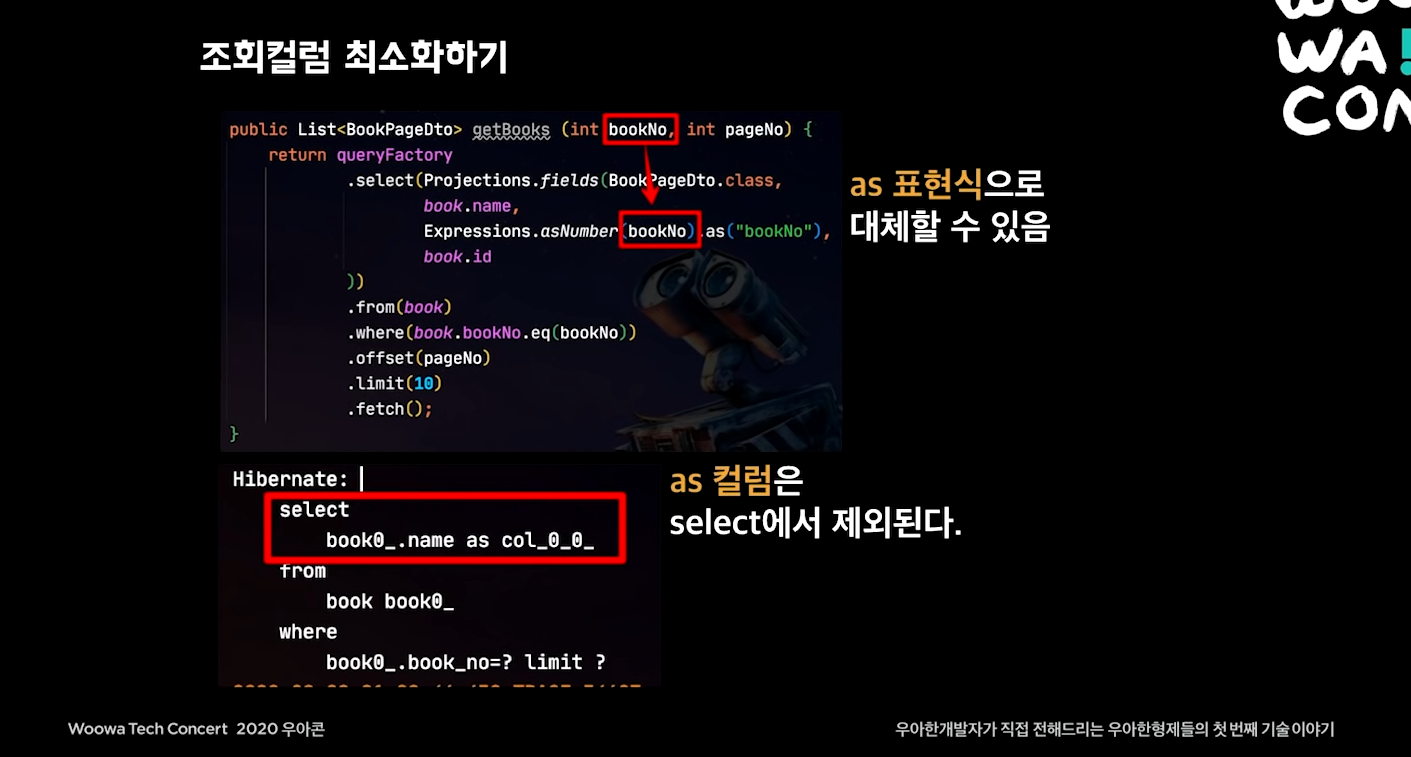
조회 컬럼 최소화하기
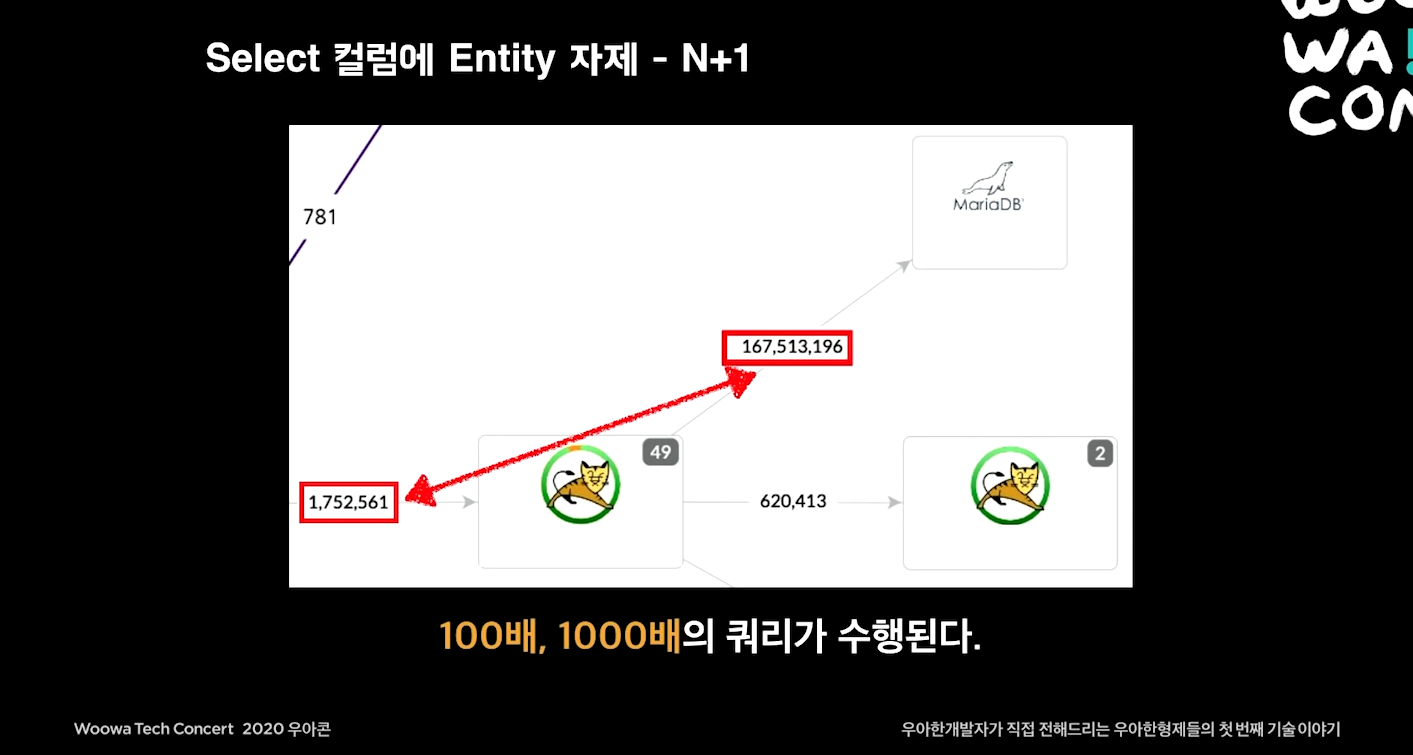
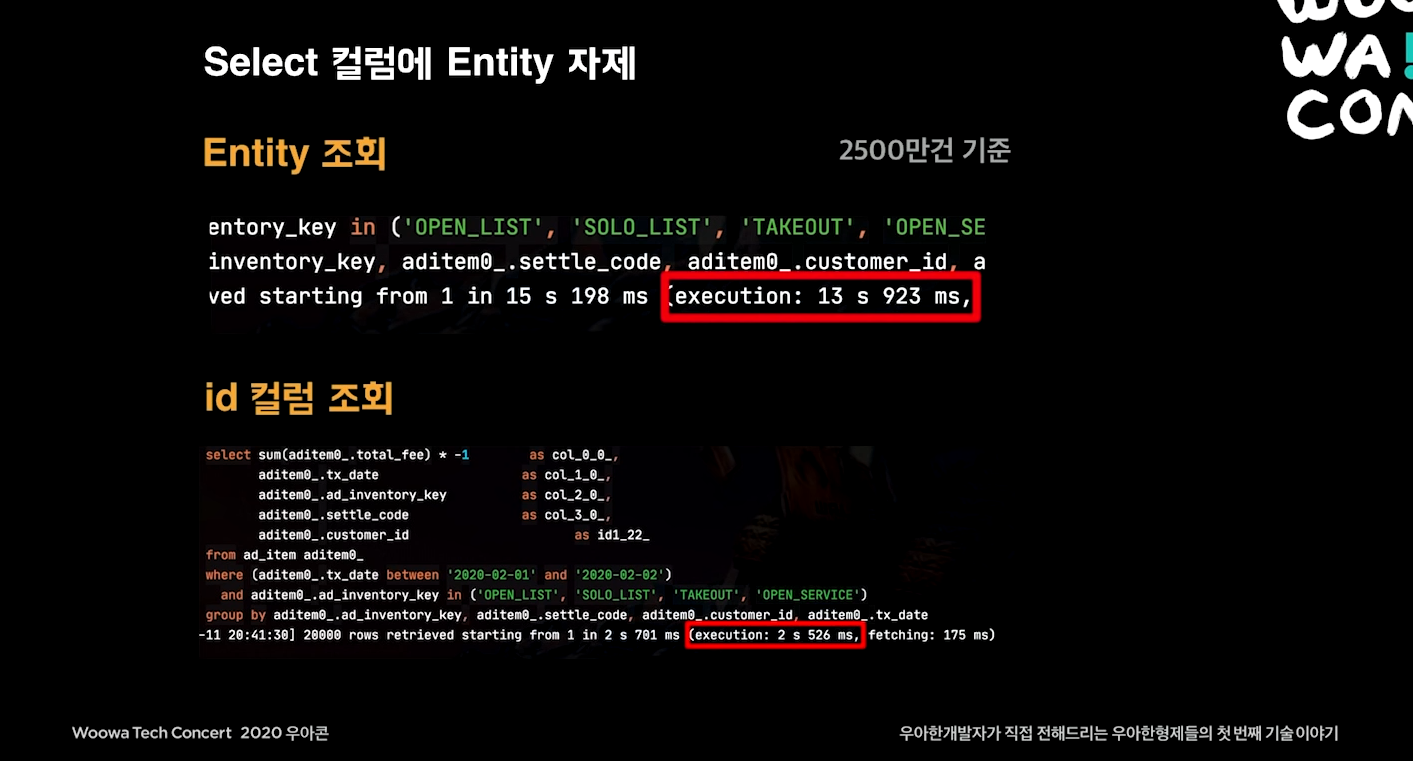
Select 컬럼에 Entity 자제



Q1. 만약 Shopt에도 @OneToOne이 있다면?
Q2. Entity간 연관관계를 맺으려면 반대 Entitiy가 있어야하지 않나요?



