char_filter
해당 기능에 대한 문서를 살펴보면, 모두가 이렇게 적혀있다.
tokenizer의 전단계로써, 문자열에 대한 전처리를 처리한다
나는 그래서 이렇게 해석했다.
char_filter 단계에서 전처리를 진행하고, 정제된 데이터 상태에서 색인한다.
즉, 실제 색인할때는 변경이나 삭제된 데이터는 아무런 영향이 없을줄 알았다.
다음과 같은 상황을 보자
이슈 시나리오
char_filter에 관련되면 모두가 같았지만, 여기서는 최초 이슈가 발견되었던 html_strip으로 진행한다.
Put index
PUT /html_strip_test
{
"settings": {
"analysis": {
"analyzer": {
"html_analyzer": {
"char_filter": [
"html_strip"
],
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "html_analyzer"
}
}
}
}html_strip을 통해서 html태그가 삭제되고, nori_tokenizer로 형태소분석을 진행하고 색인한다.
Post document
POST html_strip_test/_doc
{
"content": "<p>특히</p><span>test</span>"
}Html로 감싸진 문자열을 색인한다. 예상되는 색인 토큰은 [특히], [test]이다.
GET Query & Highlight
실제 검색을 진행하고 하이라이팅이 정상적으로 되었는지 확인한다.
GET html_strip_test/_search
{
"query": {
"match": {
"content": "특히"
}
},
"highlight": {
"pre_tags": [
"<result>"
],
"post_tags": [
"</result>"
],
"fields": {
"content": {}
}
}
}
// Result
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "html_strip_test",
"_type" : "_doc",
"_id" : "EO3wCYkB1lH3kl5DUSAI",
"_score" : 0.2876821,
"_source" : {
"content" : "<em>특히</em><span>test</span>"
},
"highlight" : {
"content" : [
"<em><result>특히</em><span></result>test</span>"
]
}
}
]
}
}{
"highlight" : {
"content" : [
"<em><result>특히</em><span></result>test</span>"
]
}
}정상적으로 하이라이팅이 되었는가? 나는 검색어를 "특히"라고 넣었으며 예상되는 결과는 <result>특히</result>라고 검색이 되어야 했다.
왜그럴까?
실제 analyze로 색인 offset을 확인해보자
POST html_strip_test/_analyze
{
"tokenizer": "nori_tokenizer",
"char_filter": [
"html_strip"
],
"text": """<em>특히</em><span>test</span>"""
}
// Result
{
"tokens" : [
{
"token" : "특히",
"start_offset" : 4,
"end_offset" : 17,
"type" : "word",
"position" : 0
},
{
"token" : "test",
"start_offset" : 17,
"end_offset" : 28,
"type" : "word",
"position" : 1
}
]
}[특히] 토큰의 start_offset:4, end_offset:17 이다. 정상적인 케이스이면 0 - 2여야 하는거 아닌가?
char_filter 단계에서 전처리를 하기는 하지만, 실제 검색을 하면 char_filter 전의 원문을 가지고 있다. 즉, char_filter는 색인을 처리하기 위한 단계기 때문에
실제 색인의 offset은 태그 정보를 포함하고 있다.
태그 정보를 포함하고 있으면 4 - 6이여야 하잖아?
왜 end_offset이 17일까? 이유는 <span>의 offset이 같이 적용되었다.
< e m > 특 히 < / e m > < s p a n >
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16Lucene HTMLStripCharFilter.java 분석
HTMLStripCharFilter를 디버그로 돌려보았다. 문자열을 Buffer로 변환하여 미리 지정된 값들에 대한 매칭과 계산으로 필터를 거르게 되는데 모든 값이 아스키 코드값으로 변환하여 처리함으로 코드에 대한 이해를 할 수 가 없었다.
(모든 값이 아스키 코드 처리 )
그로인해 명확하게 어떠한 로직에 의해 해당 이슈가 발생하는지, 수정이 되려면 어찌해야하는지 등에 대한 의문이 풀리지는 않았다.
