EKS란?
Amazon Elastic Kubernetes Service(Amazon EKS) 의 약자로 ,
클라우드, 또는 온프레미스에서 Kubernetes 어플리케이션을 실행하고 크기를 조정하는 관리형 컨테이너 서비스 이다.
동작 방식
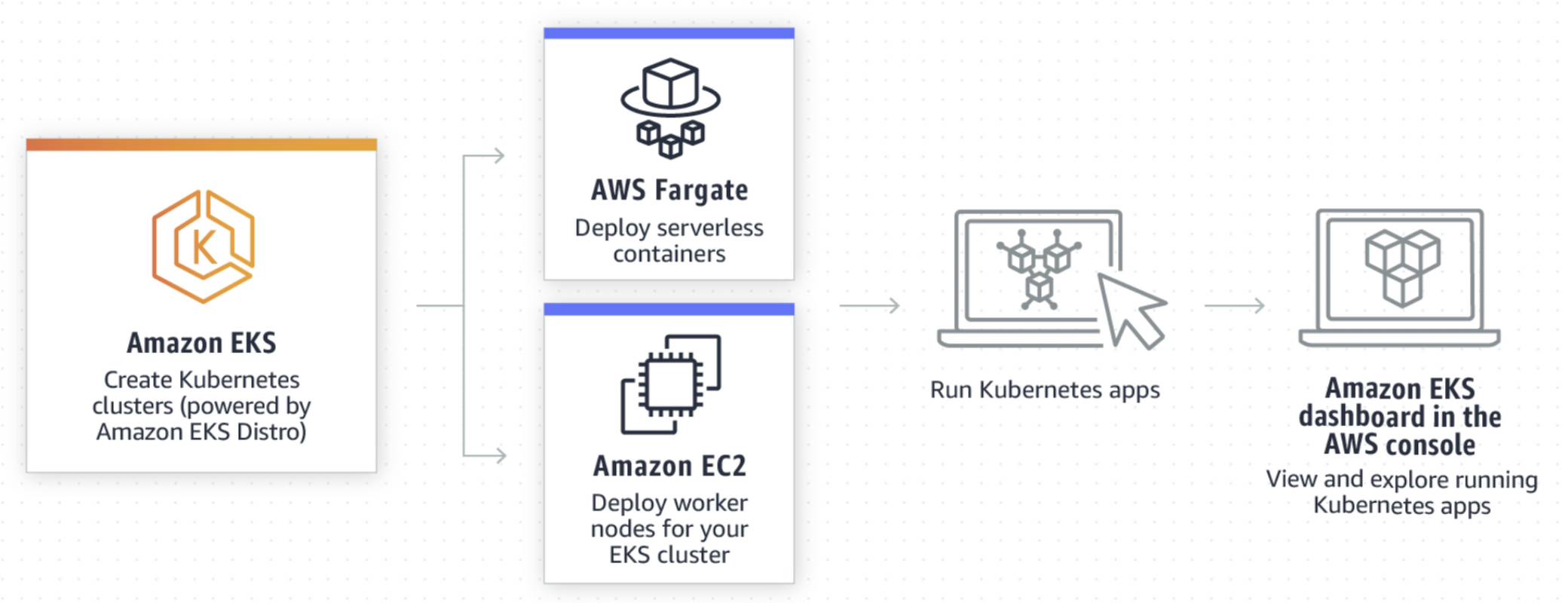
Elasticsearch 및 Kibana 구성 결과
Elasticsearch 접속확인
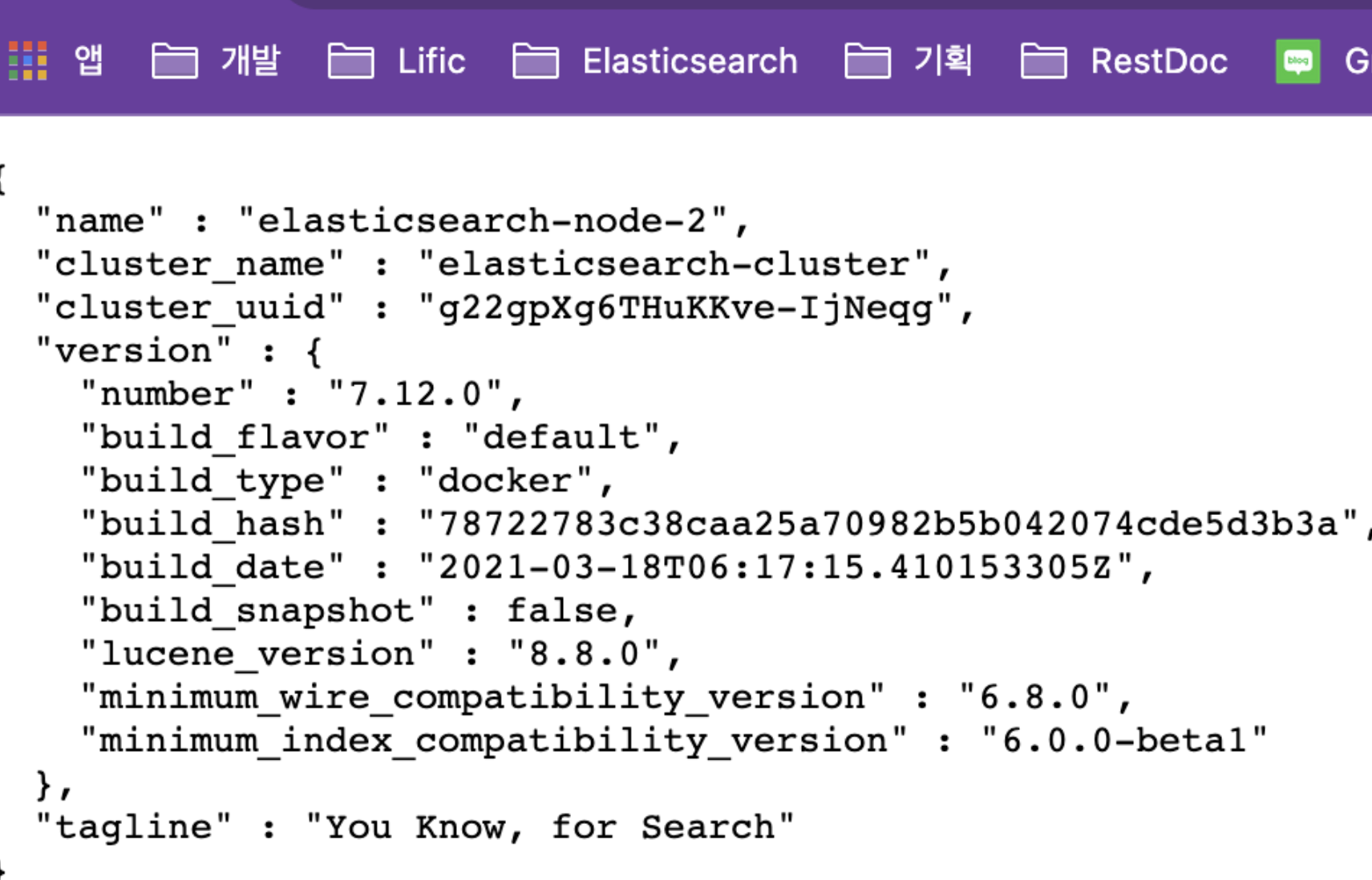
Kibana와 Elasticsearch 클러스터링 연결 확인
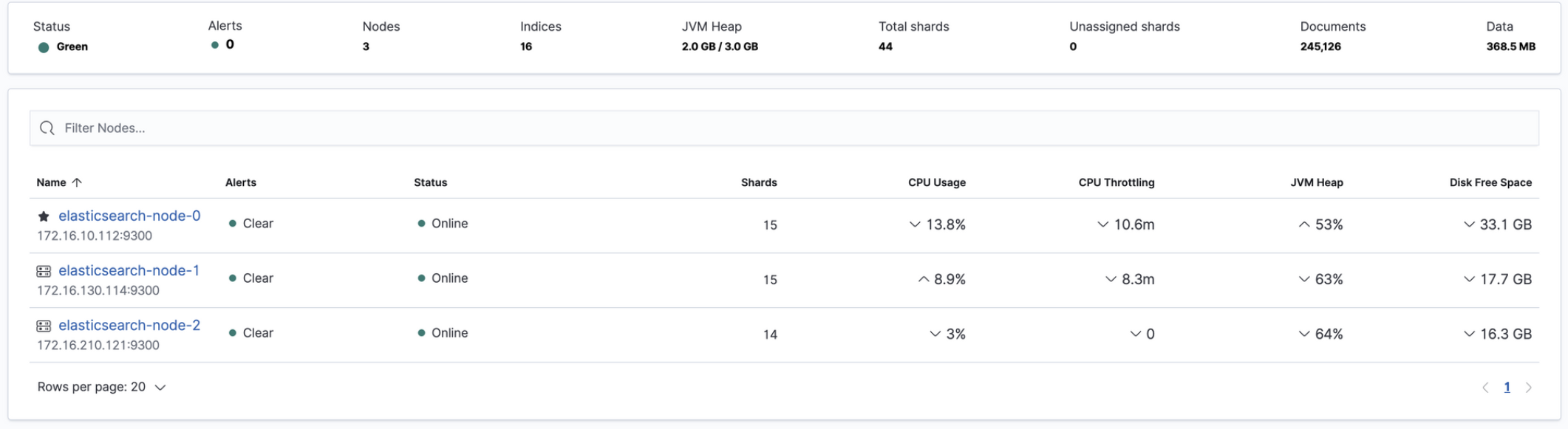
Kubernetes Pods 구성 확인

Elasticsearch EKS 구성하기