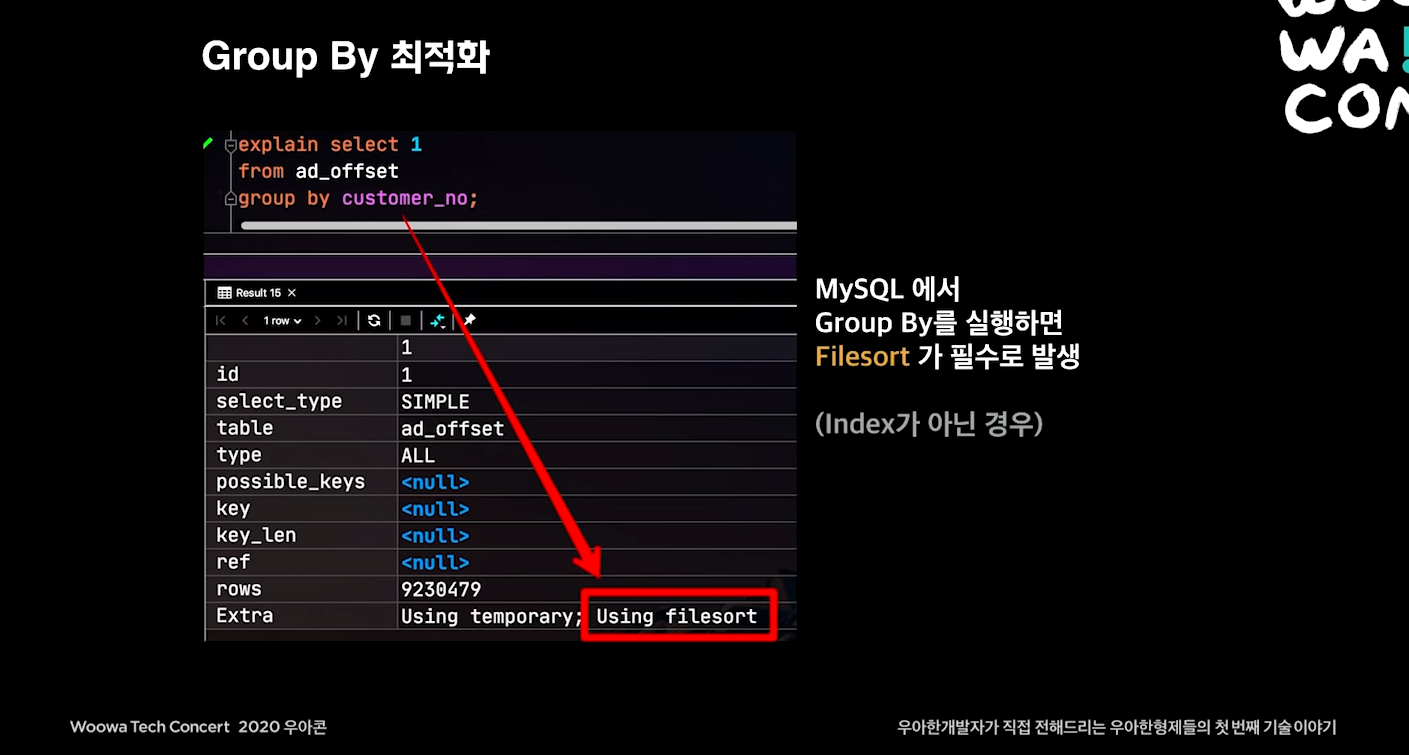
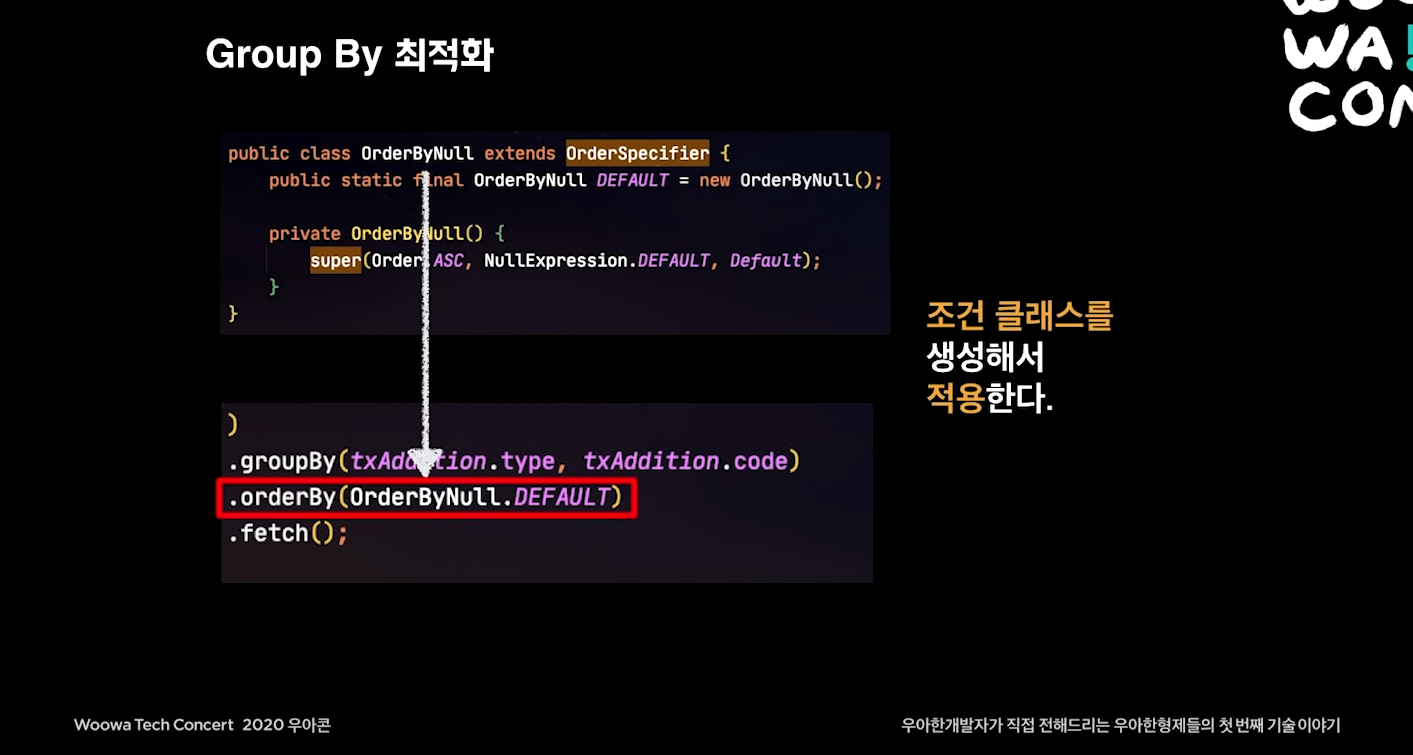
Group By 최적화



일반적으로 DB보다 WAS의 자원(비용, COST)이 저렴하다.
DB는 4~5대를 사용해도, WAS 수십~수백대를 쓰는 경우가 빈번함.