대략적으로 어느 부분에 의해서 발생하는지 확인하자
HTMLStripCharFilter를 사용하여 HTML 태그를 제거하는 char_filter 생성
char_filter 적용 후의 텍스트를 StringWriter에 기록
HTMLStripCharFilter charFilter = new HTMLStripCharFilter(new StringReader("<em>생선</em>.<span>교회</span>"));
while ((numChars = charFilter.read(buffer, 0, buffer.length)) != -1) {
writer.write(buffer, 0, numChars);
}태그의 시작문 발견 ('<')
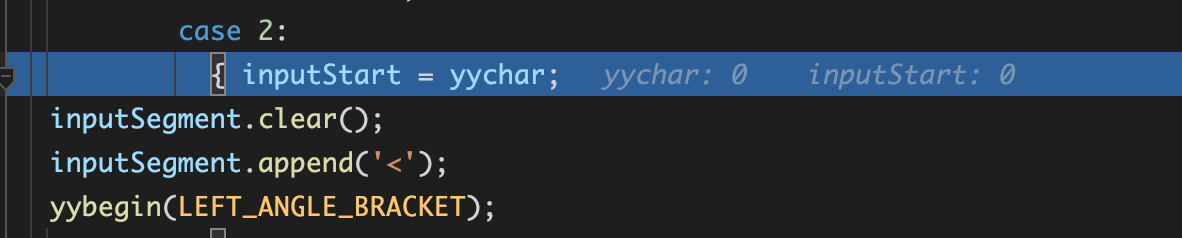
태그의 종료문 발견 ('>'), offset 기록(addOffCorrectMap)


종료 처리
이후 정상적인 케이스이면 zzAction < 0 ? zzAction : ZZ_ACTION[zzAction]의 값이 1이 나와서 해당 태그의 값을 종료 시키고 다음태그의 값을 진행시켜야 한다. 그러나 다음값이 또 다른 태그의 시작이 되면 값이 2가 나오게 되어서 초기화가 이루어지지 않고 다음값과 합산하계 된다.
// 이때 12의 값을 가지고 있음
cumulativeDiff += inputSegment.length() + yylength();</em>까지의 offset 위치값 9

</em>이후의 값이 <가 되면 값이 1이 아닌 2가 되어 종료 하지 않음
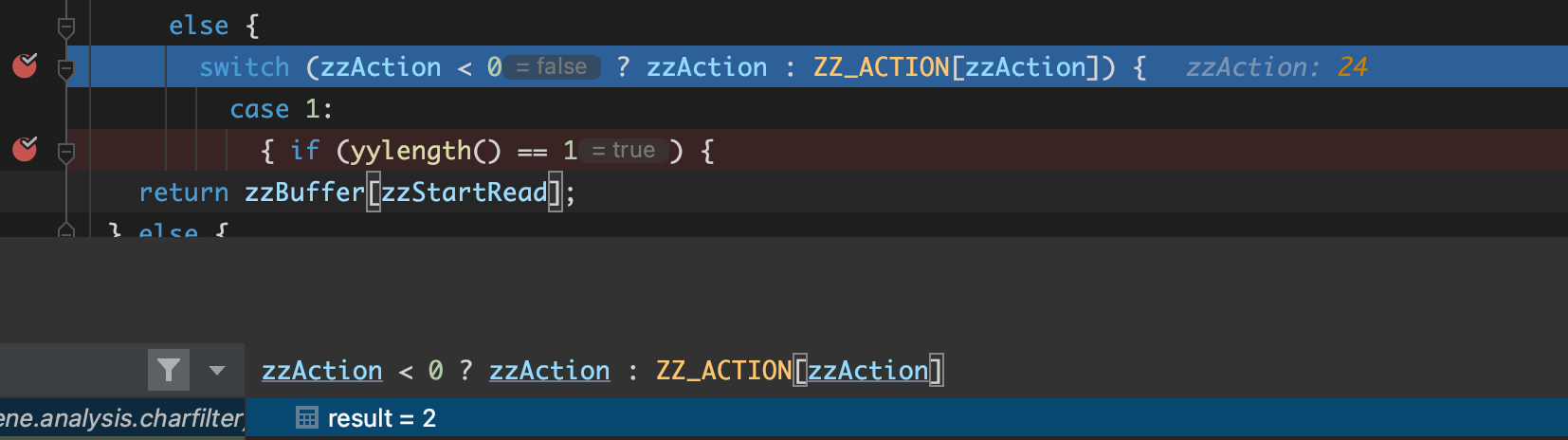
띄어쓰기와 [.]의 경우는 정상적으로 1이 나옴을 확인.