💡 ES를 구성함에 있어서 가장 중요한 부분은 내부 POD들의 `클러스터링 여부`이다. EKS에서는 설정에 따라 일정 이상 부하가 생길 경우, `가변적으로 POD의 개수를 늘린다`. 이때 ES에서는 늘어난 POD도 서로 클러스터링이 되어야 하며, 각각의 노드가 이름으로 관리가 되어야 한다. ( 일반적인 방식에서의 POD 이름은 랜덤 코드 이름이 부여된다 ) 💡 Docker 이미지는 직접적으로 만들지 않고 [**docker.io**](http://docker.io) 에서 제공하는 이미지를 사용한다Elasticsearch → docker.elastic.co/elasticsearch/elasticsearch:7.12.0
Kibana → docker.elastic.co/kibana/kibana:7.12.0
EKS 구성시 필요한 용어
쿠버네티스의 설정이나 용어들이 낯설어서 명시
[용어] Ingress
인그레스는 클러스터 외부에서 클러스터 내부 서비스로 HTTP와 HTTPS 경로를 노출한다.
즉 Pods를 호출 할 수 있는 도메인 주소이다.
[용어] StateFulSet
어플리케이션의 stateFul을 관리하는데 사용하는 워크로드 API 오브젝트이다.
Pods 집합의 Deployment와 Scaling을 관리하며, Pods의 순서 및 고유성을 보장한다.
즉, ES의 내부 클러스터링과 Kinaba의 클러스터링이 연결이 되려면 해당 방식을 사용해야 한다.
[용어] ConfigMap
Key-Value로 기밀이 아닌 데이터를 저장하는데 사용하는 API 오브젝트이다. Pods는 볼륨에서 환경 변수, 커맨드-라인 인수 또는 구성파일로 컨피그맵을 사용할 수 있다. 컨테이너 이미지에서 환경별 구성을 분리하여, 어플리케이션에 이직할 수 있다.