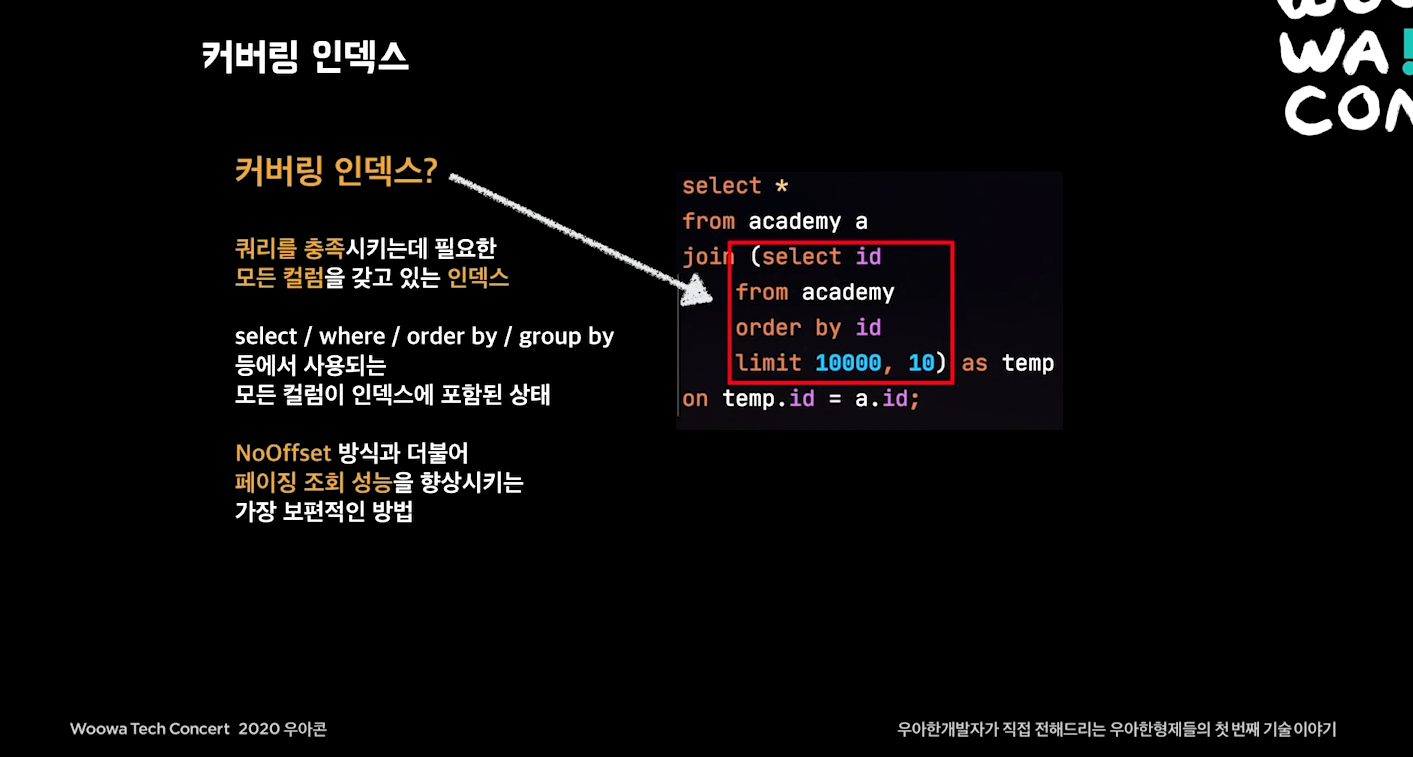
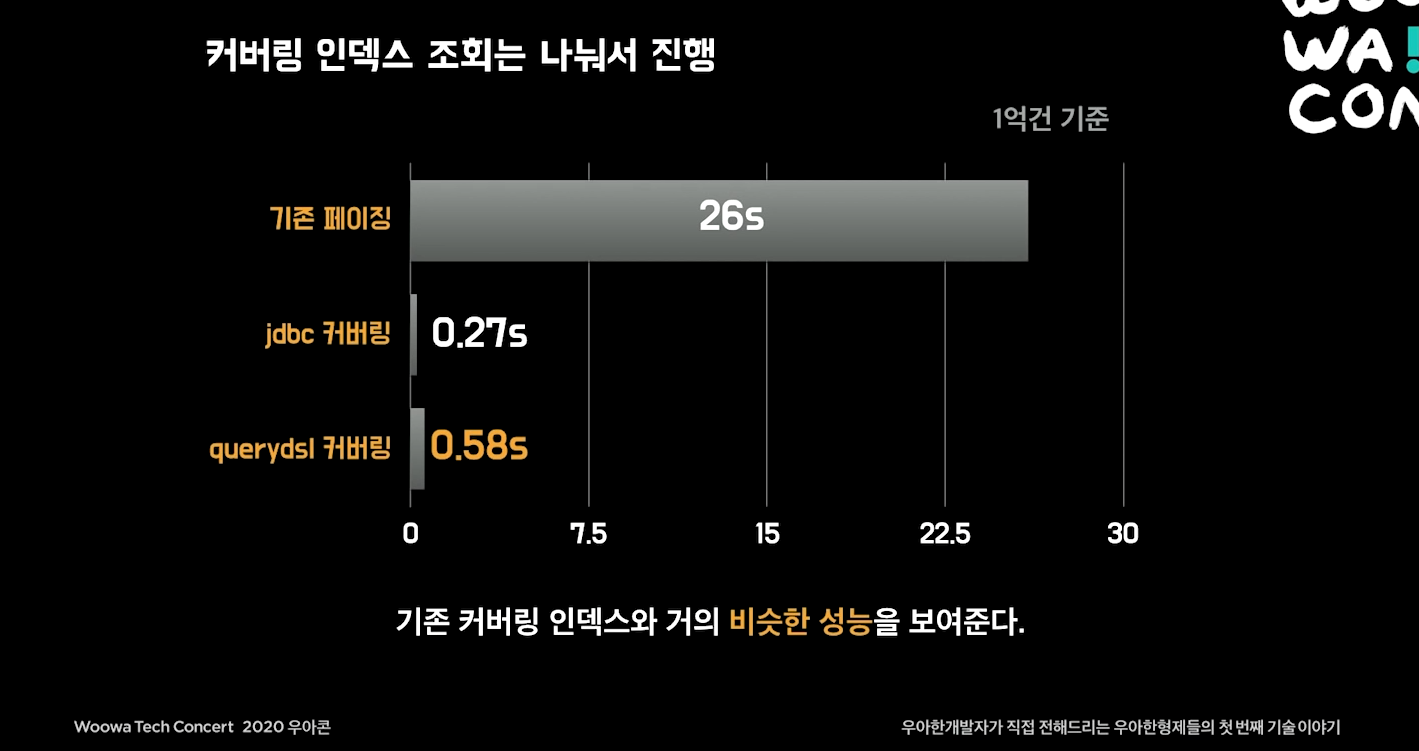
커버링 인덱스