</em>기존값 9 + <span>추가값 6
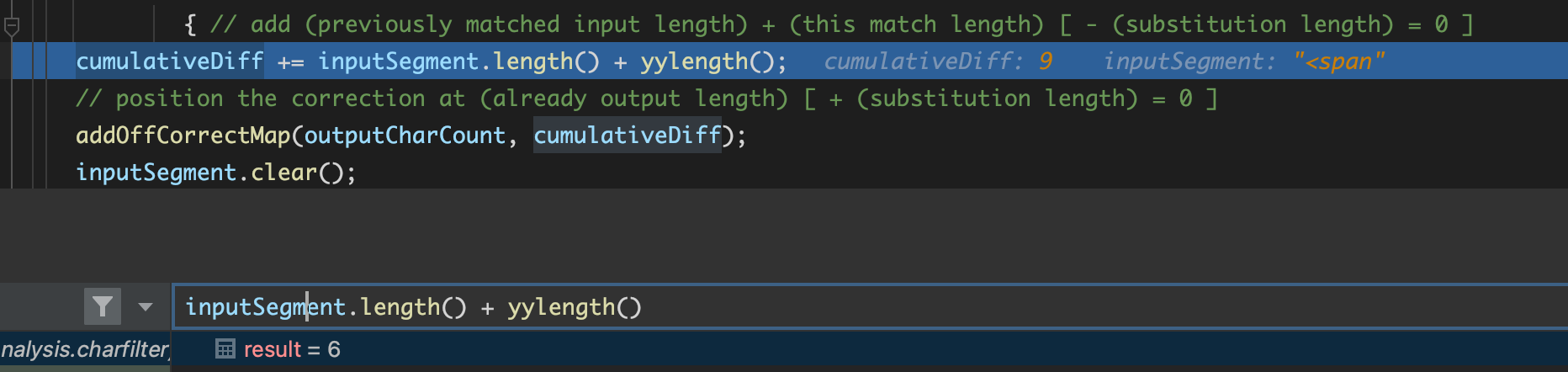
원래값 추가로 <span> 가 되어서 15 + 2 = 17
< e m > 특 히 < / e m > < s p a n >
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16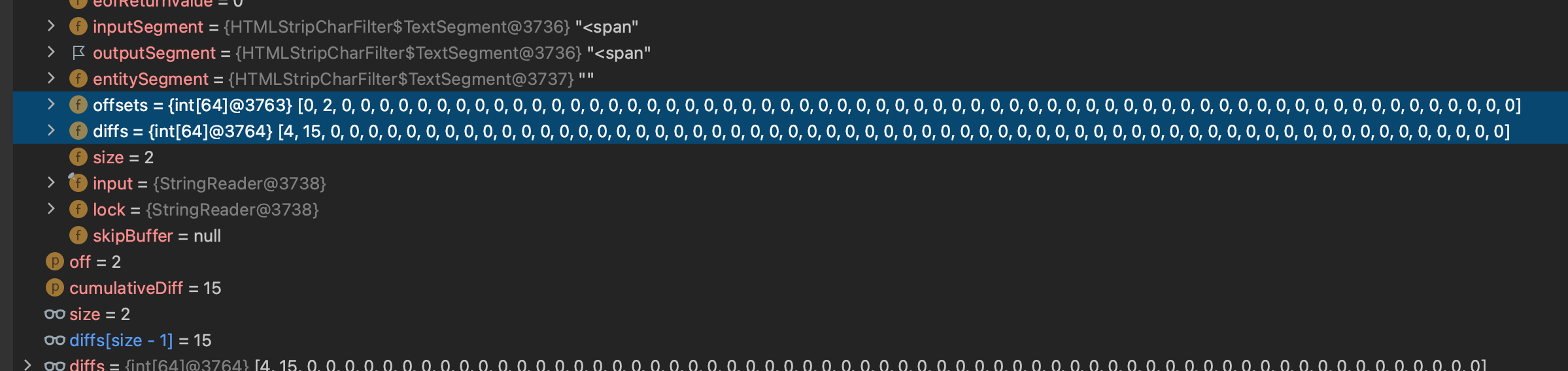
코드를 제대로 분석해서 다른 페이지에 자세히 다루려고 했으나,, 모든 값이 아스키코드로 되어있고 처리가 복잡하여 시간이 더 있어도 명확하지 않을듯 하여 이곳에다가 기록 후 종료하도록 한다.
char_filter가 없는 경우
POST html_strip_test/_analyze
{
"tokenizer": "nori_tokenizer",
"char_filter": [],
"text": """<em>특히</em><span>test</span>"""
}
// Result
{
"tokens" : [
{
"token" : "em",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "특히",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "em",
"start_offset" : 8,
"end_offset" : 10,
"type" : "word",
"position" : 2
}
...
]
}다른 방식의 해결법
해당 방식의 경우 Side effect가 발생 할 수 있다.
POST html_strip_test/_analyze
{
"tokenizer": "nori_tokenizer",
"char_filter": [
{
"type": "mapping",
"mappings": [
">< => > <"
]
},
"html_strip"
],
"text": """<em>특히</em><span>test</span>"""
}
// Result
{
"tokens" : [
{
"token" : "특히",
"start_offset" : 4,
"end_offset" : 11,
"type" : "word",
"position" : 0
},
{
"token" : "test",
"start_offset" : 17,
"end_offset" : 28,
"type" : "word",
"position" : 1
}
]
}