즉, elasticsearch.yml, kibana.yml을 해당 기능으로 구성이 가능해 진다.
[용어] HPA(Horizontal Pod Autoscaler)
CPU사용량을 관찰하여 replication controller, deployment, replicaSet, statefulSet의 Pods 개수를 자동으로 스케일링한다
즉, 가변적으로 상황에 따라 Pods개수가 설정된 범위내에서 변경된다
[용어] Service
Pods 집합에서 실행중인 어플리케이션을 네트워크 서비스로 노출하는 추상화 방법
즉, 외부 DNS를 지정하고 로드밸런스를 여기서 수행한다.
[용어] PV (Persistent Volumes)
노드가 클러스터 리소스인 것처럼 PV는 클러스터 리소스.
즉, Pods의 외부 적재 스토리지
[설정파일옵션] NodePort
특정 Pods의 Application을 접근할 수 있도록 지정. NodePort 서비스를 만든다는 것은 Service를 포트로 지정하여 서로 연결
즉, 외부에서 Pods로 연결하기 위한 방법
[설정파일옵션] Image Pull Policy
deploy될때, 이미지에 대한 정책을 정한다. 예제는 IfNotPresent 지만 제대로 동작하지 않는다. 해서 Always로 변경

[Kubernetes] yml 적용 명령어
실제 적용시, 나뉘어진 yml파일에 대해 직접적으로 apply를 해주어야 한다.
현재의 예시에서는 hpa.yml, config.yml, service.yml, deployment.yml 이 적용되어야 한다
kubectl apply -f [yml 파일이름][Elasticsearch] ConfigMap 구성하기
💡 테스트 시에 실제로 **elasticsearch.yml**을 구성하기 위해서 linux server용 도커 이미지를 받아서 구현을 하였다. 하지만 쿠버네티스내에서 클러스터링이 될 수 없었고, 실행도 제대로 되질 않았다.여러 문서를 확인 한 결과 ConfigMap을 통해서 노드별 환경구성이 되는것을 알게 되었고
(예시에서는 Master Node, Data Node를 나누는 기준으로 사용된다)
해당 예시를 이용해서 클러스터링 구성을 위해 적용해보았다
apiVersion: v1
kind: ConfigMap
metadata:
namespace: dev
name: elasticsearch-config
labels:
app: elasticsearch-node
role: master
data:
elasticsearch.yml: |-
cluster.name: ${cluster.name}
node.name: ${node.name}
discovery.seed_hosts: ${discovery.seed_hosts}
cluster.initial_master_nodes: ${cluster.initial_master_nodes}
network.host: 0.0.0.0
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.monitoring.collection.enabled: true- metadata.labels.role
- 라벨롤이 master인 라벨끼리 엮는다
- ${변수명}
- deployment에서 지정한 변수를 지정한다는 뜻
- xpack.security.enabled
- Elasticsearch security 설정 여부
- EKS 자체에서 외부 IP접근이 안되므로 현재는 false로 지정
- xpack.monitoring.enabled, xpack.monitoring.collection.enabled
- Kibana에서 Stack monitoring이 되어야 하므로 true
[Elasticsearch] HPA 구성하기
Elasticsearch에서 클러스터링 구성시, 1대는 마스터 노드여야하고, 나머지 2대는 이중화 구성이 되어야 하므로 권장하는 최소 클러스터링 구성은 3이다.
최소 3대에서 최대 5대까지 클러스터링이 구성된다
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: elasticsearch-hpa
namespace: dev
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: elasticsearch-node
minReplicas: 3
maxReplicas: 5
targetCPUUtilizationPercentage: 50- elasticsearch-node
- HPA구성이 적용되는 Pods의 이름을 명시한다.