3. 성능개선 - Update/Insert
일괄 Update 최적화




공통적으로 전달하고 싶은 것

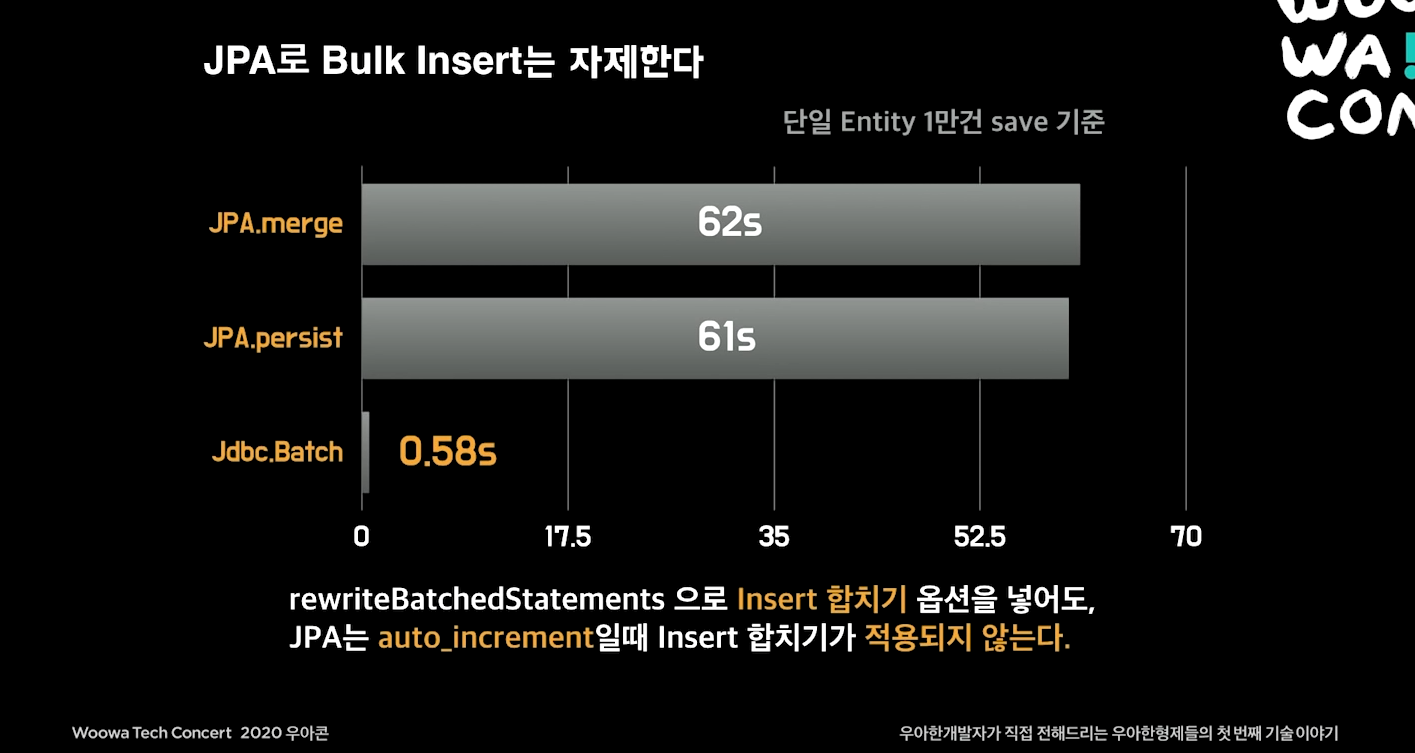
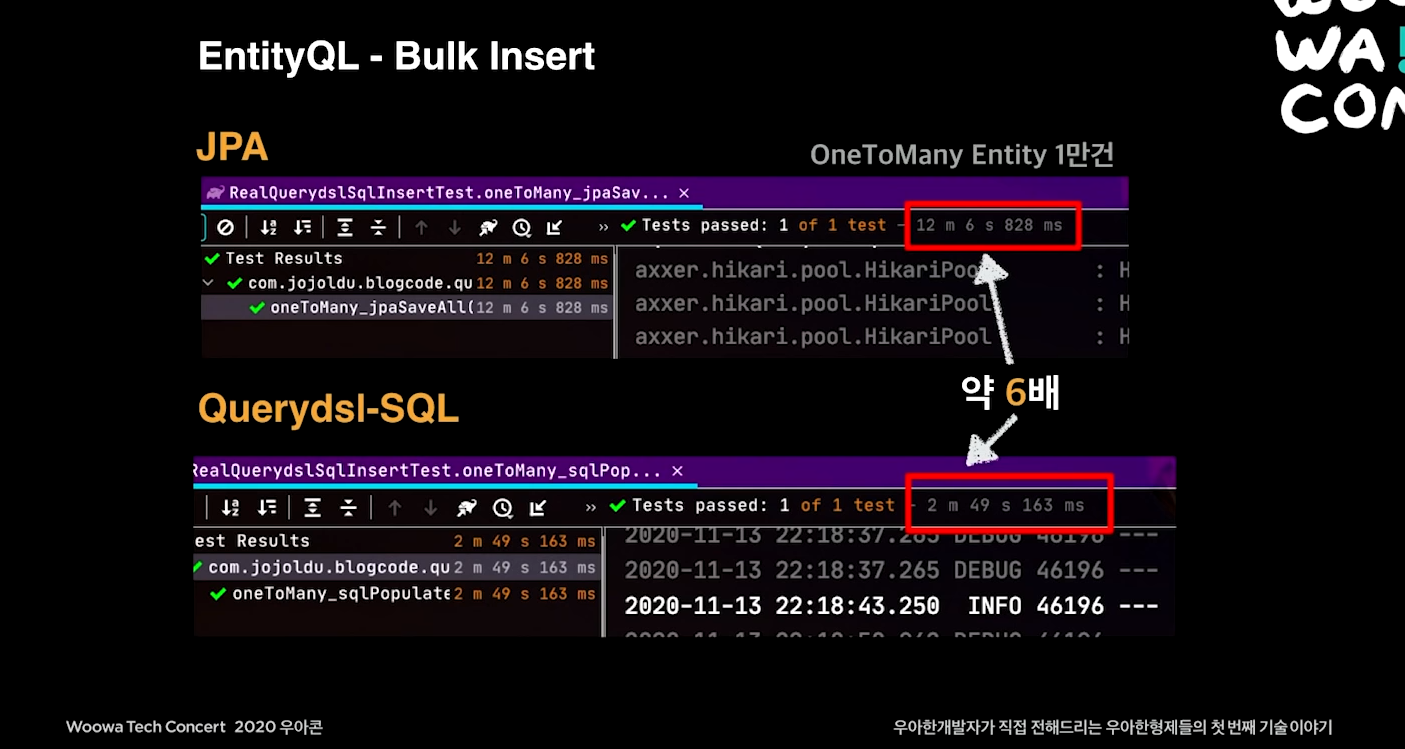
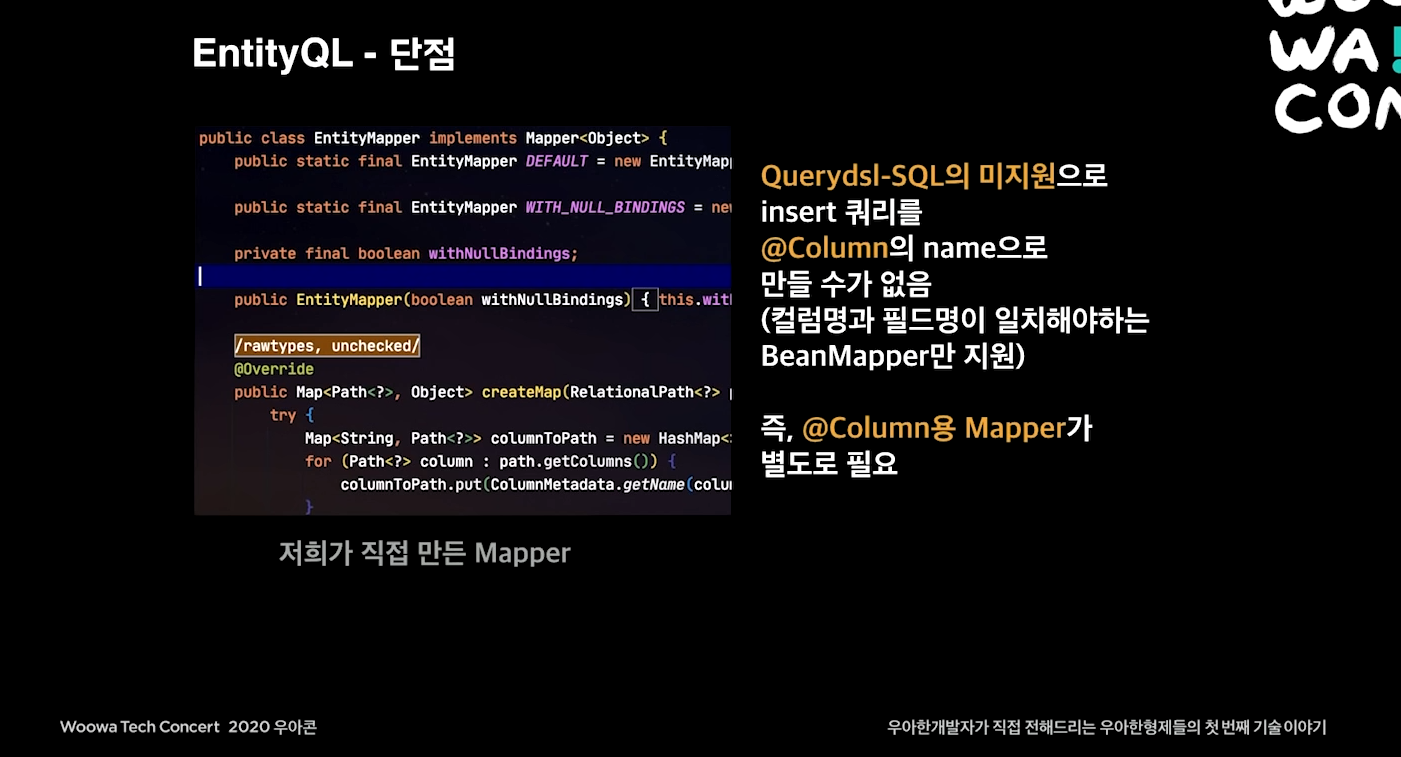
Bulk Insert (Insert 합치기)