[Elasticsearch] Service 구성하기
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-node
namespace: dev
spec:
selector:
app: elasticsearch-node
type: NodePort
ports:
- name: serving
protocol: TCP
port: 9200
- name: node-to-node
protocol: TCP
port: 9300- elasticsearch-node
- 여기서 명시한 이름으로 추후 Kibana에서 내부통신을 할때 IP주소값대신 작성한다 ( 서비스명:9200 포트)
[Elasticsearch] Deployment 구성하기
실제로는 deployment가 아니라 statefulset, 편의상 deployment라고 부름
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch-node
labels:
app: elasticsearch-node
role: master
namespace: dev
spec:
serviceName: elasticsearch-node
replicas: 3
selector:
matchLabels:
app: elasticsearch-node
role: master
template:
metadata:
labels:
app: elasticsearch-node
role: master
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0
imagePullPolicy: Always
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 500m
memory: 1Gi
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
env:
- name: cluster.name
value: elasticsearch-cluster
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "elasticsearch-node"
- name: cluster.initial_master_nodes
value: "elasticsearch-node-0,\
elasticsearch-node-1,\
elasticsearch-node-2"
- name: ES_JAVA_OPTS
value: "-Xms1024m -Xmx1024m"
volumeMounts:
- mountPath: "/usr/share/elasticsearch/data"
name: data
initContainers:
- name: fix-permissions
image: busybox:1.32.0-musl
imagePullPolicy: Always
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox:1.32.0-musl
imagePullPolicy: Always
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox:1.32.0-musl
imagePullPolicy: Always
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi- discovery.seed_hosts (가장 중요)
- 클러스터링을 구성하기 위해 명시된 name을 지정한다 ( 예제는 다르게 나와있음 )
statefulset의 대표이름을 명시해야한다
- cluster.initial_master_nodes
- master node가 될 수 있는 후보군을 명시한다
statefulset에 의해 부여받은 이름을 명시해야한다- hpa지정을 최소 3개로 하였으니 후보군은 고정적인 0 ~ 2를 범위로 잡는다
- volumeClaimTemplates
- 외부 볼륨으로 스토리지 사용 10G
[Kibana] ConfigMap 구성하기
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: dev
name: kibana-config
labels:
app: kibana
role: master
data:
kibana.yml: |-
elasticsearch:
hosts: ${ELASTICSEARCH_HOSTS}
username: lific
password: lific
---[Kibana] HPA 구성하기
키바나는 내부에서만 사용하므로 Pods의 구성은 1로 고정한다
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: kibana-hpa
namespace: dev
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kibana-node
minReplicas: 1
maxReplicas: 1
targetCPUUtilizationPercentage: 50[Kibana] Service 구성하기
apiVersion: v1
kind: Service
metadata:
name: dev-kibana-service
namespace: dev
spec:
selector:
app: kibana
type: NodePort
ports:
- protocol: TCP
port: 5601
targetPort: 5601[Kibana] Deployment 구성하기
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: dev
labels:
app: kibana
role: master
spec:
replicas: 1
selector:
matchLabels:
app: kibana
role: master
template:
metadata:
labels:
app: kibana
role: master
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.12.0
imagePullPolicy: Always
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 700m
memory: 1Gi
env:
- name: ELASTICSEARCH_HOSTS
value: http://elasticsearch-node:9200
ports:
- containerPort: 5601- ELASTICSEARCH_HOSTS (중요)
- ES의 Service에서 명시한 내부 이름을 해당 부분에다가 명시한다 ( 예제는 다르게 되어있음 )
- Kibana와 ES의 통신은 9200 ( 만약 NodePort를 다르게 작성하였으면 변경 )

안녕하세요.
EKS에서도 클러스터링이 되는지 찾아보고 있었는데 좋은 글 잘 읽었습니다!
혹시 "여러 문서를 확인 한 결과 ConfigMap을 통해서 노드별 환경구성이 되는것을 알게 되었고" 해당 문장에 대한 레퍼런스 기억나시는 링크가 있을까요..??
추가로 혹시 Fargate 기반의 EKS일까요? EC2 기반의 EKS일까요?
감사합니다.