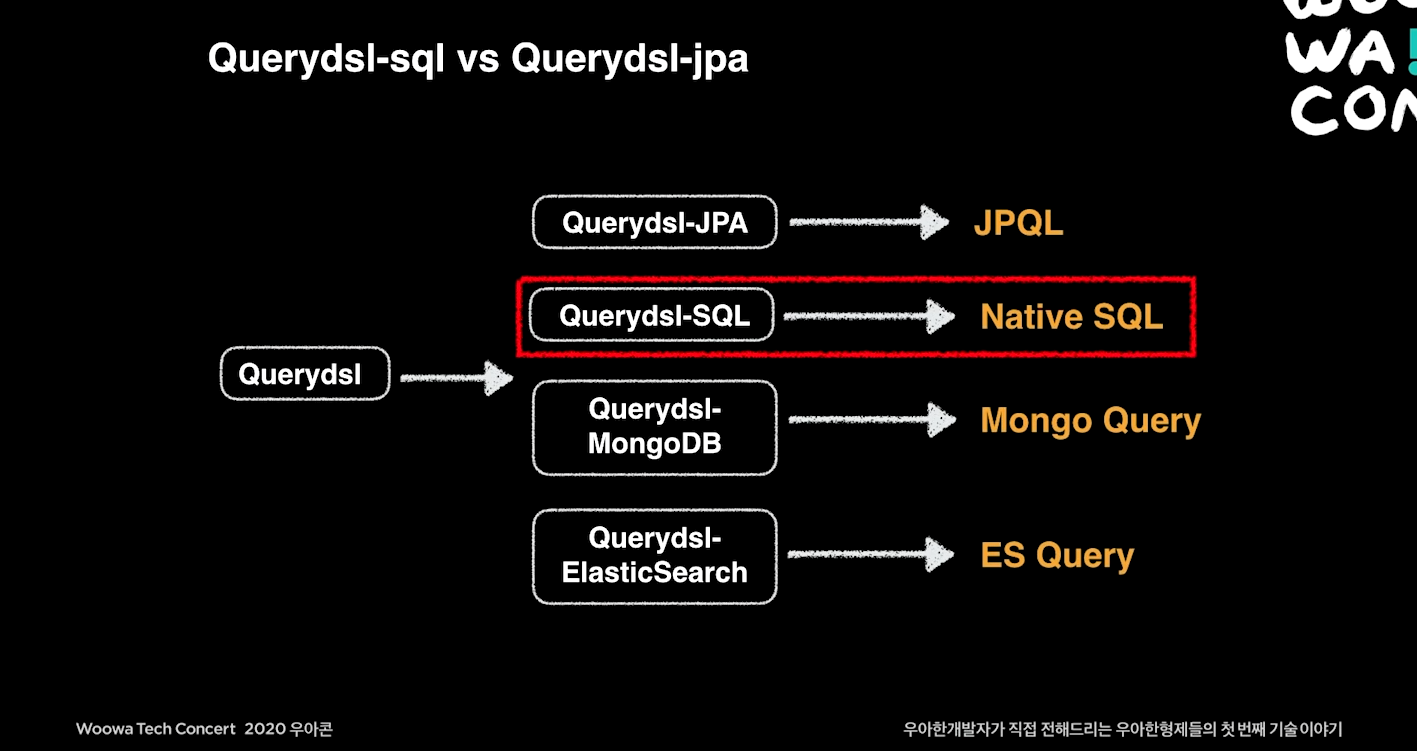




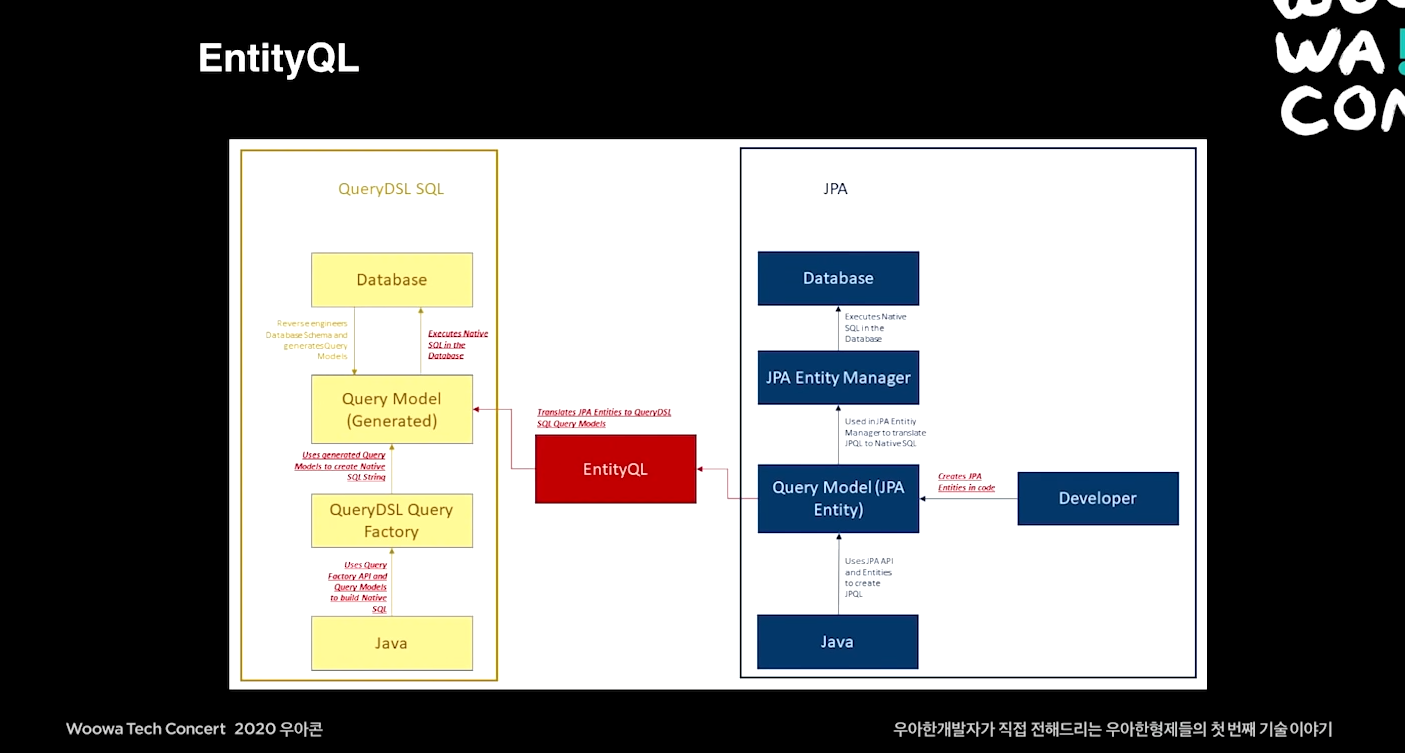
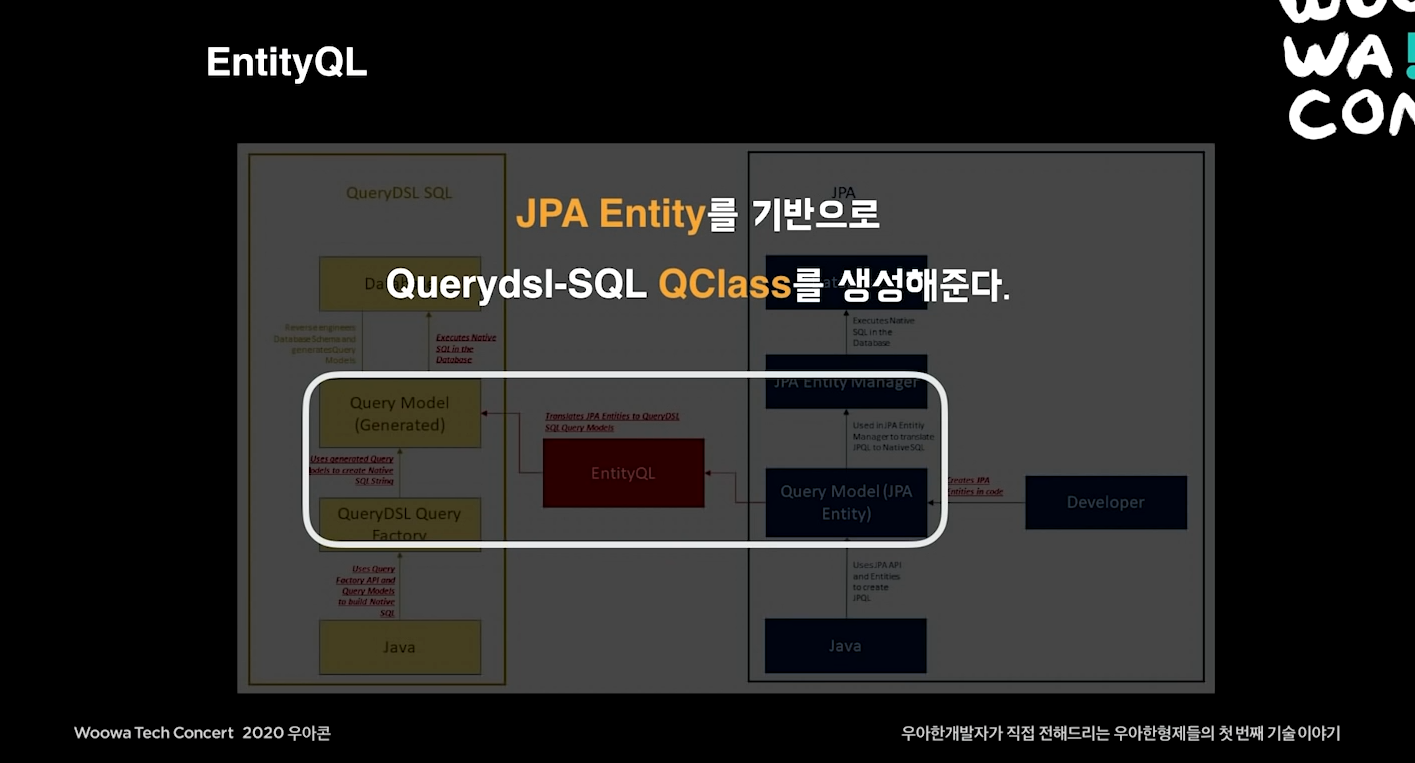

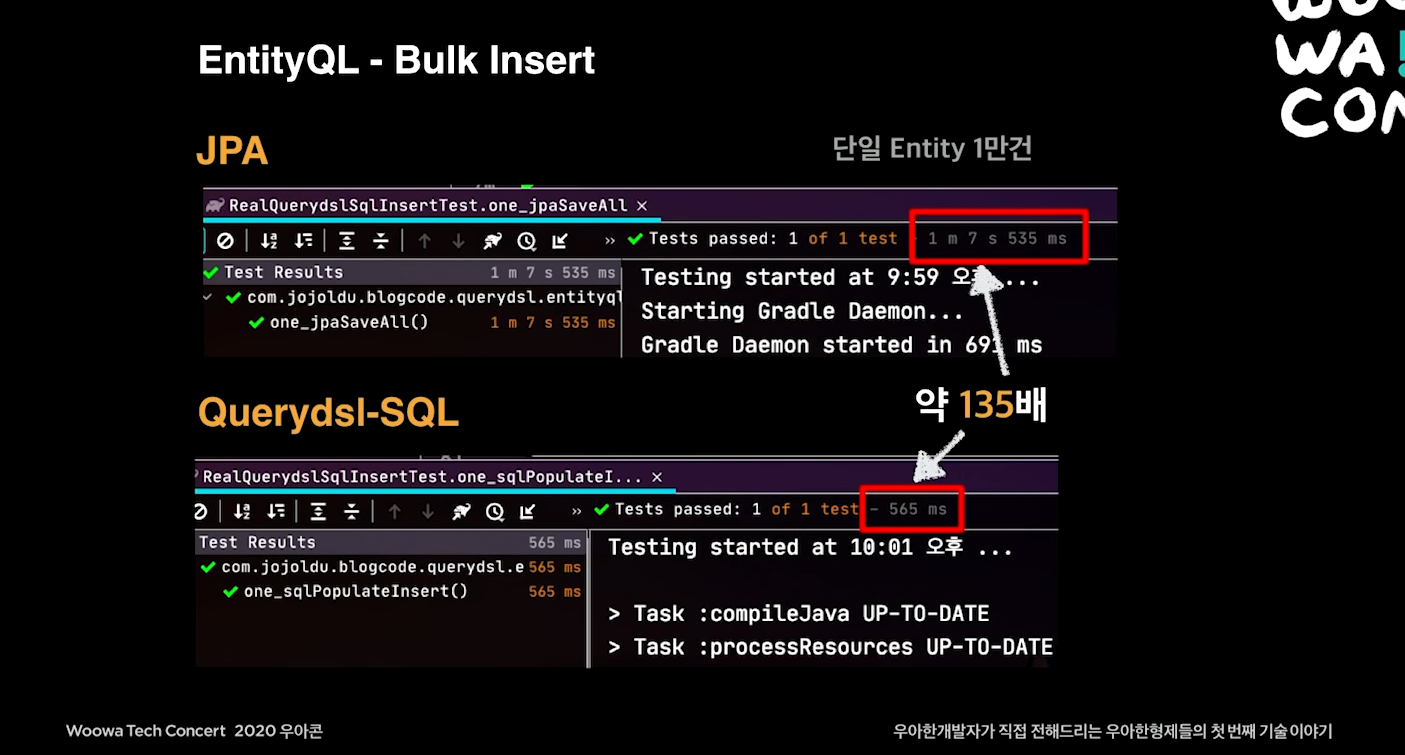


4. 마무리



Engineer, Look Beyond the Code.